前置き
去年作ったこれを改良した
結果これができた
https://mcbeeringi.github.io/amuse/bf_.html
全体の流れ
コード生成の基本的な流れは前回と変わっていない
以下の通り
- \u0000~\u00ffを0~255の数の配列に起こす
- 数の差が閾値以下の文字同士をグループ化する(brainf*ckでどの文字がどのメモリから吐き出されるかを決める)
- 同時にそのインデックスも作成する(ポインタの移動で必要)
- ポインタの移動を最小限抑えるためインデックスとグループを並べ替える←重要
- 各グループの最初の数に近い数を生成するためのループ部分を作成←これ大事
- インデックスとグループを参照して残りを書き出す
インデックス並び替えとループ部分は出力したい文字が長くなるほど効いてくる
改善点
- 書き方が古臭い。洗練されていない。
- ポインタの移動によるコストの削減のためのインデックス並び替えが洗練されていない。非効率。
- 最初のループ部分の最適化が不十分。
洗練する
インデックスの作成までは処理に変化がないので省略
インデックスペア列挙
まずインデックスから隣り合う数のペアを列挙する
前回はmapで拾ったが個人的にreduceが好きになったのでreduceで書く
//s.i=インデックス番号の配列
//s.a=グループの配列
//create freq index [...[[pair,pair],priority]]
s.freq=Object.entries(new Array(s.i.length-1).fill().reduce((a,x,i)=>{
x=s.i.slice(i,i+2);
if(x[0]!=x[1]){i=`${Math.min(...x)}_${Math.max(...x)}`;if(a[i])a[i]++;else a[i]=1;}
return a;
},{}))
.sort((a,b)=>Math.sign(b[1]-a[1]))
.map(x=>[x[0].split('_').map(y=>+y),x[1]]);
これで[[ペ,ア],出現回数]の配列が手に入る
前回はこの後出現回数を数えていたが今回はこれだけで済む
ゾロ目のカットも簡単
reduceかわいいね
Object.entriesもかわいい
インデックス並び替え
前回は最初に種を植えてそこからインデックスのペアをつなげていく手法をとった
ただこれだとつなげられるペアが一つもなくなった時点で結果に含まれないインデックス番号が存在する場合が生じうる
しかもペアをつなげていく過程でその時点の結果にペアのどちらの番号も含まれていない場合はそのペアは完全に後回しにしていた
これだとあまりに非効率
今回は出現回数と無理やり入れた場合のペアの距離から移動のコストを点数化して比較した結果それが最小のものを挿入していく
//solve freq
s.freq={
x:null,//仮置き
q:s.freq.slice(1),//入れるべきペア q=[...[[ペア],出現回数]]]
a:s.freq[0][0]//一番出現回数の多いペアを種として植える
};
while(1){
s.freq.x=Object.fromEntries(s.freq.a.map(Array));//indexOfをforしないためにインデックスを作る
s.freq.x=s.freq.q.reduce((a,x,i)=>({
tt:()=>a,ff:()=>a,tf(){x[0].reverse();return this.ft();},
ft(
d=s.freq.x[x[0][1]],//ペアで既に存在する番号の配列中の座標
p=(s.freq.a.length-1)/2>d//配列の前端が近ければtrue
){
d=(p?d+1:s.freq.a.length-d)/x[1];//コストの点数化
return d<a.d?{i,d,p}:a;//最小点数の更新
}
})[
//結果にペアがそれぞれ含まれているか否かを文字列にして返してそのままObjectの中の関数を呼び出す
x[0].reduce((a,y)=>s.freq.a.includes(y)?a+'t':a+'f','')
](),{d:Infinity,_:true});
if(s.freq.x._)break;//reduceで何も得られなければ結果が完成したと判断してループを抜ける 元のインデックスがひとつながりになっている以上これは保証される
s.freq.a[s.freq.x.p?'unshift':'push'](s.freq.q.splice(s.freq.x.i,1)[0][0][0]);//入れるべきペアからreduceで得られたペアを抜き取って結果につけくわえる
console.log(s.freq.a);//現時点での結果
}
/*
こんな感じでlogが出る
[1,0,5]
[1,0,5,3]
[1,0,5,3,7]
[1,0,5,3,7,13]
[1,0,5,3,7,13,9]
[1,0,5,3,7,13,9,8]
[1,0,5,3,7,13,9,8,10]
[1,0,5,3,7,13,9,8,10,22]
[1,0,5,3,7,13,9,8,10,22,21]
[1,0,5,3,7,13,9,8,10,22,21,23]
[2,1,0,5,3,7,13,9,8,10,22,21,23]
[19,2,1,0,5,3,7,13,9,8,10,22,21,23]
[6,19,2,1,0,5,3,7,13,9,8,10,22,21,23]
[11,6,19,2,1,0,5,3,7,13,9,8,10,22,21,23]
[11,6,19,2,1,0,5,3,7,13,9,8,10,22,21,23,12]
[11,6,19,2,1,0,5,3,7,13,9,8,10,22,21,23,12,17]
[15,11,6,19,2,1,0,5,3,7,13,9,8,10,22,21,23,12,17]
[16,15,11,6,19,2,1,0,5,3,7,13,9,8,10,22,21,23,12,17]
[16,15,11,6,19,2,1,0,5,3,7,13,9,8,10,22,21,23,12,17,14]
[16,15,11,6,19,2,1,0,5,3,7,13,9,8,10,22,21,23,12,17,14,4]
[16,15,11,6,19,2,1,0,5,3,7,13,9,8,10,22,21,23,12,17,14,4,20]
[16,15,11,6,19,2,1,0,5,3,7,13,9,8,10,22,21,23,12,17,14,4,20,18]
[25,16,15,11,6,19,2,1,0,5,3,7,13,9,8,10,22,21,23,12,17,14,4,20,18]
[25,16,15,11,6,19,2,1,0,5,3,7,13,9,8,10,22,21,23,12,17,14,4,20,18,24]
[25,16,15,11,6,19,2,1,0,5,3,7,13,9,8,10,22,21,23,12,17,14,4,20,18,24,26]
*/
//結果をもとにインデックスとペアを並び替える
//swap index
s.a=s.freq.a.map(x=>s.a[x]);
s.freq=Object.fromEntries(s.freq.a.map(Array));
s.i=s.i.map(x=>s.freq[x]);
Object.fromEntries毎度いい仕事する惚れた
ループ作成
前回の探索もいい線ついてはいたが詰めが甘かった
具体的には近い数の公倍数を探索するまではよかったのだがその補正に-を使うことが考慮されていなかった
つまり文字数の勘定が間違っていた
直す。
//find best init loop
s.init=new Array(10).fill().map((_,i)=>i+7).reduce((a,i,x)=>{
x=s.a.reduce((b,x)=>{
x=x[0];x=x<128?[1,x]:[-1,256-x];//+周りと-周りどちらが早いか
x[2]=x[1]%i;x[1]=x[1]/i;//共通部分の計算
x=x[1]%1>.5?[x[0],Math.ceil(x[1]),(x[2]-i)*x[0]]:[x[0],Math.floor(x[1]),x[2]*x[0]];//補正は+か-か 倍数で近いのはどちら側か その補正は?
b.x+=x[1]+Math.abs(x[2]);//文字数の勘定
b.a.push(x);//計算した補正の必要数等は後で使うのでとっとく
return b;
},{
i,//公倍数
x:i,//文字数の勘定 公倍数も文字数に入るよ
a:[]//補正等の保存用
});
console.log(x);
return x.x<a.x?x:a;//勘定の結果文字数が少なかったら結果更新
},{x:Infinity});
/*
こんな感じ
{"i":7,"x":285,"a":[[1,11,0],[1,16,1],[-1,7,-2],[-1,13,-1]...
{"i":8,"x":269,"a":[[1,10,-3],[1,14,1],[-1,6,-3],[-1,11,-4...
{"i":9,"x":261,"a":[[1,9,-4],[1,13,-4],[-1,6,3],[-1,10,-2]...
{"i":10,"x":243,"a":[[1,8,-3],[1,11,3],[-1,5,-1],[-1,9,-2]...
{"i":11,"x":237,"a":[[1,7,0],[1,10,3],[-1,5,4],[-1,8,-4],[...
{"i":12,"x":240,"a":[[1,6,5],[1,9,5],[-1,4,-3],[-1,8,4],[-...
{"i":13,"x":221,"a":[[1,6,-1],[1,9,-4],[-1,4,1],[-1,7,-1],...
{"i":14,"x":221,"a":[[1,5,7],[1,8,1],[-1,4,5],[-1,7,6],[-1...
{"i":15,"x":223,"a":[[1,5,2],[1,8,-7],[-1,3,-6],[-1,6,-2],...
{"i":16,"x":197,"a":[[1,5,-3],[1,7,1],[-1,3,-3],[-1,6,4],[...
*/
//各グループの先頭に補正前の数を入れる
//apply init number
s.init.a.forEach((x,i)=>s.a[i].unshift(s.a[i][0]-x[2]));
reduce見た目に反して処理速度はそこそこ早かったりする
残りを出力
気合で頑張る
補正を入れるのも忘れずに
s.x=s.i.reduce((a,i,x)=>{
x=s.a[i][a.i[i]+1]-s.a[i][a.i[i]];//現在のポインタの位置と目標のメモリとの距離の計算
x=[x>0,Math.abs(x)];//符号
a.a+=(i>a.x?'>':'<').repeat(Math.abs(i-a.x))+(x[0]^x[1]>128?'+':'-').repeat(Math.min(x[1],256-x[1]))+'.';//文字起こし
a.i[i]++;//グループ内の現在位置を進める
a.x=i;//ポインタ位置保存
return a;
},{
x:0,//ポインタ位置
a:'+'.repeat(s.init.i)+'['+s.init.a.map(x=>'>'+(x[0]>0?'+':'-').repeat(x[1])).join('')+'<'.repeat(s.init.a.length)+'-]>',//ループ文字起こし
i:new Array(s.a.length).fill(0)//グループ内での現在の処理位置
}).a;//文字だけほしい
できた
const main=(s,dist)=>{
s=Array.from(s,x=>x.codePointAt(0)).filter(x=>x<256);
//create chain:{a:heap,x:raw,i:heap_index}
s={
...s.reduce((a,x,i)=>{
i=a.x.reduce((b,y,j)=>{
const p=[Math.abs(y-x),Math.abs(b[0]-x)].map(z=>Math.min(z,256-z));
return p[0]<p[1]&&p[0]<=dist?[y,j]:b;
},[(x+128)%256,a.x.length])[1];
if(a.a[i])a.a[i].push(x);else a.a[i]=[x];
a.x[i]=x;a.i.push(i);return a;
},{a:[],x:[],i:[]}),
x:s
};
//create freq index [...[[pair,pair],priority]]
s.freq=Object.entries(new Array(s.i.length-1).fill().reduce((a,x,i)=>{
x=s.i.slice(i,i+2);
if(x[0]!=x[1]){i=`${Math.min(...x)}_${Math.max(...x)}`;if(a[i])a[i]++;else a[i]=1;}
return a;
},{}))
.sort((a,b)=>Math.sign(b[1]-a[1]))
.map(x=>[x[0].split('_').map(y=>+y),x[1]]);
if(s.freq.length>=2){
//solve freq
s.freq={x:null,q:s.freq.slice(1),a:s.freq[0][0]};
while(1){
s.freq.x=Object.fromEntries(s.freq.a.map(Array));
s.freq.x=s.freq.q.reduce((a,x,i)=>({
tt:()=>a,ff:()=>a,tf(){x[0].reverse();return this.ft();},
ft(d=s.freq.x[x[0][1]],p=(s.freq.a.length-1)/2>d){
d=(p?d+1:s.freq.a.length-d)/x[1];
//console.log(x,d);
return d<a.d?{i,d,p}:a;
}
})[x[0].reduce((a,y)=>s.freq.a.includes(y)?a+'t':a+'f','')](),{d:Infinity,_:true});
if(s.freq.x._)break;
s.freq.a[s.freq.x.p?'unshift':'push'](s.freq.q.splice(s.freq.x.i,1)[0][0][0]);
console.log(s.freq.a);
}
//swap index
s.a=s.freq.a.map(x=>s.a[x]);
s.freq=Object.fromEntries(s.freq.a.map(Array));
s.i=s.i.map(x=>s.freq[x]);
}
//find best init loop
s.init=new Array(10).fill().map((_,i)=>i+7).reduce((a,i,x)=>{
x=s.a.reduce((b,x)=>{
x=x[0];x=x<128?[1,x]:[-1,256-x];x[2]=x[1]%i;x[1]=x[1]/i;
x=x[1]%1>.5?[x[0],Math.ceil(x[1]),(x[2]-i)*x[0]]:[x[0],Math.floor(x[1]),x[2]*x[0]];
b.x+=x[1]+Math.abs(x[2]);b.a.push(x);return b;
},{i,x:i,a:[]});
console.log(x);return x.x<a.x?x:a;
},{x:Infinity});
//apply init number
s.init.a.forEach((x,i)=>s.a[i].unshift(s.a[i][0]-x[2]));
s.x=s.i.reduce((a,i,x)=>{
x=s.a[i][a.i[i]+1]-s.a[i][a.i[i]];x=[x>0,Math.abs(x)];
a.a+=(i>a.x?'>':'<').repeat(Math.abs(i-a.x))+(x[0]^x[1]>128?'+':'-').repeat(Math.min(x[1],256-x[1]))+'.';
a.i[i]++;a.x=i;return a;
},{x:0,a:'+'.repeat(s.init.i)+'['+s.init.a.map(x=>'>'+(x[0]>0?'+':'-').repeat(x[1])).join('')+'<'.repeat(s.init.a.length)+'-]>',i:new Array(s.a.length).fill(0)}).a;
return s;
};
main('Hello World!',10).x// >> "++++++++++++++[>+++++>+++++++>++>++++++<<<<-]>++.>+++.+++++++..+++.>++++.>+++.<<.+++.------.--------.>+."
今回のサンプル↓
https://mcbeeringi.github.io/amuse/bf_.html
去年のサンプル↓
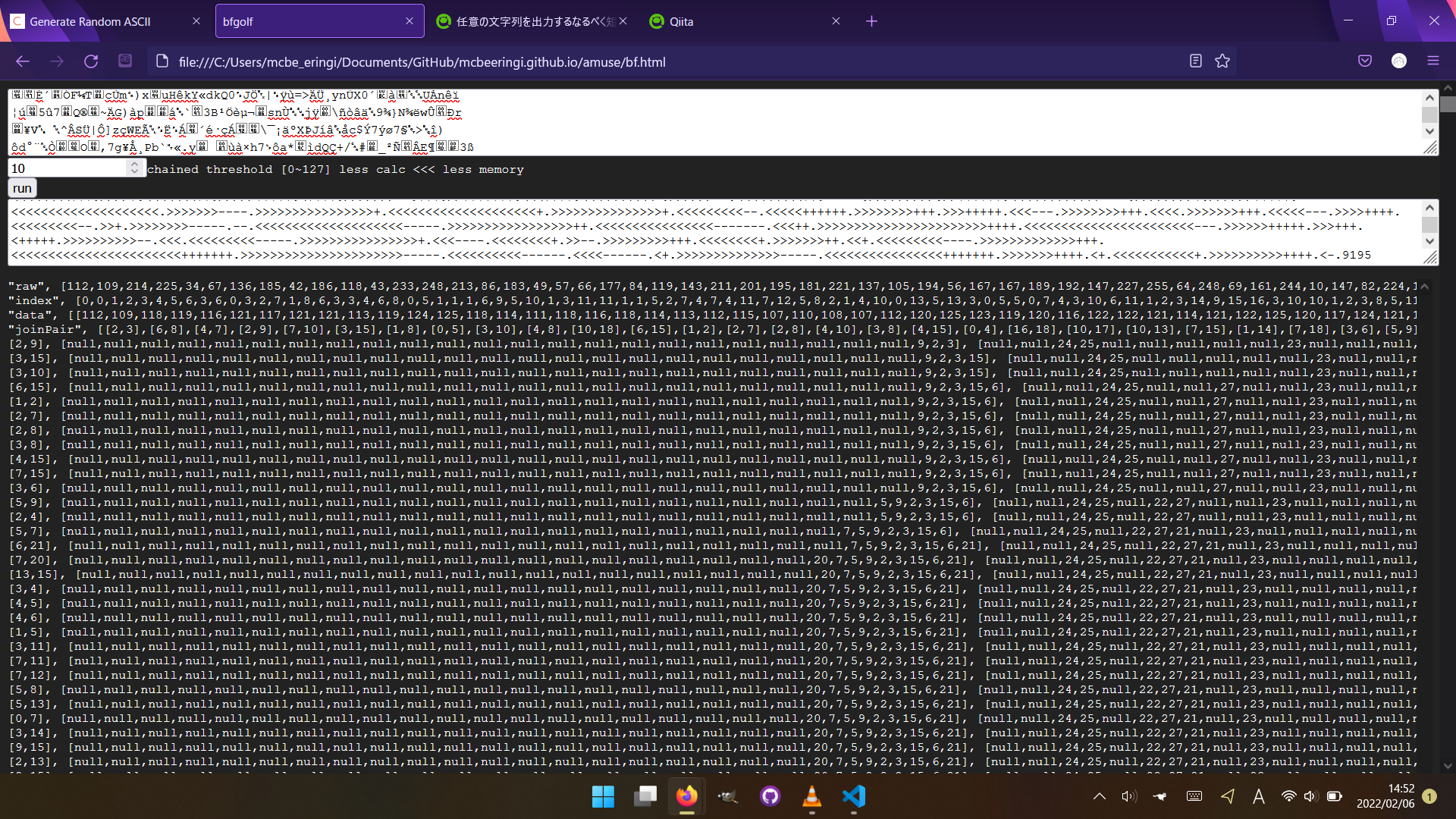
https://mcbeeringi.github.io/amuse/bf.html
効果あるの??
適当なサイトで生成した\u0000~\u00ffの羅列896字を去年のと今回のに投げる
去年: 9195字
今回: 8468字
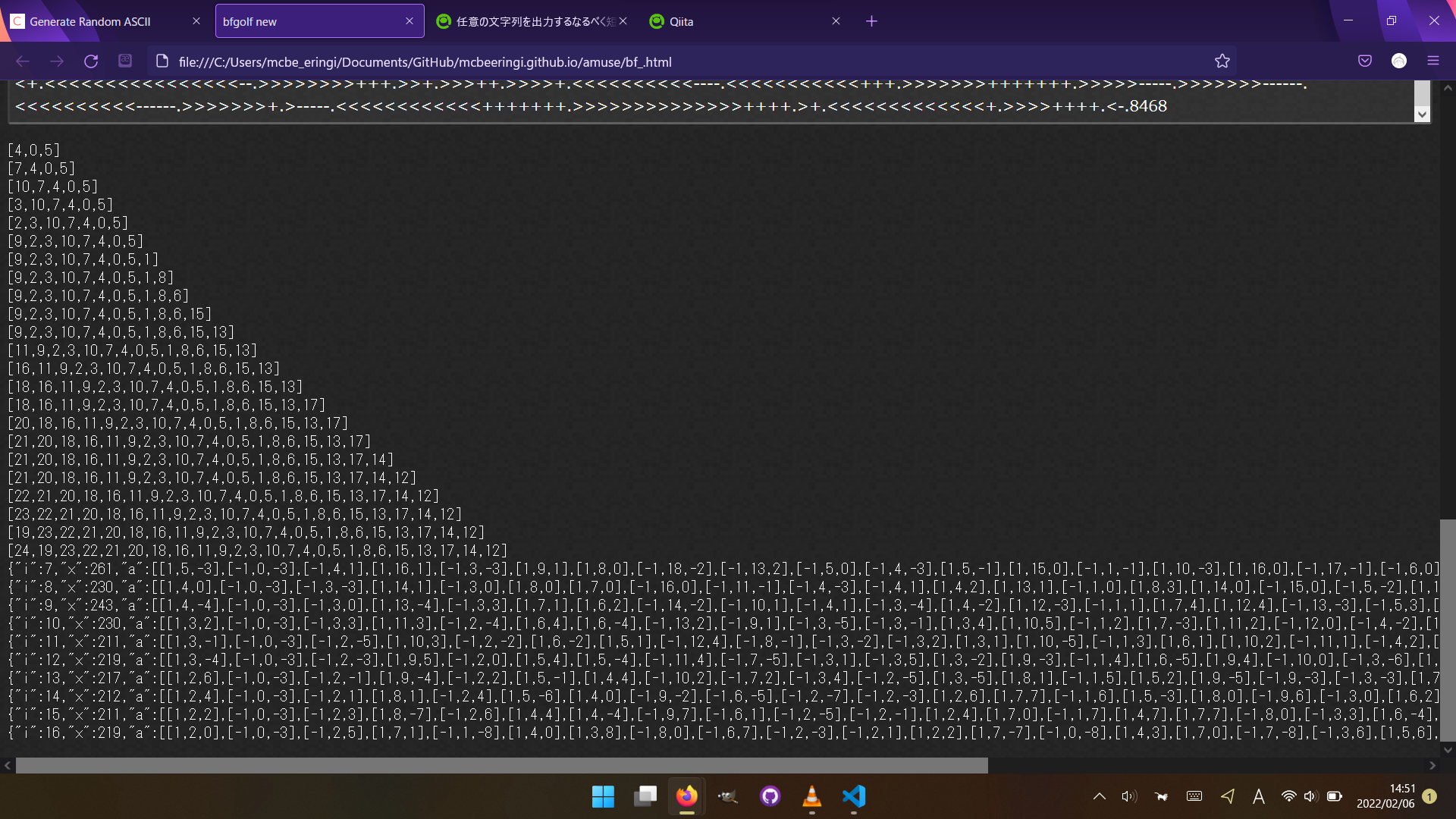
896字で8%の改善
コードも短くなって動作も早くなってこれは良いのでは?
めでたしめでたし~~
reduceとObject.fromEntriesを推していきたい