はじめに
Prometheusは、アラートの重複排除、サイレンシング、グループ化、抑制、ルーティング(ソース)などの多数の機能を提供するAlertmanagerと呼ばれる別のコンポーネントとともに非常に一般的にデプロイされます。 実際、Prometheusは強力にサポートされているため、PrometheusとAlertmanagerはほとんど切り離せません。Prometheusの構成には、alertingというトップレベルのキーがあります。 このキーは、Alertmanagerノードと、アラートを起動する前のアラートのマングルルールを指定するためだけのものです。
ただし、これは見た目ほど簡単ではありません。 経験上、いくつかの問題が何度も発生します。 この記事では、それらに光を当て、これらの一般的な問題を回避および解決する方法を記載させていただきます。
注釈とラベル
アラートを定義するときに最初に遭遇することは、注釈とラベルと呼ばれるこれら2つのことです。 簡単なアラートルールは次のようになります。
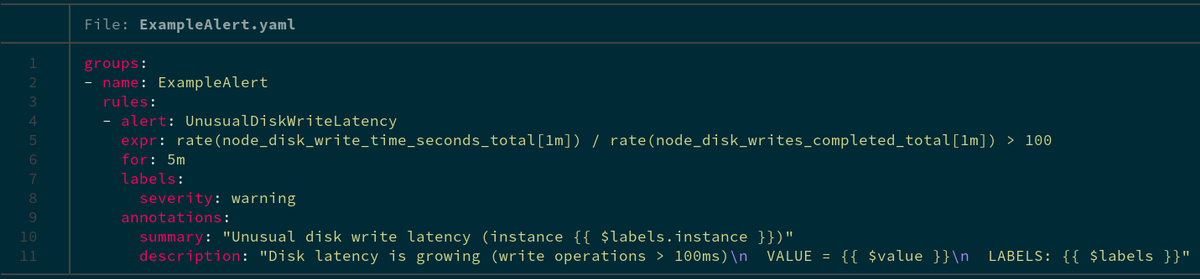
ご覧のとおり、注釈とラベルは一見同じように使用されているように見えます。つまり、すでに存在しているものの上にアラートにデータを追加します。
-
ラベルはアラートを識別するものであり、デフォルトではアラートの表現に基づいて自動的に書き込まれます。 ただし、ラベルセクションのアラートルールの定義で上書きできます。
-
注釈はアラートに関する情報も追加しますが、アラートルールのデータを使用して自動的に事前入力されることはありません。 代わりに、ラベルからのデータを充実させる独自の注釈を作成することになっています。
また、利用可能なテンプレートシステムを使用することもできます。たとえば、この例では、アラートの式の値で置き換えられる**{{$ value}}**などを確認できます。これは、通常の文字列値であるラベルでは不可能です。テンプレートエンジンのさまざまな可能性の詳細については、GoのドキュメントまたはPrometheusのドキュメントをご覧ください。
さらに重要な違いが1つあります。ラベルは、関連するアラートをグループ化するために使用されます。ルートの構成のキーgroup_byは、アラートを1つにまとめるために使用されるラベルを設定するために使用されます。つまり、Alertmanagerで構成したエンドレシーバーが1つのバッチでアラートを受信します。
通知テンプレートの変数CommonLabelsには、指定したすべてのラベルが含まれます。ただし、Alerts変数内の個別のアラートには、CommonLabelsに含まれているものを超える追加のラベルが含まれている場合があります。 Alerts変数の個別のアラートには、group_byで指定したもの以外に、追加のラベルが含まれている場合があります。
したがって、特にPrometheusを初めて使用する場合は、ここで間違いを犯しやすいため、アラートルールを作成するときはこの小さな違いに注意してください。
アラートのフラッピングを回避
いくつかのアラートルールを作成した後、それらが継続的に実行され、何度も解決されることに気づいたことがありますか。 これは、アラートルールが、自然に解決されるかどうかを確認するのを待たずに、構成されたレシーバーにアラートを早すぎるために発生する可能性があります。 これをどのように解決しますか?
問題の原因は次のとおりです。
-
アラートルールに「for」句が存在しない(または小さすぎる)および/または
-
アラートルールでの集計操作
まず、アラートルールでは、ほとんどの場合、通知を送信する前にアラートが待機する必要がある時間を示す、ある種の時間コンポーネントを含める必要があります。ネットワーク接続が不完全であるために失敗は避けられないため、これは重要であり、ターゲットのスクレイピングに失敗することがあります。通知を送信する前に、指定された時間アラートがアクティブであることを確認したいので、アラートが1〜2分以内に解決されても、通知されません。また、サービスに対して持つ可能性のあるサービスレベルインジケーター、目的、または合意は、通常、一定期間「費やす」ことができるエラーバジェット、またはサービスが過去に利用可能であったパーセントで定義されます。 同様に、Prometheusなどの監視システムは、トレンドにアラートが出るように設計されています。 Googleの本によると、これらを自動的に生成するSLOの便利なジェネレータを次に示します。
上記の集計操作オプションを使用してこの問題を解決しようとすると、これは式自体に関係するため問題を解決するのが難しい方法であり、変更が難しい場合があることがわかります。このページで説明されている集計関数のいずれかを自由に使用してから、ここで説明されているように、範囲ベクトルで使用される時間範囲を徐々に増やしてください。ただし、たとえば、特定のメトリックが1になった場合に警告する必要がある場合があるため、これは常に適用できるとは限りません。これが前者の方法の出番です。
前に見たように、アラートルールの定義には「for」というフィールドが含まれています。

この図では、「for」の値は10m、つまり10分に相当します。 つまり、Prometheusは、構成されたレシーバーにアラートを発行する前に、アラートが10分間アクティブであることを確認します。 また、デフォルトではアラートルールは1分ごとに評価され、Prometheus構成のEvaluation_intervalパラメータを使用して変更できることに注意してください。
アラートルールはいずれかの方法で2回評価されるため、for句をEvaluation_intervalよりも小さくしても、おそらくあまり意味がないことを認識することが重要です。 「for」句をEvaluation_intervalより小さくしても、実際には「for」句はEvaluation_intervalと「等しい」ことになります。
したがって、通知で不必要にスパムが送信されないように、常にこれら2つのオプションのいずれか(または両方)を検討してください。 通知は常に実行可能である必要があります。
PromQL式に注意する
次に、アラートルールに使用できるPromQL式にある危険について説明します。
メトリックがない
まず、exprフィールドに書き込んだメトリックが特定の時点で存在しない可能性があることに注意してください。 このような場合、アラートルールは警告なしで失敗し始めます。つまり、「発火」することはありません。 この問題を解決するには、欠落している関数で欠落しているメトリックについて警告する追加の警告を追加する必要があります。 「or」バイナリ演算子を使用して、これを元のアラートと合体させるものさえあります。
checker_upload_last_succeeded {instance =” foo.bar”}!= 1 or absent(checker_upload_last_succeeded {instance =” foo.bar”})== 1
ただし、これはほとんどの場合、集計関数を使用せず、単一のメトリックのみを使用する場合に便利です。
カーディナリティのエクスプロージョン
Prometheusは、システムで定義されたすべてのアラートに対して、ALERTSおよびALERTS_FOR_STATEと呼ばれる新しいメトリックを作成します。これらには、アラートの式から生成されたすべてのラベルと、前述のように定義した追加のラベルが含まれています。 ALERTSおよびALERTS_FOR_STATEの目的は、過去に発生したアラートの種類を確認できるようにすることです。ただし、小さな問題が1つあります。元の式に特定のラベルセレクターが含まれていない場合、Prometheusは一致したシリーズごとに数千の新しい時系列を作成する可能性があります。各シリーズには、元の式のラベルとアラートルールで定義した追加のラベルを結合することによって生成された一連のラベルがあります。アラートルールで定義されたラベルは静的ですが、メトリクスのラベルは静的ではありません-これがカーディナリティの問題の原因です。これにより、Prometheusインスタンスが大幅に遅くなる可能性があります。これは、新しい時系列がそれぞれインデックスの新しいエントリに等しくなり、クエリを実行しているときにルックアップ時間が長くなるためです。これは、Prometheusインスタンスで「カーディナリティエクスプロージョン」と呼ばれるものを取得する方法の1つです。警告式があまりに多くの異なる時系列に触れないことを常に検証する必要があります。
たとえば、何千ものメトリックを持つ可能性があるkube-state-metricsのようなものをスクレイピングすることは想像に難くありません。たとえば、Kubernetesクラスタで多数のポッドを実行していて、kube_pod_createdなどの多くのメトリクスがあるとします。メトリックの値は、ポッドがいつ作成されたかを示します。おそらく、kube_pod_created> 1575763200のようなアラートルールがあり、Kubernetesクラスターのメンテナンスウィンドウの開始となる可能性があるポッドが12/08/2019 @ 12:00am (UTC)以降に作成されたかどうかを確認できます。悲しいことに、ユーザーは毎日何千もの新しいポッドを作成し続けるでしょう。この場合、ALERTSとALERTS_FOR_STATEは、Kubernetesクラスター内にあるすべてのポッドの情報(より正確には、ポッドの名前とその名前空間)に一致するため、元の時系列が乗算されます。
これは架空の例ですが、PromQL式のこの側面にある危険性を示しています。結論として、アラート式のラベルセレクターに関して行う決定を意識する必要があります。
巨大なクエリ
最後に重要なことですが、Prometheusインスタンスのすべてのリソースをアラートルールがどのように利用し始めるかについて話しましょう。何十万ものサンプルをメモリにロードするアラートを無意識のうちに書くかもしれません。これは**--query.max-samples**がジャンプする場所です。デフォルトでは、1つのクエリで5000万を超えるサンプルをメモリにロードすることを禁止しています。それに応じて調整する必要があります。この制限に達すると、Prometheusログに次のようなエラーが表示されます。「query processing will load too many samples into memory in query execution(クエリ処理は、クエリ実行でメモリにロードするサンプルが多すぎます)」。これは非常に役立つ通知です!
ただし、通常はクエリが実行され、Prometheusインスタンスの応答が遅くなるまで、問題に気付くことはありません。幸いなことに、Prometheus自体には、通常よりも時間がかかっている可能性があることを示す優れたメトリックがたくさんあります。たとえば、prometheus_rule_group_last_duration_secondsは、最後の時間を評価するのにかかった時間を秒単位で評価するために、ルールグループにアラートを出すことで表示します。ほとんどの場合、このデータを視覚化するGrafanaダッシュボードを作成またはインポートするか、指定したしきい値を超えた場合に通知する別のアラートを実際に作成することができます。アラート式は次のようになります。
avg_over_time(prometheus_rule_group_last_duration_seconds {instance =” my.prometheus.metricfire.com”} [5m])> 20
Prometheusの負荷は時間とともに必然的に変化するため、最後の評価の期間には当然、ある程度のジッターがあるため、ここでは平均の計算を追加する可能性が最も高くなります。
まとめ
PromQLとPrometheusアラートエンジンは、ユーザーにさまざまな機能を提供しますが、それを注意深く使用することが、Prometheusインスタンスの長期的な安定性とパフォーマンスの鍵となります。 アラートルールを作成するときは、この記事でのヒントを覚えておく必要があります。
MetricFireには、独自のアラートルールを作成することを好むお客様と、アラートルールを作成することを好むお客様がいます。 MetricFireがPrometheusのセットアップをどのように支援できるかについて、 [デモを予約]、お問合せください! また、無料トライアルを入手して、数分以内にPrometheusを使用することもできます。