はじめに
内容について
やる事
- Docker で vLLM を実行し OpenAI 互換の API を用意
- Cline を Docker で実行し隔離し,安全を考慮して実行
- Cline で試しにタスクを実行する
やらない事
- モデル運用の最適化
- Cline のベストプラクティス
- 性能検証
概要
Cline [1] は VS Code でコーディングエージェントを提供する拡張機能であり,チャットでの対話やコードの生成,ローカルのファイルの読み書き(RW),シェルコマンドの実行といった機能を VS Code を介して提供する.
開発を効率化するツールとして注目されているが,組織利用にはいくつか課題がある.例えば,端末のリソースに対するアクセスやシェルコマンドの実行権限を与える場合のセキュリティ.外部のLLM プロバイダの API にアクセスするため,内部のデータを送信しなければならないなどである.こういった場合は閉域でLLMを実行させる,(あるいはクラウドサービスでLLMを占有して利用する),必要性が生まれる.
後述するが,ClineはローカルLLMの利用を推奨していない(基本的にパフォーマンスが悪い).そのため特に利用できない理由が無いならば,素直にプロバイダのAPIを利用するべきといえる.一方で前述のように,コードを外に出せない,オフライン環境で使う必要がある,検証用途である,GPUリソースが余っているのでAPIに課金したく無い,といった場合は閉域実行が視野に入る.
ここでは,Clineを閉じた環境(ローカルLLM)で利用する環境を Docker コンテナを利用して用意して利用を開始するまでを記載する.一方,Cline を利用した開発のベストプラクティスは記述しない.
結果として,単一GPUに載せた7B程度のモデルで Cline は利用可能であるが,簡単なタスクの実行に限定されるという予想できる結果となった.性能を上げるには運用方法など更なる工夫が必要と思われる.
前提条件
以降の内容を実行するための前提条件について述べる.
- 開発用端末とLLMを動かすサーバ(GPUサーバ)があり, それぞれで Docker (Docke Engine)が動作すること.
- LLMを動かす GPU サーバは VRAMが 24GB 程度のGPU (ここでは Nvidia 製とする)を持つこと.
- サーバには Nvidiaドライバ,CUDA,Nvidia Container ToolkitがインストールされDockerコンテナからGPUが認識できる設定であること. つまり,Docker のホストで
nvidia-ctk --versionコマンド,コンテナ内でnvidia-smiコマンドが通ること. - GPU サーバがリモートの場合は ssh 接続できること.
- 開発用端末にはVS Code がインストールされていること.
参考までに,動作確認したGPUサーバの環境情報を示す.
| 項目 | バージョン |
|---|---|
| OS | ubuntu server 22.04 |
| NVIDIAドライバ | 560.35.03 |
| CUDA | 12.6 |
| NVIDIA Container Toolkit | 1.17.1 |
| Docker | 27.3.1, build ce12230 |
| GPU | Nvidia A10G (24GB) x 1 |
Cline について
Cline [1] は VS Code でコーディングエージェント機能を提供する拡張機能である.
今回の用途において利用を始めるにあたり,注意すべき事柄をドキュメント[2] から抽出して,端的にいうと次の3点になる.
- Cline は現時点ではローカルモデルの利用を推奨していないこと
- コンテキストウィンドウの設定が重要であること(大きい方が良い)
- Cline はローカルのファイルをRWし,シェルコマンドを実行すること
1~2 では,パラメータが多く量子化がなるべくされていないオリジナルに近いモデルを利用し,その内,モデルの最大トークン長が長いものを選択すること.さらに,GPUのVRAMが多くコンテクストウィンドウが大きく取れることが要求されている.
3 は開発端末のセキュリティ的に問題が発生する可能性を示唆しているため,対策が望ましい.今回の対策は後述する.
LLM
Cline が現時点で推奨しているLLMは Claude 3.5 Sonnet (2025-03 時点)である.しかし,今回は前述の目的から Anthropic や OpenAI といったLLMプロバイダのAPIは利用しない.なお,繰り返しになるが, Cline のドキュメント [2] にてローカル LLM は現時点で推奨していない記述がある点は留意すること.
A Note on Local Models
While running models locally might seem appealing for cost savings, we currently don't recommend any local models for use with Cline. Local models are significantly less reliable at using Cline's essential tools and typically retain only 1-26% of the original model's capabilities.
https://docs.cline.bot/getting-started/model-selection-guide#a-note-on-local-models
今回は利用しないが,LLMプロバイダのAPIを利用する場合,モデルの切り替えをしたくなると思われるため,OpenRouter [3]というAPIを一括管理するサービス経由で呼び出すとプロバイダごとにAPIを発行する必要がない点では便利である.一方でチャージコストがあったり接続が安定しなかったりするという話も聞く.
公式ドキュメントで節を設けて重点的に説明があるように,Cline の実行ではコンテキスト長が重要である.この件は,例えば ollama x cline でのディスカッション [4] でも取り上げられている.
これらを踏まえて,今回はコーディングに強い,日本語に強い,最大トークン長が大きいという観点からいくつか候補を下表にまとめた.表にあるように,最近は中国モデルがこの界隈でよく用いられている.
| 名称 | リポジトリURL | 概要 |
|---|---|---|
| lightblue/DeepSeek-R1-Distill-Qwen-7B-Japanese | https://huggingface.co/lightblue/DeepSeek-R1-Distill-Qwen-7B-Japanese | lightblue社が提供する,コーディングや理論的思考,数学が得意なDeepSeekR1の蒸留モデルの日本語調整版. |
| cyberagent/DeepSeek-R1-Distill-Qwen-14B-Japanese | https://huggingface.co/cyberagent/DeepSeek-R1-Distill-Qwen-14B-Japanese | cyberagent社が提供する,コーディングや理論的思考,数学が得意なDeepSeekR1の蒸留モデルの日本語調整版. |
| Qwen/Qwen2.5-Coder-7B-Instruct | https://huggingface.co/Qwen/Qwen2.5-Coder-7B-Instruct | Alibabaが提供する,Qwenのコード特化モデル. |
| Qwen/Qwen2.5-Coder-14B-Instruct | https://huggingface.co/Qwen/Qwen2.5-Coder-14B-Instruct | Alibabaが提供する,Qwenのコード特化モデル. |
| Qwen/Qwen2.5-7B-Instruct-1M | https://huggingface.co/Qwen/Qwen2.5-7B-Instruct-1M | Alibabaが提供する,Qwenの特にトークン長が大きいモデル. |
| Qwen/Qwen2.5-14B-Instruct-1M | https://huggingface.co/Qwen/Qwen2.5-14B-Instruct-1M | Alibabaが提供する,Qwenの特にトークン長が大きいモデル. |
セキュリティ
Cline は端末のファイルの読み出し,書き込み,コマンドの実行を行う.実行時はLLMによって安全かどうかの判定がされるようであるが,環境を破壊する懸念は残る.
LLMによる安全性の判定はAnthropicやOpenAIのような業界内において高性能なモデルであれば,完全ではないがある程度信頼できるものになる.一方で今回は,ローカルで動かす都合上,パラメータを落とした オープンなLLMを利用するためLLMによる判定はより信頼できないものになる.よって,ここではリスクを回避する手段を講じる.
対策として取れるのは下表に示すもので,この内, .clinerulesや.clineignoreファイルについては公式ドキュメントに書き方が記載されている [5].また,試行錯誤した結果を共有してくれる方がいるので適宜参照されたい[6].
今回用いた Cline 用セキュリティ対策.
| 名称 | 説明 |
|---|---|
.clinerules |
プロンプトに作用してClineの動作を制御する. .clinerules/ ディレクトリで複雑なルール定義も可能.プロジェクトのルートに配置. |
.clineignore |
.gitignore と同様にClineファイルの読み取りを制限する (v.3.3.0~) [7].プロジェクトのルートに配置. |
| Dev Containers 拡張機能 | VS Code の拡張機能.コンテナで VS Code Server を実行してコードの編集を行う.拡張機能はコンテナ内で実行されるため[8],Clineが行う操作をコンテナに隔離できる. |
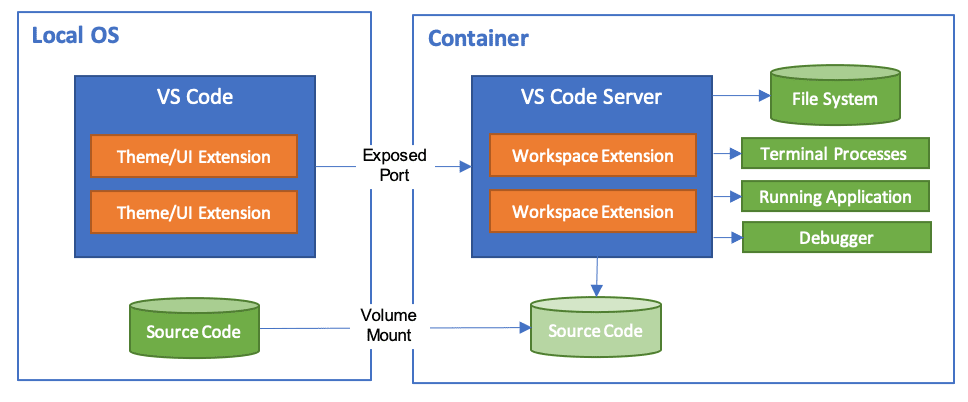
Dev Containers 拡張機能について,動作の仕組みを補足する [8].このように,開発端末のVS Code は Docker コンテナ内の VS Code サーバにリモート接続する.拡張機能は Docker コンテナ内で実行されシステムを破壊するリスクは低減される.
Workspace files are mounted from the local file system or copied or cloned into the container. Extensions are installed and run inside the container, where they have full access to the tools, platform, and file system. This means that you can seamlessly switch your entire development environment just by connecting to a different container.
https://code.visualstudio.com/assets/docs/devcontainers/containers/architecture-containers.png
引き合いに出されるツール
Cline系の他にも類似した目的を持つツールが開発,提供されている.下表にはその有名どころである2つを示す.
| ツール名 | 概要 |
|---|---|
| Cursor [9] | VS Codeからフォークしたエディタ.UIが使いやすい.ただ,Cursorのサーバ宛てにリクエストするためローカルLLMが簡単には使えないはず. |
| Devin (OSS版: OpenHands [10]) | 完全なエージェントとして設計されている.専用のコードの実行環境がサンドボックスとして用意され,LLMエージェントが自由に操作する.エディタではないため,開発方法が大幅に変更する事となり,よりLLMが中心の運用となる. |
環境の用意
冒頭で述べた開発端末とGPUサーバからなる環境は整っている事を前提として,ローカルLLMでClineを実行する手順は下記である.
- VS Codeに拡張機能をインストール
- プロジェクトの作成と開発用コンテナの起動
- LLMの起動
- 拡張機能 Cline の設定
1. VS Codeに拡張機能をインストール
開発端末の VS Code に Cline [11]と Dev Containers [12] がない場合はインストールする.
直接インストールするには,VS Code 起動後,左側ペインの「拡張機能」を選択し,2つの拡張機能を検索してインストールボタンを押下する.
2. プロジェクトの作成と開発用コンテナの起動
まず,作業するプロジェクトを新規作成する.開発端末に任意のディレクトリを作成し,VS Codeで開く.
次に,Dev Containers で開発用のコンテナを追加する.手順は MS Learn の方がわかりやすいかもしれないので適宜参照[13].
- command + shift + P (あるいはF1)でコマンドパレットを表示する.
- 「Dev Containers: Add Development Container Configuration Files」 を検索しつつ選択
- 「ワークスペースに構成を追加する」を選択.
- 「ワークスペースに構成を追加する」の場合プロジェクトに設定ファイルが保存され,Gitリポジトリに追加できる.
- 「ユーザデータフォルダに構成を追加すうる」の場合,ファイルシステムのユーザ領域に設定ファイルが保存される.こちらでも特に問題ない.
- 今回はpythonを実行したいので「Python3」を選択.
- 「3.12」を選択.
- 以降「OK」を選択.
この段階で, .devcontainer/ と devcontainer.json が追加される.これがコンテナ構成の設定ファイルである.このファイルが確認できたらコンテナを起動する.
- command + shift + P (あるいはF1)でコマンドパレットを表示する.
- 「Dev Containers: Reopen in Container」を検索しつつ選択.
- しばらく待つ
- VS Code 左下の青いリモートインジケーターに「開発コンテナ: Python3」のような表示が出ていれば起動と接続が完了している.
この段階でVS CodeはコンテナのVS Code Serverのクライアントになる.そのため拡張機能はVS Code Server の物が表示され, ctrl + で起動するターミナルのプロンプトもvscode → /` と表示される.
そのため拡張機能が無効になっている場合がある.左ペインから拡張機能を選択し Cline がグレーアウトしている場合は「開発コンテナにインストール」を選択する.
3. LLMの起動
まず,GPUサーバに接続しシェルコマンドが実行可能な状態にしておく.今回は推論が高速なvLLMでLLMをデプロイする.GPUサーバに下記のような最小限の構成を作成し,docker コンテナでvLLMを起動する.
vllm/
├── .env # 環境変数ファイル
├── docker-compose.yml # compose ファイル
└── data/ # コンテナのボリュームマウント用のディレクトリ
docker-compose.yml
コンテナの起動設定を記述する.
services:
vllm:
image: vllm/vllm-openai:v0.7.3
container_name: vllm
restart: no
runtime: nvidia
environment:
- OPENAI_API_KEY=vllm_api_key
expose:
- "8000"
ports:
- "8000:8000"
networks:
- vllm-network
volumes:
- ./data/.cache:/root/.cache
command: "--model ${MODEL_NAME} --served-model-name ${MODEL_NAME} --tensor-parallel-size 1 -q ${QUANTIZATION} --gpu-memory-utilization 0.9 --max-model-len ${MAX_MODEL_LEN} --host 0.0.0.0 --port 8000"
networks:
vllm-network:
name: vllm-network
driver: bridge
.env
環境変数を定義して制御する.Hugging Face から取得できるモデル名と量子化方式,モデルのトークン長を任意に定義する.
MODEL_NAME="Qwen/Qwen2.5-Coder-7B-Instruct"
QUANTIZATION="None"
MAX_MODEL_LEN=22800
LLMの追加とサービング
GPUサーバのシェルを起動して,vLLMを実行する.起動時点でモデルをGPUに展開するため数分待つ. -d オプションを外したり, docker logs , docker ps でエラーの有無を時々確認 .
$ cd /path/to/vllm
$ docker compose up -d
GPU サーバでの vLLM のサービング状態をテストする.APIを叩いて,モデルの情報が返ってくれば利用可能な状態になっている.
$ curl http://localhost:8000/v1/models
{"object":"list","data":[{"id":"Qwen/Qwen2.5-Coder-7B-Instruct", ...
起動ログで見た今回の利用可能なVRAMは下記.
total_gpu_memory (22.08GiB) x gpu_memory_utilization (0.90) = 19.88GiB
4. Cline の設定
モデルのサービングが完了したら開発端末の VS Code に戻り Cline を設定する.
Clineの接続設定
最初に左側のペインから Cline のアイコンをクリックし Cline を呼び出す.呼び出すと上部に拡張機能の操作メニュー,下部にチャット用のテキストボックスとモード切り替えボタン,Auto-Approve(自動承認)のオプションが表示される.
-
上部
-
下部
上部の歯車アイコンをクリックしてモデルの接続設定を呼び出す.
- API Provider は 「OpenAI 互換」を選択.
- VS Code が Docker コンテナで起動していることを思い出して,Base URL にはホストの8000番ポートを指して「http://host.docker.internal:8000/v1」とする(Mac, Win の Docker Desktop の場合).
- API Key は compose ファイルで指定した 「vllm_api_key」を入力する.
- Model ID には
http://localhost:8000/v1/modelsのAPIレスポンスに含まれる “id” キーの値 「Qwen/Qwen2.5-Coder-7B-Instruct」を入力する. - 今回は下部にある Use different models... のチェックボックスは外して,Plan モードと Act モードで同じモデルを使う.
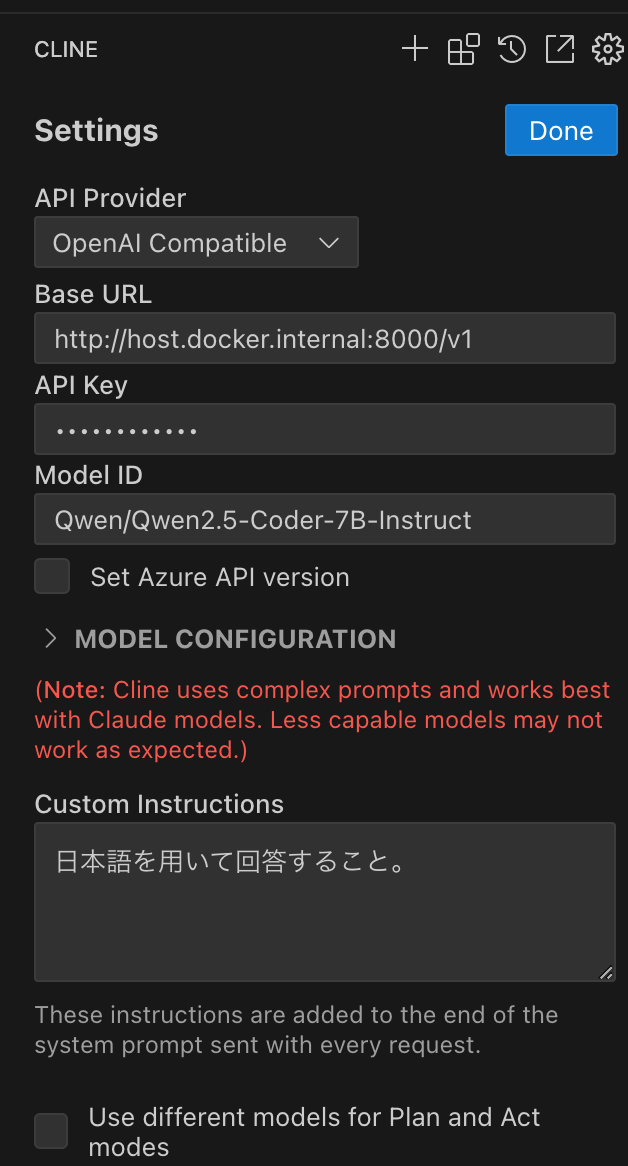
最後に 「Done」をクリックして設定を終了する.
セキュリティに関する設定
ここでは,.clinerules と.clineignore を用意し,開発端末の VS Code に下記のようなディレクトリ構成をつくる.
project/
├── .devcontainer/
│ └── devcontainer.json
├── .clineignore
└── .clinerules
まずは前者を作成する.公式ドキュメントにあった .clinerules を機械翻訳したものを下記に示す.
# プロジェクトガイドライン
## ドキュメント要件
- 機能を変更する際は、`/docs` 内の関連ドキュメントを更新する
- `README.md` を新しい機能に合わせて更新する
- `CHANGELOG.md` に変更履歴を記録する
## アーキテクチャ決定記録(ADR)
以下の変更については、`/docs/adr` に ADR を作成する:
- 主要な依存関係の変更
- アーキテクチャパターンの変更
- 新しい統合パターンの追加
- データベーススキーマの変更
テンプレートは `/docs/adr/template.md` を使用すること。
## コードスタイルとパターン
- API クライアントは OpenAPI Generator を使用して生成する
- TypeScript の axios テンプレートを使用する
- 生成されたコードは `/src/generated` に配置する
- 継承よりもコンポジションを優先する
- データアクセスにはリポジトリパターンを使用する
- エラーハンドリングは `/src/utils/errors.ts` のパターンに従う
## テスト基準
- ビジネスロジックにはユニットテストを必須とする
- API エンドポイントには統合テストを実施する
- 重要なユーザーフローには E2E テストを実施する
公式の例を参考にしつつ,今回作成した例を次に示す.
# プロジェクトガイドライン
## 回答
### ロール
- プロフェッショナルなアーキテクトとして実装方針を考える
- プロフェッショナルなプログラマーとして実装方針に忠実に従ったコード実装を行う
### 回答の制限
- 基本的に思考は英語で行い,回答は日本語とする
## コードリポジトリの設計
### 技術要件
- バックエンド
- python
- フロントエンド
- streamlit
- テスト
- pytest
### ドキュメント
- ドキュメントは `/docs` に `.md` 形式で配置する
- 機能を変更する際は,`/docs` 内の関連ドキュメントを更新する
- `README.md` を新しい機能に合わせて更新する
- `CHANGELOG.md` に変更履歴を記録する
### コード
- 機能ごとにコンポーネントに区切る
- コンポーネントごとにディレクトリを分ける
- コンポーネント同士は疎結合とする
- pythonコードはPEP8の規約に従うこと
- コードの複雑な部分には特にwhyについて補足説明を追加する
## テスト
- テストはpytestで実施する
- 基本はコードエラーの修正をする
- 明確な指示がある場合は,コンポーネントに対してテストコードを作成し,ユニットテストを実施する
- 明確な指示がある場合は,API エンドポイントに統合テストを実施する
## セキュリティ
### ファイルアクセス
- `.env` ファイルは読み取らないこと
- .clineignore に定義されたファイルまたはディレクトリを読み込まない
- GitコマンドをShellで実行しない
### コーディング
- 機密情報は環境変数に格納する
さらに, .clineignore ファイルの例も次に示す.
# Environment variables
.env
.env.local
.env.example
.env.template
.env.development.local
.env.test.local
.env.production.local
# Systemfile
.DS_Store
# Large data files
*.csv
*.xlsx
*.pdf
*.jpg
data/
# Cache
**/__pycache__/
# Dependencies
**/venv*/
今回は大雑把な内容だが,大きいく共有して開発するプロジェクトを作る場合はより厳密に定義したほうが良い結果が得られそうである.また, .clinerules の解釈もモデルの性能に依存すると予想する.
利用
設定が完了したため利用を開始する.ここでは http://:8000 に接続しなければならないため今回はsshのポートフォワードなどで接続を確立する.
コマンド例.
$ ssh -i <ssh-key.pem> -L 8000:localhost:8000 <user>@<gpu-server-ipaddr>
Cile の利用
Cline には今のところ2つのモードがあるので,適宜使い分ける必要がある.
- プランモード:
- 全体的な方向性を決める.
- タスク開始直後や,アクションモードがつまずいたら実行する感覚.アクションの方向性を決めるため,推論(思考)が得意なモデルを選択すると良いと思われる.
- 要求はなるべく具体的に書き,プランを明確にすると良いと思われる.
- アクションモード:
- コード生成,編集を実行する.
- プランモードでレスポンスを受領した後,アクションモードに切り替えると自動的に処理が実行される.
- こちらは特にコンテクストサイズが重要だと思われる.
Cline はタスクという単位で作業を区切っている.タスクは上側の 「+」で追加できる.
- タスク:
- この中では同じコンテクストウィンドウで処理される様子.
- タスクごとに,上部にトークン数と消費したコンテクストウィンドウ(1度のプロンプトで参照できるトークンサイズのようなもの),コストが表示される.
- 利用したところ,プロジェクトのうち任意の修正(Gitのコミット単位に近い感覚)単位で実行するのがよいと思われた.
動作確認
実際に動作させてみた結果をまとめる.
表の各列について.
- 動作確認:デフォルト設定でvLLMで起動できるか.Clineでエラーなくレスポンスが得られるか.
- Context size: 今回,動作できる範囲で設定したモデルのコンテクストサイズ.
- token/s: 推論時のスループット.vLLMログの目測値であり,統計処理はしていない.
- VRAM: 推論開始前の
nvidia-smiでみたGPUメモリ消費.
| 名称 | 動作確認 | Context size | token/s | VRAM | 所感 |
|---|---|---|---|---|---|
| lightblue/DeepSeek-R1-Distill-Qwen-7B-Japanese | o | 77616(最大128k) | 28.1 | 19781MiB / 23028MiB | コードをファイルに出力してくれない,がplanの出力が詳細. |
| cyberagent/DeepSeek-R1-Distill-Qwen-14B-Japanese | x | 128000 | - | - | VRAMに載らない |
| Qwen/Qwen2.5-Coder-7B-Instruct | o | 22800 | 27.8 | 17813MiB / 23028MiB | 1ファイル100行未満の簡単なコードの作成. |
| Qwen/Qwen2.5-Coder-14B-Instruct | x | 22800 | - | - | VRAMに載らない |
| Qwen/Qwen2.5-7B-Instruct-1M | o | 73700k (最大は1010k) | 28.1 | 19535MiB / 23028MiB | 1ファイル100行未満の簡単なコードの作成. |
| Qwen/Qwen2.5-14B-Instruct-1M | x | 1010000 | - | - | VRAMに載らない |
Qwen/Qwen2.5-Coder-7B-Instruct
参考までに Qwen2.5-Coder-7B-Instruct で動かした場合どのようになったかを用途別に記載する.
コードの生成
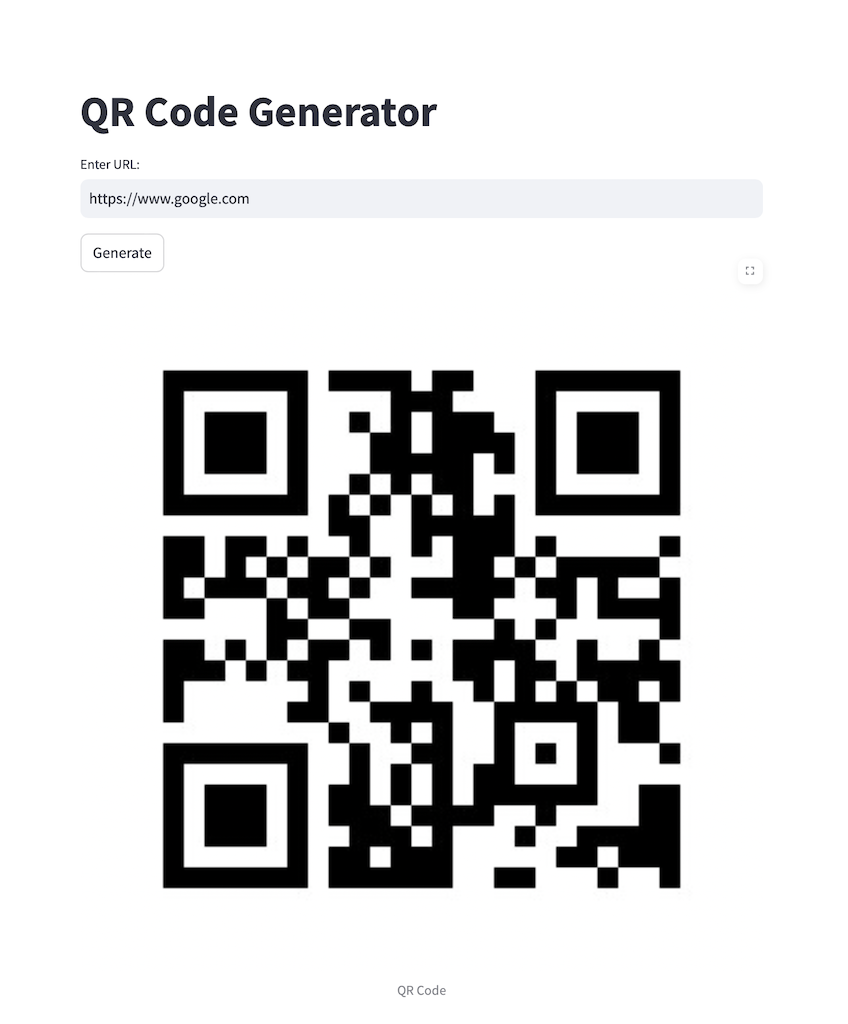
特定の利用目的に沿ったコードを生成させる.今回は入力されたURLに対してQRコードを生成するWebUIを作成してみる.
例としてPlanモードで次を実行する.
特定のURLを受け取ってQRコードを生成するアプリを開発したい.
環境
- qrcode
- streamlit
仕様
- テキストでURLの入力を受け付けるテキストボックスを配置.
- その後,「生成」ボタンで画面上にQRコードを画像として表示する.
- アプリの実行ファイル名はmake-qr.py
作業のステップが出力され,内容に満足したら,Actモードに切り替える.
場合によっては pip で環境構築が実行され,プロジェクトにコードが生成される.バグがある場合は,バグ修正をPlanモードで指示して繰り返し修正させる.今回はモデルの精度がイマイチなので何度かインデントの構文エラーなど簡単な問題を修正できなかった点は留意する必要がある.
結果を示す.一応動くものは出来上がった.
import streamlit as st
import qrcode
import io
def generate_qr_code(url):
qr = qrcode.QRCode(
version=1,
error_correction=qrcode.constants.ERROR_CORRECT_L,
box_size=10,
border=4,
)
qr.add_data(url)
qr.make(fit=True)
img = qr.make_image(fill='black', back_color='white')
img_byte_arr = io.BytesIO()
img.save(img_byte_arr, format='PNG')
img_byte_arr = img_byte_arr.getvalue()
return img_byte_arr
st.title('QR Code Generator')
url = st.text_input('Enter URL:')
if st.button('Generate'):
if url:
img = generate_qr_code(url)
st.image(img, caption='QR Code', use_container_width=True)
コードの変換
レガシーコードのリファクタリングを想定し,C → Python のコード変換(翻訳)をさせてみる.
次のカレンダーを表示する簡単なC (calendar-show.c)をpythonに変換させる.
#include <stdio.h>
// 各月の日数(閏年考慮なし)
int days_in_month[] = {0, 31, 28, 31, 30, 31, 30, 31, 31, 30, 31, 30, 31};
// うるう年かどうか判定
int is_leap_year(int year) {
return (year % 4 == 0 && year % 100 != 0) || (year % 400 == 0);
}
// 曜日を求める(ツェラーの公式を使用)
int get_start_day(int year, int month) {
if (month < 3) {
year--;
month += 12;
}
int k = year % 100;
int j = year / 100;
return (1 + (13 * (month + 1)) / 5 + k + (k / 4) + (j / 4) + (5 * j)) % 7;
}
// カレンダーを表示
void print_calendar(int year, int month) {
// うるう年なら2月の日数を29に設定
if (month == 2 && is_leap_year(year)) {
days_in_month[2] = 29;
} else {
days_in_month[2] = 28;
}
// 曜日を取得(0:土曜, 1:日曜, ..., 6:金曜)
int start_day = get_start_day(year, month);
// カレンダーのヘッダー
printf("\n %d年 %d月\n", year, month);
printf(" 日 月 火 水 木 金 土\n");
// 曜日を合わせるためのスペース
int i;
for (i = 0; i < start_day; i++) {
printf(" ");
}
// 日付を出力
for (int day = 1; day <= days_in_month[month]; day++) {
printf("%3d", day);
if ((day + start_day) % 7 == 0) {
printf("\n"); // 7日ごとに改行
}
}
printf("\n");
}
int main() {
int year, month;
printf("年と月を入力してください(例: 2025 3): ");
scanf("%d %d", &year, &month);
if (month < 1 || month > 12) {
printf("月の値が不正です(1~12を指定してください)。\n");
return 1;
}
print_calendar(year, month);
return 0;
}
例としてPlanモードで次を実行.
calendar-show.c を python に変換したい.calendar-show.py というファイルを作成して出力せよ.
ライブラリを利用しても問題ないので,適宜インストールする事.
結果.同じような動作をするpythonスクリプトが出来上がった.
import calendar
def print_calendar(year, month):
print(calendar.month(year, month))
if __name__ == "__main__":
year = int(input("年を入力してください(例: 2025): "))
month = int(input("月を入力してください(例: 3): "))
if month < 1 or month > 12:
print("月の値が不正です(1~12を指定してください)。\n")
exit(1)
print_calendar(year, month)
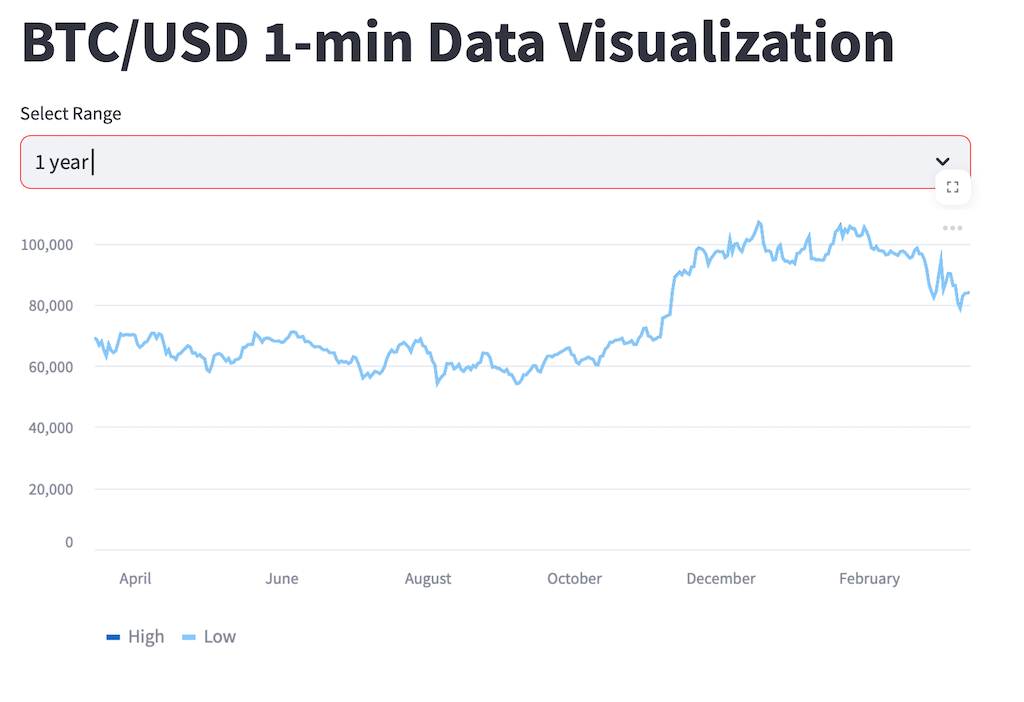
コードの生成(データの可視化)
直接LLMは与えられない程度の大きめのcsvデータ(300MB)を用意して可視化するコードを生成させる.今回はkaggleのデータセットを読み込ませて可視化してみる [14].
具体的には下記のような時系列データである.
Timestamp, Open, High, Low, Close, Volume
1325412060.0,4.58,4.58,4.58,4.58,0.0
1325412120.0,4.58,4.58,4.58,4.58,0.0
例としてPlanモードで次を実行.
btcusd_1-min_data.csvを読み出して可視化するアプリをstreamlitで作成せよ.
条件
- 可視化するのはHigh, Lowの平均とする
- データは事前に日毎に平均をとる事
- 可視化範囲はUIで週,月,年の粒度で選択できるようにする事
- 可視化範囲はデフォルトで最新の年月日から7日
- timestamp はdatetimeの年月日に変換する事
データについて
- 1行目はヘッダである
- 各行は分単位のデータを示す
データの最初の3行は下記.
Timestamp, Open, High, Low, Close, Volume
1325412060.0,4.58,4.58,4.58,4.58,0.0
1325412120.0,4.58,4.58,4.58,4.58,0.0
結果.少々要求とは違うが動くものはできる.
import streamlit as st
import pandas as pd
from datetime import datetime, timedelta
# データの読み込み
@st.cache_data
def load_data():
df = pd.read_csv('btcusd_1-min_data.csv')
df['Timestamp'] = pd.to_datetime(df['Timestamp'], unit='s')
df['Date'] = df['Timestamp'].dt.date
return df
# 日毎の平均計算
def calculate_daily_avg(df):
return df.groupby('Date').agg({'High': 'mean', 'Low': 'mean'}).reset_index()
# UIの設計
def create_ui(df):
st.title('BTC/USD 1-min Data Visualization')
selected_range = st.selectbox('Select Range', ['7 days', '1 month', '1 year'], index=0)
if selected_range == '7 days':
range_days = 7
elif selected_range == '1 month':
range_days = 30
else:
range_days = 365
# データのフィルタリング
filtered_df = df[df['Date'] >= (df['Date'].max() - timedelta(days=range_days))]
# 折れ線グラフの表示
st.line_chart(filtered_df.set_index('Date')[['High', 'Low']])
# メイン処理
if __name__ == '__main__':
df = load_data()
daily_avg_df = calculate_daily_avg(df)
create_ui(daily_avg_df)
まとめ
結果
- 閉域で動かすことは容易にできる
- 今回の環境では必要なコンテクストウィンドウを十分に維持して14Bの LLM は動かせない
- 小さい LLM では 1タスク = 1ファイルで,その一部分の編集が限度
- 小さい LLM ではエラーの修正に難あり.
考察
- 今回の環境では,Cline のドキュメントにもあるように簡単なタスクで利用するのが限界.
- 性能を上げるには,当然ながらモデルサイズとトークン長を増やすためにGPUを盛る必要がある.
- 7B を使う場合は Plan を deepseek,コードを qwen-coder など使い分けるとよいかもしれない.サービング方法は要検討.
参考
[1] Cline, https://github.com/cline/cline
[2] Cline docs, https://docs.cline.bot
[3] Openrouter, https://openrouter.ai
[4] Cline discussion, https://github.com/cline/cline/discussions/241
[5] Cline special files, https://docs.cline.bot/improving-your-prompting-skills/prompting
[6] Cline rules file article, https://zenn.dev/berry_blog/articles/c72564d4d89926
[7] Cline tag 3.3.0, https://github.com/cline/cline/releases/tag/v3.3.0
[8] Dev Containers, https://code.visualstudio.com/docs/devcontainers/containers
[9] Cursor, https://www.cursor.com/ja
[10] OpenHands, https://github.com/All-Hands-AI/OpenHands
[11] Cline-vs marketplace, https://marketplace.visualstudio.com/items?itemName=saoudrizwan.claude-dev
[12] Dev Containers-vs marketplace, https://marketplace.visualstudio.com/items?itemName=ms-vscode-remote.remote-containers
[13] MS-Learn, https://learn.microsoft.com/ja-jp/training/modules/use-docker-container-dev-env-vs-code/
[14] kaggle - Bitcoin Historical Data, https://www.kaggle.com/datasets/mczielinski/bitcoin-historical-data