WARNING: これはNeural Networkの入門ではありません。深層学習をある程度知っているという前提です。And i'm sure my Japanese make less sense sometime, bear me
背景と目標
Deep Learningをある現実問題に適用しょうとして、データの複雑さ、関連性などでの原因ですごく複雑なNNネットを設計してしまったとき、Kerasにまだ慣れっていないひとはそれをKerasで実装するに難しいと思います。
よくある「作りたい」構造の一つとして、図1のようなNNを作ります。

図1:Mult-blocks Neural Network for multiple inputs and single ouput
それはInception Layerではないかと思う人もおると思います、確かに図1のNN1、NN2などブロックが1層ぐらいだと同じです。

図2:Inception Layer
Q1:何でこんな構造作るんですか:
A1:現実では問題に対して集められたデータがすべて同じく対応するには行かない、データのドメインが違ったり、物理意味が違ったりするによって、すべてを同じ扱い(only one NN)は効率が悪い、だが各データに対してNNを独立するには行かない(システムとして各NNの誤差が別物になってしまう)、そいうときこそ、図1のよな構造が必要
NNブロックを作成
説明しやすくするために、cifar10を目標データとして作ります。
準備
import tensorflow as tf
from keras.datasets import cifar10
from keras.models import Model, Sequential
from keras.layers import Input, Dense, Dropout, Activation, Flatten
from keras.layers import Conv2D, MaxPooling2D, BatchNormalization
from keras.utils import np_utils
from keras import backend as K
from keras.layers import add, concatenate
ksess = K.get_session()#Graphを読み出すために
以上でLibの参照は終わる
NNブロックを作る
目標は結果がいいモデルということではないので、適当なCNNモデルを作ります。
Block #1
with tf.name_scope("NN1_Block"):
NN1= Sequential()
NN1.add(Conv2D(32, (3, 3), padding='same', input_shape=(32,32,3)))
NN1.add(Activation('relu'))
# NN1.add(BatchNormalization())#グラフの繋がりが分からなくなりますので、ここで取っていきます、実際では使います
NN1.add(Conv2D(filters=32, kernel_size=(3,3), padding='same'))
NN1.add(Activation('relu'))
# NN1.add(BatchNormalization())#グラフの繋がりが分からなくなりますので、ここで取っていきます、実際では使います
# NN1.add(Dropout(0.2))#グラフの繋がりが分からなくなりますので、ここで取っていきます、実際では使います
NN1.add(Conv2D(filters=32, kernel_size=(3,3), padding='same'))
NN1.add(Activation('relu'))
# NN1.add(BatchNormalization())#グラフの繋がりが分からなくなりますので、ここで取っていきます、実際では使います
NN1.add(Conv2D(filters=32, kernel_size=(3,3), padding='same'))
Block #2
with tf.name_scope("NN2_Block"):
NN2= Sequential()
NN2.add(Conv2D(32, (3, 3), padding='same', input_shape=(32,32,3)))
NN2.add(Activation('relu'))
# NN2.add(BatchNormalization())#グラフの繋がりが分からなくなりますので、ここで取っていきます、実際では使います
NN2.add(Conv2D(filters=32, kernel_size=(3,3), padding='same'))
NN2.add(Activation('relu'))
# NN2.add(BatchNormalization())#グラフの繋がりが分からなくなりますので、ここで取っていきます、実際では使います
# NN2.add(Dropout(0.2))#グラフの繋がりが分からなくなりますので、ここで取っていきます、実際では使います
NN2.add(Conv2D(filters=32, kernel_size=(3,3), padding='same'))
NN2.add(Activation('relu'))
# NN2.add(BatchNormalization())#グラフの繋がりが分からなくなりますので、ここで取っていきます、実際では使います
NN2.add(Conv2D(filters=32, kernel_size=(3,3), padding='same'))
Block #3
with tf.name_scope("NN3_Block"):
NN3= Sequential()
NN3.add(Conv2D(32, (3, 3), padding='same', input_shape=(32,32,3)))
NN3.add(Activation('relu'))
# NN3.add(BatchNormalization())#グラフの繋がりが分からなくなりますので、ここで取っていきます、実際では使います
NN3.add(Conv2D(filters=32, kernel_size=(3,3), padding='same'))
NN3.add(Activation('relu'))
# NN3.add(BatchNormalization())#グラフの繋がりが分からなくなりますので、ここで取っていきます、実際では使います
# NN3.add(Dropout(0.2))#グラフの繋がりが分からなくなりますので、ここで取っていきます、実際では使います
NN3.add(Conv2D(filters=32, kernel_size=(3,3), padding='same'))
NN3.add(Activation('relu'))
# NN3.add(BatchNormalization())#グラフの繋がりが分からなくなりますので、ここで取っていきます、実際では使います
NN3.add(Conv2D(filters=32, kernel_size=(3,3), padding='same'))
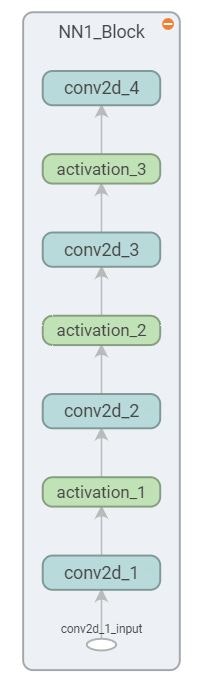 *図3:NN1からNN3まではこんな形になります*
*図3:NN1からNN3まではこんな形になります*
次はNN4を作り同時にNN1,NN2とNN3を繋げって行きます
NN1とNN2の結果を足算をして、一つにします(addblock )
added = add([NN1.output, NN2.output])
addblock = Model([NN1.input, NN2.input], added)
 *図4:Model after two blocks added*
*図4:Model after two blocks added*
addblockとNN3をつなげます(merged)
merged = concatenate([addblock.output, NN3.output])
mergedとNN4をつなげます
NN4もSequential APIで作ろうとしましたが、非常に難しくて、Functional APIを使いました、Sequential APIで繋がる方法が知っている人がいるなら教えてください。
with tf.name_scope("NN4_Block"):
NN4_conv = Conv2D(32, (3, 3), padding='same')(merged)
NN4_conv = Activation('relu')(NN4_conv)
# NN4_conv = BatchNormalization()(NN4_conv)#グラフの繋がりが分からなくなりますので、ここで取っていきます、実際では使います
NN4_conv = Conv2D(32, (3, 3), padding='same')(NN4_conv)
NN4_conv = Activation('relu')(NN4_conv)
# NN4_conv = BatchNormalization()(NN4_conv)#グラフの繋がりが分からなくなりますので、ここで取っていきます、実際では使います
NN4_conv = Conv2D(32, (3, 3), padding='same')(NN4_conv)
NN4_conv = Activation('relu')(NN4_conv)
# NN4_conv = BatchNormalization()(NN4_conv)#グラフの繋がりが分からなくなりますので、ここで取っていきます、実際では使います
NN4_conv = Conv2D(32, (3, 3), padding='same')(NN4_conv)
NN4_conv = Flatten()(NN4_conv)
NN4_conv = Dense(256)(NN4_conv)
# NN4_conv = BatchNormalization()(NN4_conv)#グラフの繋がりが分からなくなりますので、ここで取っていきます、実際では使います
NN4_conv = Dense(128)(NN4_conv)
# NN4_conv = BatchNormalization()(NN4_conv)#グラフの繋がりが分からなくなりますので、ここで取っていきます、実際では使います
NN4_conv = Dense(32)(NN4_conv)
NN4_conv = Dense(10, activation="softmax")(NN4_conv)
最終Model生成
finalblock = Model([NN1.input, NN2.input, NN3.input], NN4_conv)
finalblock.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
最後のgraph結果
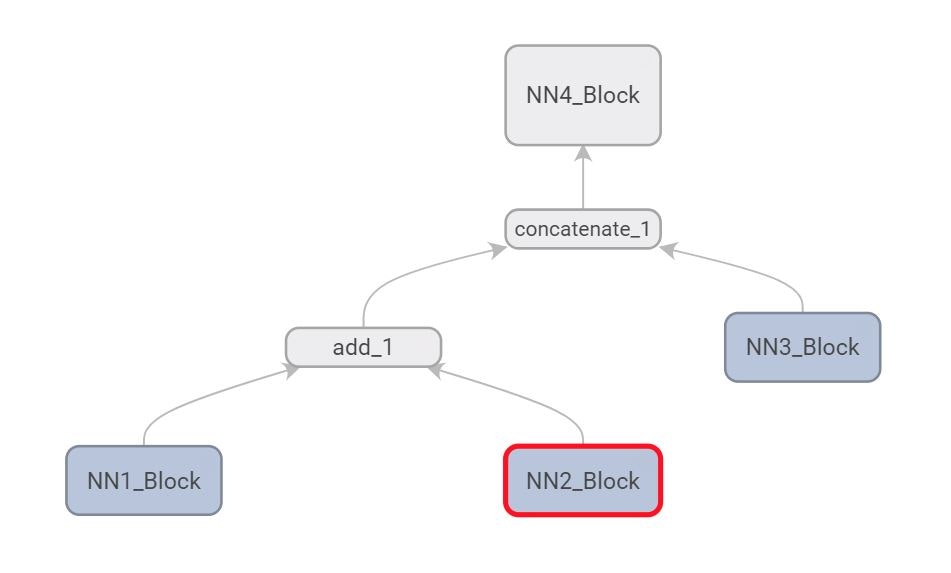 *図5:Final Model Graph*
*図5:Final Model Graph*
学習
ここまでできて、実際に学習して見ないと、残念が残りそうです。早速学習してみましょう。
(X_train, y_train), (X_test, y_test) = cifar10.load_data()
X_train = X_train.astype('float32')
X_test = X_test.astype('float32')
X_train /= 255
X_test /= 255
Y_train = np_utils.to_categorical(y_train, 10)
Y_test = np_utils.to_categorical(y_test, 10)
n_epochs = 20
batch_size = 64
H = finalblock.fit([X_train, X_train, X_train], Y_train, validation_data=([X_test, X_test, X_test], Y_test),
epochs=n_epochs, batch_size=batch_size, callbacks=None)
Train on 50000 samples, validate on 10000 samples
Epoch 1/20
50000/50000 [==============================] - 37s 743us/step - loss: 1.2756 - acc: 0.5486 - val_loss: 1.3998 - val_acc: 0.5553
.
.
.
Epoch 8/20
50000/50000 [==============================] - 32s 630us/step - loss: 0.3911 - acc: 0.8598 - val_loss: 0.9137 - val_acc: 0.7142
Epoch 9/20
50000/50000 [==============================] - 31s 625us/step - loss: 0.3219 - acc: 0.8838 - val_loss: 1.0909 - val_acc: 0.6962
Epoch 10/20
50000/50000 [==============================] - 31s 630us/step - loss: 0.2626 - acc: 0.9047 - val_loss: 1.0493 - val_acc: 0.7135
.
.
.
Epoch 20/20
50000/50000 [==============================] - 31s 628us/step - loss: 0.0976 - acc: 0.9653 - val_loss: 1.6173 - val_acc: 0.6955
やはりこのデータセットは簡単すぎて、すぐover-fittingになりますね。
まとめ
これは単純なKerasの使い方のメモみたいなものなんで、まとめがない。