はじめに
この記事では,Pythonを使って気象庁の「震源リスト」をスクレイピングする方法について解説します。
できるだけ詳しく解説したつもりなので,ぜひ最後までご覧ください!
おおまかな方針
まず,方針として「どのようにスクレイピングするか?」について説明します。
1.サイトにアクセスしてデータの場所を確認する
最初に,スクレイピングしたい気象庁のサイトへアクセスしましょう。
今回は「震源リスト」として公開されている地震情報(直近2年間分)を取ってきたいと思います。
↓ サイトはこんな感じになっています。
これは目次のページなので,データは入っていません。
そこで例えば「2022年4月17日」って書いてあるリンクをクリックしてみます。
すると,こんな↓ページが出てきて,「クリックするとリストが開閉します」の部分をクリックすると地震のデータが出現しました。
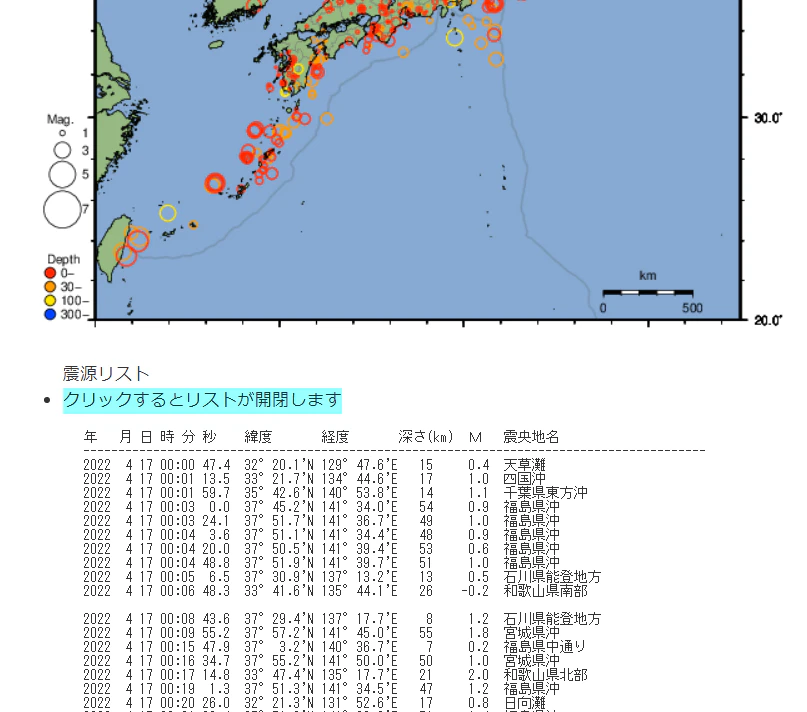
ここに記載されているデータをスクレイピングで取ってくればいいわけですね。
2.HTMLソースコードを見る
Webページから文字などをスクレイピングで取ってきたい場合,HTMLのタグを目印にします。
HTMLとは?
HTMLとは,我々が見ているようなWebページを生成するためのマークアップ言語のことです。 この「HTML」ってやつを,ChromeやSafariといったブラウザがうまく変換してくれて,Webページが見られるようになっています。じつはこのHTMLのコードは誰でも簡単に見られるようになっています。
Webページを開いている画面で,Ctrl + Uを押してみてください。
黒い背景の画面が出てきましたか?それがHTMLのソースコードです。
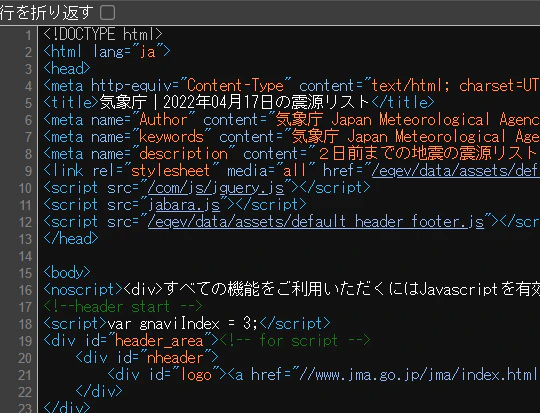
HTMLのソースコードを見ると,今回対象とするデータ部分は<pre>タグで囲まれていることがわかります。
ここで,<pre>タグはこのページに1つしかないことに注意しておきます。
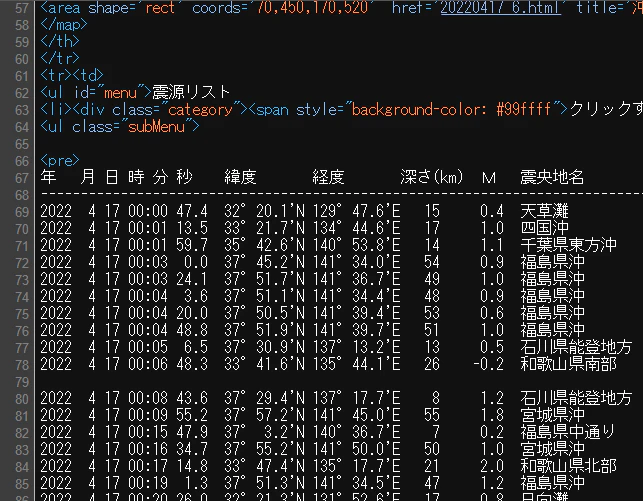
この<pre>タグに囲まれた部分を取り込んで,うまい感じに整理すれば良さそうです。
3.カラムへ分割する
ここまでで,スクレイピング作業は終わりました。
しかし,このままではデータとして扱うことができません。
なぜなら,スクレイピングで得たのは単なる1つの文字列だからです。
そこで,1つの地震ごとに分割したり,1つの地震情報を「年,月,日,…」と属性ごとに分ける必要があります。
つまり,
"2022 4 17 00:00 47.4 32°20.1'N 129°47.6'E 15 0.4 天草灘 \n2022 4 17 00:01 13.5 33°21.7'N 134°44.6'E 17 1.0 四国沖 \n2022 4 17 00:01 59.7 35°42.6'N 140°53.8'E 14 1.1 千葉県東方沖 \n2022 4 17 00:03 0.0 37°45.2'N 141°34.0'E 54 0.9 福島県沖 "
という文字列を,
[[2022, 4, 17, 00:00, 47.4, 32°20.1'N, 129°47.6'E, 15, 0.4, 天草灘 ],
[2022, 4, 17, 00:01, 13.5, 33°21.7'N, 134°44.6'E, 17, 1.0, 四国沖 ],
[2022, 4, 17, 00:01, 59.7, 35°42.6'N, 140°53.8'E, 14, 1.1, 千葉県東方沖 ],
[2022, 4, 17, 00:03, 0.0, 37°45.2'N, 141°34.0'E, 54, 0.9, 福島県沖 ]]
のような分析に適した形式にしなければなりません。
ここまでやれば,作業完了となります。
詳細とコードの解説
ではここから,どのようにPythonコードを書いていけばいいか説明していきます。
コードの説明については,コメントとして書いたのでそこをお読みいただければと思います。
全コードはこちら
# 必要なライブラリをインポート
import numpy as np
import pandas as pd
import requests
from bs4 import BeautifulSoup
from tqdm import tqdm
# 震源リストに掲載されている分の年月日をshingen_listへ格納
URL_index = "https://www.data.jma.go.jp/svd/eqev/data/daily_map/index.html"
res = requests.get(URL_index)
soup = BeautifulSoup(res.content, "html.parser")
shingen_list = [i.get("href") for i in soup.find_all("a") if len(i.get("href"))==13]
# レコード形式
format_dict_1 = {"年":4, "月":2, "日":2, "時分":5, "秒":4,
"緯度":10, "経度":10,
"深さ(km)":7, "M":5, "震央地名":34}
## 入力された1行のレコードを分割する関数を定義
def split_record_1(record):
record_list = []
cnt = 0
for p,c in enumerate(record[59:]):
if c == " ":
break
for name,i in format_dict_1.items():
record_list.append(record[cnt:cnt+i])
cnt += i+1
return record_list
# スクレイピング
URL1 = "https://www.data.jma.go.jp/svd/eqev/data/daily_map/"
df_1 = []
## ページでforループ
for day in tqdm(shingen_list):
url = URL1 + day
res = requests.get(url)
soup = BeautifulSoup(res.content, "html.parser")
r = soup.pre.text # レコード部分を抽出
# ループで1行ずつ取り出す
for record in [i for i in r.split("\n") if len(i)>1][2:]:
df_1.append(split_record_1(record))
# DataFrameに格納
df_1 = pd.DataFrame(df_1, columns=format_dict_1.keys())
必要なライブラリをインポート
import numpy as np
import pandas as pd
import requests # HTTPリクエスト
from bs4 import BeautifulSoup # HTML解析
from tqdm import tqdm # 進捗状況をバーで表示(なくてもよい)
掲載されている年月日をしらべる
目次ページに書いてあるすべての日付についてデータを集めたいので,全日付分ののURLを取得する必要があります。
HTMLソースコードを見てみると,そのURLは<a>タグのhref属性にあるとわかります。
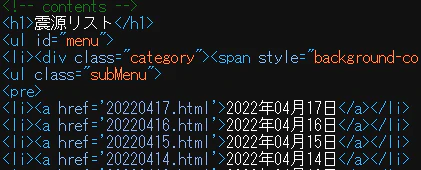
これらをBeautifulSoupで拾ってきて,リストに格納すればOKですね。
# 震源リストに掲載されている年月日をshingen_listへ格納
## 目次のURLをURL_indexに代入
URL_index = "https://www.data.jma.go.jp/svd/eqev/data/daily_map/index.html"
## requestsモジュールのgetメソッドを使うと,Webサーバーに「このページちょうだい」と要求できる
res = requests.get(URL_index)
## getしたWebページの中身(res.content)をBeautifulSoupに渡して,HTMLを解析してもらう
## 引数"html.parser"は「HTMLを解析してね」という意味。
## これ ↑ がないとXML形式として認識されてしまいエラーになることがあるらしい。
soup = BeautifulSoup(res.content, "html.parser")
## soup.find_all("a")
## ...... <a>タグを全て拾ってくる
## i.get("href")
## ...... [<a>タグの中の] href属性(URLが入ってる)を取得する
## len(i.get("href))==13
## ...... 同ページ内にもいろいろリンクがあったので,文字数を指定して必要なものだけ選別
shingen_list = [i.get("href") for i in soup.find_all("a") if len(i.get("href"))==13]
レコード形式を調べて分割する
データがどのような形式になっているかを調べてみましょう。
2022 4 17 00:00 47.4 32°20.1'N 129°47.6'E 15 0.4 天草灘
このレコードを見ると,形式は次のようになっていることがわかります。
(数字は文字数(半角)を表しています)
| 年 | 月 | 日 | 時分 | 秒 | 緯度 | 経度 | 深さ(km) | M | 震央地名 |
|---|---|---|---|---|---|---|---|---|---|
| 4 | 2 | 2 | 5 | 4 | 10 | 10 | 7 | 5 | 34 |
(*各カラムの間が半角1スペースになるようにあてはめました。)
これをもとに,レコードを分割していきます。
# レコード形式
format_dict_1 = {"年":4, "月":2, "日":2, "時分":5, "秒":4,
"緯度":10, "経度":10,
"深さ(km)":7, "M":5, "震央地名":34}
## 入力された1行のレコードを分割する関数を定義
def split_record_1(record):
record_list = []
cnt = 0
# 「震央地名」は全角文字で長さが34よりズレるので行ごと修正
for p,c in enumerate(record[59:]):
if c == " ":
break
# スライスで取り出す
for name,i in format_dict_1.items():
record_list.append(record[cnt:cnt+i])
cnt += i+1
return record_list
スクレイピング!
URL1 = "https://www.data.jma.go.jp/svd/eqev/data/daily_map/"
df_1 = [] # スクレイピング&分割結果をここへ格納
## ページでforループ
for day in tqdm(shingen_list):
url = URL1 + day
res = requests.get(url)
soup = BeautifulSoup(res.content, "html.parser")
r = soup.pre.text # レコード部分を抽出(<pre>タグ指定)
# ループで1行ずつ取り出す
# ...... 改行文字"\n"で分割すれば行へ分割できる
# ...... if len(i)>1 は,空白行をスキップするため
# ...... [2:]はヘッダー(カラム名,線(=====))をスキップするため
for record in [i for i in r.split("\n") if len(i)>1][2:]:
df_1.append(split_record_1(record))
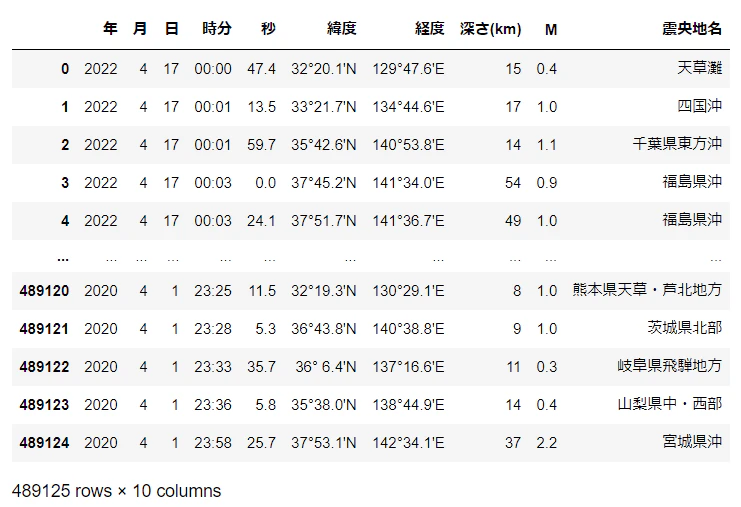
DataFrame化して完成!
# DataFrameへ変換
df_1 = pd.DataFrame(df_1, columns=format_dict_1.keys())
成功していれば,こんな感じになるはずです!
最後に
今回は,Pythonで気象庁の地震情報をスクレイピングで取得する方法について解説しました。
本記事で紹介したサイトでは,直近2年間のデータしか得られませんでしたが,実は1919年からの古いデータも気象庁のサイトで公開されています。(参考:地震月報(カタログ編))
ここで解説した方法と同じ感じでやれば,こちら↑のデータ収集もできると思うので,ぜひやってみてください!