背景
実際機械学習の分野では99%以上のデータはラベル無しって言われる。そのラベル無しのデータを使えるのは教師無しの学習方法です。
教師無しの学習方法の一つとしたAutoencoderを使って教師無しのクラスッタを作ったこの記事を読んで、面白いと思っていましたので、自分でも再現してみようと思います。
アイディア概略:直接cifar10のデータをKmeansで分類するとacc.が低い、autoencoderで32323のベクトルを10して、それをKmeansで分類する、そしてKmeansの出力分散を別のNNで学習させる。こうすることで、ラベル無し意のデータでも分類器を作ることができる。
注意:このコードをDocker環境で動かすと
OSError: [Errno 28] No space left on device: XXXX
が出る可能性がある、jupyterを使っているなら臨時フォルダを設定すれば通ります
%env JOBLIB_TEMP_FOLDER=/tmp
準備
読んだ記事と違ったデータで行うとしています、そのためモデルの構造が違っています。前回この記事のため、畳み込みの各層の入出力の次元計算方法を書きました、それを使って構造を作ります。
The Big Picture
教師なしの分類を作るに三つのステップで分けます:
- CAEモデル作成
- Kmeansでのクラスタ作成
- 学習させるクラスタ
CAE の学習
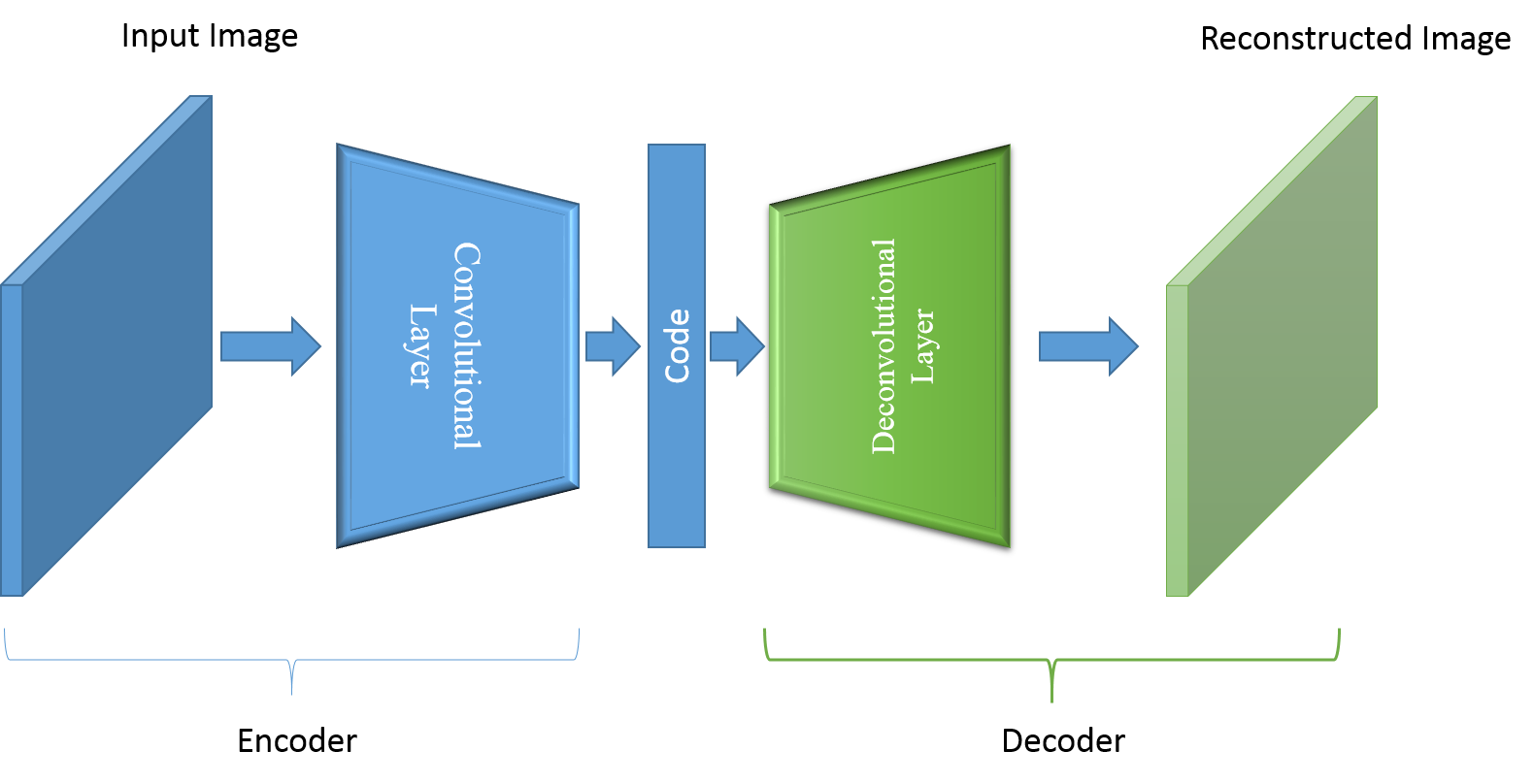
図1. CAE学習モデル
from keras.layers import Input, Dense, Convolution2D, MaxPooling2D, UpSampling2D, Flatten
from keras.models import Model
from keras import backend as K
from keras.callbacks import ModelCheckpoint
from keras.datasets import cifar10
必要なパッケージを入れる
(X_train, y_train), (X_test, y_test) = cifar10.load_data()
X_train = X_train.astype('float32')
X_train /= 255
データを正規化する
def autoencoder(act='relu', init='glorot_uniform'):
"""
Fully connected auto-encoder model, symmetric.
Arguments:
dims: list of number of units in each layer of encoder. dims[0] is input dim, dims[-1] is units in hidden layer.
The decoder is symmetric with encoder. So number of layers of the auto-encoder is 2*len(dims)-1
act: activation, not applied to Input, Hidden and Output layers
return:
(ae_model, encoder_model), Model of autoencoder and model of encoder
"""
input_img = Input(shape=(32, 32, 3))
x = Convolution2D(16, (3, 3), activation='relu', padding='same')(input_img)
x = MaxPooling2D((2, 2), border_mode='same')(x)
x = Convolution2D(8, (3, 3), activation='relu', padding='same')(x)
x = MaxPooling2D((2, 2), padding='same')(x)
x = Convolution2D(8, (3, 3), activation='relu', padding='same')(x)
x = MaxPooling2D((2, 2), padding='same')(x)
x = Flatten()(x)
x = Dense(4*4*8, activation="relu")(x)
encoded = Dense(10, activation="relu")(x)
x = Dense(4*4*8, activation="relu")(encoded)
x = Reshape(target_shape=(4,4,8))(x)
x = Convolution2D(8, (3, 3), activation='relu', padding='same')(x)
x = UpSampling2D((2, 2))(x)
x = Convolution2D(8, (3, 3), activation='relu', padding='same')(x)
x = UpSampling2D((2, 2))(x)
x = Convolution2D(3, (3, 3), activation='relu', padding='same')(x)
x = UpSampling2D((2, 2))(x)
decoded = Convolution2D(3, (3, 3), activation='sigmoid', padding='same')(x)
return Model(inputs=input_img, outputs=encoded, name='encoder'), Model(inputs=input_img, outputs=decoded, name='AE')
#
CAEモデル作成
encoder, autoencoder = autoencoder()
autoencoder.compile(loss='mse', optimizer='adam', metrics=['accuracy'])
filepath="weights-improvement-{epoch:02d}.hdf5"
checkpoint = ModelCheckpoint(filepath, monitor='accuracy', verbose=1, save_best_only=True, mode='max')
callbacks_list = [checkpoint]
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_37 (InputLayer) (None, 32, 32, 3) 0
_________________________________________________________________
conv2d_127 (Conv2D) (None, 32, 32, 16) 448
_________________________________________________________________
max_pooling2d_109 (MaxPoolin (None, 16, 16, 16) 0
_________________________________________________________________
conv2d_128 (Conv2D) (None, 16, 16, 8) 1160
_________________________________________________________________
max_pooling2d_110 (MaxPoolin (None, 8, 8, 8) 0
_________________________________________________________________
conv2d_129 (Conv2D) (None, 8, 8, 8) 584
_________________________________________________________________
max_pooling2d_111 (MaxPoolin (None, 4, 4, 8) 0
_________________________________________________________________
flatten_35 (Flatten) (None, 128) 0
_________________________________________________________________
dense_105 (Dense) (None, 128) 16512
_________________________________________________________________
dense_106 (Dense) (None, 10) 1290
_________________________________________________________________
dense_107 (Dense) (None, 128) 1408
_________________________________________________________________
reshape_21 (Reshape) (None, 4, 4, 8) 0
_________________________________________________________________
conv2d_130 (Conv2D) (None, 4, 4, 8) 584
_________________________________________________________________
up_sampling2d_7 (UpSampling2 (None, 8, 8, 8) 0
_________________________________________________________________
conv2d_131 (Conv2D) (None, 8, 8, 8) 584
_________________________________________________________________
up_sampling2d_8 (UpSampling2 (None, 16, 16, 8) 0
_________________________________________________________________
conv2d_132 (Conv2D) (None, 16, 16, 3) 219
_________________________________________________________________
up_sampling2d_9 (UpSampling2 (None, 32, 32, 3) 0
=================================================================
Total params: 22,789
Trainable params: 22,789
Non-trainable params: 0
学習時のモデルの重みを保存しておく。
autoencoder.fit(X_train, X_train, batch_size=32, epochs=20, callbacks=callbacks_list)
Epoch 1/20
50000/50000 [==============================] - 22s 438us/step - loss: 0.0210 - acc: 0.5110
Epoch 2/20
416/50000 [..............................] - ETA: 20s - loss: 0.0148 - acc: 0.5944
/opt/conda/lib/python3.6/site-packages/keras/callbacks.py:432: RuntimeWarning: Can save best model only with accuracy available, skipping.
'skipping.' % (self.monitor), RuntimeWarning)
50000/50000 [==============================] - 20s 398us/step - loss: 0.0142 - acc: 0.6192
Epoch 3/20
50000/50000 [==============================] - 19s 384us/step - loss: 0.0130 - acc: 0.6324
Epoch 4/20
50000/50000 [==============================] - 19s 373us/step - loss: 0.0124 - acc: 0.6380
Epoch 5/20
50000/50000 [==============================] - 19s 373us/step - loss: 0.0120 - acc: 0.6411
Epoch 6/20
50000/50000 [==============================] - 19s 375us/step - loss: 0.0118 - acc: 0.6446
Epoch 7/20
50000/50000 [==============================] - 19s 379us/step - loss: 0.0116 - acc: 0.6560
Epoch 8/20
50000/50000 [==============================] - 18s 369us/step - loss: 0.0114 - acc: 0.6806
Epoch 9/20
50000/50000 [==============================] - 18s 363us/step - loss: 0.0112 - acc: 0.6915
Epoch 10/20
50000/50000 [==============================] - 18s 369us/step - loss: 0.0111 - acc: 0.6963
Epoch 11/20
50000/50000 [==============================] - 19s 375us/step - loss: 0.0110 - acc: 0.7008
Epoch 12/20
50000/50000 [==============================] - 19s 375us/step - loss: 0.0109 - acc: 0.7038
Epoch 13/20
50000/50000 [==============================] - 19s 371us/step - loss: 0.0109 - acc: 0.7067
Epoch 14/20
50000/50000 [==============================] - 19s 377us/step - loss: 0.0108 - acc: 0.7091
Epoch 15/20
50000/50000 [==============================] - 19s 373us/step - loss: 0.0107 - acc: 0.7113
Epoch 16/20
50000/50000 [==============================] - 18s 368us/step - loss: 0.0107 - acc: 0.7126
Epoch 17/20
50000/50000 [==============================] - 18s 368us/step - loss: 0.0107 - acc: 0.7142
Epoch 18/20
50000/50000 [==============================] - 18s 369us/step - loss: 0.0106 - acc: 0.7157
Epoch 19/20
50000/50000 [==============================] - 19s 379us/step - loss: 0.0106 - acc: 0.7167
Epoch 20/20
50000/50000 [==============================] - 19s 379us/step - loss: 0.0105 - acc: 0.7182
必要があればEpoch数を増やして90%以上のacc.にしてください。
dict([(layer.name, layer) for layer in autoencoder.layers])
{'conv2d_1': <keras.layers.convolutional.Conv2D at 0x7f9e59969748>,
'conv2d_2': <keras.layers.convolutional.Conv2D at 0x7f9e59969160>,
'conv2d_3': <keras.layers.convolutional.Conv2D at 0x7f9e500a1cf8>,
'conv2d_4': <keras.layers.convolutional.Conv2D at 0x7f9e500405c0>,
'conv2d_5': <keras.layers.convolutional.Conv2D at 0x7f9e407cbe48>,
'conv2d_6': <keras.layers.convolutional.Conv2D at 0x7f9e40794f28>,
'conv2d_7': <keras.layers.convolutional.Conv2D at 0x7f9e407576d8>,
'dense_1': <keras.layers.core.Dense at 0x7f9e500cc2b0>,
'dense_2': <keras.layers.core.Dense at 0x7f9e50080be0>,
'dense_3': <keras.layers.core.Dense at 0x7f9e50021128>,
'flatten_1': <keras.layers.core.Flatten at 0x7f9e500ccd30>,
'input_1': <keras.engine.input_layer.InputLayer at 0x7f9e59969a90>,
'max_pooling2d_1': <keras.layers.pooling.MaxPooling2D at 0x7f9e59969a20>,
'max_pooling2d_2': <keras.layers.pooling.MaxPooling2D at 0x7f9e599695c0>,
'max_pooling2d_3': <keras.layers.pooling.MaxPooling2D at 0x7f9e500b9470>,
'reshape_1': <keras.layers.core.Reshape at 0x7f9e50040278>,
'up_sampling2d_1': <keras.layers.convolutional.UpSampling2D at 0x7f9e50040908>,
'up_sampling2d_2': <keras.layers.convolutional.UpSampling2D at 0x7f9e407e4b00>,
'up_sampling2d_3': <keras.layers.convolutional.UpSampling2D at 0x7f9e407aa320>}
Layer名を出して、code層の名前使う[dense_2]
cluster = autoencoder.get_layer('dense_2').output
CL = Model(inputs=autoencoder.input, outputs=cluster, name='cluster_10')
code層までだけを単独のモデルとして保存する
K-meansの分類
あまりにも有名過ぎて、私の「ダメ」な日本語で言わない方が良いかも、Scipy使ったコードだけ置いておきます。
# code credit goes to https://www.dlology.com/blog/how-to-do-unsupervised-clustering-with-keras/
from sklearn.cluster import KMeans
from keras.datasets import cifar10
def acc(y_true, y_pred):
"""
Calculate clustering accuracy. Require scikit-learn installed
# Arguments
y: true labels, numpy.array with shape `(n_samples,)`
y_pred: predicted labels, numpy.array with shape `(n_samples,)`
# Return
accuracy, in [0,1]
"""
y_true = y_true.astype(np.int64)
assert y_pred.size == y_true.size
D = max(y_pred.max(), y_true.max()) + 1
w = np.zeros((D, D), dtype=np.int64)
for i in range(y_pred.size):
w[y_pred[i], y_true[i]] += 1
from sklearn.utils.linear_assignment_ import linear_assignment
ind = linear_assignment(w.max() - w)
return sum([w[i, j] for i, j in ind]) * 1.0 / y_pred.size
(x_train, y_train), (x_test, y_test) = cifar10.load_data()
x = x_train.astype('float32')
x /= 255
y = y_train
# 10 clusters
n_clusters = len(np.unique(y))
kmeans = KMeans(n_clusters=n_clusters, n_init=20, n_jobs=4)
# Train K-Means.
y_pred_kmeans = kmeans.fit_predict(CL.predict(x))
# Evaluate the K-Means clustering accuracy.
acc(y, y_pred_kmeans)
結果
このままK-meansを使うと22%ぐらい、使い物にならないですね。
To Be Continued...
KNNで....