データを活用できていますか?
予測分析による顧客行動や需要などの予測結果は、ビジネスアクションに繋がりやすいため、高い費用対効果を実現します。
通常、統計や機械学習の知識がある人が、Python上で、pandas, Numpy, scikit-learnなどライブラリを使って予測分析されていると思います。
SONY Prediction Oneが簡単
ソニーネットワークコミュニケーションズ株式会社から、機械学習を用いた予測分析サービスPrediction Oneが無償提供されましたので、使ってみました。過去の実績データから将来の結果を予測するAI技術であり、営業や業務管理、人事など幅広いビジネスへの適用が可能です。
研究の世界でも、過去の膨大な過去データを使って、複数のパラメーターから別のパラメーターを予測する期待度は高いですね。
Prediction Oneはpythonの知識は必要ありません。これは試してみたい。
SONY Prediction Oneのサイトはこちら
kaggleのtitanicデータを使って試してみた
予測するデータはkaggleのtitanicデータを使ってみました。
kaggleのtitanicのサイトはこちら
Prediction Oneを試す前に、pythonでまずトライ
Anacondaをインストールしてpython環境を作る。
インストール方法は
Anaconda で Python 環境をインストールする
以下のサイトに従い、最後までハンズオン。
【Kaggle初心者入門編】タイタニック号で生き残るのは誰?
import pandas as pd
import numpy as np
train = pd.read_csv("../ディレクトリを指定/train.csv")
test = pd.read_csv("../ディレクトリを指定/test.csv")
# 欠損データを代理データに入れ替える
train["Age"] = train["Age"].fillna(train["Age"].median())
train["Embarked"] = train["Embarked"].fillna("S")
kesson_table(train)
# trainについて文字列を数字に変換
train["Sex"][train["Sex"] == "male"] = 0
train["Sex"][train["Sex"] == "female"] = 1
train["Embarked"][train["Embarked"] == "S" ] = 0
train["Embarked"][train["Embarked"] == "C" ] = 1
train["Embarked"][train["Embarked"] == "Q"] = 2
train.head(10)
# testについて文字列を数字に変換
test["Age"] = test["Age"].fillna(test["Age"].median())
test["Sex"][test["Sex"] == "male"] = 0
test["Sex"][test["Sex"] == "female"] = 1
test["Embarked"][test["Embarked"] == "S"] = 0
test["Embarked"][test["Embarked"] == "C"] = 1
test["Embarked"][test["Embarked"] == "Q"] = 2
test.Fare[152] = test.Fare.median()
test.head(10)
# scikit-learnのインポート
from sklearn import tree
# 予測モデルで使う値を取り出す
features_two = train[["Pclass","Age","Sex","Fare", "SibSp", "Parch", "Embarked"]].values
# 決定木の作成とアーギュメントの設定
max_depth = 10
min_samples_split = 5
my_tree_two = tree.DecisionTreeClassifier(max_depth = max_depth, min_samples_split = min_samples_split, random_state = 1)
my_tree_two = my_tree_two.fit(features_two, target)
# testから使う項目の値を取り出す
test_features_2 = test[["Pclass", "Age", "Sex", "Fare", "SibSp", "Parch", "Embarked"]].values
# 決定木を使って予測をしてCSVへ書き出す
my_prediction_tree_two = my_tree_two.predict(test_features_2)
PassengerId = np.array(test["PassengerId"]).astype(int)
my_solution_tree_two = pd.DataFrame(my_prediction_tree_two, PassengerId, columns = ["Survived"])
my_solution_tree_two.to_csv("my_tree_two.csv", index_label = ["PassengerId"])
結果
pandas, Numpy, scikit-learnを使って、Pclass, Sex, Age, SibSp, parch, fare, Embarked の項目を反映させた予測モデルでは、結果をkaggleに投稿したところ0.76076でした。
Prediction Oneを使う。
それでは今回の主題のPrediction Oneを使ってみます。
手順通りインストールします。
方針
titanicのtrain.csvのデータは未加工で使用してみます。たとえば、年齢の空白は埋めない、性別はmale, female表記のまま(0,1など数字に変換しない)。
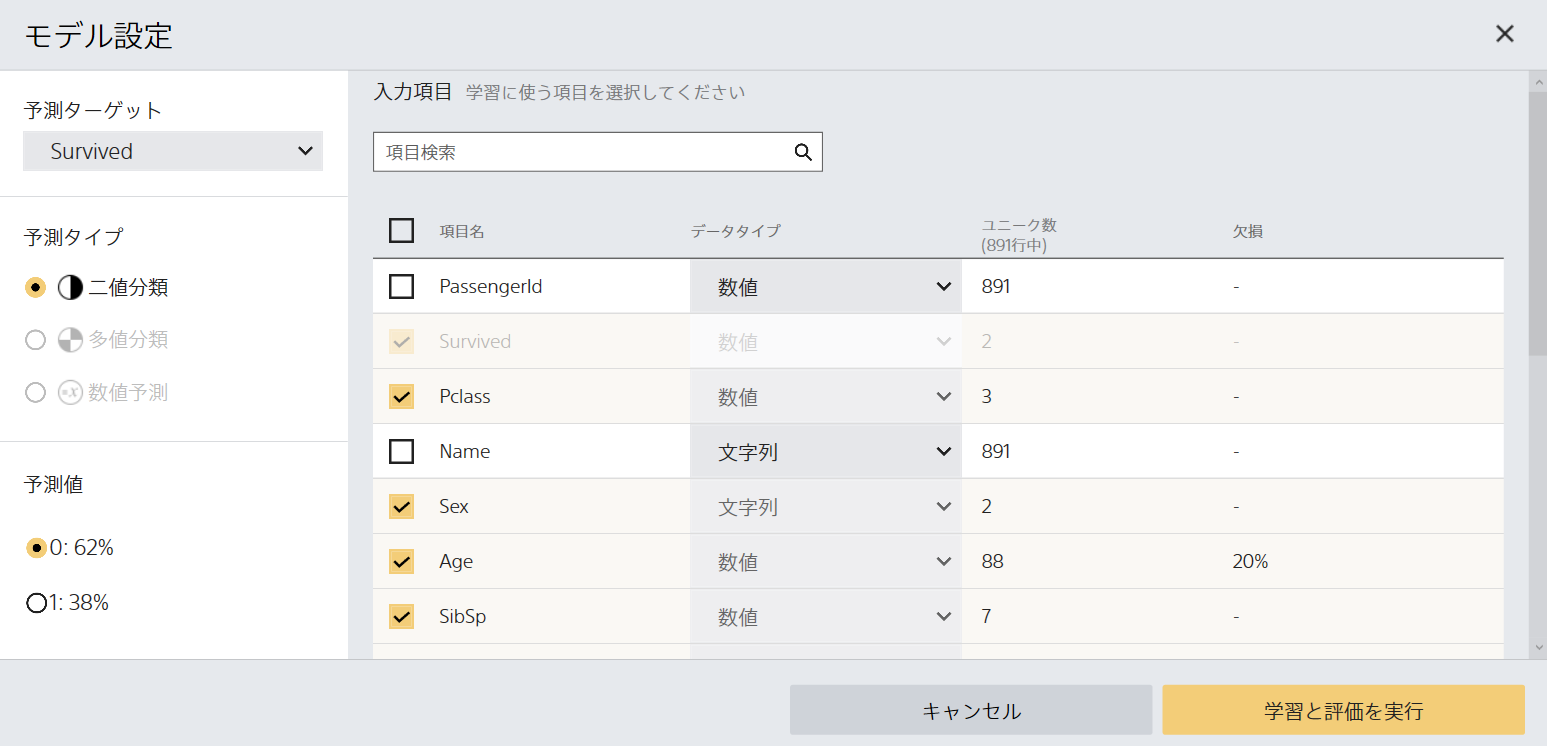
モデル設定
以下に示す通り、予測ターゲットはSurvivedに設定します。それ以外の設定項目も以下に示す通り。学習に使う項目から、Name, Ticket, Cabinの3つの文字列は外します。文字列であってもSexとEmbarkedは、重要な判定要素ですから、チェックを入れておきます。
予測タイプは二値分類。予測値0.62%。評価データの部分の「必ず交差検証を行う」はチェックを外します。
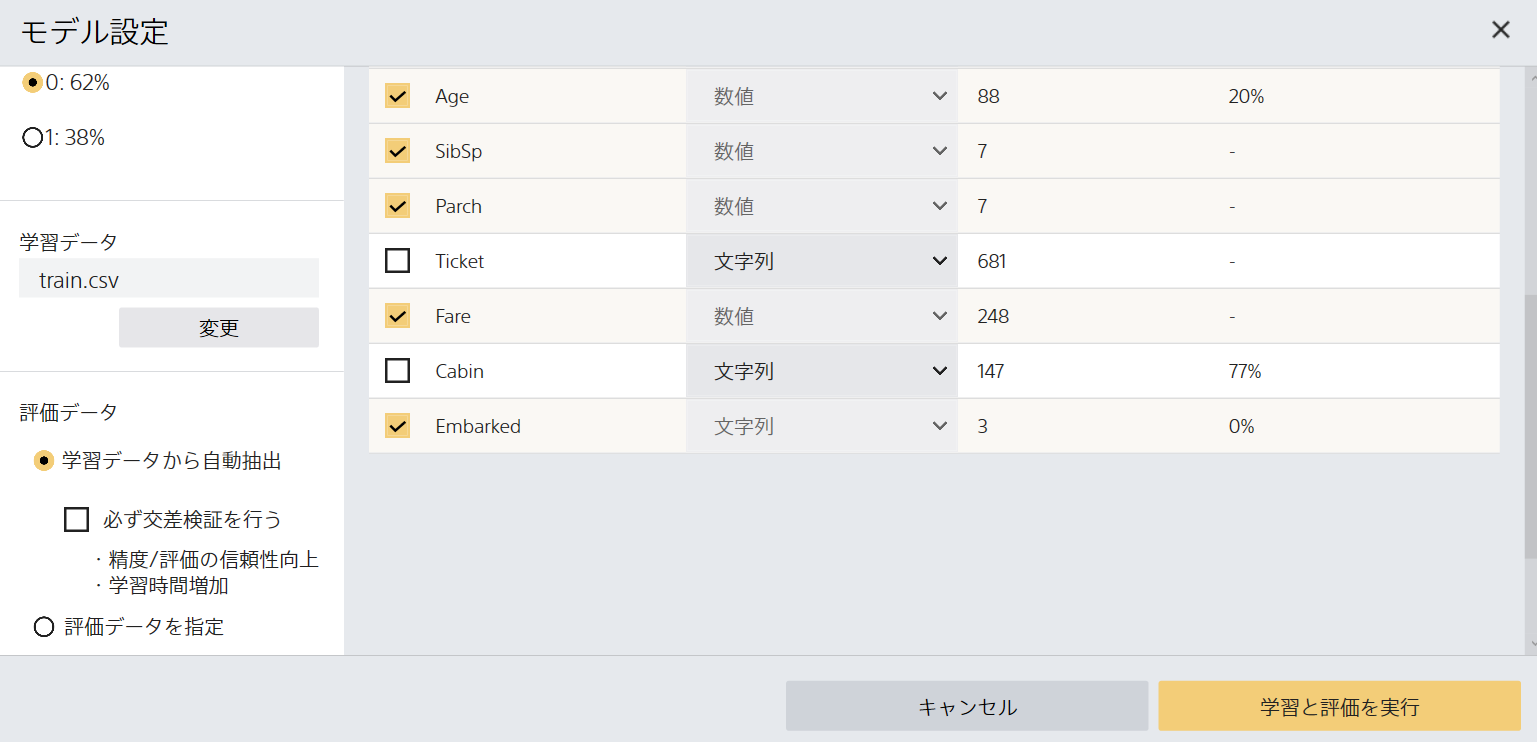
右下の「学習と評価を実行」の黄色ボタンを押す
学習と評価の結果
結果はこの画面
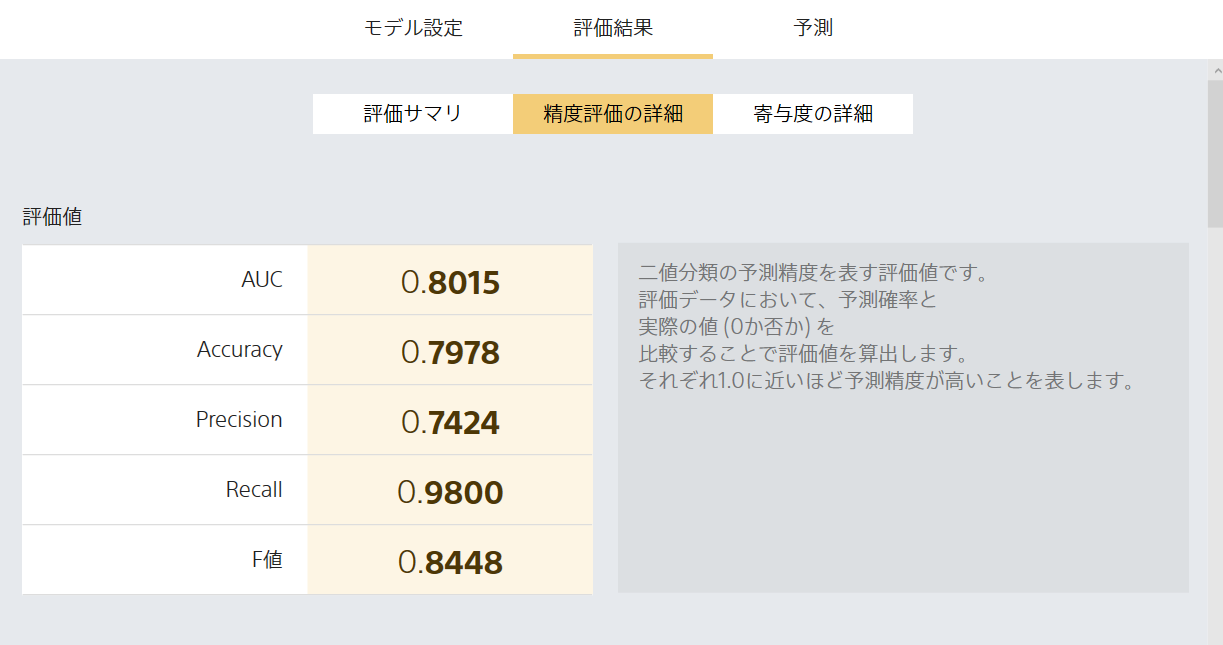
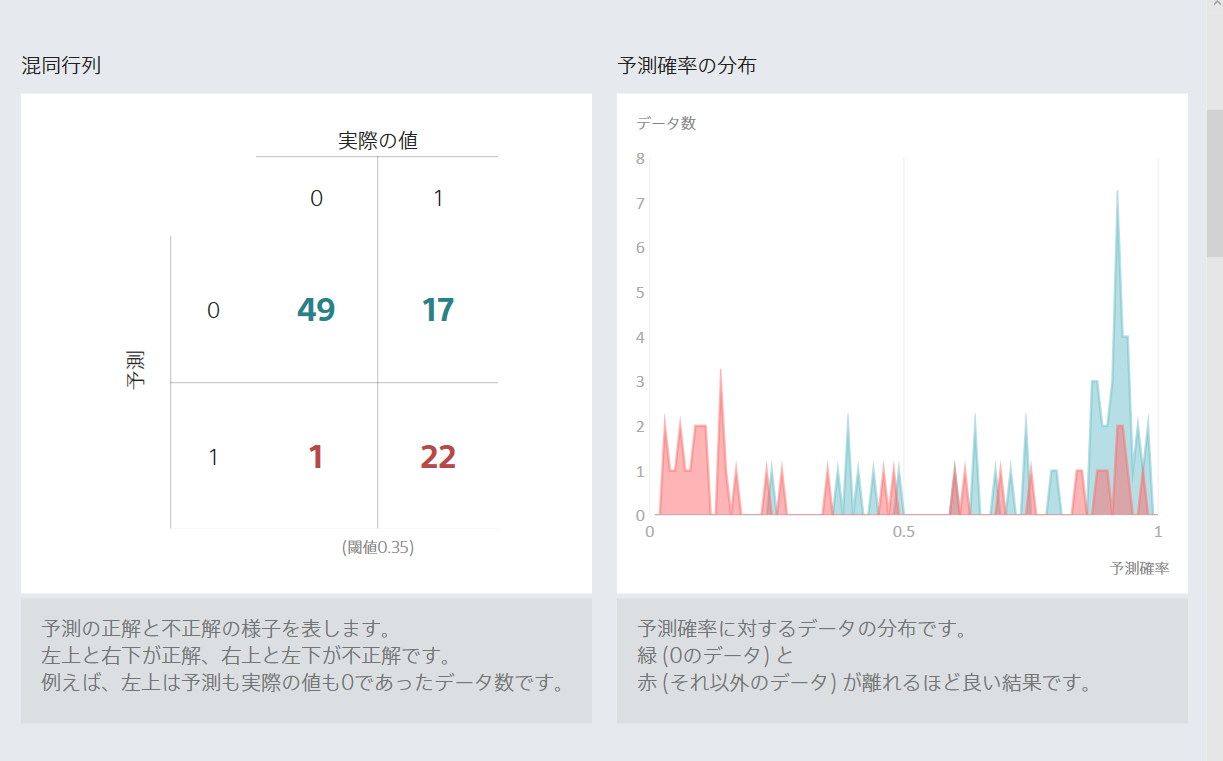
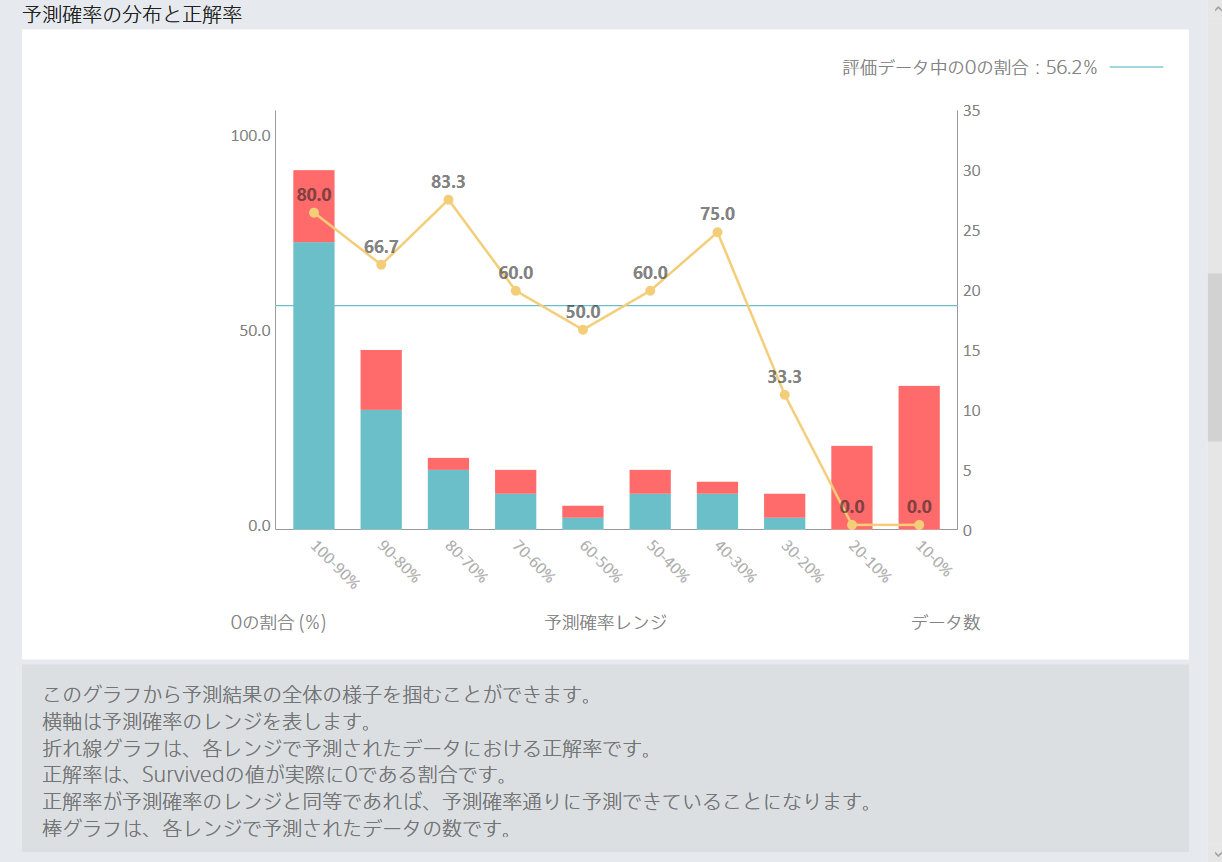
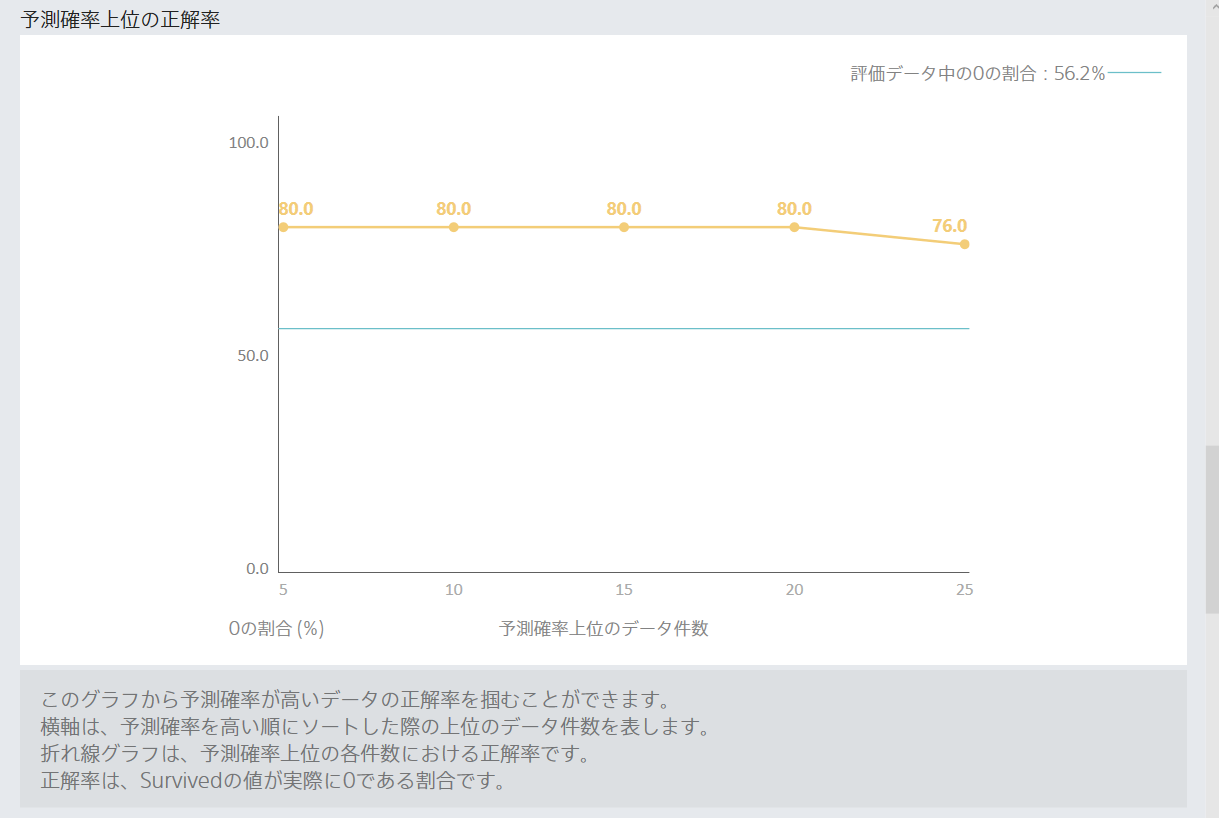
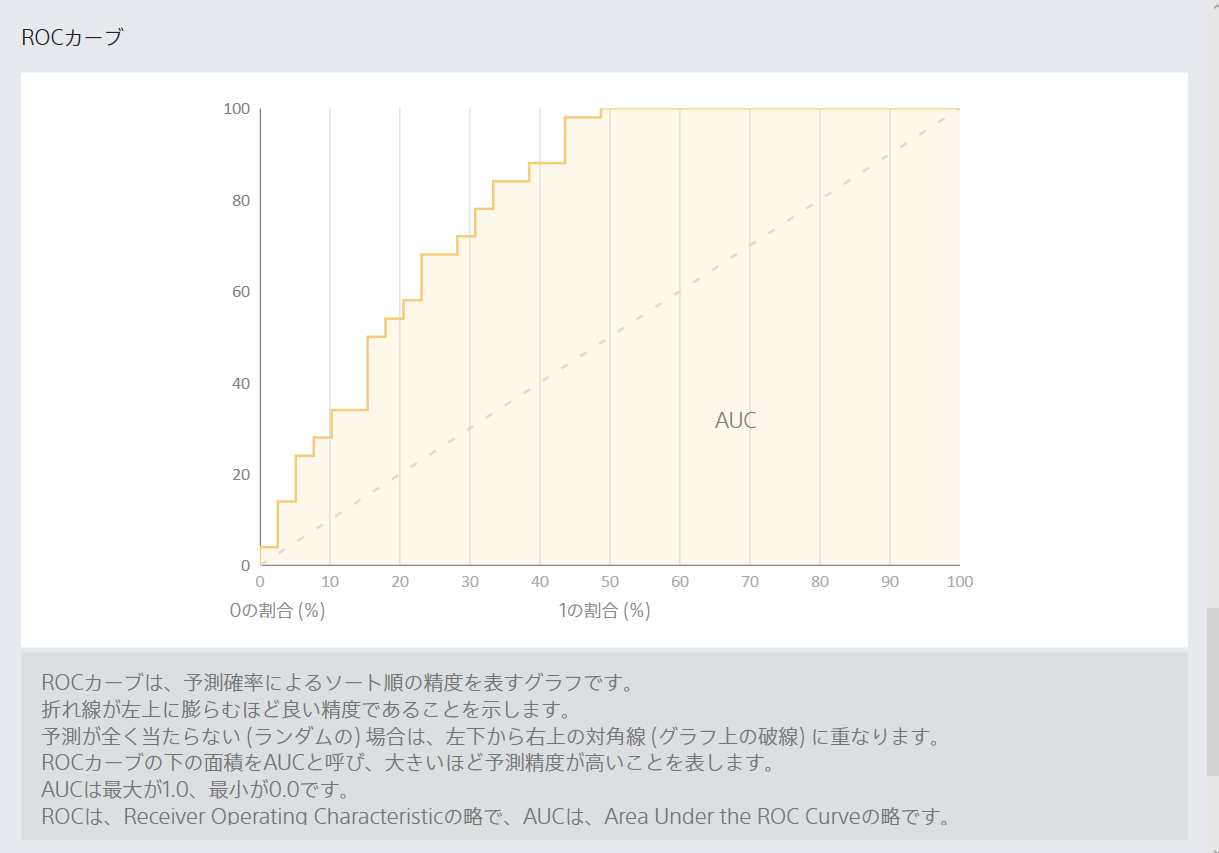
なんかよさそう。データの読み方は理解できていない。でも、なんかよさそう。
予測してみる。
予測タブをクリックして予測画面に移動。はじめの画面で、新規予測をクリック。
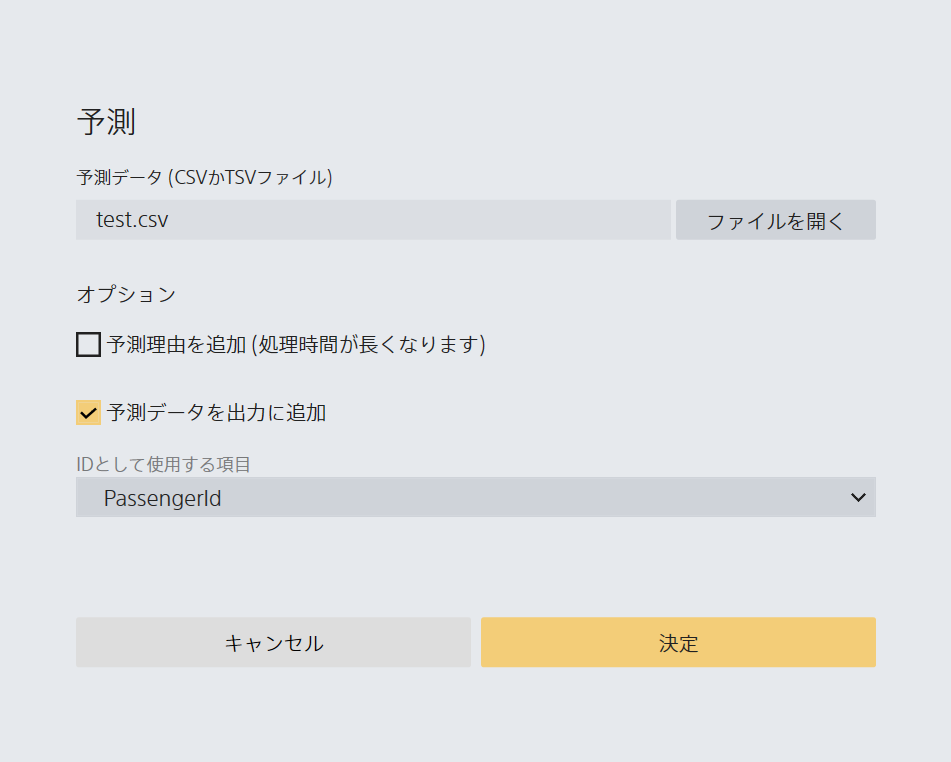
予測データとして、test.csvを入れる。
「予測理由を追加」のチェックを外す。「予測データを出力に追加」をチェック。
IDとして使用する項目はPassengerIDを設定。
以上設定したら、右下の「決定」の黄色ボタンを押す。
予測結果を保存して得られたCSVファイルをエクセルで開いてみるとこの通り。
左から2列目(B列)が0(死亡)の可能性、左から3列目(C列)が1(生存)の可能性の数字となっているので、2列目(B列)が0.5より大きく1以下の行は、Survivedとして0を入力。また3列目(C列)が0.5より大きく1以下の行は、Survivedとして1を入力。この入力操作はエクセルを使用し手作業で行った。
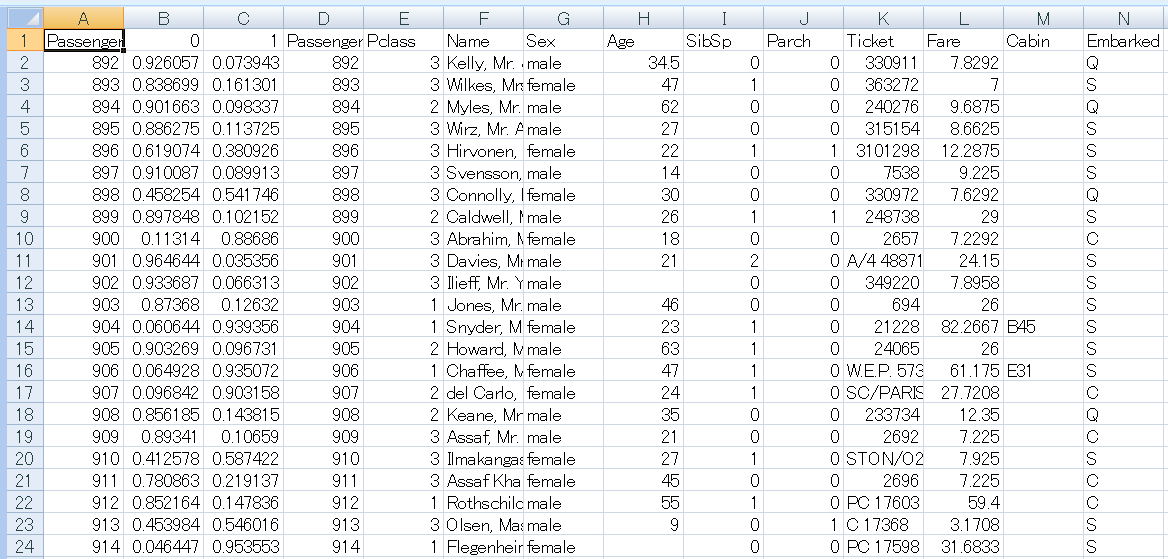
左から1列目にPassengerID、2列目にSurvivedとして3列目以降は削除する。
最終的なCSVファイルはこれ。(エクセルで閲覧)
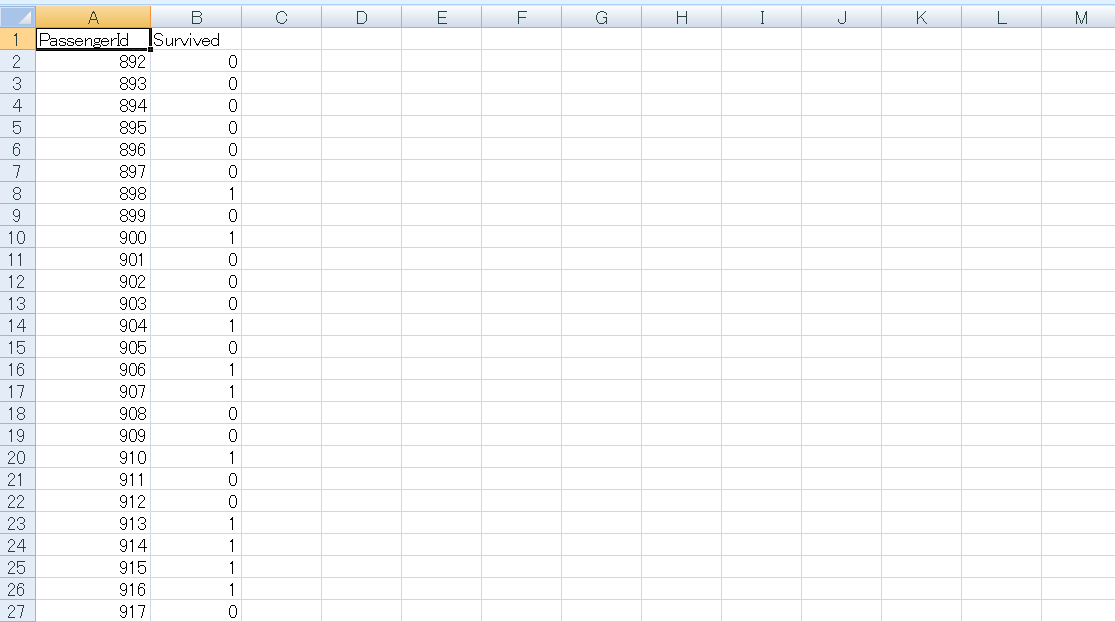
結果
このCSVファイルをkaggleに投稿してみた。
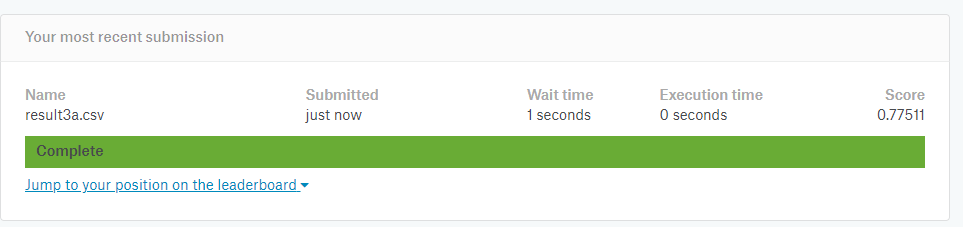
Prediction Oneを使って予測した結果は0.77511で、pythonを使った結果の数字0.76076より高い好成績となりました。
大きなデータに挑戦してみた
日本最大のデータサイエンティストコミュニティであるSIGNATEのサイト内のAI創薬: 薬物動態パラメータ予測のデータを使って予測できるか試してみました。この学習用データ(train.csv)は、レコード数が13,731、列数が3,807と大きなCSVファイルです。
学習させようとした結果
このCSVファイルで学習させようとすると項目数が多すぎるため、データを読み込めませんと表示されて無理でした。(残念)

項目数減らしてみた結果
項目数が多いのなら単純に減らしてみたらどういう結果になるのか試してみました。単純に項目数をエクセルを使ってカット。以下のサイズならPrediction Oneは「項目数が多すぎるため、データを読み込めません」と言ってこないことをあらかじめ確かめました。
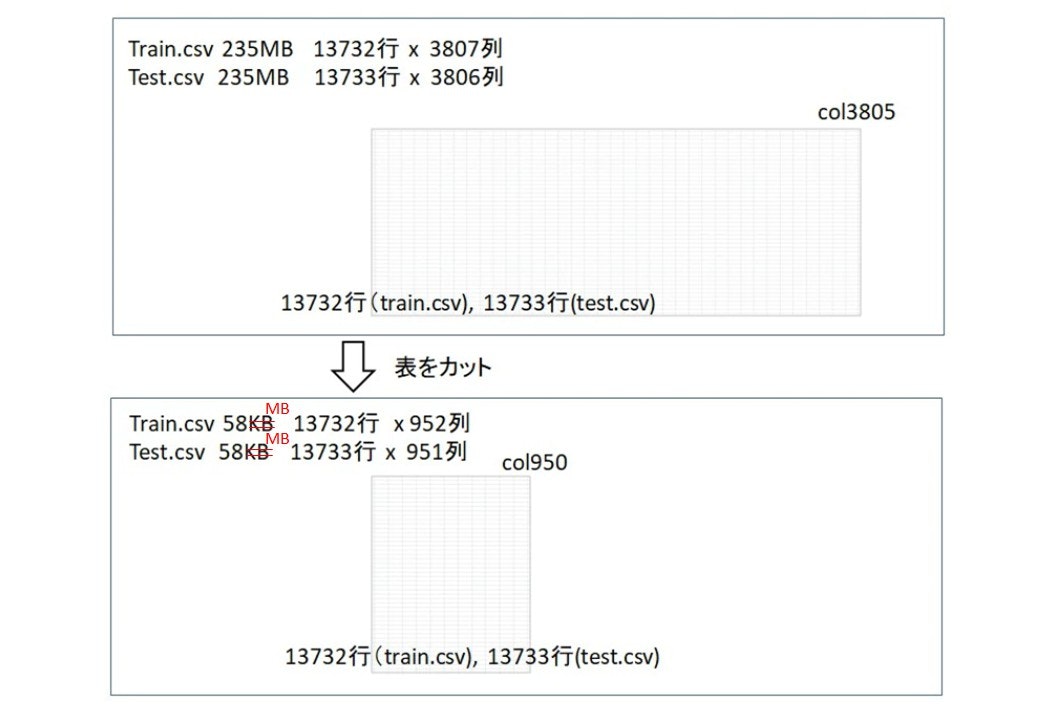
このカットしたtrain.csv(58MB, 13732行 x 952列)をPrediction Oneに学習させて、その後test.csv(58MB, 13733行 x 951列)を予測してみました。
そして、得られた結果をSIGNATEに投稿してみたところ、暫定評価 0.55283, ランキング423位(参加1678人中)という結果をもらいました。与えられたデータを約4分の3の量をカットし残り約4分の1だけで予測してこの成績というのは健闘していますね。

おわりに
Prediction Oneなら、統計の知識もPythonの知識も必要なく、データサイエンティストが行っている結果と同レベルの予測ができることがわかりました。
営業や業務管理、人事などの分野で、また研究の分野で、Prediction Oneが強力なツールとなります。
超簡単に予測分析できるものの、大きすぎるデータには注意です。
皆さんも試してみてくださいね。