
こんにちは、まゆみです。
Pandas についての記事をシリーズで書いています。
今回の記事は第13回目になります。
今回の記事では、データのなかに欠損値があった時の処理方法を色々と書いていこうと思います。
今回使うデータについて

引用元:kaggle.com
今回はkaggle.comさんのサイトからカナダのバンクーバーの犯罪についてのデータを使って欠損値の処理の例を書いていきます
いつも通り、read_csv()メソッドを使ってCSVファイルを読み込みました。
(CSVファイルの読み込み方が分からない方はこちらの記事を参考にどうぞ)
実行結果は以下のようになります

2003年から2017年までのデータなので、かなり膨大なrowの数値になっています。
データのところどころに書いてある『NaN』が欠損値を表しています。
dropna()メソッド

引用元:Pandasドキュメント
dropna()メソッドはPandasドキュメントに書いてあるように様々なパラメーターを取ることができます。
このパラメーターにどのような引数を取るかで、削除の仕方が変わってきますので、それぞれのパラメーターを一つづつ説明していきますね。
では具体的にコードを書きながら説明します
dropna() メソッドのパラメーター how

パラメーターhow には引数に
"any" か
"all" を取ることができます
"any"は『どんな欠損値でもある限りは』ということを意味し、『NaN』が一つでも存在する row は削除されます。
上の実行結果のスクショを見ていただくと分かると思いますが、インデックス番号530649には 『NaN』が一つ以上存在しているので、コードの実行結果では、そのrow が削除されています
次に、引数を"all" にした場合を説明します。
"all"を引数に取ると、row の全ての項目が『NaN』ではない限り、削除されることはありません。
コラム名で言うと、右端の『TYPE』から左端の『LONGTITUDE』まで全てが『NaN』の場合のことです。
パラメーターsubset
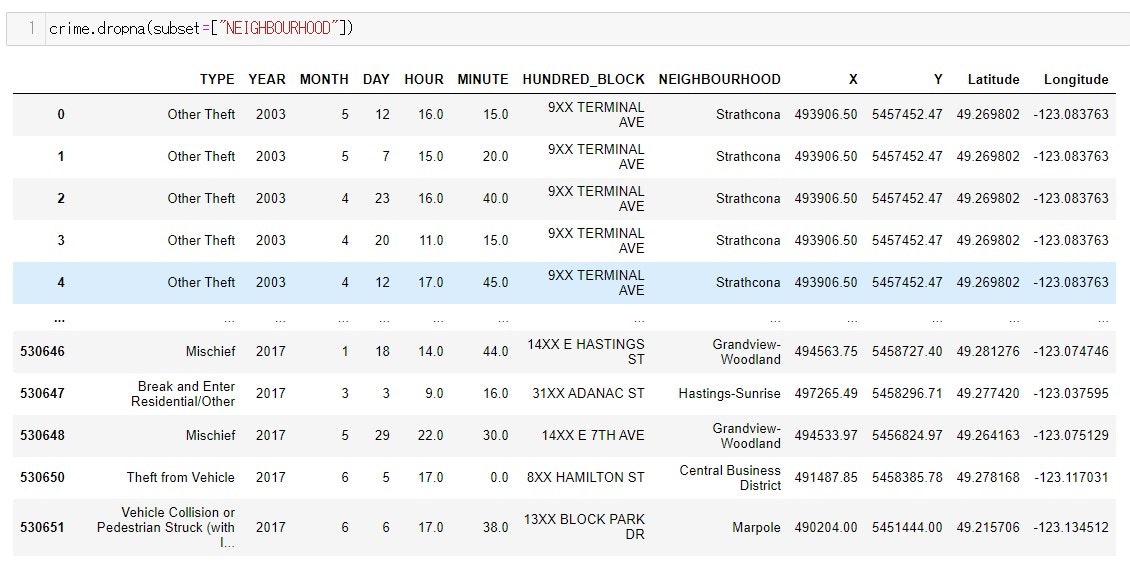
例えば、今回のデータでコラム名が『"NEIGHBOURHOOD"』に欠損値があるデータは削除したいけど、他のコラムに欠損値があっても使いたいとします
そのような時にsubsetの引数に『"NEIGHBOURHOOD"』とコラム名を書きます
『"NEIGHBOURHOOD"』以外のコラムに『NaN』があっても、そのrow は削除されません。
パラメーターinplace
inplace はこちらの記事でも詳しく説明しています。
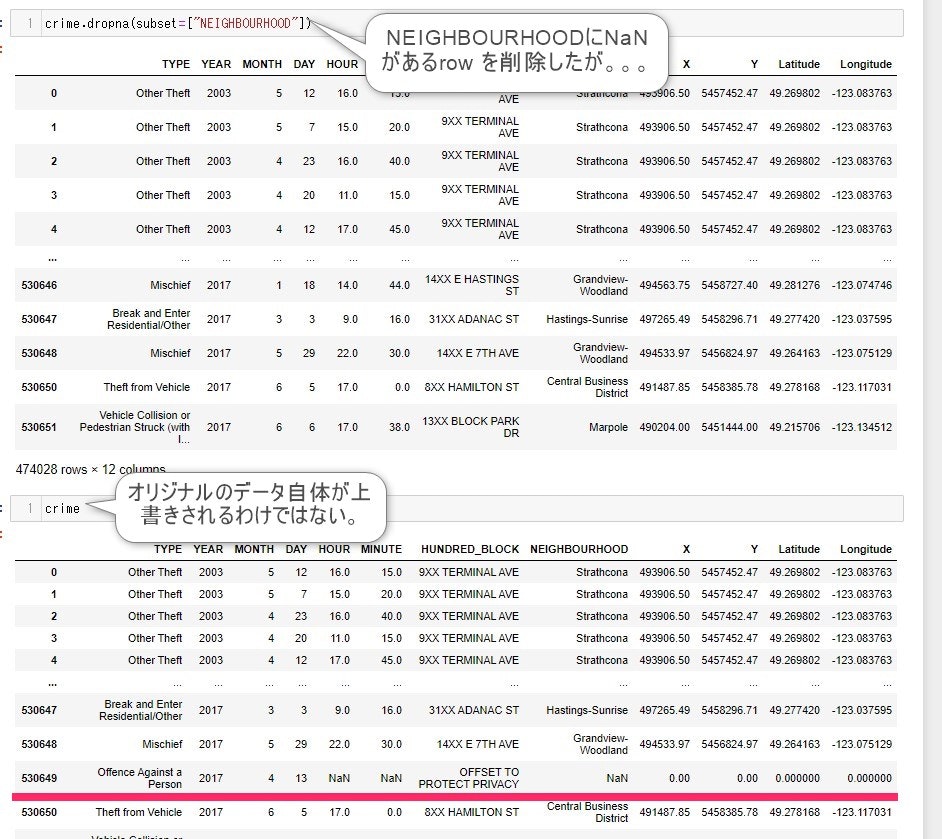
inplace = False がデフォルト値であり、デフォルトではinplace されません。
そのinplace とはどういうことかというと、元々のオリジナルのDataFrame をdropna() で実行した結果で上書きするというパラメーターです。
例を取って説明します
ただ、
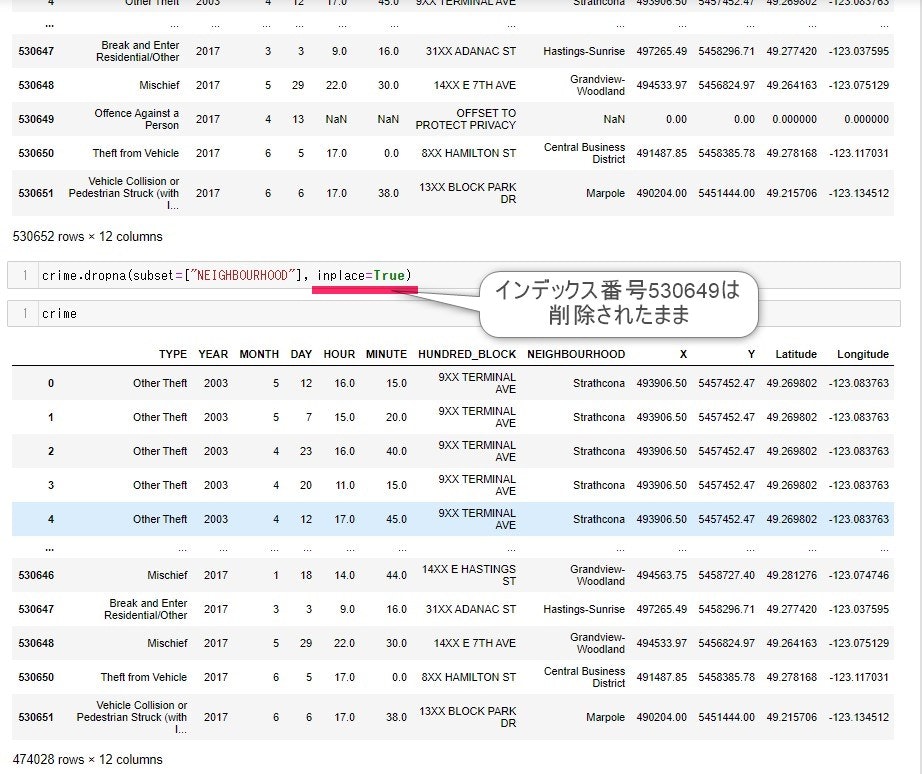
inplace= True
に変えますと、下記のようになります
パラメーターaxis

axis は軸のことで、デフォルト値0はインデックスを表します。
axis=1
に変えますと、軸が縦方向に変わり、コラムのなかに『NaN』があるかどうかをPandas が探してくれて、そのコラムを削除してくれます。

columns の数が、8まで減っています
欠損値があるrow やcolumnを削除する方法はこれくらいで終わりにします。
では次に、削除するのではなく、『欠損値だと分かるように何かで穴埋めしたい時』はどうしたら良いのでしょうか?
その方法を次に書いていきますね。
fillna()メソッド

引用元:Pandasドキュメント
NA/NaNの値になっている部分を埋めてくれます。

上記のスクショには、コラム名『HOUR』『MINUTE』『NEIGHBORHOOD』に『NaN』の欠損値をもつrow があります。
ただ、HOUR や MINUTE は 『0』で穴埋めしたいけど『NEIGHBORHOOD』は『UNKNOWN』と穴埋めしたいとします。
![DataFrame名[コラム名].fillna(埋めたい数値or文字列).png](https://qiita-user-contents.imgix.net/https%3A%2F%2Fqiita-image-store.s3.ap-northeast-1.amazonaws.com%2F0%2F1011305%2F056a9ff6-ee9e-b588-d53c-b979472dc915.png?ixlib=rb-4.0.0&auto=format&gif-q=60&q=75&s=9e0ea2115df02f648d6779ef76743b10)
ただこのままですと、オリジナルのDataFrameを呼び出した時には、また元のデータに戻ってしまうので、パラメーターinplace = True とします
実行結果は下のようになります

さらに、NEIGHBORHOOD のNaN をunknown にして欠損値を穴埋めします
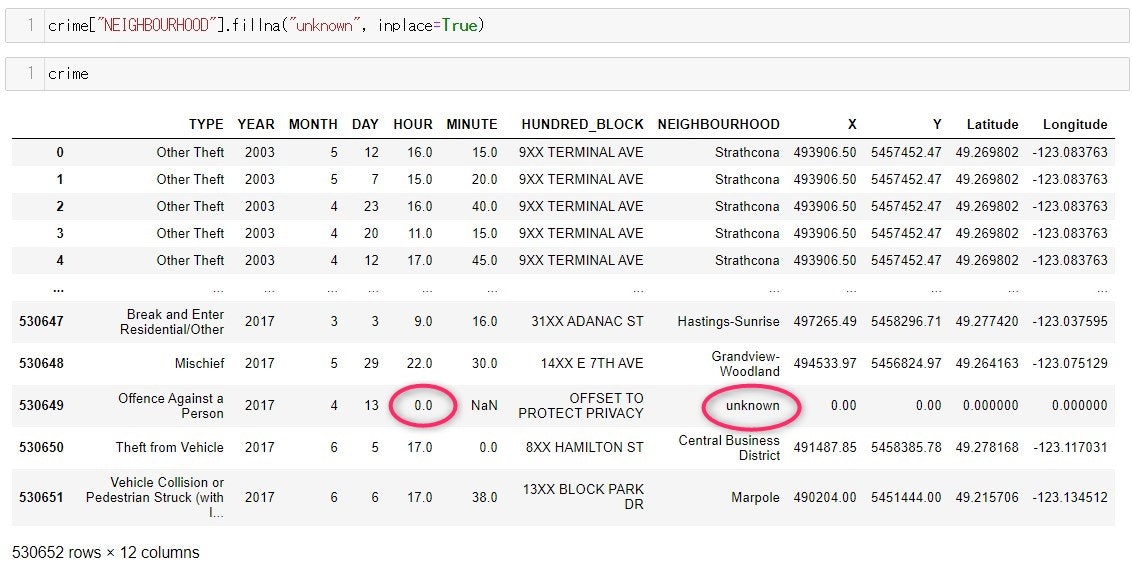
HOURの欠損値が0で上書きされたまま、さらにNEIGHBOURHOOD の欠損値も書き換えることができました。
まとめ
今回は欠損値の処理の仕方を色々と集めてみました。
次回の記事では、データの並べ替えについて書いていきたいと思います