では書きます。
WordEmbedding
文脈を考慮した単語の埋め込み表現です。
単語をNNに入れる際に文字データを数値データ(例:[犬]→[1,0,0])に変換する必要があります。
どう変換するのがよいでしょうか。
one hot encording
例えばone hot encordingで変換する手法があります。
例:
リンゴ:[1,0,0]
梨:[0,1,0]
車:[0,0,1]
これだと似た意味が反映されないので表現能力が低く、単語数=次元数となりメモリ効率が悪いです。
word 2 vec
意味が近い単語を似たようなベクトルにする手法。
例:
リンゴ:[1,0,0]
梨:[0,1,0]
車:[0,0,1]
↓
リンゴ:[1,2,0]
梨:[3,1,0]
車:[0,0,1]
似ている情報もベクトルに載せます。
似ている情報をどうやれば得られるでしょうか。
求め方:分布仮説
単語の意味は周辺の単語によって決まるという仮説です。
例えば
彼 は __ に 乗る
文の空欄には乗り物が入りそうですよね。というように周辺の単語から空欄に入る単語を予測する事前学習をしてあげれば、似たような単語を似たようなベクトルにできます。
以下に手法をまとめます。
CBOW
周辺単語から求めたい単語を予測させ、ベクトルを決める手法
彼 は __ に 乗る
Skip-gram
入力に空欄の単語を入れて周辺単語を予測させてベクトルを決める手法。
__ __ バイク __ __
負例(正解じゃない単語)の用意が容易なので精度が少し上がります。
Sentence Piece
トークン列(単語)を得るために形態素解析をする手法。
ですが形態素ベースは
・メモリを食うので大きい辞書が使えない
・低頻度語を捨てる(専門用語だったらとても大事)
・未知語はあきらめ
問題が多いです。
サブワード
事前に決めた語彙数以下になるまで区切る手法。以下のメリットがあります。
・未知語がなくなる
・語彙サイズがかなり節約
・精度が下がらない
と形態素解析の問題点を解決しております。
Sentence Pieceというライブラリを用いてサブワードを求め、サブワードはBPE(Bite pair Encording)というアルゴリズムを求めます。
Transformer(Attention)
時系列データの処理の問題点を解決した"Attention Is All You Need"という論文で開発されたアルゴリズムです。
もともと翻訳に用いられていたエンコーダーデコーダーモデルですが、エンコーダーの出力を特徴ベクトルに使うとパフォーマンスが出ます。
これまで時系列データはRNN、LSTMを用いて処理していましたが
・BPTTでメモリをたくさん使う
・並列処理ができないので時間がかかる
・安定しない
とデメリットがありました。それらの問題を解決したのがTransformerです。
Transformerでは
・入力を一度に処理
・過去のデータとの関係を知る処理回数が少ない(=どの単語とも関係性がすぐわかる)
といったメリットがあります。
pre-training
文脈モデルをpre-trainingすると性能が上がり汎用性も高くなります。
自然言語処理では画像処理と違い、問題固有のアプローチ(翻訳、ポジティブネガティブ判定は別で作る)になりますが、Modelを作り、Finetuningすればチャットボット、翻訳ソフトなどに応用できます。
文脈モデル
t-n~tまでの単語を使ってt+1に出現する単語を予測するモデル。
例えばword2vecだと
bank(銀行)=x
bank(土手)=x
と意味が異なっても同じベクトルになります。そこで前後の文脈を考慮してベクトルを考えましょうというのがこのモデルです。
このモデルをあらかじめpre-trainingしてから問題を解くと性能が上がります。
Self Attention
AttentionではQuerry,Key,Valueの3つを使った辞書を用い、Self AttentionとSource Targtet Attentionの2つを使って予測をします。
QueryとMemoryが同じAttentionです。
Queryがitの後ろに続くものを探しているとき、softmaxでKeyとValueのうち不要な情報を消す手法。係り受け構造を取得していると考えられています。
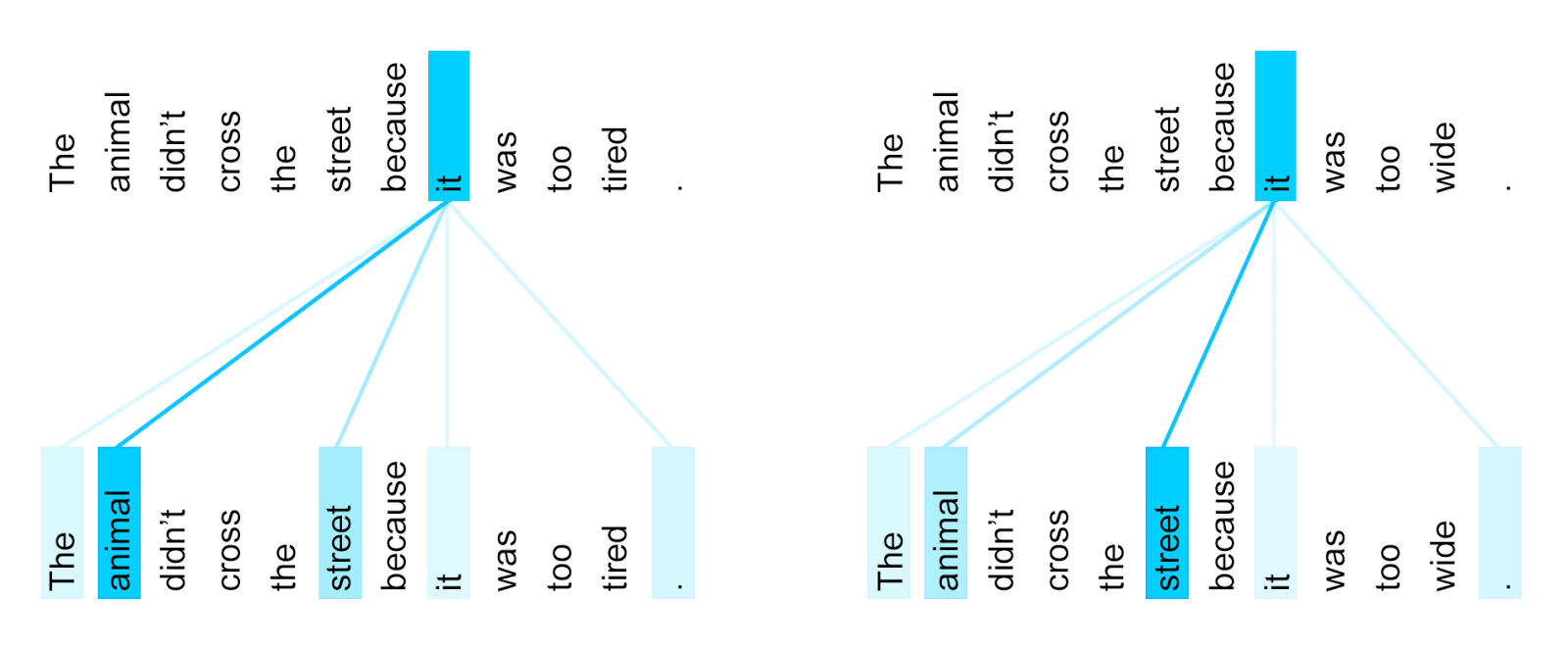
引用:https://ai.googleblog.com/2017/08/transformer-novel-neural-network.html
Source Targtet Attention
QueryとMemoryが違うAttentionです。
Queryから入力を得て、そこからふさわしいものを出力します。
positional Encording
単語の順番情報を加えるもの。
相対的な単語の位置関係をNNが学習しやすいよう設計されていますが、あまり効果がないらしく現在は使われていません。
Mask
pre-trainingでは未来の情報を参照せず、次に来る単語を予測する学習をします。
未来の情報を参照しない手法をMaskといいます。
BERT(双方向Transformer)
Transformerを使いつつ、未来から過去と過去から未来への文どちらとも考慮するモデルです。
Masked Language Modelを使っています。
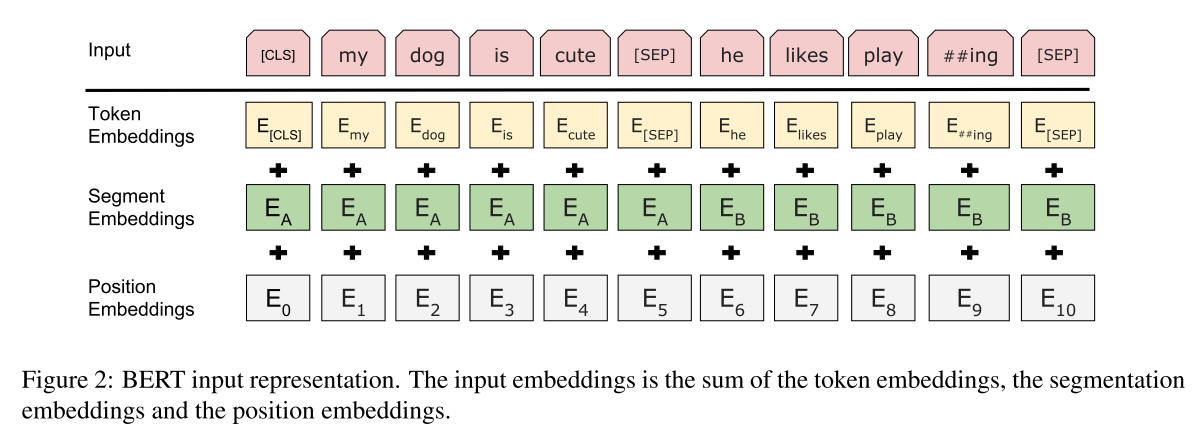
長さは512単語で固定、足りないときはpadding、多いときは打ち切ります。
Token Emmeddings:word2vecのような単語の埋め込みベクトル(256~2048次元)
Segment Embedding:文1か2か区別する入力
Position Embedding:文中で何番目に出ているかの情報
softmaxで単語を推定します。
Masked Language Model
単語の穴埋めを解かせる問題を機械に課すモデル。
以下の手法で解きます。
ランダムに15%のtokenを選びます。
選ばれたtokenのうち
80%:を[mask]に置き換えて穴埋め問題を解かせる(置き換えすぎると性能が下がる(本番で穴埋め問題を解かせないため))
10%:ランダムに選んだ適当なtokenに置き換える
10%:なにもしない
とやって学習をさせます。
BERT NEXT Sentence Prediction
MLMをした後、NEXT Sentence Predictionをpre-trainingでやる手法。
NEXT Sentence Predictionとは文章を2つ与え、正しいペアなのか回答させる手法です。
正しい例
A:あなたは人ですか?
B:はい。
誤っている例
A:あなたは人ですか?
B:ふんぐあ!
BERTで解けるもの
Sentense Pair Classification
会話破綻検出などに用いられるテキストのペア分類
例;STS-B,SWAG
Single Sentence
記事のカテゴリ付けのような一つの文の分類
例:SST-2,CoLA
Question Answering Tasks
Q&A、読解能力を試されるものに使われます。
例:SQuAD
Single Sentence Tagging Tasks
各単語に人名や地名などタグ付け
発展手法
ALBERT:Bertの軽量化、性能アップ
XLNet:Maskを使わず、シャッフルした文をもとに戻す学習方法
Transformer-XL:再帰的にTransformerを使って可変長の文字列に対応