環境
- Python:3.6
- TensorFlow:1.8.0
- Keras:2.2.5
アニメ画像切り出し
下記を参考にフォルダ内全ての画像を切り出しする。
OpenCVでアニメの顔検出 - Qiita
import os
import cv2
import glob
list = glob.glob("/Users/katasugirupan/Desktop/sample/*")
classifier = cv2.CascadeClassifier('lbpcascade_animeface.xml')
output_dir = 'corpus'
if not os.path.exists(output_dir):
os.makedirs(output_dir)
n = 0
for i in list:
print(i)
image = cv2.imread(i)
gray_image = cv2.cvtColor(image,cv2.COLOR_BGR2GRAY)
faces = classifier.detectMultiScale(gray_image)
# print(faces)
for j, (x,y,w,h) in enumerate(faces):
face_image = image[y:y+h, x:x+w]
resize_image = cv2.resize(face_image,(64,64),interpolation = cv2.INTER_AREA)
output_path = os.path.join(output_dir,str(n)+'.jpg'.format(j))
cv2.imwrite(output_path,resize_image)
n += 1
lbpcascade_animeface.xml
https://github.com/nagadomi/lbpcascade_animeface
画像の名前を連番にする
特に必要な作業ではないですが管理がしやすいように、ファイル名を「A0.jpg - A1.jpg ...」に変更しておきます。
import os
import glob
list = glob.glob("/Users/katasugirupan/Desktop/corpus/*")
output_dir = 'dataset'
if not os.path.exists(output_dir):
os.makedirs(output_dir)
n = 0
for file_name in list:
print(file_name)
os.rename(file_name, '/Users/katasugirupan/Desktop/' + output_dir + '/' + 'A' + str(n) + '.jpg')
n += 1
kerasで自前のデータセットを読み込み、表示してみる
# データセット作成 表示
import keras
from keras.utils import np_utils
from keras.preprocessing.image import array_to_img, img_to_array, load_img
import numpy as np
from PIL import Image
import os
import re
# 画像表示
def ConvertToImg(img):
return Image.fromarray(np.uint8(img))
def list_pictures(directory, ext='jpg|jpeg|bmp|png|ppm'):
return [os.path.join(root, f)
for root, _, files in os.walk(directory) for f in files
if re.match(r'([/w]+/.(?:' + ext + '))', f.lower())]
X = []
# 画像フォルダから、64x64で取り込む
for picture in list_pictures('./dataset'):
img = img_to_array(load_img(picture, target_size=(64,64)))
X.append(img)
# arrayに変換
X = np.asarray(X)
# 画像一つの幅
chr_w = 64
# 画像一つの高さ
chr_h = 64
# 画像をPILで1枚の画像に描画する(15枚*15枚)
canvas = Image.new('RGB', (int(chr_w * 15), int(chr_h * 15)), (255, 255, 255))
# 画像を読み込んで描画
i = 0
for y in range(15):
for x in range(15):
chrImg = ConvertToImg(x_train[i])
canvas.paste(chrImg, (chr_w*x, chr_h*y))
i = i + 1
canvas.show()
# 表示した画像をJPEGとして保存
canvas.save('test.jpg', 'JPEG', quality=100, optimize=True)
今回はMakeGirlsMoeから画像を頂き、切り出しています。
表示するとこのような感じ。

kerasでCNNを実装
下記の記事を参考にさせていただきました。
kerasでCNN 自分で拾った画像でやってみる - Qiita
Kerasは相撲取りとアイドルを見分けられるかやってみた - Qiita
私もやってみたい。
と言う事で、Fate0のセイバーが好きなのでセイバー分類機を作成することに。
* セイバーかセイバーではないか分類。
* セイバー : 300枚
* セイバーではない : 600枚
* 学習とテストは合計900枚を利用し、その内10%をテストに使用
* プラス、未知のデータとして検証用にそれぞれ3枚づつ用意
画像はgoogle検索で頑張る。
keras2系で記述しています。
from keras.models import Sequential
from keras.layers import Activation, Dense, Dropout, Conv2D, Flatten, MaxPooling2D
from keras.utils.np_utils import to_categorical
from keras.optimizers import Adagrad
from keras.optimizers import Adam
import numpy as np
from PIL import Image
import os
import matplotlib.pyplot as plt
# 学習用のデータ作成
X = []
Y = []
for dir in os.listdir("drive/My Drive/keras/data2/train"):
dir1 = "drive/My Drive/keras/data2/train/" + dir
label = 0
# Labelを付ける
if dir == "saber":
label = 0
elif dir == "unknown":
label = 1
for file in os.listdir(dir1):
Y.append(label)
filepath = dir1 + "/" + file
image = np.array(Image.open(filepath).resize((64, 64)))
image = image.transpose(2, 0, 1)
X.append(image / 255.)
X = np.array(X)
Y = to_categorical(Y) # [1,0],[0,1] One hot
# CNN
model = Sequential()
model.add(Conv2D(32, (3, 3), padding="same", input_shape=(3, 64, 64)))
model.add(Activation("relu"))
model.add(Conv2D(32, (3, 3)))
model.add(Activation("relu"))
model.add(MaxPooling2D(pool_size=(2, 2), padding=("same")))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(200))
model.add(Activation("relu"))
model.add(Dropout(0.2))
model.add(Dense(200))
model.add(Activation("relu"))
model.add(Dropout(0.2))
model.add(Dense(2))
model.add(Activation("softmax"))
opt = Adam(lr=0.0001)
model.compile(loss="categorical_crossentropy", optimizer=opt, metrics=["accuracy"])
# 10%はテストに使用
hist = model.fit(X, Y, epochs=50, batch_size=25, validation_split=0.1)
# テスト用ディレクトリの画像でチェック、正解率を表示
total = 0.
ok_count = 0.
for dir in os.listdir("drive/My Drive/keras/data2/test"):
dir1 = "drive/My Drive/keras/data2/test/" + dir
label = 0
if dir == "saber":
label = 0
elif dir == "unknown":
label = 1
for file in os.listdir(dir1):
label_list.append(label)
filepath = dir1 + "/" + file
image = np.array(Image.open(filepath).resize((64, 64)))
print(filepath)
image = image.transpose(2, 0, 1)
result = model.predict_classes(np.array([image / 255.]))
print("label:", label, "result:", result[0])
total += 1.
if label == result[0]:
ok_count += 1.
print("seikai: ", ok_count / total * 100, "%")
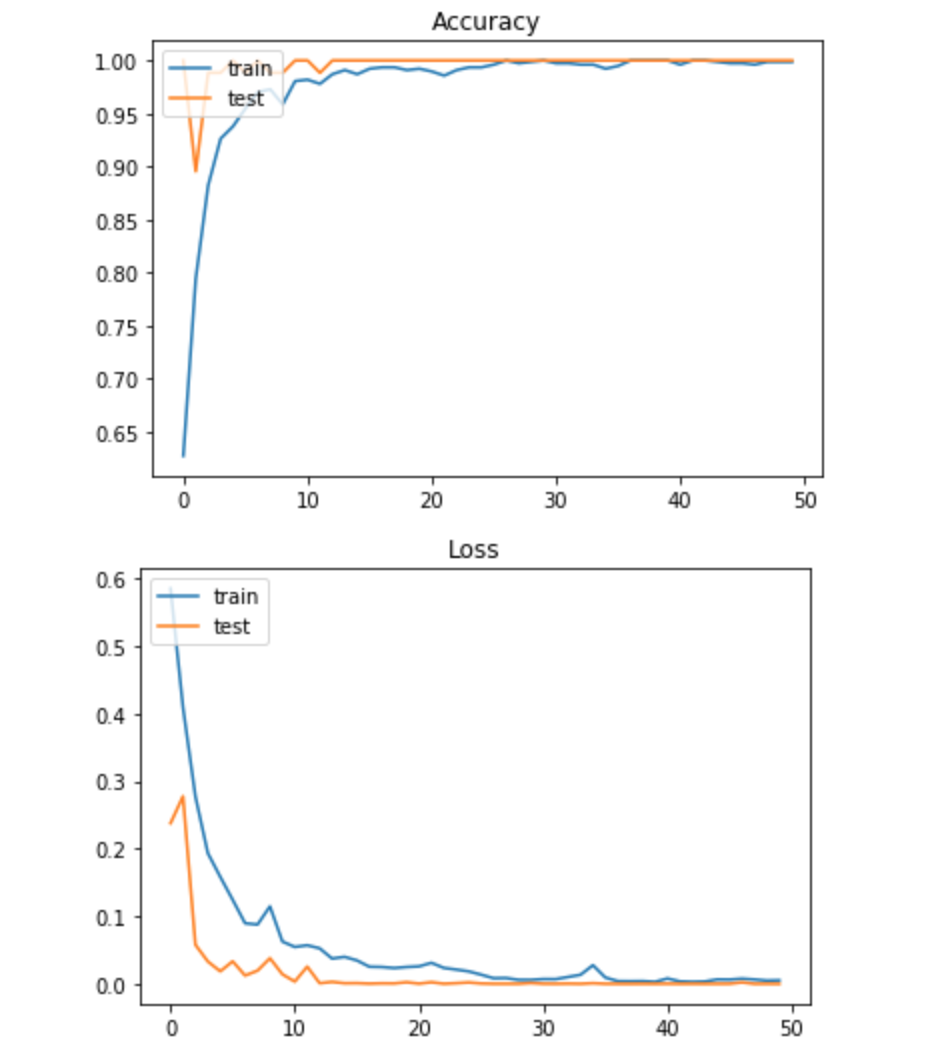
# 正解率の推移をプロット
plt.plot(hist.history['acc'])
plt.plot(hist.history['val_acc'])
plt.title('Accuracy')
plt.legend(['train','test'], loc='upper left')
plt.show()
# ロスの推移をプロット
plt.plot(hist.history['loss'])
plt.plot(hist.history['val_loss'])
plt.title('Loss')
plt.legend(['train','test'], loc='upper left')
plt.show()
model.summary()
drive/My Drive/keras/data2/test/saber/F302.jpg
label: 0 result: 0
drive/My Drive/keras/data2/test/saber/F303.jpg
label: 0 result: 0
drive/My Drive/keras/data2/test/saber/F301.jpg
label: 0 result: 0
drive/My Drive/keras/data2/test/unknown/A560.jpg
label: 1 result: 1
drive/My Drive/keras/data2/test/unknown/A561.jpg
label: 1 result: 1
drive/My Drive/keras/data2/test/unknown/A562.jpg
label: 1 result: 1
seikai: 100.0 %
未知のデータ6枚に対しても正しく認識しているようです。
枚数を増やして検証すれば正解率は下がるかもしれません。
終わりに
- 下記のモデルも試して見たいと思うのですが、長くなり疲れてきたので一旦終わりにしようと思います。
padding='valid'にしたり、もう一段階Denseを増やしたりと色々考えれると思います。
qiitaの記事がありましたので、私でもCNNを試せました。先人に感謝致します。