
目次
-
はじめに
-
仕組み
2.1 引数のタイプ
2.2 Range Vector の時間範囲の選択
2.3 計算
2.4 外挿:情報が欠落した際の rate() 関数の挙動
2.5 集計 -
例
3.1 アラートのルール
3.2 SLO の算出
1. はじめに
Prometheusとその問い合わせ言語であるPromQLは、保持しているデータに対して様々な計算を行うための関数を数多く持っています。最も広く使われている関数の1つは rate() 関数ですが、最も間違った理解をされている関数の1つでもあります。
Metricfire が提供するような監視ツールが社内にあれば、必要とされる基本的な機能を提供することができます。重要な機能の1つはトレンドを予測することです。そこで登場するのが、 rate() 関数です。その名前が示すように、ある期間における値の増加率を1秒あたりの平均値で計算することができます。この関数は、例えば、サーバーに送られるリクエスト数が時間の経過とともにどのように変化するか、またはサーバーのCPU使用率を計算したい場合に使用します。まずは、内部の仕組みを理解し、そこから知識を蓄積していきましょう。Prometheusを自身で試してみたい方は、MetricFireのHosted Prometheusの無料の試用版に今すぐ登録してみてください。
2. 仕組み
2.1 引数のタイプ
PromQLには、Range VectorとInstant Vectorという2種類の引数があります。この2つのタイプを図で見ると、次のようになります。
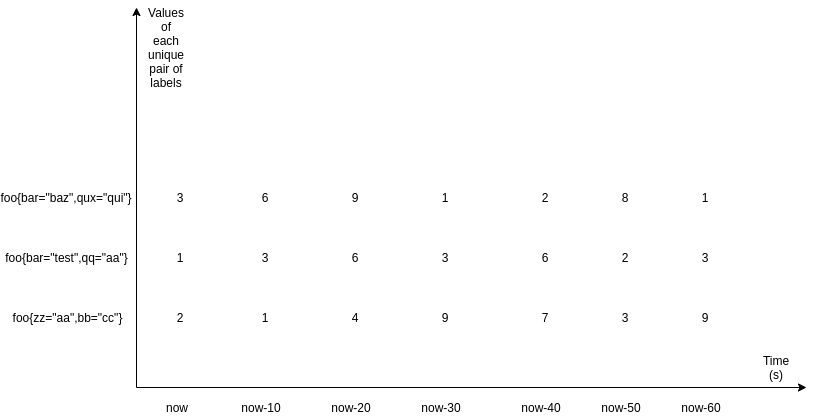
これは3つのRange Vectorのマトリックスで、それぞれが10秒ごとに取得(scrape)された1分間のデータを持っています。このように、ラベル・ペアの一意のセットによって定義されるデータのセットです。Range Vectorには時間の次元 (この場合は1分) もありますが、インスタントベクトルにはありません。Instant Vectorは次のようになります。

このようにInstant Vectorは、最後に取得(scrape)された値のみを定義し、rate() 関数とその関連メソッドは範囲型の引数をとります。これは、どのような種類の変化を計算するためにも、少なくとも2つの時点のデータが必要だからです。それゆえにサンプル数が2未満の場合は、結果はまったく返されません。PromQLは、時間範囲を角括弧で囲んでセレクタの横に記述することによってRange Vectorを示します。直近どのくらいまでの経過データに対して比較を行うかの値を示します。
2.2 Range Vector の時間範囲の選択
これに関しては、どの時間範囲を選択すべきでしょうか。これには模範解答というものはありません。最低限として、取得(scrape)間隔の2倍にする必要はあります。ただし、この場合、結果は非常に「鋭く」なり、値の変更はすべて、他のどの時間範囲よりも速く関数の結果に反映されます。その後、結果はすぐに0に戻ります。時間範囲を長くすると、逆の結果を得ることができます。結果のライン(結果をプロットした場合)は「滑らか」になり、スパイクを見つけるのは難しくなります。そのため、Grafanaでは、時間範囲は変数(例:1m、5m、15m、2h)に入れて管理することをお勧めします。そうすれば、スパイクやトレンドなど、何かを検出しようとしている際に、ケースに最も適した値を選択することができます。
また、Grafanaでは $__interval という特別な変数を使用することもでき、この変数は、時間範囲をステップのサイズで割った値と等しくなるように定義されています。各ステップ間のすべてのデータポイントが考慮されているように見えるので、一見、完璧な解決策のように思えるかもしれませんが、前述した課題は残ります。非常に詳細なグラフと幅広いトレンドを同時に見ることは不可能なのです。また、時間間隔はクエリステップに関連付けられるため、取得(scrape)間隔が変更されると、非常に短い時間範囲で問題が発生する可能性があります。
2.3 計算
他のいずれの関数と同様に、rate() 関数も各ステップで評価されます。とはいえ、どのような仕組みで機能してるのでしょうか。
大まかには次のような計算となっています。
rate(x[35s]) = difference in value over 35 seconds / 35s
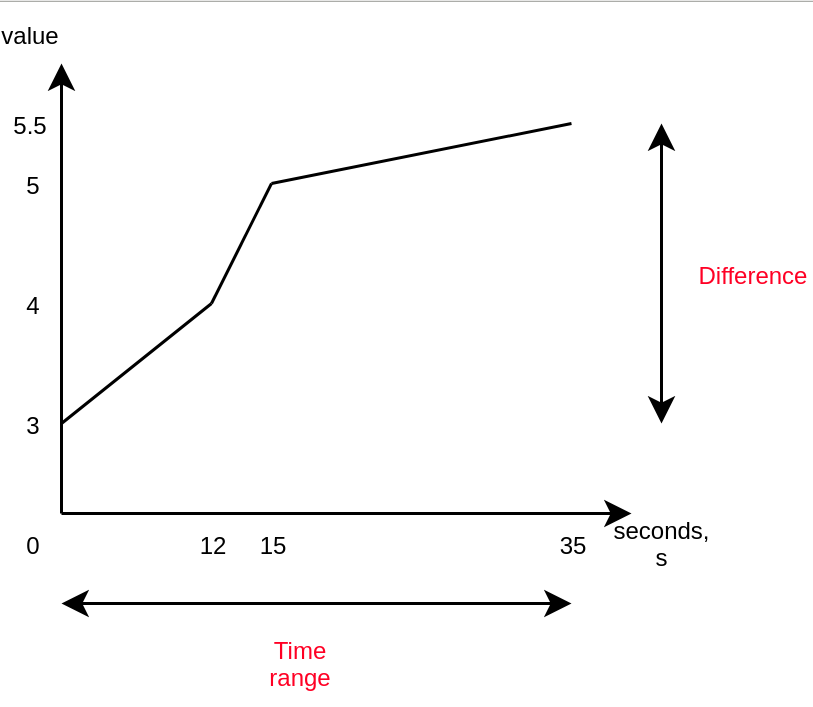
rate()関数の良いところは、最初と最後のデータポイントだけでなく、すべてのデータポイントを考慮するところです。最初と最後のデータポイントだけを使用するirate関数というものは別途存在します。ここで、なぜ delta() 関数を利用しないのかと思われるかもしれません。さて、先ほど説明した rate() 関数にはリセットに合わせて自動的に調整されるという優れた特性がありました。これは、「カウンタ(Counter)」というメトリック型、つまり絶えず増加しているメトリックにのみ適しているという意味と解釈できます。「ゲージ(Gauge)」のようなメトリック型には適していません。また、熱心な読者なら、rate() 関数を使うことは、浮動小数点数がメトリクスの値に使われるという制限を回避するためのハックとなり、制限に達すると浮動小数点数は無限に上昇することができないため、「ロールオーバー」されることに気づいたでしょう。このロジックにより古いデータが失われるのを防ぐことができるため、この機能が必要な場合は rate() 関数を使用することをお勧めします。
注:このリセットの自動調整のため、rate() 関数と一緒に他の集計を使用する場合は、はじめに rate() 関数を適用する必要があります。そうしないと、カウンタのリセットがキャッチされず、意図しない結果となってしまいます。
いずれにせよ、PromQL は現在のところ、「ゲージ(Gauge)」で rate() 関数を使うことを阻止できません。そのため、どのメトリックをこの関数に渡すかを選択するときに、このことを理解しておくことは非常に重要なことです。「ゲージ(Gauge)」に rate() 関数を使用するのは正しくありません。リセット検出ロジックが「カウンタリセット」によって下がった値を誤ってキャッチし、誤った結果を得ることがあるからです。
全体として、次のように変化するカウンタメトリックがあるとします。
- 0
- 4
- 6
- 10
- 2
「10」と 「2」 の間のリセットは、irate() 関数と rate() 関数によってキャッチされ、その後の値は「12」、すなわち、「2」(0から)だけ増加したものと解釈されます。60秒間rate() 関数でレートを計算しようとして、理想的なタイムスタンプでこれら6つのサンプルを取得できたものとすると、1秒あたりの平均増加率は次のようになります。
12-0/60 = 0.2 。すべてがこの状況では完全に理想的であるため、逆算 (0.2*60=12) も成立します。ただし、一部のサンプルが理想的に全範囲をカバーしていない場合、またはサンプル取得(scrape)の間にランダムな遅延が発生により完全に整列できていない場合は、この逆算が常に成立するとは限りません。これについては、次のセクションで詳しく説明します。
2.4 外挿:情報が欠落した際の rate() 関数の挙動
最後に、rate() 関数が外挿を実行することを理解することが重要です。これを知っていれば、長期的に頭を悩まされる心配はなくなるでしょう。rate() 関数がある時点で実行されたとき、一部の取得(scrape)が失敗し、一部のデータが失われることがあります。さらに、ランダム性が追加されることにより、範囲ベクトルの時間範囲の倍数であっても、範囲ベクトルと完全に一致しないことがあります。
このような場合、rate() 関数は、保持しているデータから比率を算出し、情報が欠落している場合は、最初または最後の2つのデータポイントを使用して、選択したウィンドウの開始または終了を推定します。これは、すべてのデータポイントが整数であっても結果が不均等になる可能性があることを意味します。したがって、この関数はトレンド、スパイクの検出、および何かが発生した場合の警告にのみ適しています。
2.5 集計
他の関数と同様に、特定の次元にのみ rate() 関数を適用するという使い方もできます。例えば、rate(foo) by (bar) は、すべてのbar(ラベルの名前)におけるfooの変化率を計算します。これは例えば haproxy を使っていて、異なるバックエンドでのエラー数の変化率を計算したい場合に便利です。以下のような形で記載することができます。
rate(haproxy_connection_errors_total[5m]) by (backend)
3. 例
3.1 アラートのルール
前述したように、rate() 関数は、エラーの量が急増したときにアラートを受け取りたい場合に完璧に動作します。そのため、次のようなアラートを作成することができます。

これにより、いずれかのバックエンドで接続エラーが増加した場合に通知されるようになります。このように、rate() 関数はこういった用途に最適です。お気軽に Metricfire を利用しサービスを監視して、同様のアラートを実装してみてください。
3.2 SLO の算出
rate() 関数のもう1つの一般的な使用例として、SLIの計算と、SLO / SLAに違反していないかどうかの確認があります。Googleは最近、SRE向けの人気のある本をリリースしました。サービスの可用性を計算する方法は次のとおりです。
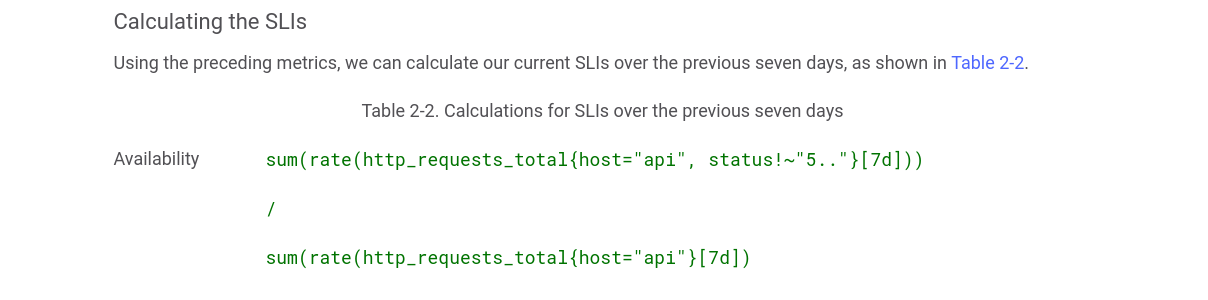
このように、5xx ではないすべてのリクエストの量の変化率を計算し、リクエストの合計量の変化率で 5xxのリクエストを割ります。5xx レスポンスがある場合、結果の値は1未満になります。繰り返しになりますが、何らかの閾値を指定してこの式をアラートのルールで使用すると、超過した場合にアラートを受け取るか、predict_linearを使用して近い将来を予測し、SLA/SLOの問題を回避できます。
詳しくは、 MetricFIreのHosted Prometheus のページをチェックしてみてください。また、試してみたい方は、 Hosted Prometheus の無料の体験版に登録してみてください。デモに予約して、Prometheus の最高のモニタリングソリューションについてお話しすることもできます。