Abstract
個人的にはこれまで機械学習モデル(モデル)のといえば精度やアルゴリズムに目が行きがちで,その説明性にはあまり注意を払ってこなかった.しかし,ビジネスで利用する場合は作成したモデルに対して責任が生じてくる.これはモデルを提供する側だけでなく,モデルを使用して意思決定する人も同じである.例えば重要な意思決定の場においてAIが言っていたからでは通らないはずである.
そこで今後より重要視されそうな XAI (Explainable artificial intelligence) についてざっくりサーベイし,結果を書き留めた.
本文の内容は浅いのでより深く正確に知りたい場合 → 文末の参考文献を参照
想定読者
自分のように"XAI"というワードは知っているが,必要性や,手法の例がわからない方.
モデルを理解する動機
説明できるAI
ここでは XAI の定義をまず確認しておきたい.
解釈可能な人工知能(Explainable Artificial Intelligence、XAI)は、機械学習やディープラーニングなどの人工知能技術を用いたシステムの内部の動作や意思決定プロセスを理解可能な形で説明する手法やアプローチです。XAIの目的は、ブラックボックスとして振る舞う従来の人工知能システムの説明責任や信頼性の問題に対処することです。XAIは、人間がなぜ特定の意思決定が行われたのかを理解し、結果に対して信頼を持つために重要です。これにより、法的、倫理的な観点からの問題解決や、意思決定プロセスの改善、バイアスの特定などが可能になります。XAIの手法には、透明性の向上、特徴の重要度の可視化、ルールベースのアプローチ、モデルの単純化などが含まれます。1
とのこと.
上記はLLMから吐き出された文章である.出力までのプロセスはブラックボックスであり Explainable とは言い難い例の1つといえる.しかし,一般的な認識や外部の文献からの情報を参照すれば,XAIとはモデルを理解するために用いる技術全般を指すと理解でき,文章に問題は無いと確認を取ることができる.このようにモデルの説明ができなくともその使用に問題はないケースもある.
XAIの定義に戻ると,重要と思われるのは透明性や信頼性といったワードである.透明性があるとは入力を与えたらどう加工され,どこに注目して,どういった出力を出すかというモデルの入出力プロセスを後追いして確認でき,ユーザがマネジメントできる状態であると考える.信頼性があるとはモデルの出力根拠が明確で,その根拠が一般倫理や法律に従っている状態であると考える.この辺りの定義 (範囲やレベル) はまだ厳密には確定していないと思われるが,一般的にはこういったニーズのために用いられる技術がXAIといわれている.
説明できると何がいいか
機械学習手法には手法そのものに説明性を持つものがある.例えばベーシックなな線形回帰や決定木などである.その一方で,AIといえばの深層学習手法,特に素晴らしい性能を発揮している昨今の大規模言語モデルを挙げてみる.こちらは基本的に入力と出力のみが観測可能であるブラックボックスとなっているのが現状であり内部の動きは全くもって不明である.補足すると,ここでの"ブラックボックス"は学習のアルゴリズムは定式化され,パラメータも観測できているが,規模が大きすぎて理解できない,パラメータの意味を人間が解釈できないといった意味である.このように複雑かつ大規模なモデルは性能が高い一方で説明性が低下するため,性能と説明性はトレードオフと言っても良いだろう.
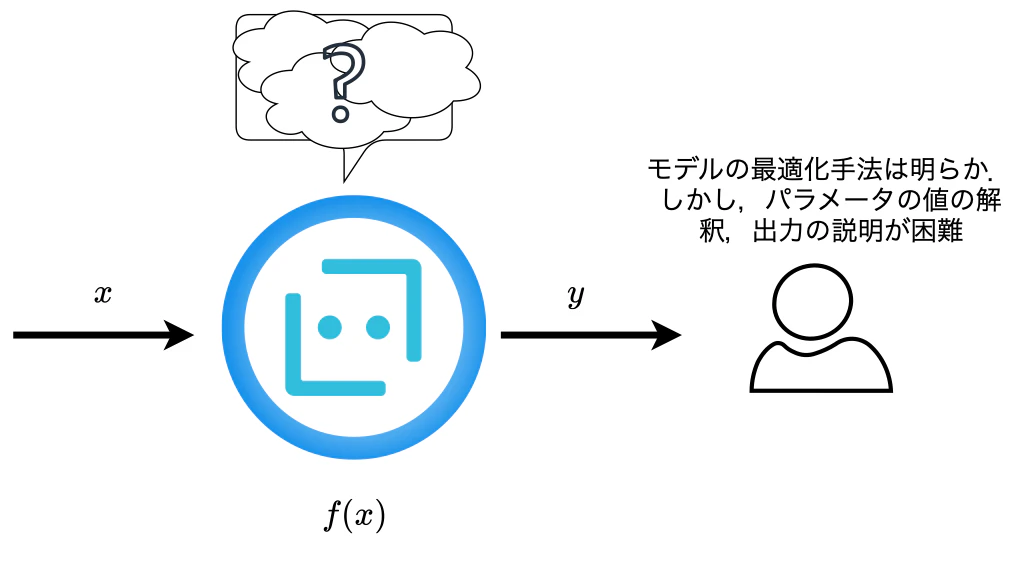
図1. AIを活用する際,判定根拠が不明だと妥当性を説明できない.
AIをビジネス適用する場合は”精度”はもちろん”なぜその予測をしたか”についての説明を求められるケースが多い.これは金融や法など,人の権利や資産に直結する業界で特にシビアであるように思う.こういった場面ではAIによる効率アップをしながら企業の信頼性を保つ必要がある.
業務でAIを利用するエンドユーザには既に豊富な業界知識や経験を有している人物がいる.その場合AIのサジェストのみでは現場で信頼されづらく,自身の知見との突合をしながら活用を進めたいというニーズも生まれる.このケースでは仮に数値上の精度が高くとも,説明性がなければ現場活用に結びつけることが難しくなるのである.
OpenAI社が提供している ChatGPT は攻撃的な返答や不平等な回答を抑制するよう作られているため以前のLLMサービスと比較して受け入れられやすくなったと思われる一方で,説明性は皆無である.このように,利用に耐えうるもの (説明コスト<利益) であれば説明は必ずしも必要ではないケースがある.他の例では,クレジットカード審査AIは説明性が必須であろうが,写真加工アプリのAIには説明性はマストではないはずである.
これまで述べたように,AI導入によって業務効率化を行いたい反面,高性能なモデルを用意するだけではダメなケースがある.例えば業務自体に説明責任があったり,AIと協働するユーザの信頼関係であったり,モデルがおかしな振る舞いをしないか不安が残っているなどである.これらに対応するためには説明性を確保しなければならず,今後XAIの必要性は十二分に存在するはずである.一方で全てのAIについて絶対的に説明性が必要かと言われればそうとは限らないという点に留意したい.
モデルの説明
本題のXAIに用いられる手法について.
説明方法の分類
体系的に理解するため,まずは説明方法を4種類に大別した例をみてみる2.その分類とは下記である.
- 大域的な説明
- 局所的な説明
- 説明可能なモデルの設計
- 深層学習モデルの説明
クリストフ氏による説明可能なAIに関する書籍のWeb版 3 や,機械学習工学の書籍 4 でも類似した括りで分類し説明している.しかし,必ずしも文献間で分類が統一されているとはいえないので留意する.
ここでは文献 4 を参考にこれらを更に大きく括り,大域的な説明と局所的な説明の2つに分類したい.但し,これが一般的に正しいわけではなく,文献間でもまちまちであると再度述べておく.ここでは文献 4 から読み取れる大域的な説明と局所的な説明の大枠は次の図のようになる.
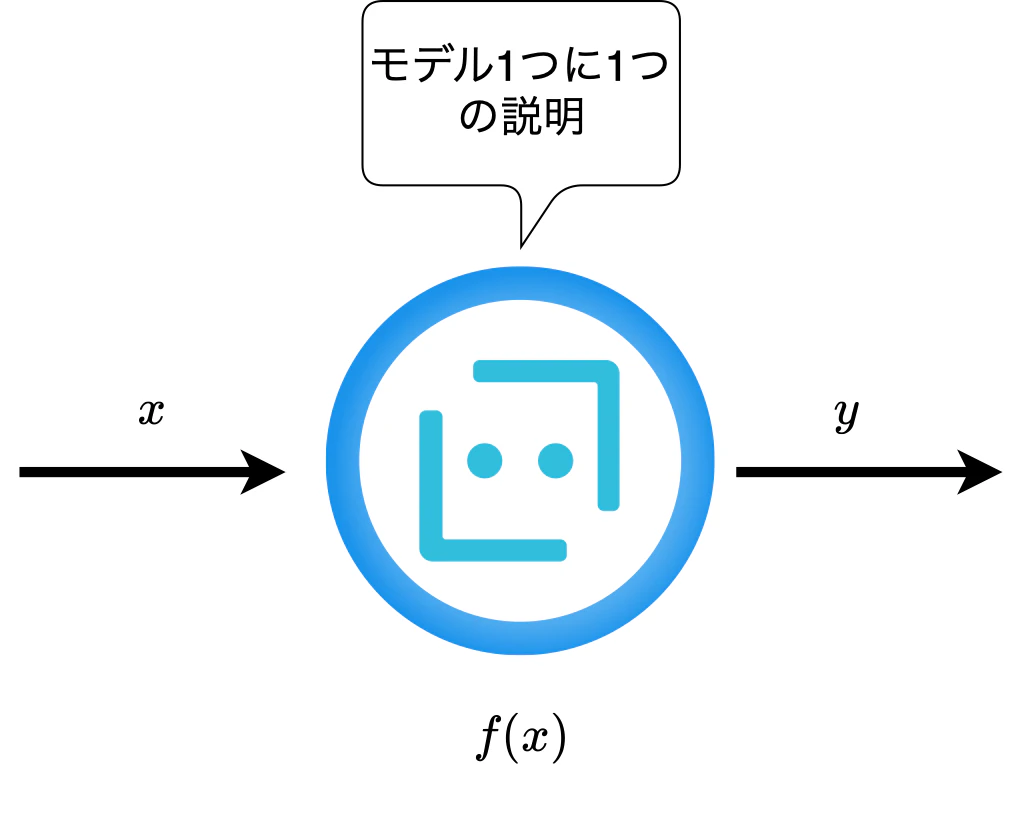
図6. 大域的な説明のイメージ.
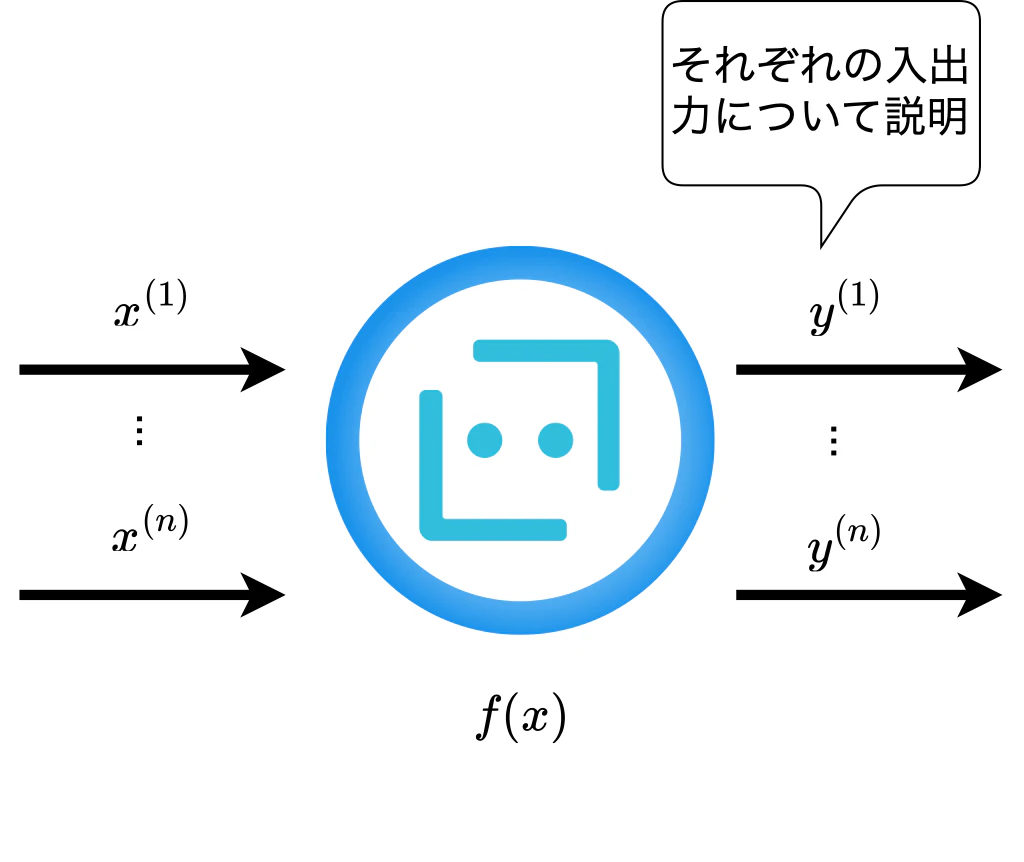
図7. 局所的な説明のイメージ.
なお,文献 4 では節ごとにXAIについて次の分類をしている.
- 可視化よる説明 (e.g. PDPやICE)
- 可読なモデルによる説明 (e.g. 線形モデル,決定木)
- 大域的な説明
- 局所的な説明
ここで,"可読なモデルによる説明" つまりGBDTや回帰モデルのようにアルゴリズムそのものが説明性を組み込んでいるものについては,1モデル=1説明であり,大域的な説明に通づるものがあるように思う.一方でICEはデータセットインスタンスごとにICEプロットを作成し可視化を行うため,局所的な説明に近い.PDPについてはICEと似ているがモデルの入力の一部を要約し1モデルに対して1特徴量の平均的な説明を与えるため大域的な説明に近い.
このように解釈して,ここでは大域的な説明と局所的な説明の2つに分類し,具体的な手法を挙げてみる3, 4.
| 名称 | 概要 | 該当する手法 |
|---|---|---|
| 大域的説明 | モデルへの入出力全体から説明を行う | PDP, PI, BATrees |
| 局所的説明 | モデルへの特定の入出力を観察し説明を行う | ICE, LIME, SHAP |
次に,XAI手法について少しだけ掘り下げてみる.
Parmutation Importance (PI)
Parmutation Importance (Parmutation Feature Importance: PFI とも) はモデルがどの特徴量を重要視しているか,どの特徴量が結果に寄与しているかを確認する手法である.すなわち,判定の根拠となる要素を特定する手法である.
アルゴリズムとしては至って単純であり,注目する(説明する)特徴量についてランダムに並べ替えることで使用不可能とし,その影響を調べる.特徴量次元 $d$ の入力 $ \boldsymbol{x} = (x_1, x_2, \ldots, x_d) $ について $N$個だけデータ数を用意する. $ D= { \boldsymbol{x}^{(n)}, y^{(n)} } \quad (n=1,\ldots,N) $.
このデータセットについて,注目したi番目の特徴量 $\boldsymbol{x}_i$ について,インスタンス方向に$N$だけ取り出し,ランダムに並べ替える.このランダム化した場合とそうでない場合について,予測結果を適当な損失関数に当てはめてその差を重要度 PI として扱う.PIが大きければその特徴量が使用不能になることで損失が増える,つまり予測に寄与している.逆にPIが小さければ特徴量は予測に寄与していないといえる.

図8. PIのイメージ.(x1の重要度を調べるとき)
BATrees
Born Again Trees (BATrees) は複雑なモデルを解釈可能な決定木で近似することで,説明を可能とする手法である.学習済みモデルへの入力を確率分布からのサンプリングやデータセットの並べ替え,データセットへノイズを加えるなどしてランダムに生成しこれに対しての出力を得る.このペアをデータセットとして決定木を学習させる.データセットはモデルの入出力の傾向を網羅的に表しているため,これを用いて学習した決定木はモデルを近似しているはずである.決定木はそれほど深くなければそれ自体で解釈可能である.
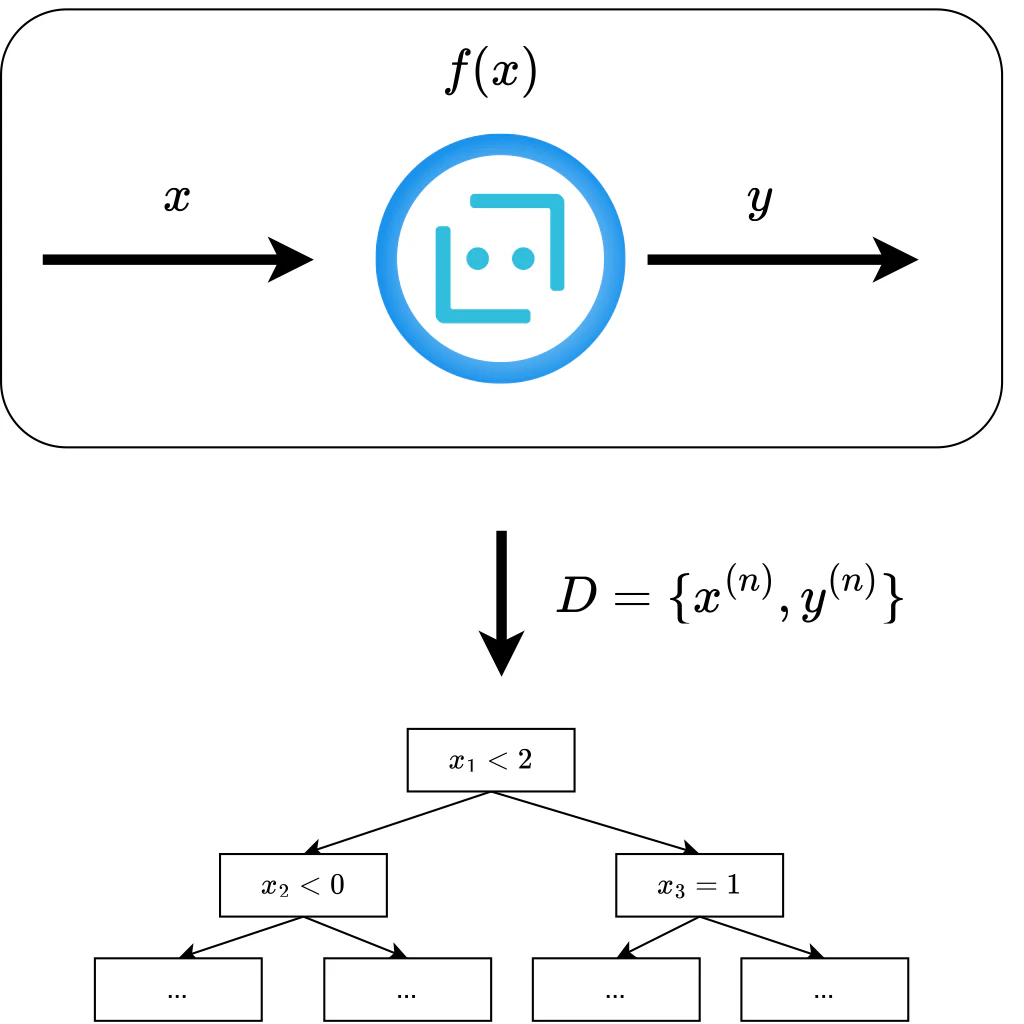
図9. BATreesのイメージ.
(n=1,...,N だけのサイズを持つデータセットを用意し決定木を学習.)
ICE
Indivisual Conditional Explanation (ICE)は Partial Dependence Plot (PDP) をより詳細にみたものと考えて差し支えなく,大元の部分は同じアルゴリズムである.両者とも縦軸にPD値やICE値をとり横軸に注目している特徴量をとって,変化を二次元にプロットすることで特徴量の影響を可視化する.
PDPのカーブは注目している特徴量 $x_j$ の独立性の仮定を置き,注目している$j$番目の特徴量を変数にもつ関数として,次式で近似される4.
$$
\text{PDP}(x_{j}) = \frac{1}{N}\sum_{i=1}^N f(x_j, \boldsymbol{x}_{i,\setminus j}) .
$$
ICEについてはほぼ同様に次式で与えられる.
$$
\text{ICE}(x_{j}) = f(x_j, \boldsymbol{x}_{i,\setminus j}) .
$$
注目している$j$番目の特徴量以外は固定して,$j$番目の特徴量による出力変化を観測するようなイメージである.また,PDPでは平均的な変動を可視化するが,ICEではインスタンスごとの変化を可視化する.
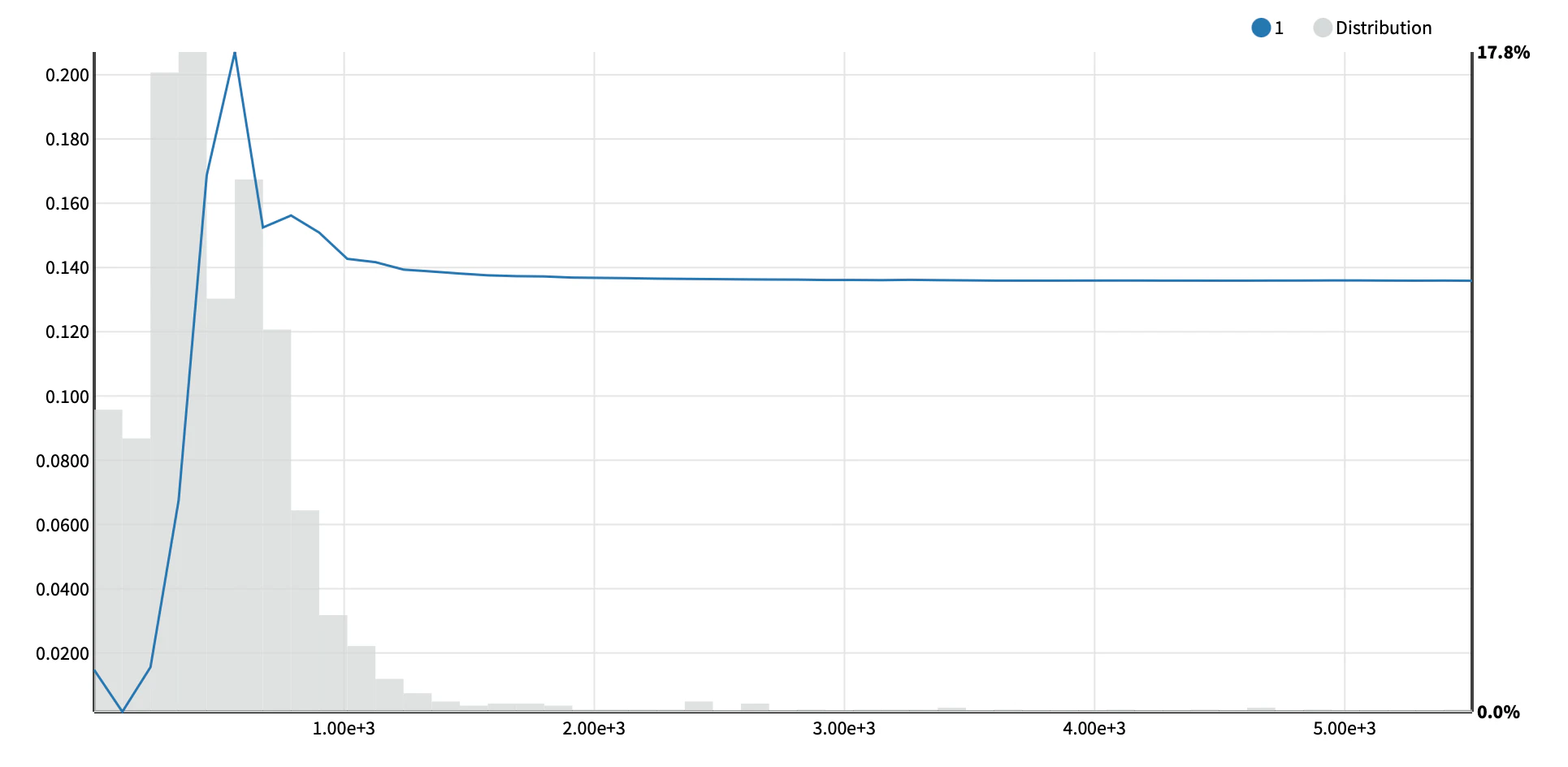
図10. PDPプロットのイメージ.
ある特徴量の変化(横軸)に対するモデル出力の変化(縦軸).
ICEでは曲線がデータセットインスタンス数だけ引かれる.
SHAP
Shapley Additive Explanations (SHAP) は Local Interpretable Model-agnostic Explanations (LIME) と同様に特徴量の重要度をみる.SHAPでは特徴量の重要度を線形に分解する.
すなわち,特徴量次元 $d$ で $i$ 番目のデータセットインスタンスについて次のように表現する.
$$
f (x_i) = \phi_0 + \sum_j^d \phi_{i,j} .
$$
予測の期待値としてのベースライン$\phi_0$からの変動を指す $\phi_{i,j}$ が特徴量それぞれの重要度である.
重要度は shap の公理という性質を満たす必要があるが,これを満たすようなあるインスタンスにおける特徴量の重要度はゲーム理論の shapley 値に相当する次式で求まる4.
$$
\phi_j = \sum_{S \subseteq d \setminus j} \frac{|S|!(d-|S|-1)!}{d!} (f(S \cup j)-f(S)) .
$$
$j$は注目している特徴量を指している.$(v(S \cup j)-v(S))$は限界貢献度と呼ばれ,特徴量$j$がある場合とない場合の差を取ることで$j$の出力への貢献度を定量化している部分である.これを組み合わせ数の逆数を重みとした荷重和として,重要度が表現される.なお,$|S|!(d-|S|-1)!$はそれぞれ$j$を除いた部分的な特徴量$S$の並べ方と特徴量全体からSとjを除いた特徴量の並べ方の積として与えられる.
SHAP についての詳細な説明は文献 5, 6 を参照されたい.
手法の比較
大域的説明はモデルとしていずれの特徴量が重要視されているかを確認できる.使い所としては説明を特徴量エンジニアリングに反映するモデルのチューニングが想定される.他にはモデルの運用にも活用できそうである.例えば,モデルを定期的に監視しバイアスがかかっていればモデルを再学習するという運用計画に活用できる.
局所的説明は特定の入力に対して説明を与える.こちらの使い所としては個々の説明がより重要な場面,例えばAIによる医療サポートなどがある.画像で病気を診断する際にどの部分が怪しいと見みなしたかを医師に提示することでより効果的な運用が可能となるはずである.
モデル精度の説明
モデルを説明するXAIの語義とは離れるが,モデルを作成した後に利用者への"説明 (成果物の解説という意味で)"には必要になるため,モデルの評価の例についても記述する.本節は普通,XAIという領域には含まない.
Lift Charts
主に2クラス分類で利用されるモデルの精度評価手法である.まず,データセットの行(データセットインスタンス)について,予測確率で降順ソートをする.そのデータセットについて適当なサンプルサイズでビンを作成しビンごとにリフト値 $\text{lift} (x)$を算出する.リフトはビンに含まれるデータセットについて,評価対象のモデル$f$で陽性と予測した場合の真陽性割合と,ランダムモデルで陽性と予測した場合の真陽性割合の比で表す.すなわちリフト値が 1.0 を超えていればそれだけランダムモデルよりも優れているとみなす.
$$
\text{lift}(x) = \frac{ \text{TP}(f(x))}{\text{TP}(\text{Random}(x))} .
$$
予測確率でソートしているため通常であれば予測確率が高い方(左側のビン)のリフト値が大きくなるはずである.
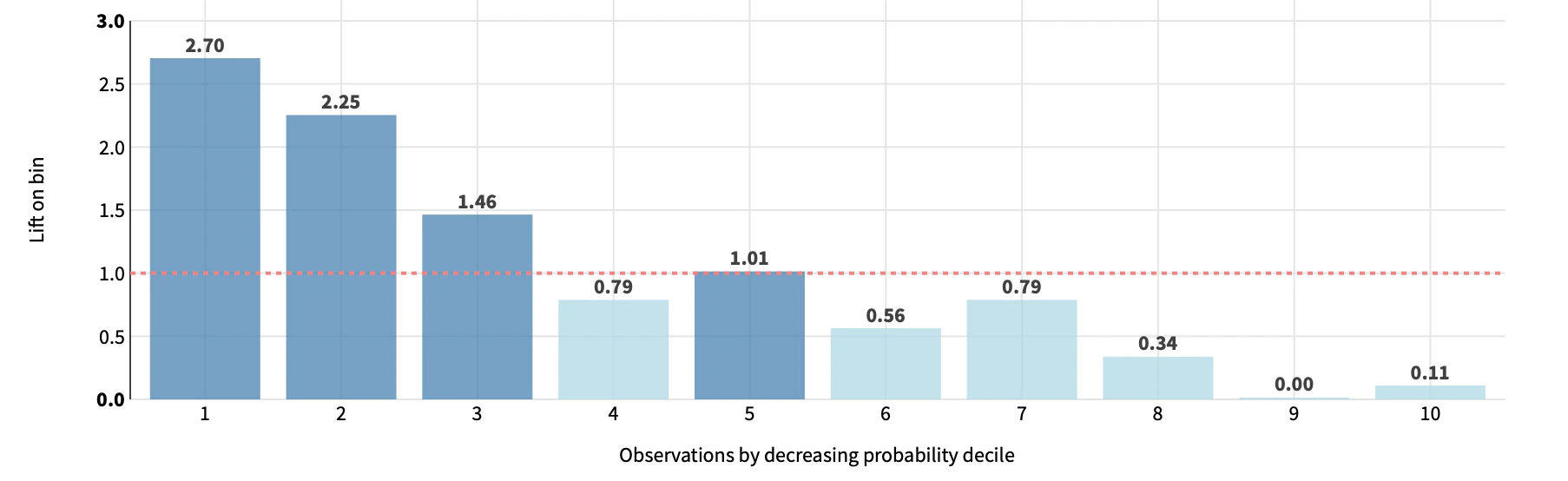
図2. リフトチャートの例.
Calibration Curve
こちらも2クラス分類問題での利用が多い.Calibration Curve は予測確率と実際の陽性出現率をプロットし,データセットと予測の整合性を表したグラフである.データセットを予測確率でビニングし,その中での陽性出現率を求める.横軸が実際の陽性出現率,縦軸が予測確率でありビンの中で平均を取ってある.
例えば予測確率が平均10%の標本を取り出したら,その中で実際の陽性の出現率を縦軸にプロットする.図のようなカーブだったりtanhの形に近かったりする.モデルが完璧であればこの線は対角線になる.
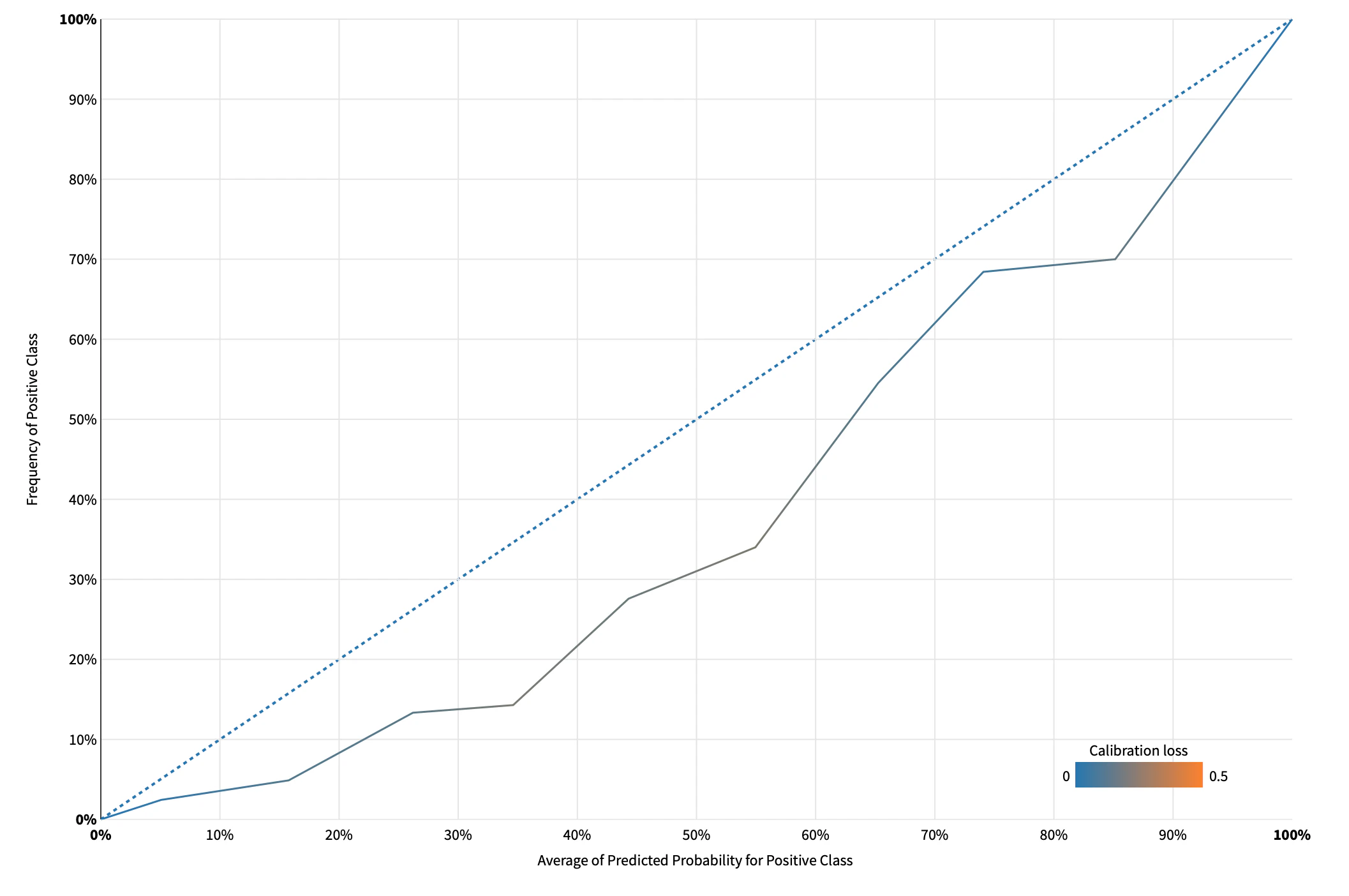
図3. calibration curve の例.
Density Chart
予測クラスごとに確率密度分布をプロットしたもの.モデルがどのようにデータセットを分割したかを視覚的に確認することができる.完全なモデルであればそれぞれの分布は重ならない.
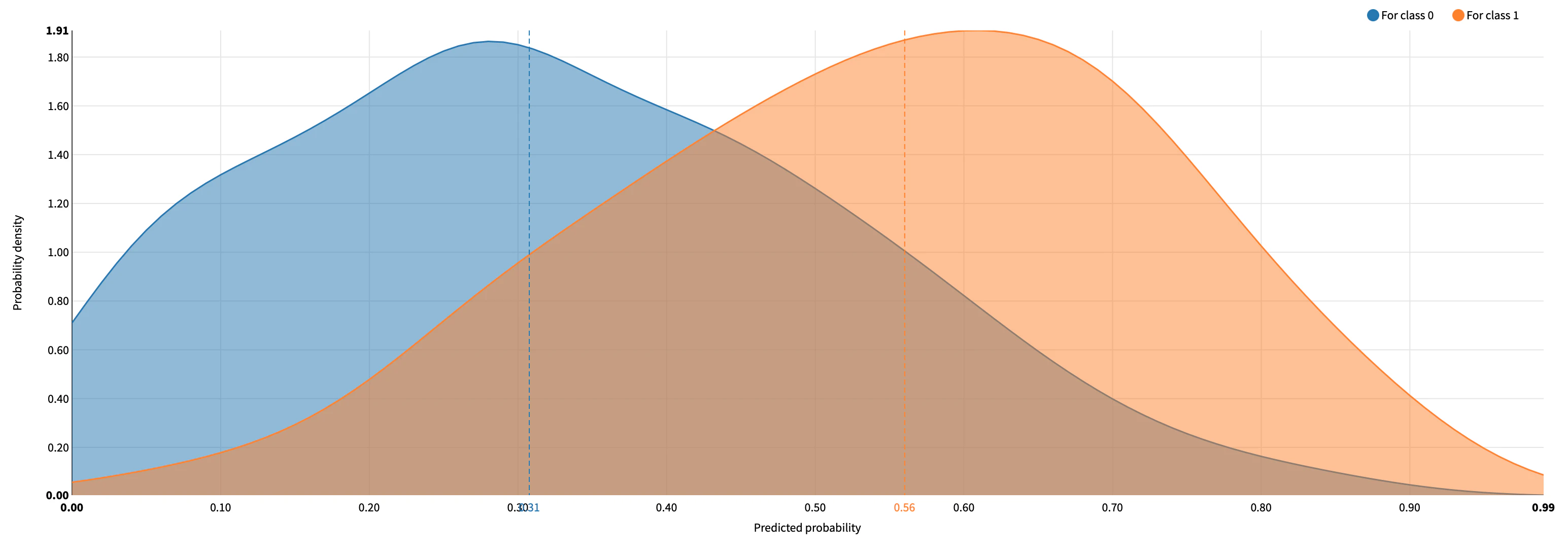
図4. 確率密度分布.
2クラスの場合は横軸のどこかに閾値を設定することになる.
ROC Curve
Receiver Operating Characteristic (ROC) Curve は主に2クラス分類問題で利用される.True Positive (真陽性) 率と False Positive (偽陽性) 率を2次元プロットしたグラフである.先のような陽性と陰性の予測確率の確率密度分布がある時,クラス分類の閾値をずらしていった時の振る舞いをグラフ上の曲線で表現している.
よって,プロットが (x=0.0, y=0.0) の時は全てが陰性として分類されている状態,(1.0, 1.0) の時は全てが陽性として分類されている場合である.一切誤りのない理想的なモデルは (0.0, 1.0) を通る一方,対角線に近づくほどモデルはランダムである.
$$
p(\text{TP}) = \frac{TP}{TP+FN} \qquad\text{(縦軸)} ,\qquad
p(\text{FP}) = \frac{FP}{FP+TN} \qquad\text{(横軸)} .
$$
ROC 曲線の下側の面積は Area Under Curve (AUC) と呼ばれ,0.0 ~ 1.0 の値をとるが,ランダムなモデル以下というのはそうそうないので,0.5 ~ 1.0 の範囲をもって評価する.

図5. ROC曲線の例.
おわりに
ここまでざっくりとXAIについて調べた内容をまとめ,"XAI" についてなぜ必要か,どういう手法があるかの大枠を把握できた.しかし,XAIについては未だ発展途中であり,上記は既存手法の一部の上澄みに過ぎない.現時点では少々日が経っているが,XAIの最近の動向については文献7,8,9 などのほか,文献 4 内で取り上げている参考文献を適宜参照する.
参考
-
chatgpt, OpenAI, accessed:2023-07. ↩
-
人工知能学会, 機械学習における解釈性, https://www.ai-gakkai.or.jp/resource/my-bookmark/my-bookmark_vol33-no3/, accessed:2023-08. ↩
-
hristoph Molnar, Interpretable Machine Learning, https://christophm.github.io/interpretable-ml-book/index.html, accessed:2023-08. ↩ ↩2
-
石川冬樹, 丸山宏, 柿沼太一, 竹内広宜, 土橋昌, 中川裕志, 原聡, 堀内新吾, 鷲崎弘宜, "機外学習工学" ,講談社, 2022. ↩ ↩2 ↩3 ↩4 ↩5 ↩6 ↩7 ↩8
-
森下光之助, 機械学習を解釈する技術〜予測力と説明力を両立する実践テクニック, 技術評論社, 2021. ↩
-
akiraTOSEI, 現場で使える機械学習活用 ~その④説明性があるAI (XAI) とその活用~, https://note.com/akira_tosei/n/n966b4a019d28, accessed:2023-08. ↩
-
人工知能学会, 説明可能AI, https://www.ai-gakkai.or.jp/resource/my-bookmark/my-bookmark_vol34-no4/, accessed:2023-08. ↩
-
Takashi J. OZAKI, 機械学習の説明可能性(解釈性)という迷宮, https://tjo.hatenablog.com/entry/2019/12/19/190000, accessed:2023-08. ↩