はじめに
こんにちは。まっちゃ。です。![]()
今回は、画像認識における"物体検出"のモデルについてまとめていきます。
目次
- 物体検出とは
- 各モデルの特徴
- Faster R-CNN
- YOLO
- FCOS
- DETR
- まとめ
物体検出とは
画像認識におけるタスクの一つであり、画像内の物体の位置およびクラスを同時に推定します。また、物体検出モデルはバウンディングボックスとクラスを出力する形で実装されます。
以下に物体検出を行った画像の一例を示します。オリジナルの画像は、Unsplashからダウンロードしました。
左図がオリジナルの画像、右図が物体検出後の画像になります。物体検出後の画像において、画像中の犬と猫をそれぞれ検出できていることが分かります。


各モデルの特徴
ここでは、代表的な下記4つのモデルについて、特徴をまとめていきます。
- CNNベースモデル
- Faster R-CNN
- YOLO
- FCOS
- Transformerベースモデル
- DETR
CNNベースの物体検出モデル
CNNベースの物体検出モデルは標準的に、「バックボーン」、「ネック」、「ヘッド」の3つの要素で構成されています。以下の表に、それぞれの役割を示します。
| 要素 | 役割 |
|---|---|
| バックボーン | 入力画像からマルチスケールの特徴を抽出、主に学習済みの画像分類モデルを使用 |
| ネック | バックボーンで抽出された画像特徴を集約し、洗練化された画像特徴を出力 |
| ヘッド | ネックが出力する特徴マップをもとに、各ボックス位置とクラスを推定 |
Faster R-CNN
Faster R-CNNは、バックボーン、特徴ピラミッドネットワーク(FPN: Feature Pyramid Network)、領域提案ネットワーク(RPN: Region Proposal Network)、検出ヘッドの4つで構成されます。以下の図に、全体像を示します。

FPNは、ネックと同様の処理を行います。具体的には、バックボーンで出力されるマルチスケールの特徴マップを統合し、画像特徴を洗練化します。
RPNは、物体が存在し得る位置と物体らしさを推定します。以下の図に、RPNの概略を示します。物体候補のボックス位置を出力する際、アンカーと呼ばれる特徴マップ上の点を用います。このアンカーから固定のアスペクト比とスケールをもつアンカーボックスを生成します。アンカーボックスと正解ボックスとのずれから物体が存在し得る位置を計算します。また、各アンカーボックスと正解ボックスとのIoU1を用いて正解ラベル(物体)を生成します。

RPNで出力されるボックスは数が多く、それらの大部分は重複します。そこで検出ヘッドでは、RPNで出力され物体らしさのスコアを用いて選別したボックスに対して、非最大抑制(NMS: Non-Maximum Supression)を適用することで、重複するボックスを削除します。また、関心領域プーリング(ROIプーリング)を用いて、ボックスで囲まれた特徴マップのサイズを均一にします。
このようにFaster R-CNNは、RPNで物体候補領域を検出し、検出ヘッドで最終的なボックス位置とクラスを推定するため、2ステージアプローチの物体検出モデルとなります。
YOLO (You Only Look Once)
続いて、YOLOを取り上げます。YOLOは、ボックス位置とクラスを同時に推定する、1ステージアプローチの物体検出モデルです。バックボーン、FPN、検出ヘッドの3つで構成されます。
YOLOでは以下の流れで、ボックス位置とクラスの推測を行います。
- 入力画像をグリッドセルと呼ばれる領域で分割
- グリッドセルにバウンディングボックスを設定し、バウンディングボックス毎の位置と信頼度(物体らしさ)を推測
- グリッドセルごとに物体クラスの条件付き確率を推測
- バウンディングボックスの信頼度とクラスの確率をかけ合わせることで、バウンディングボックス毎のクラスに対する信頼度スコアを算出し、信頼度スコアをもとに、どのバウンディングボックスが物体を検出しているかを判断
以下の図に、YOLOにおける物体検出の流れを示します。犬、自転車、車の領域がバウンディングボックスで推測され(2.)、クラスの予測についてもそれぞれの色で推測されています(3.)。最終的に、犬、自転車、車がそれぞれ検出されていることが分かります(4.)。

ここまでに取り上げた、Faster R-CNNとYOLOはアンカーを用いた物体検出モデルです。アンカーを用いた物体検出には、以下の欠点があります。
- 事前にアンカーに関する多数のパラメータ設定が必要
- ポジティブサンプル(物体)とネガティブサンプル(背景)が不均衡
これらの欠点を克服したモデルとして、FCOSがあります。
FCOS (Fully Convolutional One-Stage Object Detection)
FCOSは、1ステージアプローチかつアンカーを用いない物体検出モデルです。バックボーン、FPN、検出ヘッドの3つで構成されます。以下の図に、全体像を示します。アンカーを用いていないために上述した欠点をがなく、また、アンカーに関する計算コストを削減することで、実装が簡単になります。

アンカーを用いていないため、アンカーとは異なる方法で正解ラベルを決める必要があります。そこで、FCOSでは特徴マップ上の正解ボックス内に含まれるすべての画素をポジティブサンプルとして扱い、クラスを決定します。また、ボックス位置を推測する際、各画素から正解ボックスの各辺までの距離を用います。以下の図に、対象となる各画素から正解ボックスまでの距離を示します。右図のように、同一画素において正解ボックスが重複する場合は、小さいボックスを対象とします。

ここまでで最適化を行った場合、正解ボックスの中心から離れた位置におけるバウンディングボックスの影響で推論精度が悪くなります。そこで、正解ボックスの中心ほど1.0に近づくセンターネススコアを推定し、クラススコアに乗算します。結果として、物体の中心から離れた低品質のバウンディングボックスのスコアを抑制し、検出精度を向上させることができます。以下の図に、センターネスの概略を示します。中心に近いほどスコアが大きく(赤く)、中心から離れるにつれてスコアが低く(青く)なっていることが分かります。

ここまでに取り上げた3つのモデルは、重複するバウンディングボックスを削除するために後処置においてNMSを適用する必要があります。NMSはパラメータを設定する必要があり、モデルが複雑になるといった欠点があります。
この欠点を克服したモデルとして、TransformerベースのDETRがあります。
DETR (Detection Transformer)
DETRは、物体検出を直接集合推定問題として捉えた、1ステージアプローチの物体検出モデルです。物体検出で初めて、Transformerを採用したモデルになります。FCOSは、バックボーン、Transformerエンコーダ、デコーダ、検出ヘッドの4つで構成されます。
DETRでは以下の流れで、ボックス位置とクラスの推定を行います。
- バックボーンから出力された特徴マップに位置情報を追加し、エンコーダへ出力
- エンコーダにてクエリ、キー、バリューを作成し、計算される特徴マップと共にデコーダへ出力
- オブジェクトクエリとエンコーダから出力された特徴マップを用いて、最終的なオブジェクトクエリを作成し、検出ヘッドへ出力
- FFNを通して、ボックス位置とクラスを推定
以下の図に、DETRの全体像を示します。デコーダへ入力されるオブジェクトクエリは、初期値がランダムなパラメータであり、ボックス位置とクラスを推定するために用いられます。オブジェクトクエリ数は、画像中に含まれる物体数より多くする必要があります。

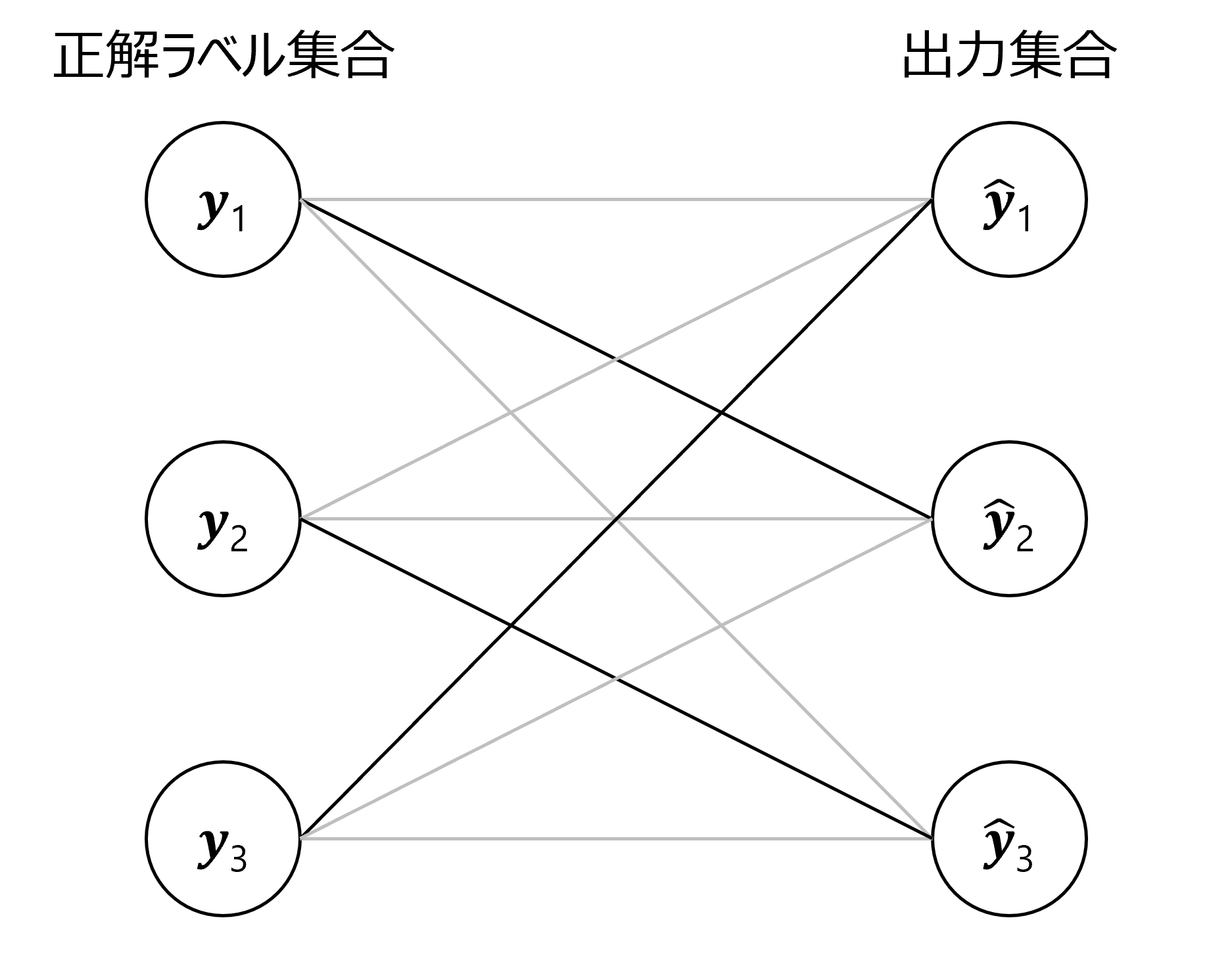
DETRでは推論と正解のマッチングが正しく行われているかを判断するため、2部グラフマッチングを実施します。以下の図に、2部グラフマッチングの例を示します。ここでは、2部グラフマッチングにおいて、異なる2つの集合要素(ボックス情報およびクラスラベルの集合と正解ラベル集合)を重複なく組み合わせた際に、損失値が最小となる組み合わせを求めます。これにより推定結果と正解ラベルを1対1対応させることができます。結果として、DETRでは過剰な検出を抑制でき、NMSなどの後処理が不要な物体検出を実現できます。
まとめ
今回は、物体検出のモデルに関する概要をまとめました。各モデルについて、どのような構造を用いているかや推論方法を知るためのいい機会となりました。CNNベースおよびTransformerベースそれぞれのモデルは、各特徴を活かして現在まで応用されているモデルであることも再確認することができました。これらのモデルをベースとして改良されたモデルも数多く出ているので、変更点を踏まえて改良されたモデルについても各構造や推論方法に関する理解を深めたいです。
参考
この記事は、各モデル説明において記載している記事と以下の書籍を参考にして執筆しました。
-
IoU (Intersection over Union)とは、正解ボックスと推測ボックスの重なり具合を図る指標です。最小値0.0、最大値1.0をとります。完全に一致したときは、1.0となります。 ↩