本来、このWriteupが初投稿になる予定でしたが、自分が解いた問題を全部解説しようとした結果、やる気が雲散霧消してしまいました・・・
Reverse(とGeneral Skills)は全部書いていたので、その部分だけでも投稿しておこうと思います。
General Skills
FANTASY CTF (10 points)
CTFにありがちな最初の問題。文章を読み進めていく昔のテキストアドベンチャーゲームのような感じ。
途中に出てくる選択肢で正しいものを選ぶとフラグが取得できるらしい。
最初の問題としてはだいぶ凝ってる感じで良き。
最初の問題とか言いながら実は解いたのは5番目くらいなのはナイショ。
Enterで読み進めていき、最初の選択肢でc、次の選択肢でaを選択するとフラグを取得できる。
picoCTF{m1113n1um_3d1710n_da2cd4b9}
Reverse Engineering
Flag Hunters (75 points)
ソースコードが渡されるので、読み解いてフラグを出力させる問題。
ソースコードは長いので折り畳み。
lyric-reader.py
import re
import time
# Read in flag from file
flag = open('flag.txt', 'r').read()
secret_intro = \
'''Pico warriors rising, puzzles laid bare,
Solving each challenge with precision and flair.
With unity and skill, flags we deliver,
The ether’s ours to conquer, '''\
+ flag + '\n'
song_flag_hunters = secret_intro +\
'''
[REFRAIN]
We’re flag hunters in the ether, lighting up the grid,
No puzzle too dark, no challenge too hid.
With every exploit we trigger, every byte we decrypt,
We’re chasing that victory, and we’ll never quit.
CROWD (Singalong here!);
RETURN
[VERSE1]
Command line wizards, we’re starting it right,
Spawning shells in the terminal, hacking all night.
Scripts and searches, grep through the void,
Every keystroke, we're a cypher's envoy.
Brute force the lock or craft that regex,
Flag on the horizon, what challenge is next?
REFRAIN;
Echoes in memory, packets in trace,
Digging through the remnants to uncover with haste.
Hex and headers, carving out clues,
Resurrect the hidden, it's forensics we choose.
Disk dumps and packet dumps, follow the trail,
Buried deep in the noise, but we will prevail.
REFRAIN;
Binary sorcerers, let’s tear it apart,
Disassemble the code to reveal the dark heart.
From opcode to logic, tracing each line,
Emulate and break it, this key will be mine.
Debugging the maze, and I see through the deceit,
Patch it up right, and watch the lock release.
REFRAIN;
Ciphertext tumbling, breaking the spin,
Feistel or AES, we’re destined to win.
Frequency, padding, primes on the run,
Vigenère, RSA, cracking them for fun.
Shift the letters, matrices fall,
Decrypt that flag and hear the ether call.
REFRAIN;
SQL injection, XSS flow,
Map the backend out, let the database show.
Inspecting each cookie, fiddler in the fight,
Capturing requests, push the payload just right.
HTML's secrets, backdoors unlocked,
In the world wide labyrinth, we’re never lost.
REFRAIN;
Stack's overflowing, breaking the chain,
ROP gadget wizardry, ride it to fame.
Heap spray in silence, memory's plight,
Race the condition, crash it just right.
Shellcode ready, smashing the frame,
Control the instruction, flags call my name.
REFRAIN;
END;
'''
MAX_LINES = 100
def reader(song, startLabel):
lip = 0
start = 0
refrain = 0
refrain_return = 0
finished = False
# Get list of lyric lines
song_lines = song.splitlines()
# Find startLabel, refrain and refrain return
for i in range(0, len(song_lines)):
if song_lines[i] == startLabel:
start = i + 1
elif song_lines[i] == '[REFRAIN]':
refrain = i + 1
elif song_lines[i] == 'RETURN':
refrain_return = i
# Print lyrics
line_count = 0
lip = start
while not finished and line_count < MAX_LINES:
line_count += 1
for line in song_lines[lip].split(';'):
if line == '' and song_lines[lip] != '':
continue
if line == 'REFRAIN':
song_lines[refrain_return] = 'RETURN ' + str(lip + 1)
lip = refrain
elif re.match(r"CROWD.*", line):
crowd = input('Crowd: ')
song_lines[lip] = 'Crowd: ' + crowd
lip += 1
elif re.match(r"RETURN [0-9]+", line):
lip = int(line.split()[1])
elif line == 'END':
finished = True
else:
print(line, flush=True)
time.sleep(0.5)
lip += 1
reader(song_flag_hunters, '[VERSE1]')
プログラムの内容はハードコードされた歌詞を出力するというもの。
歌詞の中にはフラグのテキストファイルの内容も含まれているが、通常では表示されることはない。
途中、Crowd(観衆)の歌詞の部分を入力するように言われるので、うまいことこれを利用しなければならない。
ソースコードを読み解いていくとlipという変数が現在の歌詞の位置で、song_linesのlip番目をさらに、;セミコロンで分割したものが一行という扱いになっている。
歌詞を出力する(歌う)とlipに1が加算され、ENDを踏むまでforループする。
特殊なコマンドとして、REFRAIN、CROWD、RETURNが存在する。
行が以上のどれかと一致する場合、そのコマンド特有の命令を実行するという形。
REFRAINは歌詞の[REFRAIN]の部分に飛び、RETURN命令がある行をRETURN [REFRAINを踏んだ行の位置]に変更する。(つまり、[REFREAIN]部分を歌い終わると元の歌詞の最後に歌った部分へ戻り、そこから続きを歌う)
CROWDは初めて踏んだとき、ユーザーにCrowdの歌詞の部分の入力を求め、以降は入力した歌詞を歌うようになる。
RETURNはRETURN 0のような形で使い、現在の歌詞の位置lipをその数字に変更する。
フラグを含む歌詞は先頭にあるので、どうにかしてlipを0にするのが目標。
この中でlipを0にできそうなのはRETURNコマンドしかないのでこれを実行したい。
;で歌詞が分割されることを利用し、Crowdの入力でRETURN 0を紛れ込ませる。
Crowdの入力を求められたら;RETURN 0と入力し、少し待つとフラグが出力される。
picoCTF{70637h3r_f0r3v3r_710a5048}
Binary Instrumentation 1 (200 points)
リバースエンジニアリングツールを使用する問題。
解いた人数を見ると、他の問題と比べて意外と少ない。
bininst1.exeというファイルが渡されるので、実行してみると次のような文章が表示されて待機状態に。
Hi, I have the flag for you just right here!
I'll just take a quick nap before I print it out for you, should only take me a decade or so!
zzzzzzzz....
最初はGhidraを使ってアセンブリコードを覗いてみたのだが、どうも出力された文章に関係するところが存在しない。
というかdataセグメントにもこんな文字列は見当たらない。一体どうなっているんだ・・・
静的解析は諦めて、動的解析にチェンジ。
IDA Freeのデバッグ機能を使い、動かしてみる。

一体どこでこの文字列が出力されているのか見てみたのだが、
この最後のcall命令にたどり着くまで結局文字が出力されることはなかった。
このcall命令をステップインして文字を出力するところをさらに探す。
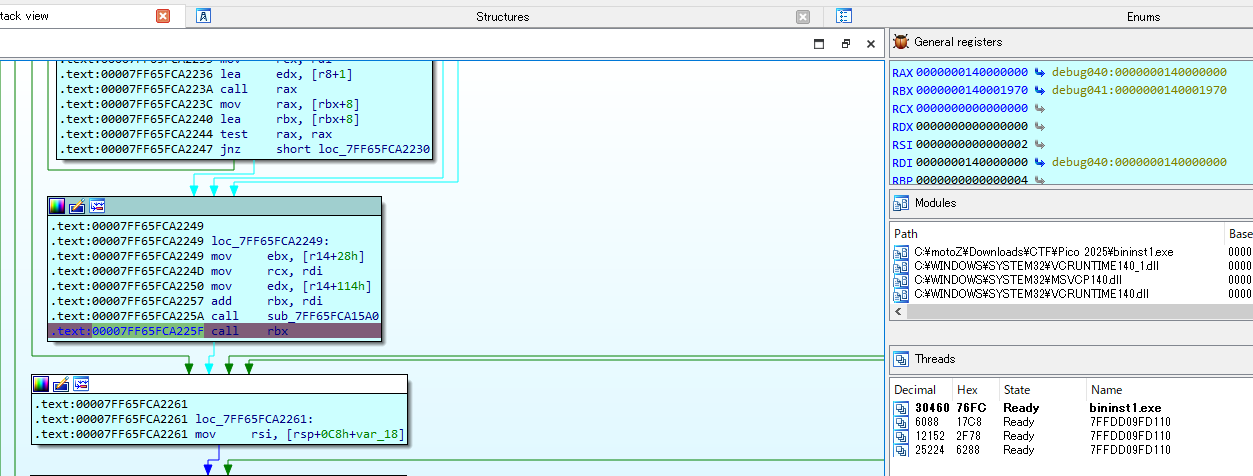
探すとこのcall命令実行後に待機状態になる。ジャンプ先のrbxを見てみるとテキストセグメント外にジャンプしているのがわかる。
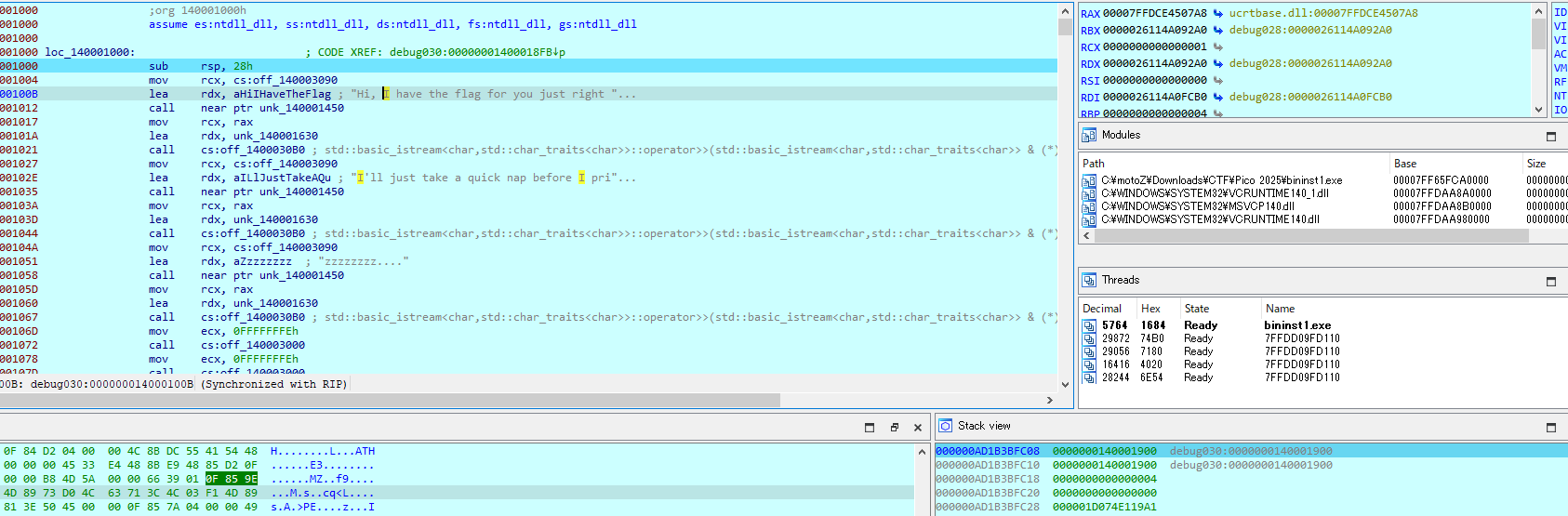
ジャンプ先をさらに探索してようやく本命のプログラムを発見。どうやらメッセージを出力してからkernel32.dllのsleep関数を86回コールするようだ。引数1はすべて4294967294に設定されているので、何もツールを使用しない場合、実に369,367,187,284ミリ秒、約11.7年ほど待てばフラグが入手できる。

もちろんそこまで待ってられないので、RIPを最後のsleep関数の次の行まで強制移動させる。
画像のように右クリックすると項目があらわれるのでSet IPをクリック。
するとプログラムが長い眠りから覚め、以下の文を出力する。
Ok, I'm Up! The flag is: cGljb0NURnt3NGtlX20zX3VwX3cxdGhfZnIxZGFfZjI3YWNjMzh9
:より後ろをBase64でデコードしてフラグを取得。
picoCTF{w4ke_m3_up_w1th_fr1da_f27acc38}
Tap into Hash (200 points)
ソースコードと暗号化されたファイルが渡される。
block_chain.py
import time
import base64
import hashlib
import sys
import secrets
class Block:
def __init__(self, index, previous_hash, timestamp, encoded_transactions, nonce):
self.index = index
self.previous_hash = previous_hash
self.timestamp = timestamp
self.encoded_transactions = encoded_transactions
self.nonce = nonce
def calculate_hash(self):
block_string = f"{self.index}{self.previous_hash}{self.timestamp}{self.encoded_transactions}{self.nonce}"
return hashlib.sha256(block_string.encode()).hexdigest()
def proof_of_work(previous_block, encoded_transactions):
index = previous_block.index + 1
timestamp = int(time.time())
nonce = 0
block = Block(index, previous_block.calculate_hash(),
timestamp, encoded_transactions, nonce)
while not is_valid_proof(block):
nonce += 1
block.nonce = nonce
return block
def is_valid_proof(block):
guess_hash = block.calculate_hash()
return guess_hash[:2] == "00"
def decode_transactions(encoded_transactions):
return base64.b64decode(encoded_transactions).decode('utf-8')
def get_all_blocks(blockchain):
return blockchain
def blockchain_to_string(blockchain):
block_strings = [f"{block.calculate_hash()}" for block in blockchain]
return '-'.join(block_strings)
def encrypt(plaintext, inner_txt, key):
midpoint = len(plaintext) // 2
first_part = plaintext[:midpoint]
second_part = plaintext[midpoint:]
modified_plaintext = first_part + inner_txt + second_part
block_size = 16
plaintext = pad(modified_plaintext, block_size)
key_hash = hashlib.sha256(key).digest()
ciphertext = b''
for i in range(0, len(plaintext), block_size):
block = plaintext[i:i + block_size]
cipher_block = xor_bytes(block, key_hash)
ciphertext += cipher_block
return ciphertext
def pad(data, block_size):
padding_length = block_size - len(data) % block_size
padding = bytes([padding_length] * padding_length)
return data.encode() + padding
def xor_bytes(a, b):
return bytes(x ^ y for x, y in zip(a, b))
def generate_random_string(length):
return secrets.token_hex(length // 2)
random_string = generate_random_string(64)
def main(token):
key = bytes.fromhex(random_string)
print("Key:", key)
genesis_block = Block(0, "0", int(time.time()), "EncodedGenesisBlock", 0)
blockchain = [genesis_block]
for i in range(1, 5):
encoded_transactions = base64.b64encode(
f"Transaction_{i}".encode()).decode('utf-8')
new_block = proof_of_work(blockchain[-1], encoded_transactions)
blockchain.append(new_block)
all_blocks = get_all_blocks(blockchain)
blockchain_string = blockchain_to_string(all_blocks)
encrypted_blockchain = encrypt(blockchain_string, token, key)
print("Encrypted Blockchain:", encrypted_blockchain)
if __name__ == "__main__":
text = sys.argv[1]
main(text)
enc_flag
Key: b'\xa9\xcco`\xfa\xf9\xb5\xc0\xda\xf6*\xb3\xbe\xa9t\x0fi\xae\x13\x01q-\xae\x9ap\xb7\xa45\x1e{\xaa\xb4'
Encrypted Blockchain: b'\xf7Y\x8db\x8bS\xb2\x80q\xf2\xa0\x87\xd6(\xfc\xe6\xf2\\\x82`\x8c\\\xb4\xd4v\xf0\xf2\xd1\xde/\xfa\xb0\xfb]\xdfg\x8bV\xe2\xd1$\xa5\xa6\xd9\x8c+\xa8\xe7\xa6X\x82d\xda\x01\xb1\x85u\xa4\xa3\xd3\xda}\xff\xbc\xeeZ\x8am\x8d\x01\xb1\x84$\xa1\xf4\x85\x8c,\xfa\xe7\xf0S\x8f4\x8f\x02\xb1\x82w\xf1\xf6\x85\xd7/\xff\xb3\xa6]\xdf`\x8b\x00\xe3\xd1"\xf2\xf6\xd8\xda|\xfd\xb7\xf3Z\xd83\xdc\\\xbe\xd6!\xa2\xae\xd8\x8c{\xfa\xb0\xf2G\x8ae\x8a\x01\xe3\xd7q\xf4\xa3\xd9\x8aq\xfd\xbd\xfb\x08\x8ag\x8dQ\xe3\xd0"\xa4\xf2\x84\xdeq\xac\xb5\xf4\x0e\xca<\xdd\x0b\xc5\xe6U\xbc\xf5\x8d\x81*\xa6\xdb\xf09\xe8=\xe8\r\xd4\xd0G\xf6\xe6\x82\xb6\x16\x95\xd1\xa9\'\x8a\'\x8a]\xe5\xfaL\xb6\xd4\x9b\x83\x03\x97\xfe\x81!\xe5a\x87\\\xbf\xd4*\xa2\xf6\x9c\xdex\xf4\xe5\xf6R\x8em\x87W\xb1\x80 \xf5\xf4\xd6\x8a{\xfd\xe7\xf3\x08\x89d\xdfP\xb2\x82u\xf4\xa0\x80\xc3y\xfd\xb2\xa5[\x83m\x8dQ\xe5\x84+\xfe\xa5\x84\xd7p\xf4\xb6\xf1S\x89m\xddQ\xb0\xd7&\xf2\xf2\xd3\x8b,\xf9\xb5\xfa\x08\xd8f\x8c\\\xe5\xd7"\xf3\xf6\xd4\x8c|\xac\xe5\xa7\x08\x8ag\x8d\x02\xbe\xd1$\xa2\xa3\x80\x8ad\xfd\xb4\xa6]\xdc0\xd8W\xb1\x85q\xa5\xf6\x80\xdbq\xa9\xb5\xf0_\xdee\x8e\x00\xbe\xd3r\xf4\xa2\xd4\x88y\xf4\xb0\xa5_\xdc4\xda\x05\xb7\x80r\xf1\xa3\x84\x8ap\xfb\xb2\xfa\x08\x8c`\x8eR\xe3\x81q\xfe\xae\x84\x88x\xcf\x86'
試しに適当に引数を追加してソースコードを実行すると、enc_flagと同じような内容が出力される。
引数の文字列を使用して暗号化されているので、enc_flagを出力する引数はなんなのかを当てる問題。
ソースコードをじっくり読み、仕様を一個一個確認しながら暗号化の手順を見てみたのだが・・・
どうやら引数に渡した文字列は最後の工程にしか使用されていないらしい。
本当に最後に出てくるのみで、それより前はブロックチェーンなるものを作成していたりと複雑そうなのだが、最後の工程で使用する情報が引数以外すべてenc_flagに開示されているため、その工程の逆を実行するだけで済んでしまう。
def encrypt(plaintext, inner_txt, key):
midpoint = len(plaintext) // 2
first_part = plaintext[:midpoint]
second_part = plaintext[midpoint:]
modified_plaintext = first_part + inner_txt + second_part
block_size = 16
plaintext = pad(modified_plaintext, block_size)
key_hash = hashlib.sha256(key).digest()
ciphertext = b''
for i in range(0, len(plaintext), block_size):
block = plaintext[i:i + block_size]
cipher_block = xor_bytes(block, key_hash)
ciphertext += cipher_block
return ciphertext
これが最後の工程の部分。
plaintextは時刻に基づいて生成されたフラグと無関係の文字列。
inner_txtは今回のフラグ。
keyはenc_flagにも書いてあるバイト列。
まずはplaintextを前半部分と後半に分け、間にinner_txtを入れている。これを新たなplaintextとする。
次にkeyをSHA-256で暗号化し、key_hashとする。
あとはblock_size分(16文字)ずつplaintextから文字を取り、key_hashと取り出した文字でXORを実行し、これらの文字をすべてつなげて暗号化された文字列(enc_flag中のEncrypted Blockchain)が完成する。
ということで、この操作を逆に実行するコードを作成する。
XORされたものは同じ値でもう一度XORすると元に戻る。(blockをkey_hashで2回XORしたものはblockと同じ)
Encrypted Blockchainはblockをkey_hashで1回XORしたものなので、もう一回key_hashでXORすると元のblockに戻る。
ということでEncrypted Blockchainを16バイトずつ取り出し、key_hashでXORしてこれらの文字をすべてつなげる。
最終的に実行したコードがこちら。
import hashlib
key = b'\xa9\xcco`\xfa\xf9\xb5\xc0\xda\xf6*\xb3\xbe\xa9t\x0fi\xae\x13\x01q-\xae\x9ap\xb7\xa45\x1e{\xaa\xb4'
encryptedBlockchain = b'\xf7Y\x8db\x8bS\xb2\x80q\xf2\xa0\x87\xd6(\xfc\xe6\xf2\\\x82`\x8c\\\xb4\xd4v\xf0\xf2\xd1\xde/\xfa\xb0\xfb]\xdfg\x8bV\xe2\xd1$\xa5\xa6\xd9\x8c+\xa8\xe7\xa6X\x82d\xda\x01\xb1\x85u\xa4\xa3\xd3\xda}\xff\xbc\xeeZ\x8am\x8d\x01\xb1\x84$\xa1\xf4\x85\x8c,\xfa\xe7\xf0S\x8f4\x8f\x02\xb1\x82w\xf1\xf6\x85\xd7/\xff\xb3\xa6]\xdf`\x8b\x00\xe3\xd1"\xf2\xf6\xd8\xda|\xfd\xb7\xf3Z\xd83\xdc\\\xbe\xd6!\xa2\xae\xd8\x8c{\xfa\xb0\xf2G\x8ae\x8a\x01\xe3\xd7q\xf4\xa3\xd9\x8aq\xfd\xbd\xfb\x08\x8ag\x8dQ\xe3\xd0"\xa4\xf2\x84\xdeq\xac\xb5\xf4\x0e\xca<\xdd\x0b\xc5\xe6U\xbc\xf5\x8d\x81*\xa6\xdb\xf09\xe8=\xe8\r\xd4\xd0G\xf6\xe6\x82\xb6\x16\x95\xd1\xa9\'\x8a\'\x8a]\xe5\xfaL\xb6\xd4\x9b\x83\x03\x97\xfe\x81!\xe5a\x87\\\xbf\xd4*\xa2\xf6\x9c\xdex\xf4\xe5\xf6R\x8em\x87W\xb1\x80 \xf5\xf4\xd6\x8a{\xfd\xe7\xf3\x08\x89d\xdfP\xb2\x82u\xf4\xa0\x80\xc3y\xfd\xb2\xa5[\x83m\x8dQ\xe5\x84+\xfe\xa5\x84\xd7p\xf4\xb6\xf1S\x89m\xddQ\xb0\xd7&\xf2\xf2\xd3\x8b,\xf9\xb5\xfa\x08\xd8f\x8c\\\xe5\xd7"\xf3\xf6\xd4\x8c|\xac\xe5\xa7\x08\x8ag\x8d\x02\xbe\xd1$\xa2\xa3\x80\x8ad\xfd\xb4\xa6]\xdc0\xd8W\xb1\x85q\xa5\xf6\x80\xdbq\xa9\xb5\xf0_\xdee\x8e\x00\xbe\xd3r\xf4\xa2\xd4\x88y\xf4\xb0\xa5_\xdc4\xda\x05\xb7\x80r\xf1\xa3\x84\x8ap\xfb\xb2\xfa\x08\x8c`\x8eR\xe3\x81q\xfe\xae\x84\x88x\xcf\x86'
def decrypt(encrypted, key):
block_size = 16
unXor = b''
key_hash = hashlib.sha256(key).digest()
for i in range(0, len(encrypted), block_size):
block = encrypted[i:i + block_size]
uncipher_block = xor_bytes(block, key_hash)
unXor += uncipher_block
return unXor
# from block_chain.py
def xor_bytes(a, b):
return bytes(x ^ y for x, y in zip(a, b))
print(decrypt(encryptedBlockchain, key))
出力:
b'43775742b57f8a1b1685282fe7e00f7487e252dc7b18bbece281de77fc424428-
0083e767fcdbe7c395a1f70d6ad9f27e7e55dec15a9450300bfb88d2e99b2741-
004eeeb348d8098b0235eb1cee08a17dpicoCTF{block_3SRhViRbT1qcX_XUjM0r49cH_qCzmJZzBK_4989f9ea}019a5
848937232c7d20c0b31a440f37a-006f19835c6892e99922938c56e55e2ee419bb328ce14a5b5aadb023f8c7e4ad-
00e7fef377bbaa58d135d00d8aa355f094f5fada12a64ed9669b6506e3b99ef1\x02\x02'
無関係な文字列を消去してフラグを取得。
picoCTF{block_3SRhViRbT1qcX_XUjM0r49cH_qCzmJZzBK_4989f9ea}
Chronohack (200 points)
ncコマンドで接続すると以下の文章が出てくる。
Welcome to the token generation challenge!
Can you guess the token?
Enter your guess for the token (or exit):
どうやら50試行以内にトークンを当てればいいらしい。
当然わかるはずがないので、問題文にあったソースコードを見てみる。
token_generator.py
import random
import time
def get_random(length):
alphabet = "0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz"
random.seed(int(time.time() * 1000)) # seeding with current time
s = ""
for i in range(length):
s += random.choice(alphabet)
return s
def flag():
with open('/flag.txt', 'r') as picoCTF:
content = picoCTF.read()
print(content)
def main():
print("Welcome to the token generation challenge!")
print("Can you guess the token?")
token_length = 20 # the token length
token = get_random(token_length)
try:
n=0
while n < 50:
user_guess = input("\nEnter your guess for the token (or exit):").strip()
n+=1
if user_guess == "exit":
print("Exiting the program...")
break
if user_guess == token:
print("Congratulations! You found the correct token.")
flag()
break
else:
print("Sorry, your token does not match. Try again!")
if n == 50:
print("\nYou exhausted your attempts, Bye!")
except KeyboardInterrupt:
print("\nKeyboard interrupt detected. Exiting the program...")
if __name__ == "__main__":
main()
ソースコードを見ると、time.time()関数を乱数のシード値として扱っている。
time.time()は現在のUNIX時間を取得し、それをfloatで返すもので、1000倍しているのはミリ秒を含めるためだ。
そして設定したシード値をベースにトークンを生成している。
実は今回の問題の中では一番時間がかかったのがこれ。悪用できそうなところが最初見当たらなかった。なんとかトークンを取得する方法を考え、特定の時間になったらコマンドを送信することも試したが、うまくいかない。
Chronohackという名前が「時」に関係するため、やはり乱数生成の部分が関係しているのだろうが、time.time()が実行されるときの時間を正確に取得するなんて無理では?と思っていた。詰まったのでヒントを見てみると、最後のヒントにこんなことが書いてあった。
Generate tokens for a range of seed values very close to the target time (目標の時間に非常に近い範囲のシードでトークンを生成しろ)
つまり、ncコマンドを実行したときの時間はわかるので、time.time()で取得した時間は"だいたい"ならわかる。ncコマンドで接続したときにこのpythonファイルが実行されるからだ。あとは正解が出るまでシード値を1つずつ試していけばいい。
ジャスト正解を求めるのではなく、当たるまで試していくという、いわゆるブルートフォース攻撃で突破するというのが答えだった。
LinuxでUNIX時間をミリ秒まで含めて表示させるコマンドとncコマンドを連続で実行する。
date +%s%3N && nc <アドレス> <ポート番号>
するとncコマンドを実行する直前のUNIX時間を出力し、サーバーにつながるので、time.time()で取得する時間に限りなく近くなる。
あとは出力された時間をベースにトークンを生成し、トークンが違ったらシード値に1を足し (+1ms)、再生成して送信。これを正解するまで繰り返す。
トークンの生成に使用したコードはこれ。
import random
time = 0 #コマンドで取得したUNIX時間
token_length = 20
#from token_generator.py
def get_random(length):
alphabet = "0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz"
random.seed(time)
s = ""
for i in range(length):
s += random.choice(alphabet)
return s
token = get_random(20)
print(token)
初めてやったときは50回すべて使い切っても不正解になってしまった。
次のトライでは出力された時間に50 (+50ms) 足した状態から送信していった。
そして計62回の試行の後、やっと正解。やってて結構作業感が強かった。
picoCTF{UseSecure#$_Random@j3n3r@T0rs8a8d9ae0}
ちなみに最初に解いたときはpicoCTFのブラウザのWebShellからやっていたのだが、フラグをもう一回取得しようと自分のWSL環境からやったときはPingがひどいのか+130msでもダメだった。
Quantum Scrambler (200 points)
ncコマンドで接続してみるとやたらと長い文字列が返ってくる。文字数は何と5万908文字。
どうやら16進数の配列になっているらしい。
[['0x70', '0x69'], ['0x63', [], '0x6f'], ['0x43', [['0x70', '0x69']], '0x54'], ['0x46', [['0x70', '0x69'], ['0x63', [], '0x6f']], '0x7b'], ['0x70', [['0x70', '0x69'],...
しかしソースコードの中身は至ってシンプル。
quantum_scrambler.py
import sys
def exit():
sys.exit(0)
def scramble(L):
A = L
i = 2
while (i < len(A)):
A[i-2] += A.pop(i-1)
A[i-1].append(A[:i-2])
i += 1
return L
def get_flag():
flag = open('flag.txt', 'r').read()
flag = flag.strip()
hex_flag = []
for c in flag:
hex_flag.append([str(hex(ord(c)))])
return hex_flag
def main():
flag = get_flag()
cypher = scramble(flag)
print(cypher)
if __name__ == '__main__':
main()
get_flag関数では単純にファイルからフラグの文字列を読み込み、配列にしている。
そしてそれはscramble関数で難読化された後にprintされるという単純なもの。
難読化については文字列0123456789を例にするとわかりやすい。
この文字列を難読化すると以下の通りになる。
[['0', '1'], ['2', [], '3'], ['4', [['0', '1']], '5'], ['6', [['0', '1'], ['2', [], '3']], '7'], ['8', [['0', '1'], ['2', [], '3'], ['4', [['0', '1']], '5']]], ['9']]
文字列を配列にしたあと、2文字ずつに分け、二つの要素の間に新たな要素を追加している。この新たな要素には以前に出現した要素を含めていくため、その大きさは後半になるにつれて膨れ上がっていく。
しかしよく見ると、二つの間に要素を追加する以外には何もしていないため、それぞれの要素の最初と最後を取得すると元の文字列に戻ることが分かる。(最後の8と9だけは例外だが、取得したのが文字ではなく配列なら無視する処理を加えればOK)
デコード処理をPythonで書いて実行する。
def decode(encrypted: list[list]):
decrypted = []
for i in encrypted:
first = i[0]
decrypted.append(first)
if len(i) >= 2:
last = i[-1]
if type(last) != list: decrypted.append(last)
return decrypted
def hex2str(hexlist: list[str]):
string = ""
for byte in hexlist:
string += chr(int(byte, base=0))
return string
cipher = [['0x70', '0x69'], ['0x63', [], '0x6f'], ['0x43', [['0x70', '0x69']], '0x54'],...
print(hex2str(decode(cipher)))
ちゃんと正しくフラグが出てきた。
picoCTF{python_is_weirde2a45ca5}
Binary Instrumentation 2 (300 points)
基本的に解き方は1と同じ。動的解析していくと、それっぽい関数が見つかる。

問題文には「フラグのファイルを作成してくれるはず」と書いているが、恐らくパスを入力しなければならないところが<Insert path here>のままとなっている。
そしてもう一つ気になる文字列が下にあるが、これがBase64でエンコードされたフラグとなっている。
その次のcs:off_140002000がkernel32.dllのWrite_File関数なので、本来この文字列が書き込まれるはずだったのだろう。
文字列をデコードしてフラグを取得。
picoCTF{fr1da_f0r_b1n_in5trum3nt4tion!_b21aef39}
perplexed (400 points)
バイナリファイルを実行すると以下の通りパスワードを求められる。
どうやらパスワードをクラックする問題のようだ。
さっそくIDAでデコンパイルしてみる。
デコンパイル内容
int __fastcall main(int argc, const char **argv, const char **envp)
{
char s[8]; // [rsp+0h] [rbp-110h] BYREF
__int64 v5; // [rsp+8h] [rbp-108h]
__int64 v6; // [rsp+10h] [rbp-100h]
__int64 v7; // [rsp+18h] [rbp-F8h]
__int64 v8; // [rsp+20h] [rbp-F0h]
__int64 v9; // [rsp+28h] [rbp-E8h]
__int64 v10; // [rsp+30h] [rbp-E0h]
__int64 v11; // [rsp+38h] [rbp-D8h]
__int64 v12; // [rsp+40h] [rbp-D0h]
__int64 v13; // [rsp+48h] [rbp-C8h]
__int64 v14; // [rsp+50h] [rbp-C0h]
__int64 v15; // [rsp+58h] [rbp-B8h]
__int64 v16; // [rsp+60h] [rbp-B0h]
__int64 v17; // [rsp+68h] [rbp-A8h]
__int64 v18; // [rsp+70h] [rbp-A0h]
__int64 v19; // [rsp+78h] [rbp-98h]
__int64 v20; // [rsp+80h] [rbp-90h]
__int64 v21; // [rsp+88h] [rbp-88h]
__int64 v22; // [rsp+90h] [rbp-80h]
__int64 v23; // [rsp+98h] [rbp-78h]
__int64 v24; // [rsp+A0h] [rbp-70h]
__int64 v25; // [rsp+A8h] [rbp-68h]
__int64 v26; // [rsp+B0h] [rbp-60h]
__int64 v27; // [rsp+B8h] [rbp-58h]
__int64 v28; // [rsp+C0h] [rbp-50h]
__int64 v29; // [rsp+C8h] [rbp-48h]
__int64 v30; // [rsp+D0h] [rbp-40h]
__int64 v31; // [rsp+D8h] [rbp-38h]
__int64 v32; // [rsp+E0h] [rbp-30h]
__int64 v33; // [rsp+E8h] [rbp-28h]
__int64 v34; // [rsp+F0h] [rbp-20h]
__int64 v35; // [rsp+F8h] [rbp-18h]
int v36; // [rsp+10Ch] [rbp-4h]
*(_QWORD *)s = 0;
v5 = 0;
v6 = 0;
v7 = 0;
v8 = 0;
v9 = 0;
v10 = 0;
v11 = 0;
v12 = 0;
v13 = 0;
v14 = 0;
v15 = 0;
v16 = 0;
v17 = 0;
v18 = 0;
v19 = 0;
v20 = 0;
v21 = 0;
v22 = 0;
v23 = 0;
v24 = 0;
v25 = 0;
v26 = 0;
v27 = 0;
v28 = 0;
v29 = 0;
v30 = 0;
v31 = 0;
v32 = 0;
v33 = 0;
v34 = 0;
v35 = 0;
printf("Enter the password: ");
fgets(s, 256, stdin);
v36 = check(s);
if ( v36 == 1 )
{
puts("Wrong :(");
return 1;
}
else
{
puts("Correct!! :D");
return 0;
}
}
fgetsで受け取った入力をcheck関数というところでチェックしており、返り値が1以外なら正解ということがわかる。
では、check関数の中身をデコンパイルしてみる。
int64 __fastcall check(const char *a1)
{
__int64 v2; // rbx
__int64 v3; // [rsp+10h] [rbp-50h]
_QWORD v4[3]; // [rsp+18h] [rbp-48h]
int v5; // [rsp+34h] [rbp-2Ch]
int v6; // [rsp+38h] [rbp-28h]
int v7; // [rsp+3Ch] [rbp-24h]
int j; // [rsp+40h] [rbp-20h]
unsigned int i; // [rsp+44h] [rbp-1Ch]
int v10; // [rsp+48h] [rbp-18h]
int v11; // [rsp+4Ch] [rbp-14h]
if ( strlen(a1) != 27 )
return 1;
v3 = 0x617B2375F81EA7E1LL;
v4[0] = 0xD269DF5B5AFC9DB9LL;
*(_QWORD *)((char *)v4 + 7) = 0xF467EDF4ED1BFED2LL;
v11 = 0;
v10 = 0;
v7 = 0;
for ( i = 0; i <= 22; ++i )
{
for ( j = 0; j <= 7; ++j )
{
if ( !v10 )
v10 = 1;
v6 = 1 << (7 - j);
v5 = 1 << (7 - v10);
if ( (v6 & *((char *)&v4[-1] + (int)i)) > 0 != (v5 & a1[v11]) > 0 )
return 1;
if ( ++v10 == 8 )
{
v10 = 0;
++v11;
}
v2 = v11;
if ( v2 == strlen(a1) )
return 0;
}
}
return 0;
}
まず最初にstrcmp関数で文字数が26(+ 改行文字 '\n' で 27)でなければすぐに1を返しているので、27文字であることがわかる。ただ、その次は謎の三つの数字が代入されていて、よくわかんないことになっている。
アセンブリコードを見ていくと、実はこの三つの数字の書き込み先は隣接しており、char配列をスタックに書き込む処理と変わらないことが分かる。
gdbでメモリを覗いてみても三つの値が連続で書き込まれているのが分かる。
(リトルインディアンなので、バイトを右から読むとデコンパイルのときに見た数字になる)
0x7fffffffd6d0: 0xe1 0xa7 0x1e 0xf8 0x75 0x23 0x7b 0x61
0x7fffffffd6d8: 0xb9 0x9d 0xfc 0x5a 0x5b 0xdf 0x69 0xd2
0x7fffffffd6e0: 0xfe 0x1b 0xed 0xf4 0xed 0x67 0xf4 0x00
一旦v3を型変換でchar[20]に変えてみる。
int64 __fastcall check(const char *a1)
{
__int64 v2; // rbx
char v3[20]; // [rsp+10h] [rbp-50h] OVERLAPPED
int v4; // [rsp+34h] [rbp-2Ch]
int v5; // [rsp+38h] [rbp-28h]
int v6; // [rsp+3Ch] [rbp-24h]
int j; // [rsp+40h] [rbp-20h]
unsigned int i; // [rsp+44h] [rbp-1Ch]
int v9; // [rsp+48h] [rbp-18h]
int v10; // [rsp+4Ch] [rbp-14h]
if ( strlen(a1) != 27 )
return 1;
*(_QWORD *)v3 = 0x617B2375F81EA7E1LL;
*(_QWORD *)&v3[8] = 0xD269DF5B5AFC9DB9LL;
*(_QWORD *)&v3[15] = 0xF467EDF4ED1BFED2LL;
v10 = 0;
v9 = 0;
v6 = 0;
for ( i = 0; i <= 22; ++i )
{
for ( j = 0; j <= 7; ++j )
{
if ( !v9 )
v9 = 1;
v5 = 1 << (7 - j);
v4 = 1 << (7 - v9);
if ( (v5 & v3[i]) > 0 != (v4 & a1[v10]) > 0 )
return 1;
if ( ++v9 == 8 )
{
v9 = 0;
++v10;
}
v2 = v10;
if ( v2 == strlen(a1) )
return 0;
}
}
return 0;
}
そうすると、return 1の前の評価式が幾分か見やすくなる。
どうやら特定の条件を満たしていないと即不正解判定されるみたいなので、この式を中心に分析を進めていく。
まず、v4とv5についてだが、これらは1を左に一定回数シフトした数字となっており、これと配列中の文字とでAND演算を行っている。
しかし、1をシフトしているため、結果に影響するのは1ビットのみとなる。なぜなら1を何回左にシフトしても二進数上で1が存在するビットは1つしかないため、AND演算を行うと0のビットはすべて0となってしまうからだ。(1を左に3回シフトしても、二進数で1000となり、2、3、4番目のビットは0なので、必ずそのビットの結果は0になる。)
そして、その後の> 0では0であるかそうでないかを判定している。
つまりこの式は、ユーザーが入力した文字列と正解の文字列を1ビットずつ比較しているということになる。
ただし、この場合、jとv9に入る数字が1だけずれていることに注意しなければならない。
最初のループであるi = 0のとき、v4とv5が計算される地点において、それぞれの値は:
j = 0, 1, 2, 3, 4, 5, 6, 7,
v9 = 1, 2, 3, 4, 5, 6, 7, 1
となる。さらに、v9が7から繰り上がり8になった瞬間、v9は0になると同時にv10に1足されるので、正解のバイト列の評価対象が二バイト目に突入しているのがわかる。
つまり、正解のバイト列の方は7ビットずつループして評価しているということである。
正解のバイト列は7ビットを1文字としたグループなので、元に戻してやるには7ビットずつ取り出して先頭に0を加えてやればいい。(ASCIIは0~127の範囲なので1を先頭につけることはない)
encrypted = [0xe1, 0xa7, 0x1e, 0xf8, 0x75, 0x23, 0x7b, 0x61, 0xb9, 0x9d, 0xfc, 0x5a, 0x5b, 0xdf, 0x69, 0xd2, 0xfe, 0x1b, 0xed, 0xf4, 0xed, 0x67, 0xf4]
binary_str = ""
for byte in encrypted:
binary = bin(byte)[2:]
for _ in range(8-len(binary)):
binary = "0" + binary
binary_str += binary
decrypted = []
for i in range(0, len(binary_str), 7):
binary = "0b0" + binary_str[i:i+7]
decrypted.append(int(binary, base=0))
string = ""
for num in decrypted:
string += chr(num)
print(string)
コードを実行してフラグを取得。
picoCTF{0n3_bi7_4t_a_7im3}