
こんにちは、まゆみです。
Pandasの記事をシリーズで書いています
今回は第18回目になります。
今回の記事では、Pandasの
.loc[]
.iloc[]
を詳しく解説していきます。(イラストを多用していますので初心者にも理解しやすいと思います)
前回までの記事では
DataFrame["コラム名"]を主に使い
あなたの抽出したいコラム名を取り出していました。
DataFrame["コラム名"]では、下記のイラストのように縦の列を基準にデータを抽出します(Ageと名のついたコラム1列が指定され、抽出したいなど)

.loc[] .iloc[] は、まず横のインデックスを基準に使い、データを抽出します(2番目の引数に、コラム名を書くと、指定しているインデックスとコラムが交差するデータも取り出すことができますが、それについては後述します)

例えば、Takeshi と名前の付いたインデックスを取り出したいなどに便利です。
この記事を読めば
- .loc[] .iloc[]の違い
- .loc[] .iloc[]のスライスとPythonのスライスとの違い
が分かります
ではさっそく始めていきますね。
今回使うデータ
今回は、『National Football League の選手のデータ』を使っていこうと思います
read_csv()で読み込むと下のようになります。
デフォルトのインデックスは数字になっています。
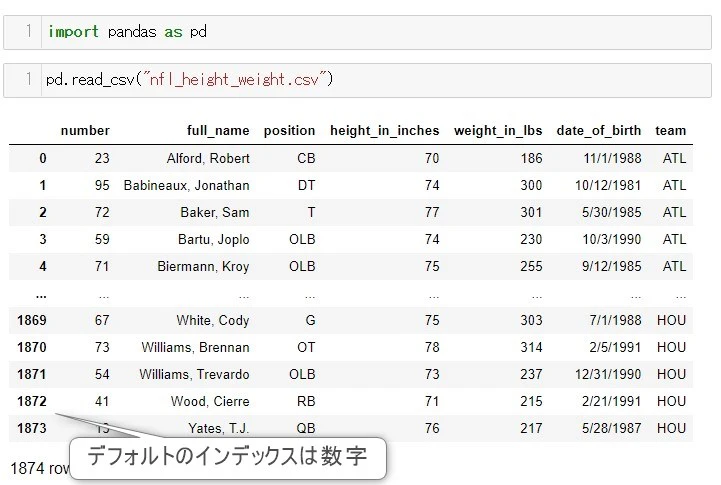
選手の名前を使ってデータを取り出したいので、デフォルトで数字になっているインデックスを
選手の名前(full_name コラム)をインデックスにします。
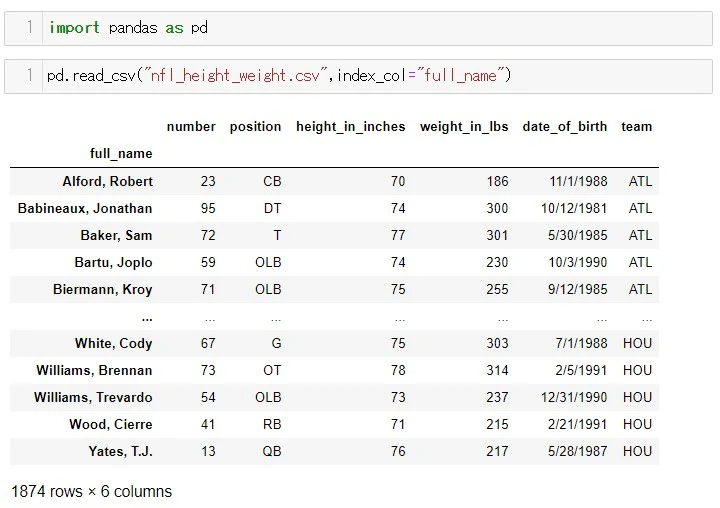
DataFrameの特定のコラムをインデックスにする

引用元:Pandasドキュメント
read_csv()メソッドの
パラメーター index_col=の引数を、インデックスにしたいコラム名
にします。
実行結果は下のようになります
あるコラムをインデックスにする方法、その2
コラムをインデックスにする方法は、もう一つあります
df.set_index("コラム名")
またset_index()メソッドの inplace = というパラメーターの引数をTrueに変えると、元々のデータが実行した結果に上書きされます。
※inplace の詳しい説明はこちらからどうぞ。
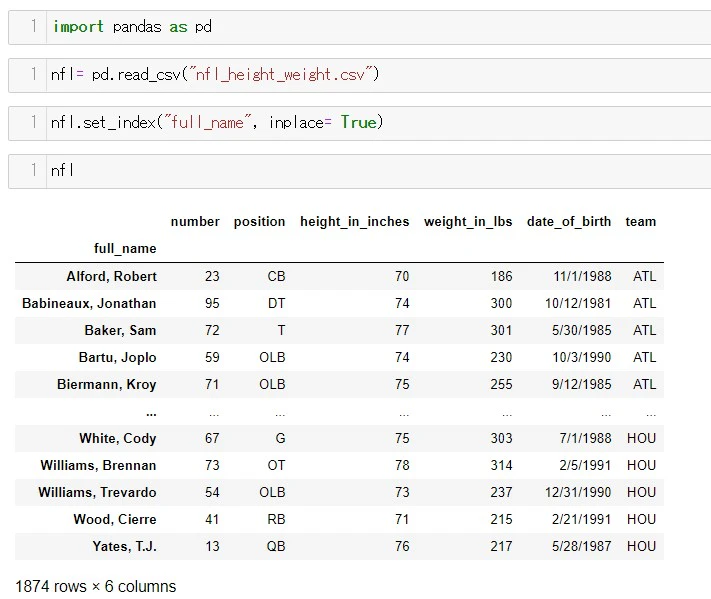
.set_index()でも、full_name のコラムをインデックスにできました。
read_csv()のパラメーターindex_colにコラム名を引数に取るか
.set_index()を使って、特定のコラムをインデックスにするか
した後、
.sort_index()でインデックスをアルファベット順に並べました。

では選手名をアルファベット順に並べ替えたこのDataFrameのインデックスを使って、いろんなデータの抽出法を書いていきます
.loc[]
インデックスにあるAbraham, Johnという名前の選手のデータを出してみます

row に並んでいる当該選手のデータが取れました。
Pythonのスライスも使える
.loc[]はPythonのスライスも使えます。
python のスライスの復習もさらっと書いておきますね
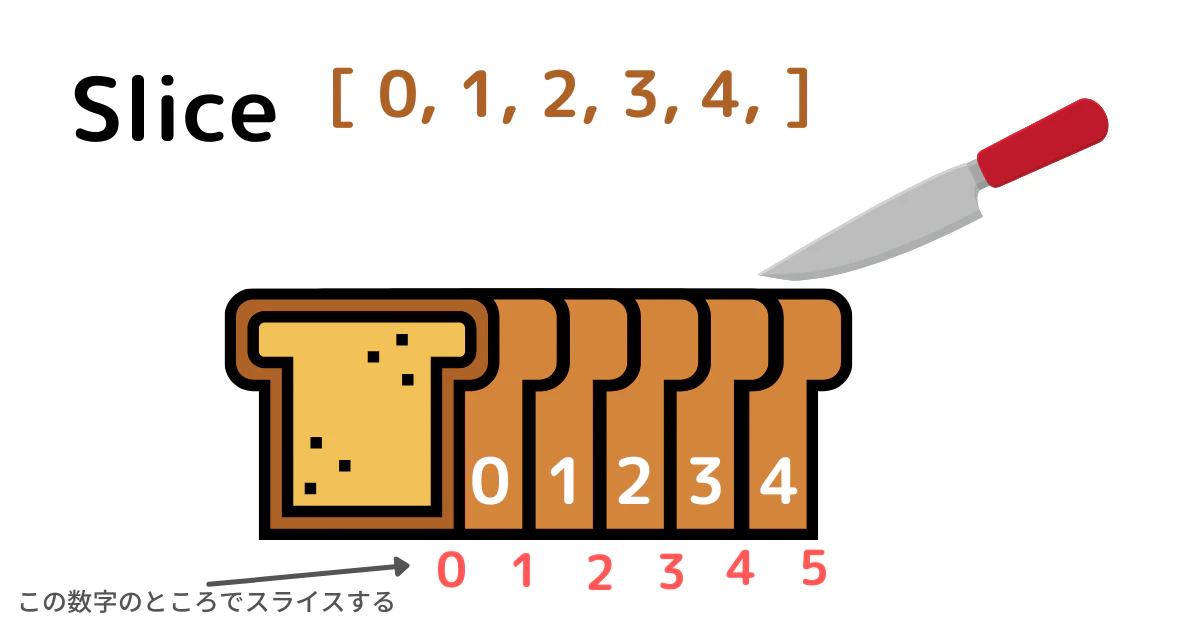
[start: stop: step]
start にはどこから始めるのか
stopは終わりはどこか
step はいくつ飛ばしで取り出すか を書く
ことになります
Pythonでスライスを使うと、stopの数字は含まないということに注意が必要です。
ややこしいですね。
ただ、パンをスライスするときを想像してみてください。(上のイラスト参考)
パンの一枚一枚は、リストの中のアイテムです。
その時[ 2: 5]とスライスしたいとすると、
上記のイラストのピンクの数字で書かれた2と5にナイフを入れることになります。
なので、取り出せるアイテムは
2, 3, 4 になります
Pythonのスライスの基本はこのように、 stopの数字は含まないです。
.loc[]のスライス Pythonのスライスとの違い
ではさっそく.loc[]でスライスを使ってみましょう
.loc[ "スタートのコラム名" : "ストップのコラム名" ]
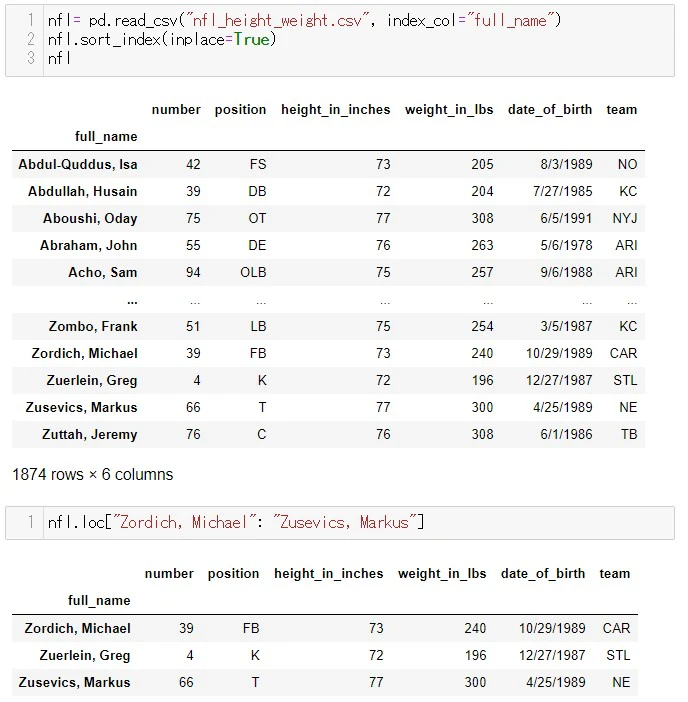
Pandas の.loc[]では、Pythonのスライスとは違い、stopの値も含まれます。
そこが相違点になりますので、注意が必要です。
ただ、他の点はPython のスライスも、Pandas .loc[]のスライスも同じになります
例えば、[ start: stop: 2] として、一つ飛ばしで表示させます
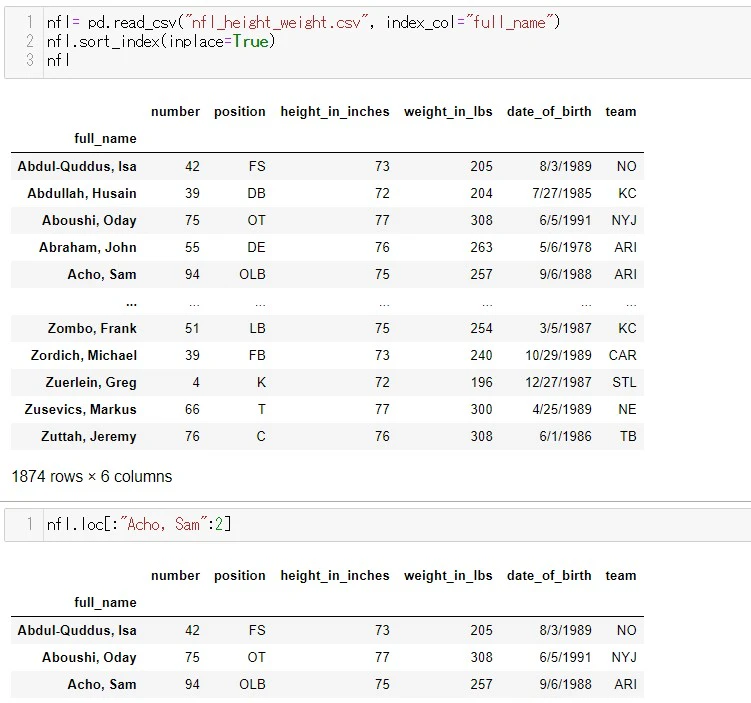
[ :stop] と書けば、一番最初からstopまでの範囲だし
[start: ] と書けば、指定したstart から最後までの範囲
を指定する事ができます
stopの値が含まれるのが違うだけで、あとの操作方法はPythonのスライスと同じです。
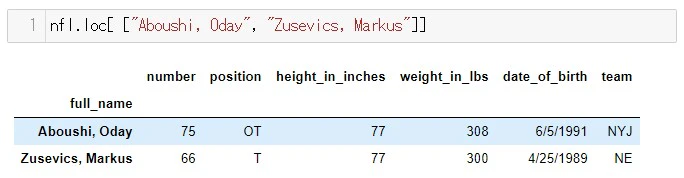
2つ以上のインデックスを指定するときはリスト型
では同様に、2人の選手のデータを取ってみましょう
その時引数は、リスト型にします
実行結果は以下のようになりました。
インデックスの指定範囲とコラムの指定範囲を組み合わせる

インデックスの範囲を3番目のインデックスから6番目のインデックス、コラムの範囲を3番目から4番目で組み合わせて、上のイラストのような範囲を取り出すこともできます
.loc[ インデックスの範囲、コラムの範囲 ]
で範囲を指定できます。

.iloc[]
では、もしインデックス名で指定をするのではなく、
2番目のインデックスにあるrow
とか
3番目から6番目のインデックスにあるrow
と、文字列ではなく、数字で指定したい場合の時を考えてみます。
その時に使えるのが
.iloc[] になります。
文字列か数列かの違いで、loc[] を使うか iloc[]を使うかという決まってくるということになりますが、使用方法は基本的に同じです
ただ、一つ気を付けないといけないのが、
iloc[ start : stop ]
と範囲を指定した時に、ilocの場合は stop の数字は含まないと、Pythonで使うスライスと同じになります
まとめ
今回の記事はこれくらいで終わりにします
また引き続きPandasの記事を書いていきますので、よろしくお願いします