はじめに
クラウドネイティブアーキテクチャとマイクロサービスのトレンドの背後には、技術的な複雑さ、パラダイムシフト、そして厳しい学習曲線があります。この複雑さは、設計、デプロイ、セキュリティだけでなく、Kubernetes のような分散システムで実行されるアプリケーションの監視と監視性に関わるすべてのことに現れています。幸いなことに、開発者がこれらの障害を克服するのに役立つツールがあります。例えば、監視性のレベルでは、オープンソースのPrometheusやGrafanaのようなツールが、開発者のコミュニティに多大な助けを提供してくれます。
この記事では、KubernetesでPrometheusとGrafanaを使用する方法を見ていきます。Prometheusがどのように機能するのか、そしてカスタムダッシュボードを作成する方法を見ていきます。その後、いくつかの概念に飛び込み、本番でどのメトリクスを見るべきか、そして、それをどのように設定するのかについて話します。
PrometheusとGrafanaを使い始める簡単な方法は、MetricFireの無料トライアルにサインアップすることです。MetricFireはPrometheusとGrafanaのマネージドサービスを提供しています。
インストールと設定
最初に Kubernetes クラスタを実行する必要があります。他の記事で紹介したようなMinikubeクラスタを使用することもできますし、GKEのようなクラウドマネージドソリューションをデプロイすることもできます。この記事ではGKEを使用します。
また、Grafana と Prometheus のデプロイには Helm を使用します。Helm は Kubernetesのパッケージマネージャで、Debian の APT のようなものです。CNCF は Microsoft、Google、Bitnami、そして Helm のコントリビューターコミュニティと協力してプロジェクトを維持しています。
Helmの助けを借りて、「Helm Charts」を使いKubernetesアプリケーションを管理することができます。Helm Chartsの役割は、Kubernetesアプリケーションの定義、インストール、アップグレードです。
Helmコミュニティでは、Helm hub上でチャートを開発し、共有しています。ウェブサーバ、CI/CDツール、データベース、セキュリティツールからウェブアプリまで、Helm hubはKubernetes対応アプリの分散リポジトリをホストしています。
Helmをインストールするには、まず最新のバージョンをダウンロードして解凍し、"helm "のバイナリを"/usr/local/bin/helm "に移動させます。
mv linux-amd64/helm /usr/local/bin/helm
MacOSユーザーはbrew install helmを使用でき、WindowsユーザーはChocolatey choco install kubernetes-helmを使用できます。 Linuxユーザー(およびMacOSユーザー)は、次のスクリプトを使用できます。
curl -fsSL -o get_helm.sh https://raw.githubusercontent.com/helm/helm/master/scripts/get-helm-3 chmod 700 get_helm.sh ./get_helm.sh
Helmを使用して、Prometheusオペレーターを別の名前空間にインストールします。
Prometheusコンテナーを別のnamespaceで実行することをお勧めします。そこで、namespaceを作成しましょう。
kubectl create ns monitor
次に、Prometheusオペレーターのインストールを続行します。
helm install prometheus-operator stable / prometheus-operator --namespace monitor
「prometheus-operator」はreleaseの名前です。 必要に応じてこれを変更できます。
「stable / prometheus-operator」はチャートの名前です。
「monitor」は、オペレーターをデプロイするnamespaceの名前です。
kubectl get pods -n monitor
Prometheus Alertmanager、Grafana、kube-state-metricsポッド、Prometheusノードエクスポーター、Prometheusポッドが表示されるはずです。
NAME READY STATUS RESTARTS AGE
alertmanager-prometheus-operator-alertmanager-0 2/2 Running 0 49s
prometheus-operator-grafana-5bd6cbc556-w9lds 2/2 Running 0 59s
prometheus-operator-kube-state-metrics-746dc6ccc-gk2p8 1/1 Running 0 59s
prometheus-operator-operator-7d69d686f6-wpjtd 2/2 Running 0 59s
prometheus-operator-prometheus-node-exporter-4nwbf 1/1 Running 0 59s
prometheus-operator-prometheus-node-exporter-jrw69 1/1 Running 0 59s
prometheus-operator-prometheus-node-exporter-rnqfc 1/1 Running 0 60s
prometheus-prometheus-operator-prometheus-0 3/3 Running 1 39s
ポッドが実行されたので、ローカルマシンから直接Prometheusダッシュボードを使用するオプションがあります。 これは、次のコマンドを使用して行われます。
kubectl port-forward -n monitor prometheus-prometheus-operator-prometheus-0 9090
ここで
http://127.0.0.1:9090
にアクセスして、Prometheusダッシュボードにアクセスします。
Prometheusと同じように、このコマンドを使用してGrafanaダッシュボードにアクセスできるようにすることができます。
kubectl port-forward $(kubectl get pods --selector=app=grafana -n monitor --output=jsonpath="{.items..metadata.name}") -n monitor 3000
http://127.0.0.1:3000
にアクセスすると、いくつかのデフォルトの事前設定されたダッシュボードがあることがわかります。

ログインには「admin」、パスワードには「prom-operator」を使用する必要があることに注意してください。 どちらもKubernetes Secretオブジェクトにあります。
kubectl get secret --namespace monitor grafana-credentials -o yaml
エンコードされたログインとパスワードのYAML記述を取得する必要があります。
apiVersion: v1 data: password: cHJvbS1vcGVyYXRvcgo= user: YWRtaW4=
次を使用して、ユーザー名とパスワードをデコードする必要があります。
echo "YWRtaW4=" | base64 --decode echo "cHJvbS1vcGVyYXRvcgo=" | base64 --decode
「base64 --decode」を使用すると、明確な資格情報を確認できます。
Kubernetes用の事前構成されたGrafanaダッシュボード
デフォルトでは、Prometheusオペレーターには事前構成されたGrafanaが付属しています-以下のような一部のダッシュボードはデフォルトで使用できます。
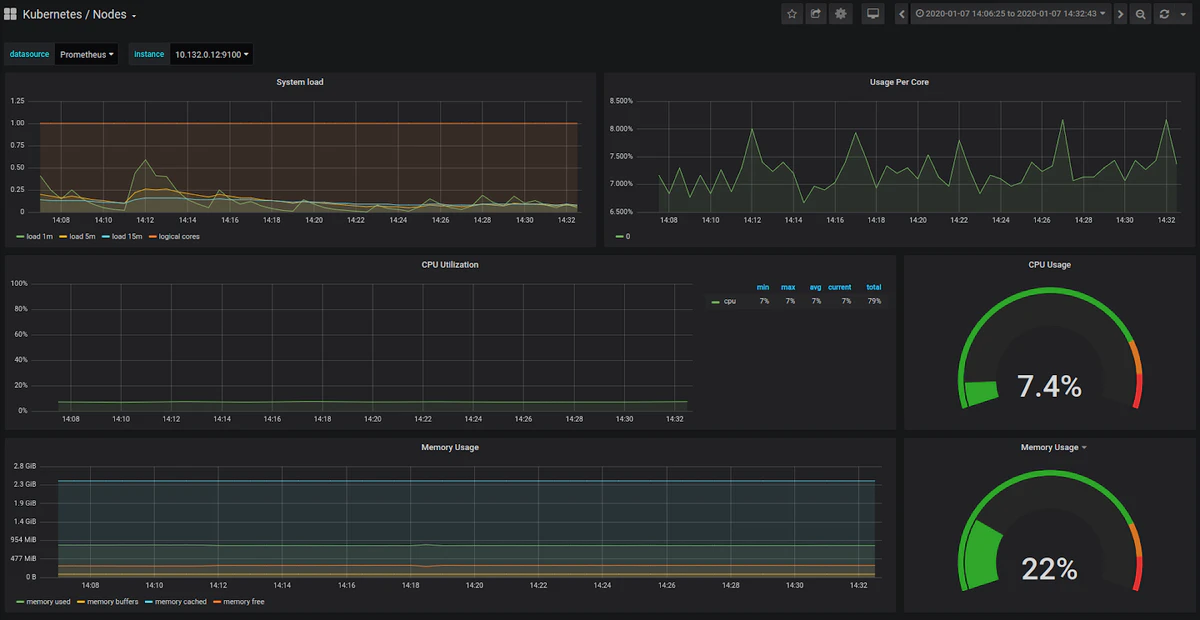
これらのデフォルトのダッシュボードには、「Kubernetes / Nodes」、「Kubernetes / Pods」、「Kubernetes / Compute Resources / Cluster」、「Kubernetes / Networking / Namespace(Pods)」、「Kubernetes / Networking / Namespace(Workload)」、 等があります。
これらのダッシュボードの詳細については、こちらをご覧ください。 たとえば、「Kubernetes / Compute Resources / Namespace(Pods)」ダッシュボードがどのように機能するかを確認したい場合は、このConfigMapを表示する必要があります。 Grafanaによる視覚化の詳細については、お気に入りのGrafanaダッシュボードの記事をご覧ください。
Helmインストールの結果として使用可能なメトリック
Prometheusの仕組みを理解するために、Prometheusダッシュボードにアクセスしてみましょう。 次のポート転送コマンドを使用します。
kubectl port-forward -n monitor prometheus-prometheus-operator-prometheus-0 9090
次に、http://127.0.0.1:9090/metrics
にアクセスします。メトリックの長いリストを表示できます。
Prometheusは、ユーザーが時系列データをリアルタイムで選択して集計できる関数クエリ言語であるPromQL(Prometheus Query Language)を使用します。 特に包括的な学習を開始する場合、PromQLは複雑になる可能性がありますが、公式ドキュメントからこれらの例を使用して始めると、その大部分を理解できます。 PromQLの詳細については、PromQLの10の主要な例を示す優れた記事をご覧ください。
Helmを使用してPrometheusをデプロイしたとき、このチャートを使用しました。実際には、Prometheusだけでなく、次のものもデプロイされています。
- prometheus-operator
- prometheus
- alertmanager
- node-exporter
- kube-state-metrics
- grafana
- service monitors to scrape internal kubernetes components
- kube-apiserver
- kube-scheduler
- kube-controller-manager
- etcd
- kube-dns/coredns
- kube-proxy
Prometheusに加えて、内部システムメトリックをこすり落とすサービスモニターなどのツールと、「kube-state-metrics」などの他のツールを含めました。
kube-state-metricsは、Prometheusサーバーが読み取ることができる情報もエクスポートします。 これらのメトリックのリストは、実行後に
http://127.0.0.1:8080/metrics
にアクセスすると確認できます。
kubectl port-forward -n monitor prometheus-operator-kube-state-metrics-xxxx-xxx 8080
本番環境で監視する重要なメトリクス
PrometheusをGrafanaのデータソースとして設定したので、どのメトリックを監視する必要があります。監視をしていく方法のアイデアはありますか?
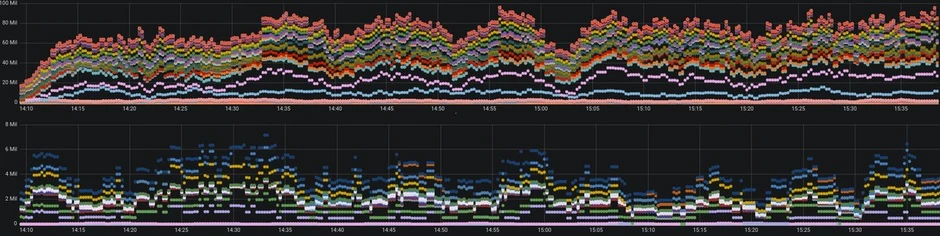
Grafanaで利用できるデフォルトのダッシュボードは多数あります。 デフォルトのダッシュボード名は一目瞭然なので、クラスターノードに関するメトリックスを表示するには、「Kubernetes / Nodes」を使用する必要があります。 以下のダッシュボードはデフォルトのダッシュボードです。
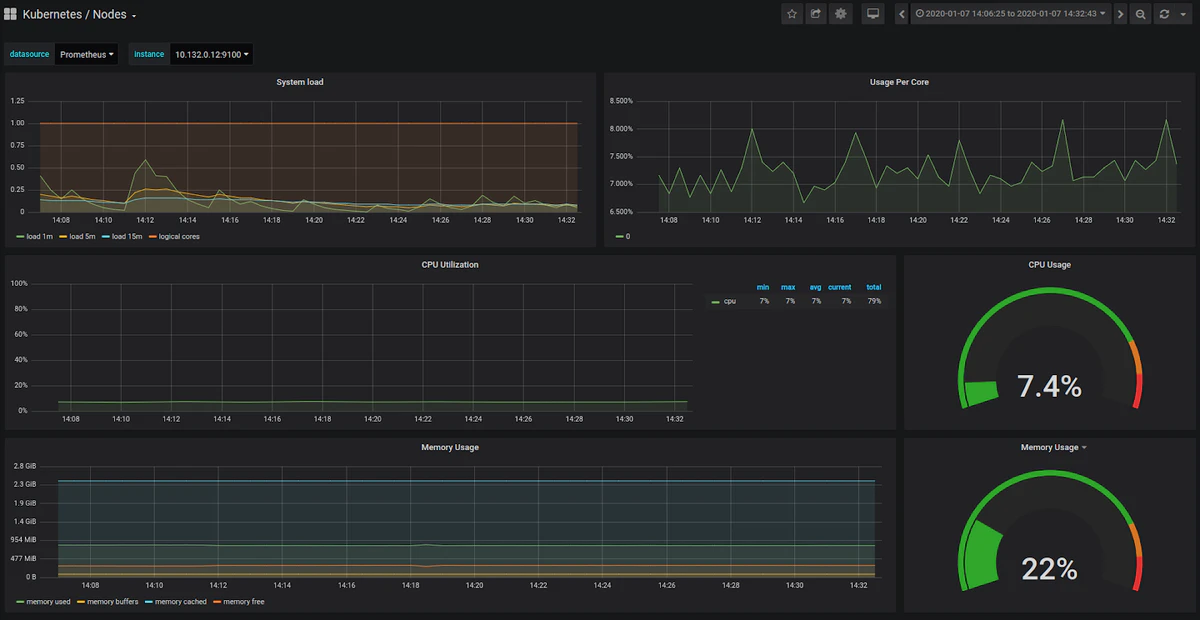
minikubeまたはその代替手段の1つを使用していない限り、Kubernetesクラスターは通常、複数のノードを実行します。 一度に1つずつ選択して、すべてのノードを監視していることを確認する必要があります。
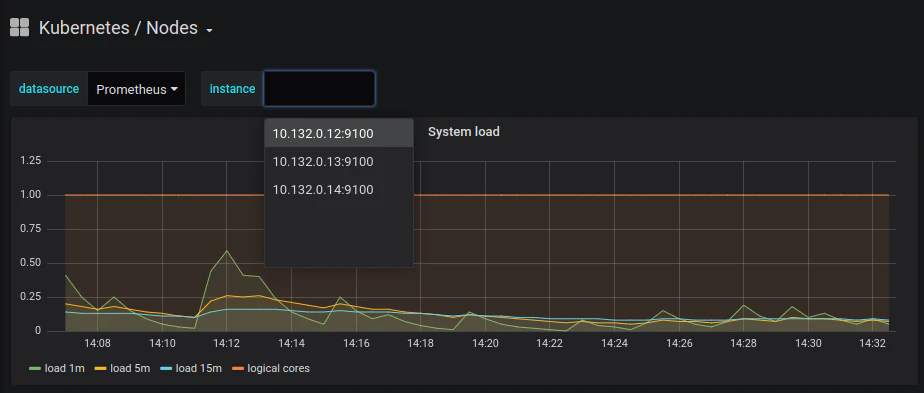
同様のConfigMapマニフェストを使用して、または直接Grafanaダッシュボードインターフェースを使用して、独自のダッシュボードを追加することが可能です。 「Create dashboard」UIの下に表示されます。
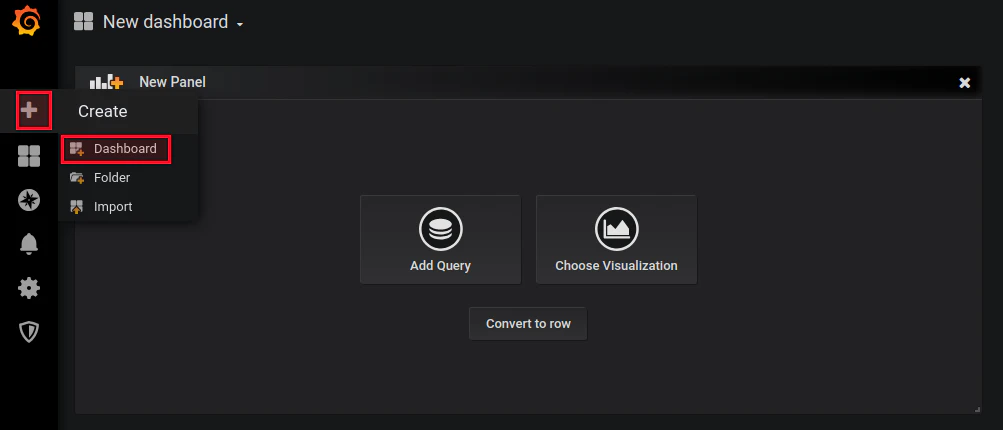
新しいカスタムダッシュボードを作成するときに、Add Queryするか、Choose Visualizationを尋ねられます。 Choose Visualizationを選択すると、グラフのタイプとデータソースを選択するよう求められます。 データソースとしてPrometheusを選択します。 また、Prometheusをデータソースとして使用してクエリを追加することもできます。
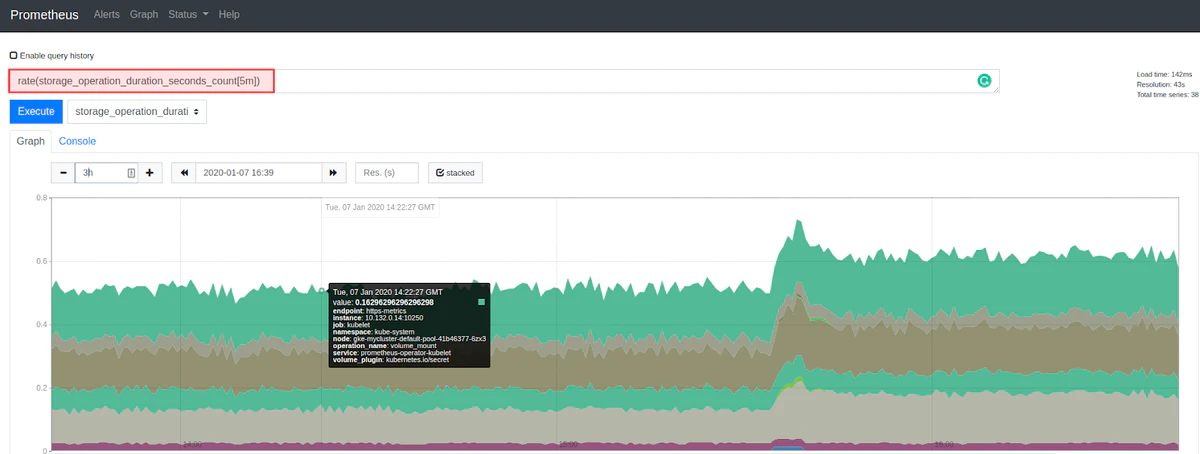
例として、グラフを設定して、エンドポイントごとのKubernetes APIへのHTTPリクエストの数に関する情報を提供するprometheus_sd_kubernetes_http_request_totalメトリックを監視できます。
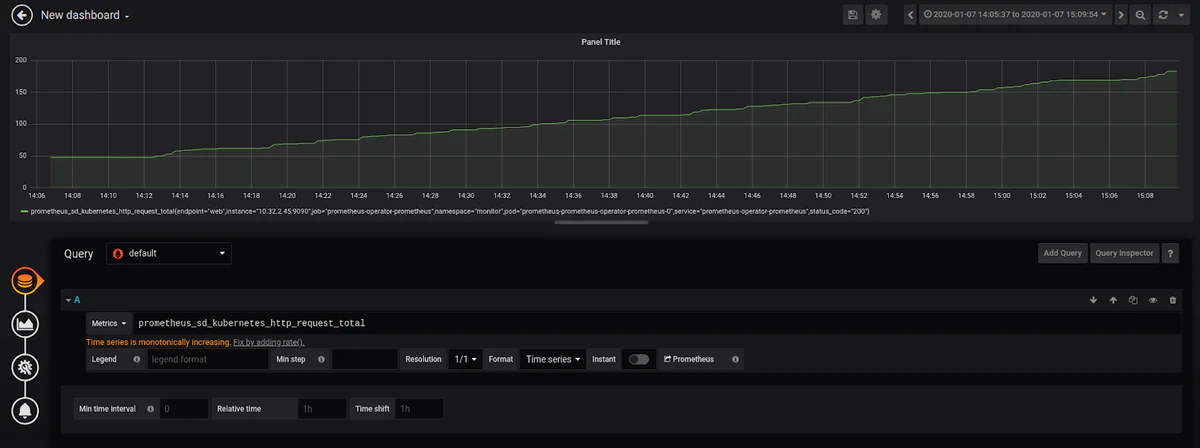
このメトリックは累積的であるため、Grafanaは、関数に関するより詳細な情報を提供する関数rate()を使用するかどうかを確認してきます。
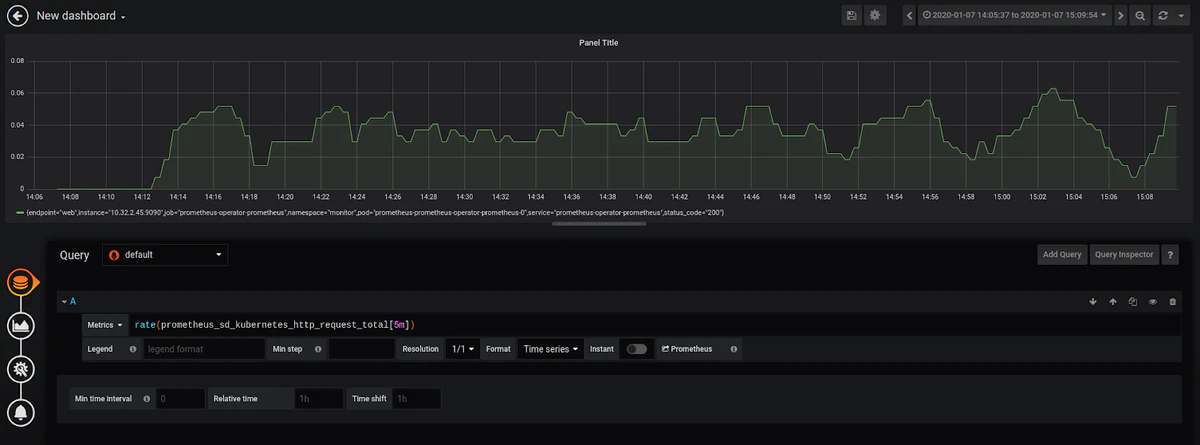
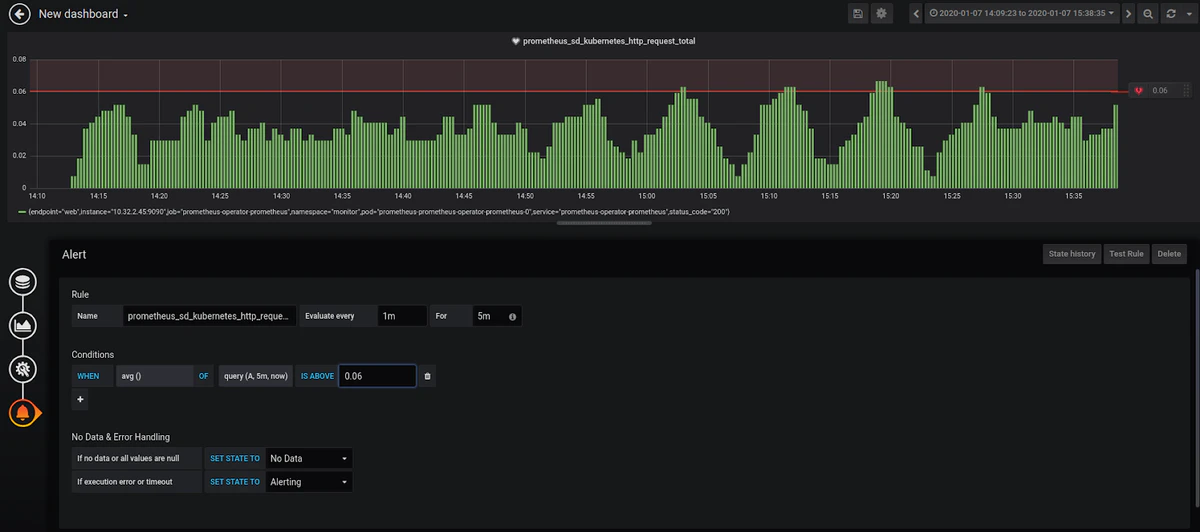
Visualizationの名前を設定した後、アラートを設定できます。 選択したメトリックの平均が「0.06」を超えないようにするとします。
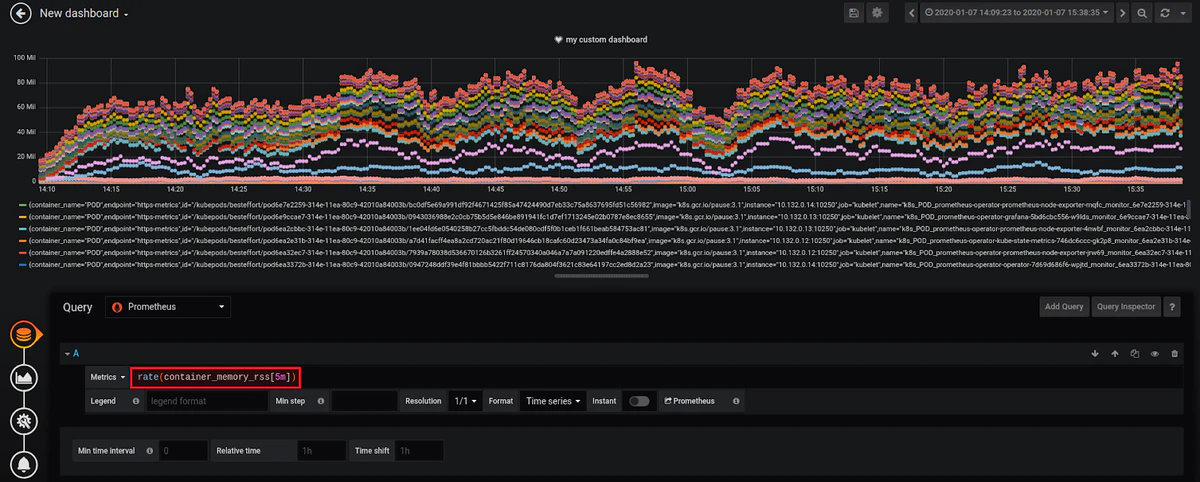
Kubernetesシステムコンテナーのレジデントセットサイズ(RSS)などの、より重要なメトリックを選択してみましょう。(RSSは、メインメモリ(RAM)に保持されているプロセスによって占有されているメモリの部分です)。 以下のダッシュボードをご覧ください。
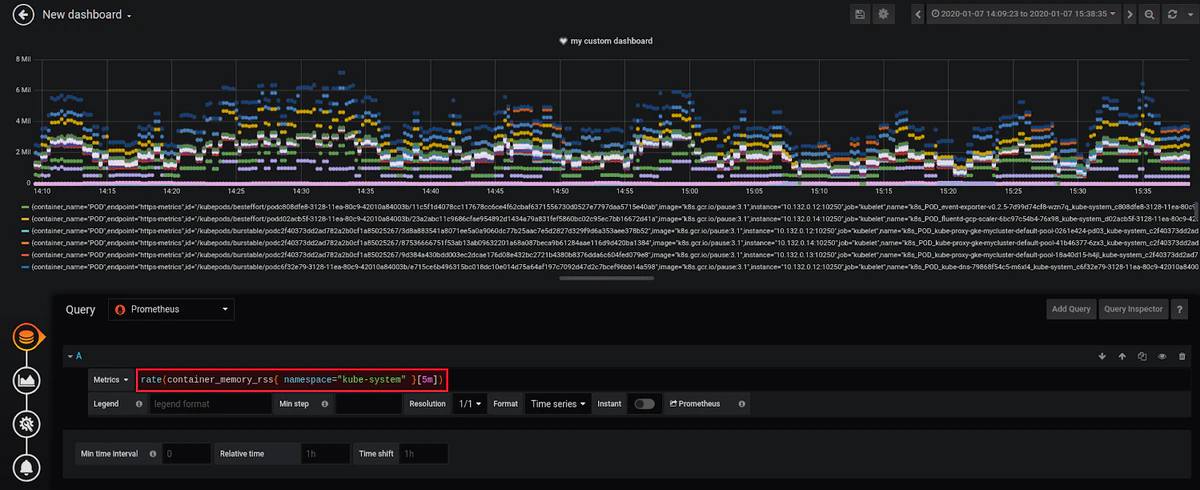
場合によっては、一部のビューが過剰に配置されていることがあります。この例では、システムコンテナーを監視する必要があるため、namespaceでフィルタリングしてダッシュボードを調整できます。
コンテナーの再起動の総数など、3番目に重要な指標を見てみましょう。 この情報には、特定のnamespaceのkube_pod_container_status_restarts_totalまたはkube_pod_container_status_restarts_total {namespace = ""}を使用してアクセスできます。
本番環境では、他にも多くの重要なメトリクスがあります。 それらのいくつかは一般的で、ノード、ポッド、Kube API、CPU、メモリ、ストレージ、およびリソースの使用全般に関連しています。 これらはいくつかの例です:
- kube_node_status_capacity_cpu_cores:ノードのCPU容量について説明します
- kube_node_status_capacity_memory_bytes:ノードのメモリ容量について説明します
- kubelet_running_container_count:現在実行中のコンテナの数を返します
- cloudprovider _ * _ api_request_errors:クラウドプロバイダーAPIリクエストエラー(GKE、AKS、EKSなど)を返します
- cloudprovider _ * _ api_request_duration_seconds:クラウドプロバイダーAPI呼び出しのリクエスト期間を秒単位で返します
デフォルトのメトリックに加えて、Prometheusインスタンスは、kube-apiserver、kube-scheduler、kube-controller-manager、etcd、kube-dns / coredns、kube-proxy、および「 kube-state-metrics」。 取得できるデータの量は膨大であり、必ずしも良いことではありません。
リストは長くなりますが、重要なメトリックはコンテキストによって異なる可能性があります。Etcdメトリックは、他の誰かにとっては本番環境にとって重要ではないと考える場合があります。
ただし、GoogleゴールデンシグナルやUSEメソッドなどの抽象化と可観測性の優れた手法は、監視する必要があるメトリックを選択するのに役立ちます。
Prometheusの使用を検討している方、質問がある方は、是非MetricFireのデモを予約してご相談ください(日本語可)。また、MetricFireの無料トライアルにて、PrometheusとGrafanaを実際にご使用になって、この記事の内容を実践してみてください。
それでは、またの記事で!