#はじめに
Internet of Things(IoT)とは1つのネットワークに接続された多数の物理デバイスで、システムが外部の世界と対話できるようにします。 状況を知らずに対応することは不可能であるため、IoTを取り巻く多くの作業は監視となります。
たとえば、作物の栽培に最適な条件を維持できる農業用の温室システムを構築する必要があるとします。 この目的のために、温度と湿度に関する情報を取得するセンサーが必要であり、このすべてのデータは自動的に保存および処理され、給水および加熱が可能になるということです。
#ベストなIoT監視スタック
IoTモニタリングに最適なスタックは、PrometheusとGrafana、またはMetricFireによるホストされたPrometheusとGrafanaです。
データの収集、保存、処理はPrometheusで実行でき、視覚化はGrafanaで実行します。この記事では、PrometheusとGrafanaの基本については詳しく説明しません。代わりに、これらのツールを使用して優れたIoTダッシュボードを作成するために知っておく必要があることに焦点を当て解説していきます。
基本について詳しく知るには、こちらのPrometheusを基礎から解説の記事と、Grafanaを基礎から解説 〜実際に導入までしてみる〜の記事を読んでください。
この記事では、エッジデバイスをPrometheusおよびGrafanaに接続する方法についても触れません。 MetricFireをIoTデバイスに接続する方法については、Raspberry Pi 4の監視に関する記事をご覧ください。
特に大規模なIoTモニタリングの場合、MetricFireによるHosted Prometheusによるモニタリングを検討する必要があります。 Hosted Prometheusは、自動スケーリング、更新、プラグイン、Grafanaダッシュボードなどを提供します。ここでMetricFireの無料トライアルにサインアップし、IoTダッシュボードの構築を開始する必要があります。
それでは、IoTの監視の背後にある中心的な概念を見て、IoTシステムを監視するためにGrafanaでダッシュボードを構築する方法を学んでいきましょう。
#IoTモニタリングが必要な理由
私たちのIoTシステムが完全に自動化され、人間が何もする必要がないようになっているとしたら、すばらしいと思いませんか? そしたらダッシュボードも必要なくなるでしょう。
理想的には、私たちのIoTシステムへの人間の関与は0です。しかし、この世界は完璧ではないことは誰もが知っています。 IoTシステムは、気象、機械的損傷、さらにはバッテリー電源に対して脆弱な数百の敏感なコンポーネントで構成されているため、現時点で人間が関与しないことは難しいでしょう。
プロダクションパイプラインの他の部分も分割される可能性があり、一般的です。 これは、人と機械の両方が原因である可能性があります。 さらに、完全に自動化されている企業はほとんどないため、人間はIoTシステムの監視と運用に参加する必要があるのです。
#スマートホームの監視
例として、家庭で圧力、温度、湿度を測定するシステムを監視し、すべてのデータをPrometheusに保存し、それをGrafanaで視覚化します。 以下に、これを実装する方法の可能なスキーマを示します。
ご覧のように、3つのSensorからのデータをハブにそしてAPIエンドポイントにMQTTまたはHTTPSを介して送信します。
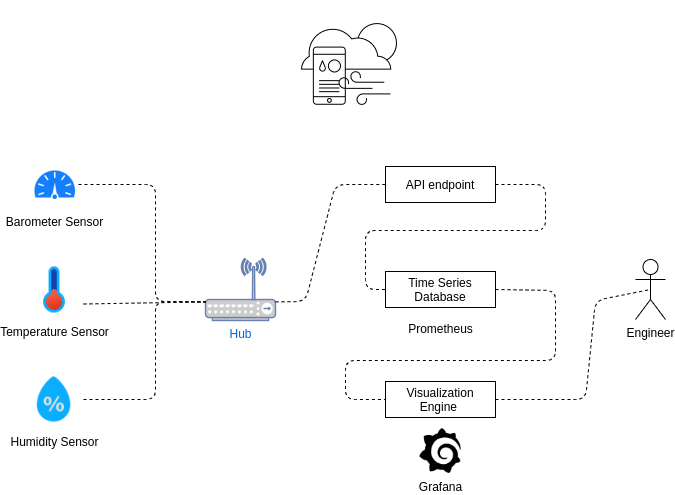
クラウドサービスまたはPrometheus Pushgatewayを使用して、データベースにデータを保存できます。 より複雑なタスクでは、データを集計するためにStatsDも必要になる場合があります。 次に、GrafanaをPrometheusに接続して、ダッシュボードを作成します。
#IoT監視のアーキテクチャ
監視戦略は、状況ロジックとインフラという2つの主要なカテゴリに分類できます。
##インフラ
最初にインフラストラクチャの部分について説明しましょう。 センサーデバイスは壊れやすく、ネットワークの問題やアーキテクチャの不良が原因で、放電したり、パッケージが失われたりする可能性があります。 そのため、各センサーから受信する頻度、数、およびデータを監視する機能が必要です。
この種のデータを使用して、破損したセンサー、放電したセンサー、またはデータを失ったセンサーを検出できます。 また、問題を解決するように専門家に通知するアラートがあると役立ちます。 これらの分析により、この量のデータを処理するために本当に必要なインフラストラクチャを推定することもできます(これは、何千ものセンサーを備えた巨大なシステムにとって重要です)。
##状況ロジック
適切な状況ロジックがあると、状況に重要な事柄を監視するのに役立ちます。たとえば、スマートホームからデータを監視している場合、このデータは、あなたが家にいる間だけ計算するのが理にかなっています(家に誰もいない場合は、空気を冷却したり、適切な温度に加熱したりすることは意味がありません)。
また、家の温度を低くしていても問題のない夜間など、特定の時間の値を計算することにも意味があります。
一部のメトリック値でアラートを作成することも意味があります。たとえば、最適な湿度の最小値は40%で、最大値は約70%です。 70%を超える湿度値を測定する場合、ダッシュボードで通知する必要があります。
最適なダッシュボードを構築するには、監視するデバイスの数と抽出するデータを決定する必要があります。スマートホームの例では、温度と湿度の履歴を持つことはそれほど重要ではありません。
ここでは、主に現在の温度、または少なくとも1日の現在の温度を気にします。別のケースでは、農業セクターのIoTは、歴史的傾向のダッシュボードを必要とする場合があります。
#監視するメトリックス
例として、以下のメトリックを監視していきます。
- humidity_gauge_percent
- pressure_gauge_pa
- temperature_gauge_c
多くの場合、メトリック名にメトリックの単位を取り込むことをお勧めします。 このプラクティスは、上記のメトリック名に示されています。 詳細については、メトリックの命名に関するPrometheusのドキュメントを参照してください。
これらの指標をPrometheusに取り込むには、上図で視覚化されたAPIエンドポイントを取得するようにPrometheusを設定する必要があります。 これを行う1つの方法については、こちらのチュートリアルをご覧ください。
すべてのデータのクエリと操作には、PromQLを使用します。 ここではいくつかの基本について説明しますが、この記事を読んでPromQLをよく理解することをお勧めします。
それでは、ダッシュボードの作成から始めましょう。
#IoTダッシュボードの構築
ダッシュボードの作成を開始するには、ホームページの左側にあるプラス記号に移動し、新しいダッシュボードを追加します。 次に、新しいパネルを追加し、クエリを追加します。 下の画像で新しいダッシュボードの始まりを確認できます。
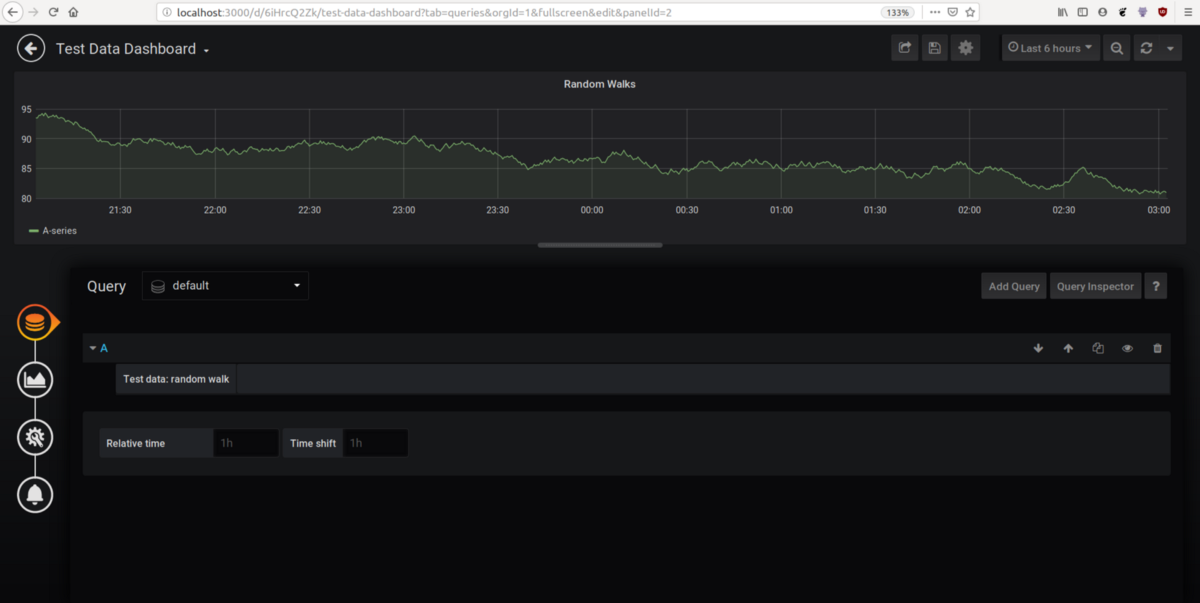
Grafanaダッシュボードを最初から作成する方法の詳細については、こちらのチュートリアル全体をお読みください。
IoTダッシュボードクエリでは、Prometheusデータベースにクエリを実行するため、上記のメトリック名を使用してデータベースにクエリを実行します。
メトリック名のみをクエリすることで、「humidity_gauge_percent」のクエリの作成を開始します。 条件とセンサーによっては、「humidity_gauge_percent」の基本的なPromQLクエリだけを実行すると、データにノイズが含まれ、次のような結果が得られる可能性があります。
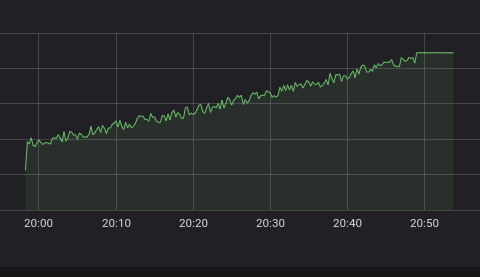
ノイズを除去したい場合は、メトリックをクエリするときに次のPromQL関数を適用できます。 次のクエリをクエリ式フィールドに書き込むだけです。
avg_over_time(humidity_gauge_percent[5m])
このPromQL式は、クエリを2つの方法で変換します。
- 1つ目は「[5m]」で、データベクトルを範囲ベクトルに分割するだけです。 各時点で、範囲ベクトルは5mの値の配列を保持します。 (おそらくご存じのとおり、これはタイムスタンプ付きのシリーズではないため、湿気_ゲージ_パーセント[5m]だけを表示することはできません。値はグループ化されたサブシリーズです。)
- 次に、時間の経過に伴う平均を取ります。
その結果、次のようになります。
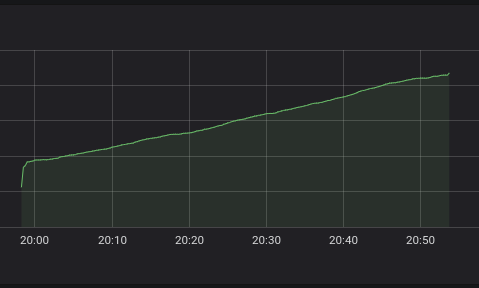
上のグラフははるかに滑らかで、データの適用が簡単です。 クエリの凡例を指定しない場合、以下のような自動生成された凡例が表示されます。

Prometheusで直接クエリを実行して、まったく同じ情報を見つけることもできます。 Prometheus式ブラウザーに移動し、次に[ラベル]列の[Prometheus Status]> [Target]ページに移動すると、同じメトリックが表示されます。

そのメトリックに関連付けられているラベルが表示されるため、これは注目すべきです。
#PromQLを使用したクエリでの関数のフィルタリング、集計、使用
###クエリのフィルタリング
前のセクションの最後の画像に表示されているものなど、ラベルでメトリックをフィルタリングできます。 特定のインスタンスをクエリするには、メトリック名の後に中かっこを追加し、等号で区切って検索するKey-Valueペアを指定するだけです。 例えば:
humidity_gauge_percent{instance="localhost:8000"}
変数を使用して、現時点で視覚化するインスタンスを決定できることに注意してください。 この詳細については、ドキュメントをご覧ください。 変数はカスタムにすることも、事前に定義しておくこともできます。 これは、部屋や地域ごとに集約されたダッシュボードを作成するために使用できる非常に強力な機器です。 ただし、この例では、センサーごとにインスタンスが1つしかないため、このアプリケーションは現在使用しません。
###クエリで関数を使用する
必要に応じて、単純な線形回帰モデルを適用して、将来の価値を予測することもできます。
predict_linear(humidity_gauge_percent [10m]、300)
この例では、将来の300秒の値を10分の範囲で予測します。 predict_linearはゲージでのみ使用する必要があります。 ダッシュボードが上限のnow +(予測間隔)で動作することを確認してください。そうしないと、予測が失われます。 また、境界は各パネルではなくダッシュボード全体にインストールされることも知っておく必要があります。
もう1つの優れた機能は変更機能です。
changes(humidity_gauge_percent[1m])
この関数は、指定された時間範囲(この場合は1分)あたりの変更数を表示します。 これから何が得られますか? データが長期間変更されていない場合、問題の可能性が高いことがわかります。
また、電力量などのセンサーステータス情報など、ネットワーク情報に関連するいくつかのメトリックを収集することをお勧めします。 これらは、危険ゾーンにあるセンサーが壊れるのを検出するのに役立ちます。
###クエリの集計
多くの場合、各インスタンスのデータと集計データが必要です。 PromQLのいくつかの集計演算子は次のとおりです。
- sum - calculate sum over dimensions
- min - select minimum over dimensions
- max - select maximum over dimensions
- avg - calculate the average over dimensions
- stddev - calculate population standard deviation over dimensions
- stdvar - calculate population standard variance over dimensions
- count - count number of elements in the vector
- count_values - count number of elements with the same value
- bottomk - smallest k elements by sample value
- topk - largest k elements by sample value
- quantile - calculate φ-quantile (0 ≤ φ ≤ 1) over dimensions
たとえば、bottomkを使用すると、家の中で最も冷たい部屋からシリーズを選択できます(複数の温度計センサーがある場合)。 構文は公式ドキュメントにありますが、使用例は次のとおりです。
bottomk (2, temperature_gauge_c)
これにより、最低温度の2つのシリーズが返されます。 「without」または「by」のキーワードを含むラベルで集約をグループ化することもできます。
注:集計演算子は、前に見たクエリ関数とは異なります。 これらの演算子は、ディメンションごとにデータを集計します(ディメンションはラベルです)。 一方、クエリ機能は、5分ごとなどの時間範囲でデータを操作します。
###しきい値の設定
次のステップは、チャートのしきい値を設定することです。 [Visualization]タブに移動して、以下を構成します。
しきい値が設定されている場合、値が特定の制限を超えるとゲージの色が変化します。 できるだけ早く反応するようにアラートルールを設定した方が良いでしょう。
次のクエリを使用して、インスタンスが正常かどうかを検出できます。
up {job = "<job-name>"、instance = "<instance-id>"}
このクエリを使用して、インスタンスが正常かどうか、つまり到達可能かどうか、またはスクレイピングが失敗した場合は0かどうかを確認します。
###適切な視覚化タイプ
データとニーズに適した視覚化タイプを使用することを忘れないでください。 たとえば、グラフは複数の値、傾向の検出、比較に適しています。 ゲージは、いくつかの集計データ、現在の値を表示し、現在の値としきい値との関係を視覚化するのに最適です。
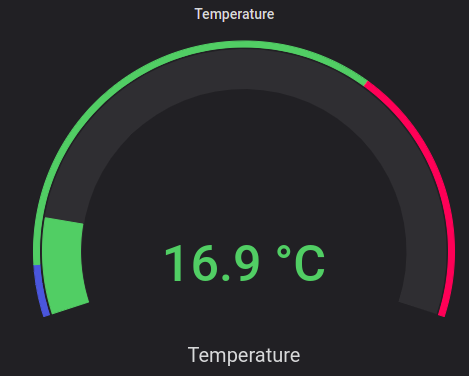
#まとめ
センサーは大量の有用な情報を生成し、それを処理するにはダッシュボードが必要です。 IoTの仕様では、一部のデバイスのインスタンスが複数あることが多いため、各グループとインスタンスを個別に監視しながら、できるだけ多くの変数を取得できるように、特定の変数を適用する必要があります。
センサーは非常に壊れやすいため、状況メトリックだけでなく、センサー自体を注意深く監視する必要があります。 問題を検出するだけでなく、できるだけ迅速に対応することも重要です。 そのため、システムの状態について常に通知されるようにアラートシステムを構成する必要があります。
ご覧のとおり、システムの設定にはかなりの作業が必要です。 構成時間を短縮するには、MetricFireの無料トライアルを使用して、PrometheusとGrafanaを実行します。 デモを予約して、IoTダッシュボードを最適に設定する方法について直接お問い合わせください。