前回はPythonを使って、ゆっくりに青空文庫を読んでもらうことに成功しました
しかし、ルビを考慮せず読ませてしまったので、読み上げの精度がかなり低いという難点がありました
今回はその点を修正していきます
今回の流れ
やりたいことは
青空文庫のURLを投げると、読みの辞書登録を済ました上でゆっくりが読み上げてくれることです
そこで、以下の流れを作っていきます
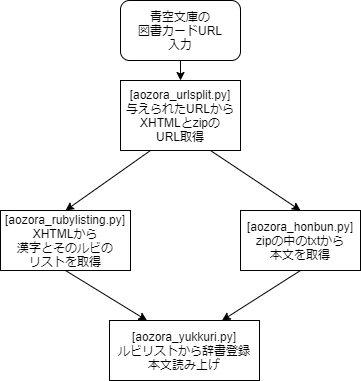
図書カードのURLからファイルのURLを取得
青空文庫には図書カードというページがあり、そこから本文が記載されたWebページに飛んだり、各種ファイルをDLできたりします
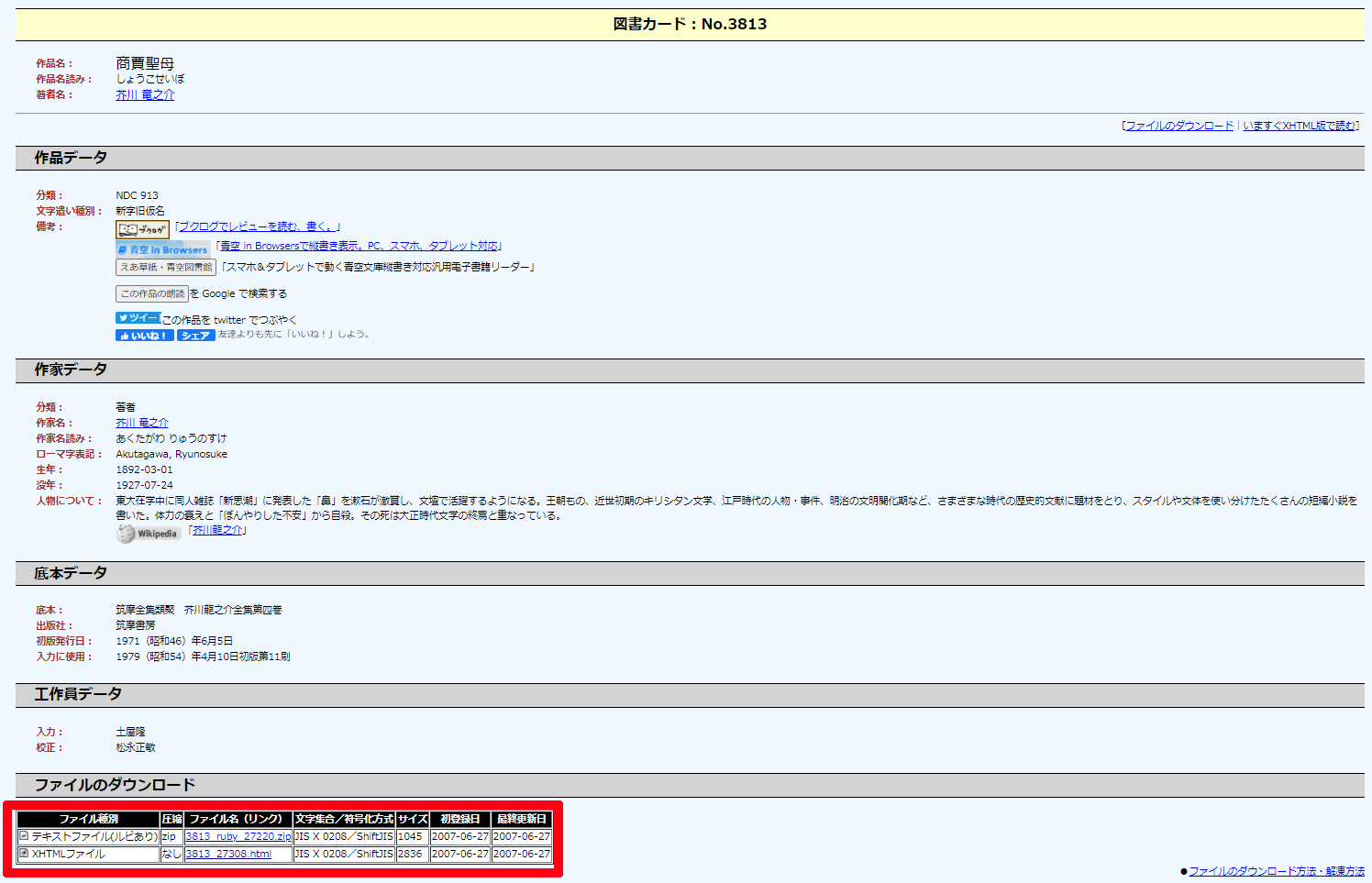
今回は赤く囲ったところのファイルの内、zipとxhtmlがほしいので、BeautifulSoup4を使って取得します
from bs4 import BeautifulSoup
import requests
import re
def aozoraurl(url):
page = requests.get(url)
soup = BeautifulSoup(page.content, 'html.parser')
table = soup.select('table.download a[href*=".html"]')
htmlurl_rel = str(table).split('\"')[1].replace("./", "/")
# XHTMLの相対パス取得
table2 = soup.select('table.download a[href*=".zip"]')
zipurl_rel = str(table2).split('\"')[1].replace("./", "/")
# zipファイルの相対パス取得
urlsplit = re.sub("/card[0-9]*.html", "", url)
htmlurl = urlsplit + htmlurl_rel
zipurl = urlsplit + zipurl_rel
aozoraurllist = [htmlurl, zipurl]
#入力したURLのcard以下を切り取り、上の相対パスとくっつける
return aozoraurllist
if __name__ == '__main__':
print(aozoraurl("https://www.aozora.gr.jp/cards/000879/card85.html"))
図書カードのページのURLを投げると[XHTMLのURL, zipのURL]のリストを返してくれます
ルビのリストを作成する
XHTMLからルビのリストを作成します
from bs4 import BeautifulSoup
import requests
import re
import jaconv
def aozoraruby(url):
page = requests.get(url)
soup = BeautifulSoup(page.content, 'html.parser')
_ruby = soup.select("ruby")
_rubylist = []
for i in _ruby:
_ruby_split = re.sub("<[/a-z]*>", "", str(i)).replace(")", "").split("(")
_rubylist.append(_ruby_split)
for index, item in enumerate(_rubylist):
_rubylist[index][1] = jaconv.kata2hira(str(item[1]))
return _rubylist
if __name__ == '__main__':
print(aozoraruby("https://www.aozora.gr.jp/cards/000879/files/3813_27308.html"))
SofTalkはひらがなでしか読み登録できないので、カタカナはひらがなに変換します
今回始めて enumerate を使ったのですが、スマートで良いですね
txtファイルから本文を作成
前回同様、青空文庫からPythonで本文を取得したい - AI人工知能テクノロジーからお借りします。
download() 関数にURLを投げると convert() 関数から本文が返ってきます
main() 関数は使わないので if __name__ == '__main__':以下に置いておきます
ゆっくりの辞書登録と読み上げ
import subprocess
import os
from aozora_urlsplit import aozoraurl
from aozora_rubylisting import aozoraruby
from aozora_honbun import download, convert
os.chdir(os.path.dirname(os.path.abspath(__file__)))
urllist = aozoraurl("https://www.aozora.gr.jp/cards/000879/card3813.html")
_ruby = aozoraruby(urllist[0])
_honbun = convert(download(urllist[1])).splitlines()
_start = "start SofTalk.exeのPath"
_pron = "/P:"
_speed = "/S:120"
_word = "/W:"
for j in _ruby:
_command_ruby = [_start, _pron + j[1] + "," + j[0] + ",True"]
print(_command_ruby)
subprocess.run(' '.join(_command_ruby), shell=True)
for i in _honbun:
_command = [_start, _speed, _word + i]
subprocess.run(' '.join(_command), shell=True)
本文を改行ごとにリストに入れて、辞書登録から本文読み上げまで行います
ゆっくりの声変えたい場合は_commandに/M:もしくは/MN:を付け足して変更してください(参考1)
既知の問題
本文とルビを別のところから取ってきている
既存のコードを使いたいがために、本文はtxt(zip)から、ルビはXHTML版から取ってきています
将来的には本文もXHTML版に統一すべきかと思います(txtからルビを取るのはかなり難しそうなので)
辞書登録に失敗している漢字
青空文庫では、下の画像のような難しい漢字は画像として表示しているようです
これを読みにするのは難しいので、辞書登録は飛ばしてひらがなとして本文にまとめるのが良さげです
今回はある程度読めればいいと思って処理していません
問題の漢字

-
Pythonでゆっくりボイスを作ろう
https://qiita.com/Mechanetai/items/78b04ed553cce01fa081 ↩