はじめに
こんにちは。まっちゃ。です。![]()
今回は、物体検出モデルの1つである「YOLO」についてまとめていきます。
目次
- YOLOとは
- モデルの遷移
- まとめ
YOLOとは
画像中において、物体のボックス位置とクラスを同時に推定する物体検出モデルの一つです。「画像を一度見るだけでいい」と言った意味から、「You Only Look Once」の頭文字をとって「YOLO」と名づけられています。
YOLOは非常に高速であるため、リアルタイムの物体検出に適しています。
モデルの遷移
モデルはYOLOv1を起源として、現在までにYOLOv10が公開されています。
以下で、各モデルの特徴をまとめていきます。
YOLOv1
Joseph RedmonとAli Farhadiによって開発された物体検出モデルです。高精度で高速な物体検出モデルであることから、当時人気を博しました。
YOLO以前の物体検出モデルは、物体のボックス位置とクラスの推定を別々に行っていました。一方YOLOは、画像全体から物体のボックス位置とクラスの推定を同時に行うため、高速な物体検出が可能となります。
以下の図に、YOLOの推論時における流れを示します。画像をグリッドで分け、グリッドごとに物体のボックス位置の信頼度およびクラスの確率を推定します。その後、ボックス位置の信頼度とクラス確率を掛け合わせて、物体検出を行います。
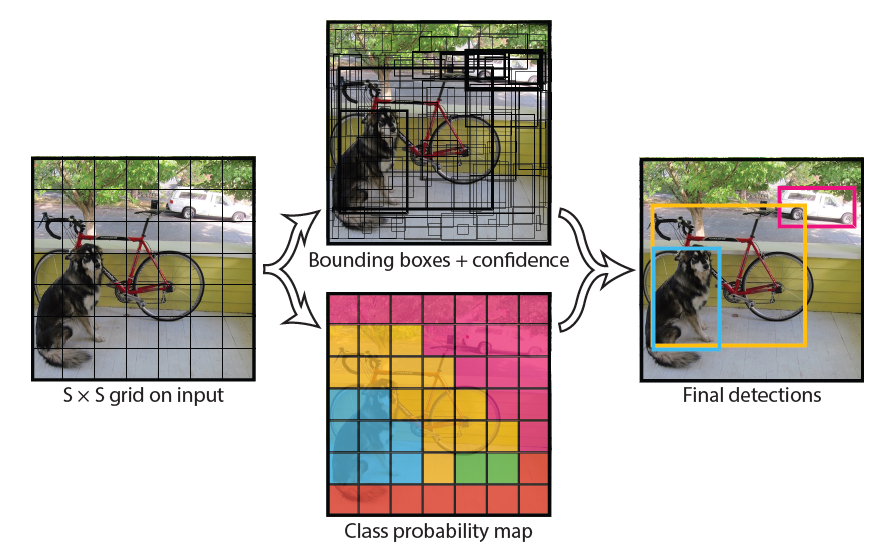
YOLOv2
Joseph RedmonとAli Farhadiによって開発された物体検出モデルです。YOLO9000と呼ばれるように、9000種類のクラスを検出できるモデルとして開発されました。
YOLOv2はYOLOv1と比較して、以下のような特徴が追加されています。
- Batch Normalization
学習を安定させ、収束を高速化しています。
- Anchor Boxes
画像中に等間隔でアンカーと呼ばれる点を作成し、アンカーを中心としてアスペクト比が決められたアンカーボックスを作成します。その後、アンカーボックスと正解ボックスのIoUをもとにボックス位置を推定します。これにより、推定されるボックス位置の精度を向上させています。
- Dimension Clusters
k-meansクラスタリングを用いて、アンカーボックスにおける枠の数やスケール、アスペクト比を自動で決定しています。これにより、手動でアンカーボックスの設定値を決める必要がなくなり、ボックス位置の精度を向上させています。
- High Resolution Classifier
高解像度の画像で学習を行うことで、高解像度の画像を効率的に処理できるようにしています。
以下の図に、YOLOv2とその他のモデルにおける物体検出の精度および速度を示します。他のモデルと比較して遜色ない精度をもち、高速であることが分かります。
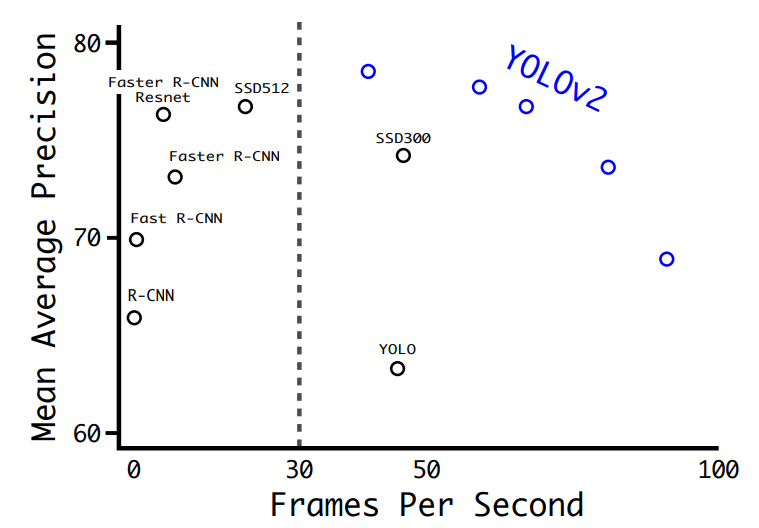
YOLOv3
Joseph RedmonとAli Farhadiによって開発された物体検出モデルです。効率的なバックボーンネットワーク、複数のアンカー、FPNを導入して、さらに性能を向上させたモデルです。
YOLOv3は、以下のような特徴を有しています。
- feature pyramid networks (FPN)
入力画像を3つの異なるサイズの検出カーネル(13x13, 26x26, 52x52)で処理し、各スケールでボックス位置とクラスを予測します。これにより異なるサイズ、特に小さいサイズの物体検出精度を向上させています。
以下の図に、YOLOv3とその他のモデルにおける物体検出の精度および精度を示します。他のモデルと比較して遜色ない精度をもち、高速であることが分かります。
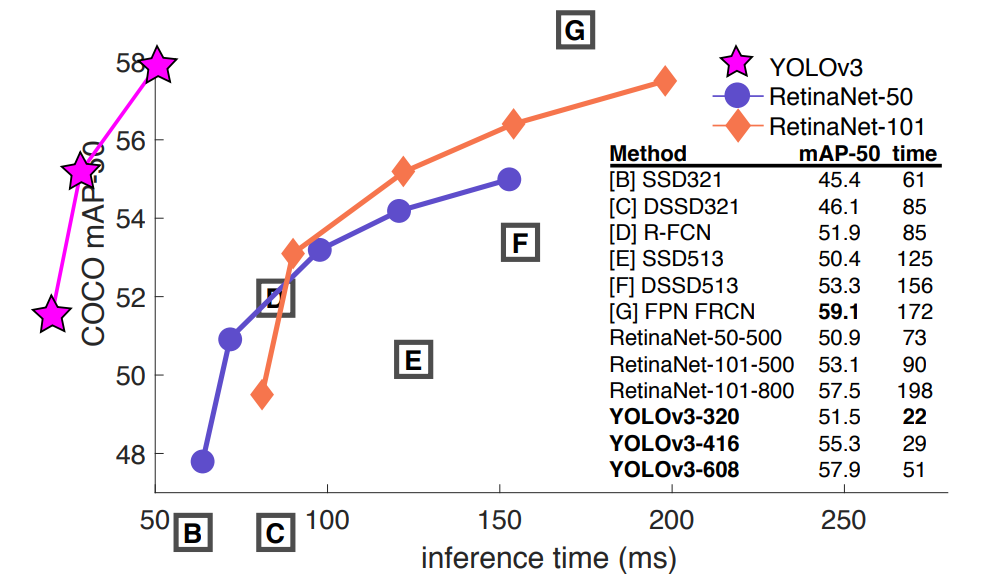
YOLOv4
Alexey Bochkovskiyらにより開発されたモデルです。YOLOv4のネック部分には、SPPとPANが用いられています。
- Spatial Pyramid Pooling (SPP)
以下の図に、SPPの概略を示します。特徴マップについて、マルチスケールでプーリングしたベクトルを結合します。この処理により、物体のスケール変化に対するロバスト性を向上させています。

- Path Aggregation Network (PAN)
以下の図に、PANの全体像を示します。局所的なパターンへの感度が高い下位層の情報は、ボックス位置の精度向上に寄与します。そこで、下位層の情報を効率的に伝搬するために非効率な経路(赤線)ではなく効率的な経路(緑線)を使用しています。

また、YOLOv4は性能を最適化させるために'bag of freebies'と'bag of specials'の手法が用いられています。
'bag of freebies'は、推論コストを増加させることなく、学習時の精度を改善する手法です。例として、入力画像のばらつきを増やすデータ拡張があり、モデルのロバスト性を改善するために用いられています。
'bag of specials'は、推論コストをわずかに増加させる一方、精度を劇的に改善する手法です。プラグインモジュールと後処理にて用いられています。
以下に、YOLOv4で用いられている詳細な手法を羅列します。
- Bag of Freebies (BoF) backbone
- CutMix
- Mosaic data augmentation
- DropBlock regularization
- Class label smoothing
- Bag of Specials (BoS) backbone
- Mish activation
- Cross-stage partial connections (CSP)
- Multi-input weighted residual connections (MiWRC)
- Bag of Freebies (BoF) detector:
- CIoU-loss,
- Cross mini-Batch Normalization (CmBN)
- DropBlock regularization
- Mosaic data augmentation
- Self-adversarial-training (SAT)
- Eliminate grid sensitivity
- Using multiple anchors for a single ground truth
- Cosine annealing scheduler
- Optimal hyperparameters
- Random training shapes
- Bag of Specials (BoS) detector:
- Mish activation,
- SPP-block
- SAM-block
- PAN path-aggregation block
- DIoU-NMS
以下の図に、YOLOv4とその他のモデルにおける物体検出の精度および速度を示します。他のモデルと比較して遜色ない精度をもち、高速であることが分かります。
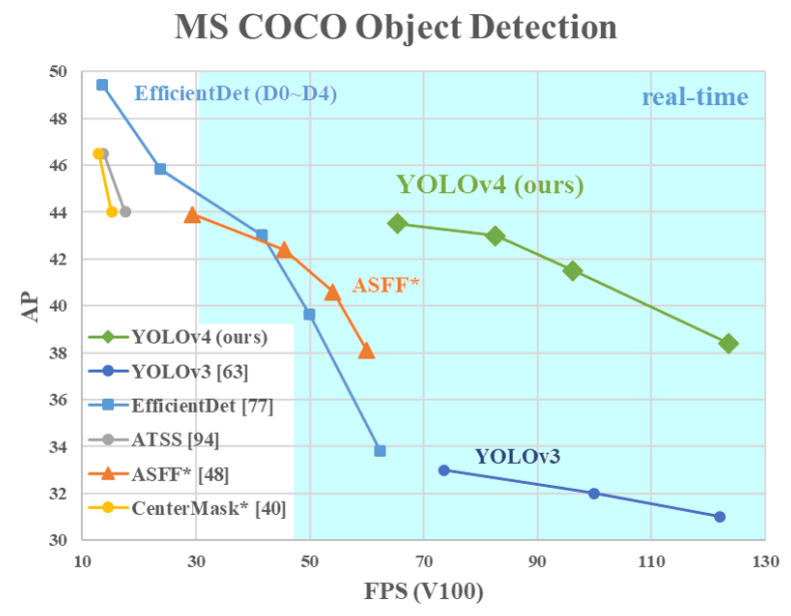
YOLOv5
モデルの性能を向上させ、ハイパーパラメータの最適化、実験追跡の統合、一般的な出力フォーマットへの自動出力といった特徴が追加されました。
UltralyticsによりYOLOv5のアーキテクチャをもとにしたYOLOv5uが開発されています。
YOLOv5uは、以下の特徴を有しています。
- Anchor-free Split Ultralytics Head
従来は物体の位置を推定するため、アンカーボックスに依存していました。Anchor-free Split Ultralytics Headを用いることで、より柔軟な検出モデルを提供しています。
- 精度と速度のトレードオフの最適化
精度を維持し、リアルタイム検出を実現します。これは、自動運転などの迅速な応答が要求されるアプリケーションにとって重要となります。
- 多様な事前学習済みモデル
万能な解決法を提供するだけでなく、タスクに応じてモデルを微調整することが可能です。
YOLOv6
Meituanによってオープンソース化された産業用の物体検出モデルです。精度と速度のバランスを備え、リアルタイムアプリケーションに最適な物体検出モデルです。
YOLOv6は、以下の特徴を有しています。
- Bidirectional Concatenation (BiC) Module
隣接する3つの層の特徴マップを統合し、局在化シグナルを拡張します。結果として、より正確な局在化シグナルを保持し、速度劣化を最小限に抑えて性能を向上させています。

- Anchor-Aided Training (AAT) Strategy
以下の図に、AATの概略を示します。AATは回帰と分類の両ヘッドに適用されており、学習時にアンカーフリーの損失にアンカーベースの損失を統合することで性能を向上させています。
また、推論時はアンカーベースの損失計算を削除することで速度を低下させることなく、精度を向上させています。

- Self-Distillation Strategy
小さいモデルにおける学習効率を高め、精度を向上させています。学習時に教師とハードラベルにより情報が更新されるため、より効果的に学習ができます。
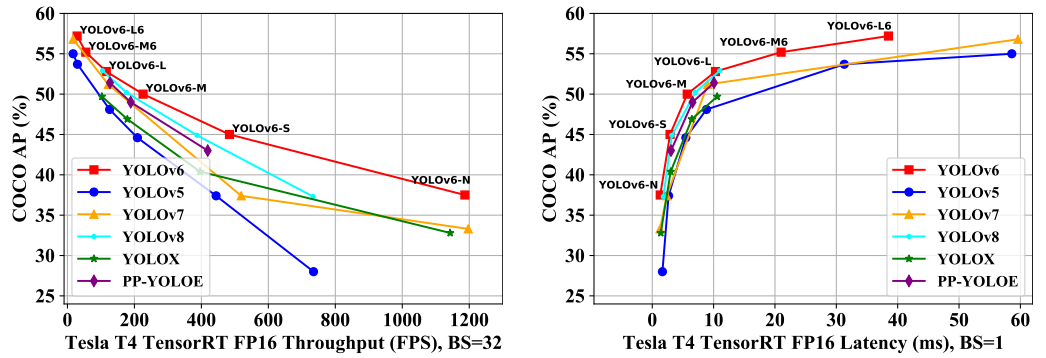
以下の図に、YOLOv6とその他のモデルにおける物体検出の精度および速度を示します。他のモデルと比較して、精度および速度を高水準で達成しています。
YOLOv7
Chien-Yao Wangらにより開発されたモデルです。従来のリアルタイム物体検出では、アーキテクチャの最適化に着目されてきました。一方YOLOv7では、学習の最適化に着目しています。
また、YOLOv7は推論のコストを増加することなく物体検出の精度を改善する'trainable bag-of-freebies'の概念を取り入れたモジュールと手法を含みます。
YOLOv7は、以下の特徴を有しています。
- Model Re-parameterization
再パラメータ化モデルは、勾配伝搬経路をもつ異なるネットワーク層において適用可能な手法です。学習時と推論時で別の構造をもつネットワークを使用します。
- Dynamic Label Assignment
複数の出力層をもつモデルの学習で発生する問題を解決するため、YOLOv7では、リード・ガイド・ラベル割り当てと呼ばれる新しいラベル割り当てを採用しています。
以下の図に、YOLOv7で用いられているラベル割り当ての概要を示します。従来の方法では、Lead HeadとAux Headのラベル割り当ては独立しています。一方YOLOv7では、Lead HeadとAux Headの両方のラベル割り当てにLead Headの結果を使用しています。このようにLead Headで学習した情報をAux Headに直接学習させることで、Lead Headの学習効率を向上させています。
また、粗-細Lead Headによるラベル割り当ては、粗いラベルと細かいラベルの2つのソフトラベルを生成します。このとき、粗いラベルの制約を緩和することで、学習能力が高くないAux Headにおいて学習すべき情報を失わないようにし、精度を向上させています。

- Extended and Compound Scaling
パラメータと計算を効率的に利用するリアルタイム物体検出のため、複合スケーリング手法が導入されています。
以下の図に、複合スケーリングの概略を示します。連結ベースのモデルにおいては、depthの増加に伴い、widthも増加します。そのため、入力と出力間で比率が変化し、効率低下を招きます。Yolov7で導入されている複合スケーリングでは、depthのスケーリングにより算出された変化量を用いてwidthのスケーリングを行います。結果として、最適な構造を維持することができます。

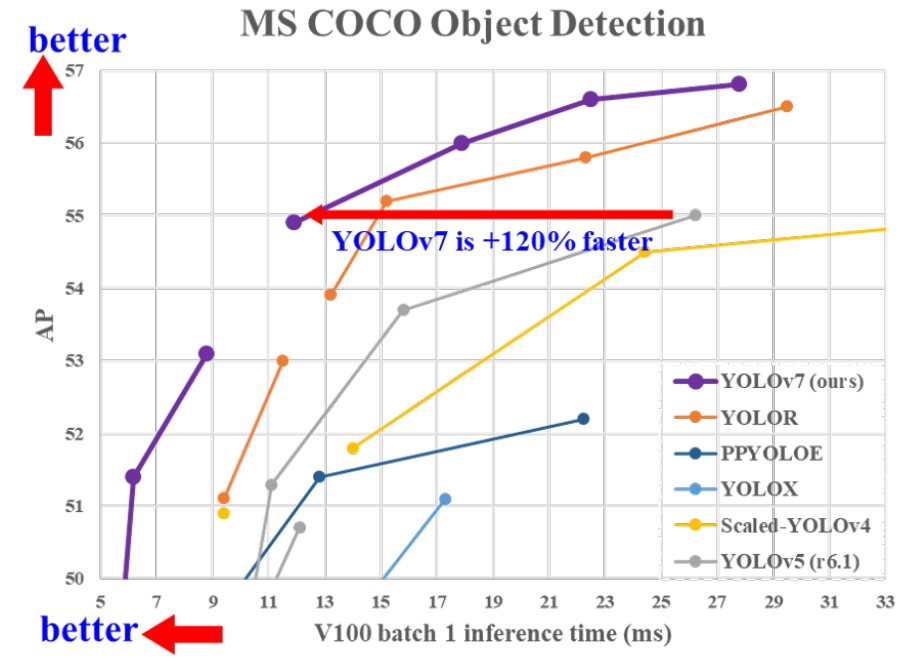
以下の図に、YOLOv7とその他のモデルにおける物体検出の精度および速度を示します。精度および速度ともに他のモデルを上回る結果となっています。
YOLOv8
UltralyticsによるYOLOの最新バージョンです。検出、セグメンテーション、姿勢推定、指向性物体検出、分類といった様々なタスクに対応しています。この汎用性により、YOLOv8の機能を多様なアプリケーションやドメインで活用することができます。
YOLOv8は、以下の特徴を有しています。
- Anchor-free Split Ultralytics Head
アンカーベースのモデルと比較して、精度が高く効率的な検出プロセスをもたらします。
- 精度と速度のトレードオフの最適化
精度と速度を両立させ、様々な応用分野におけるリアルタイム検出に適しています。
- 多様な事前学習済みモデル
様々なタスクや要求性能に対応する事前学習済みモデルを提供しており、特定のケースに適したモデルを容易に選択することができます。
YOLOv9
Chien-Yao Wangらによって開発されたモデルです。Ultralytics YOLOv5によって提供された堅牢なコードベースに基づいて構築されています。
PGIとGELANを統合することで、学習能力を向上させるだけでなく、検出プロセスを通して重要な情報を保持します。それにより、卓越した精度と性能を達成します。
学習した情報はネットワーク層を通過するにつれて、消失する可能性が増加します。情報消失への対応は、軽量モデルにとって重要です。YOLOv9のアーキテクチャーでは、PGIと可逆関数により必要不可欠な情報を保持します。
YOLOv9は、以下の特徴を有しています。
- Programmable gradient information (PGI)
以下の図に、PGIの概要を示します。PGIはmain branch、auxiliary reversible branch、multi-level auxiliary informationの3要素で構成されます。PGIにおけるauxiliary reversible branchにより信頼性の高い勾配を取得できます。また、multi-level auxiliary informationによりマルチスケールの画像における物体の位置情報を損なうことなく、効率的に学習することができます。結果として、深いネットワーク層を通して必要不可欠な情報を保持することが可能となり、全体的な検出性能を向上させています。
また、推論過程ではmain branchのみ使用するため、コストを増加することなく推論を行うことができます。

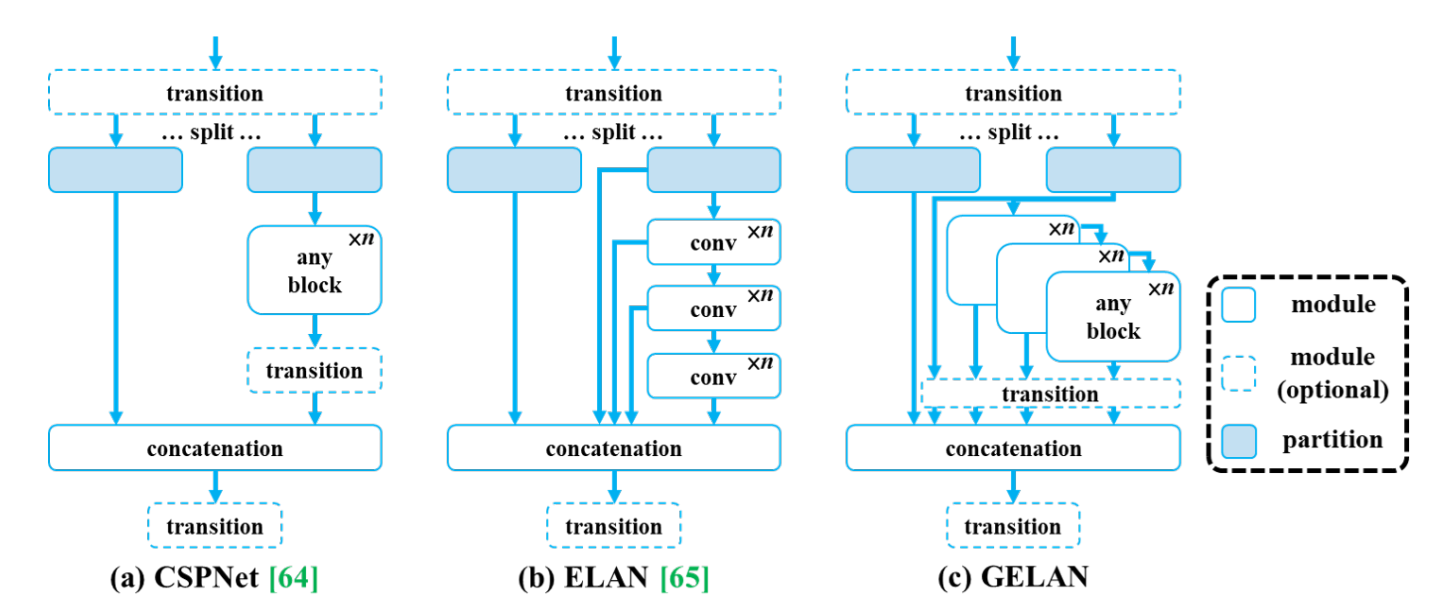
- Generalized Efficient Layer Aggregation Network (GELAN)
以下の図に、GELANの概要を示します。従来の畳み込み演算のみを使用して、各層からの情報を効率的に集約することで、計算コストを削減しながら性能を向上させます。様々な計算ブロックに柔軟に統合できるため、精度や速度を犠牲にすることなく、幅広いアプリケーションに応用することができます。
また、以下の図に、GELANにより出力された特徴マップを示します。他のモデルと比較して、情報の損失が抑制されていることが分かります。これは、信頼性の高い勾配情報が取得可能であることを示します。

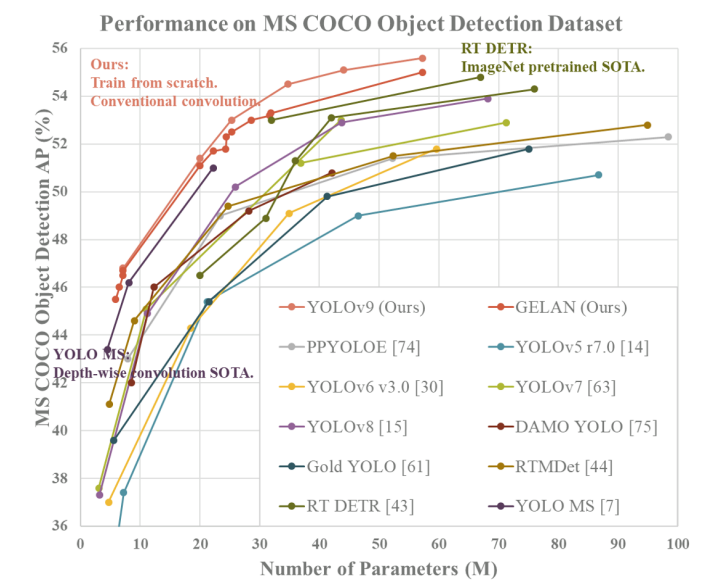
以下の図に、YOLOv9とその他のモデルにおける物体検出の精度および速度を示します。精度および速度ともに他のモデルを上回る結果となっています。
YOLOv10
清華大学の研究者たちによって作成されたモデルです。NMSを排除するEnd-to-Endヘッドを導入して計算コストを削減することで、リアルタイムの物体検出へ寄与しています。
従来のYOLOシリーズにおいては、NMSの依存とアーキテクチャの非効率性が性能を妨げてきました。YOLOv10ではNMSを使用しない学習と全体的な効率および精度を重視したモデル設計戦略を導入することで、さらなる性能向上を実現しています。
YOLOv10は、以下の特徴を有しています。
- Dual label assignments
以下の図に、二重ラベル割り当ての概要を示します。二重ラベル割り当てでは、'One-to-many Head'と'One-to-one Head'が用いられます。- One-to-many Head
学習時においてオブジェクトごとに複数の予測を生成し、豊富な信号をもたらすとともに学習精度を向上します。 - One-to-one Head
予測時においてオブジェクトごとに最適な1つの予測を生成するため、NMSが不要となります。そのため、レイテンシを抑制し、効率が改善します。
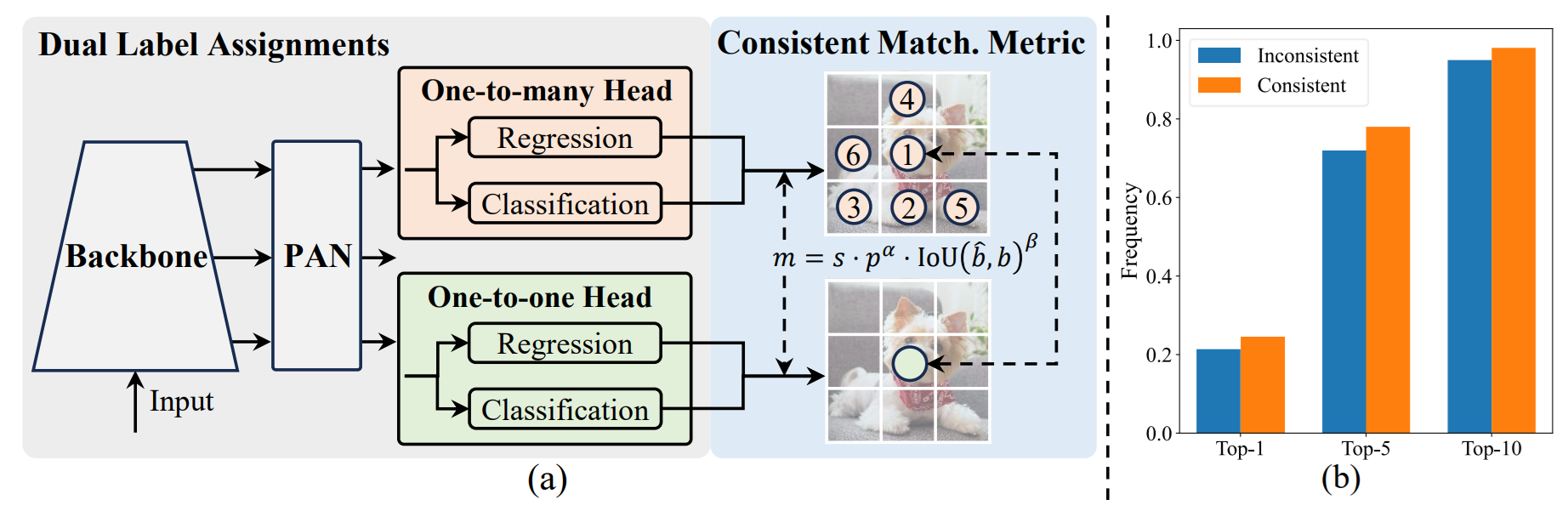
- One-to-many Head
- Lightweight classification head
回帰と分類を比較したとき、性能にとっては回帰が重要となります。そのため、分類ヘッドのオーバーヘッドを性能を損なうことなく減らすことができ、結果として軽量にすることが可能です。
- Spatial-channel decoupled downsampling
計算コストを下げる一方、ダウンサンプリングにおける情報を保持し、レイテンシ削減に寄与します。
- Rank-guided block design
あるモデルのステージについて、最初のステージをcompact inverted block (CIB) に置換し性能を比較します。性能劣化がなければ次のステージの置換を進め、劣化があれば処理を中止します。この手順を繰り返すことで、適切な設計を実装することができ、性能を損なうことなく高効率を達成することができます。
- Large-kernel convolution
受容野を拡大し、モデルの性能を向上させるために効果的な手法です。YOLOv10では、深度方向の畳み込みをCIBの深層ステージで活用します。
モデルサイズが大きい場合は、自然に受容野が拡大するため、小さいモデルに対してLarge-kernel convolutionが採用されています。
- Partial self-attention
様々なコンピュータビジョンタスクに利用されている手法です。YOLOV10では効率的なモジュール設計が提案され、低い計算コストで大域的な表現を組み込むことができます。結果として、モデルの性能改善をもたらします。
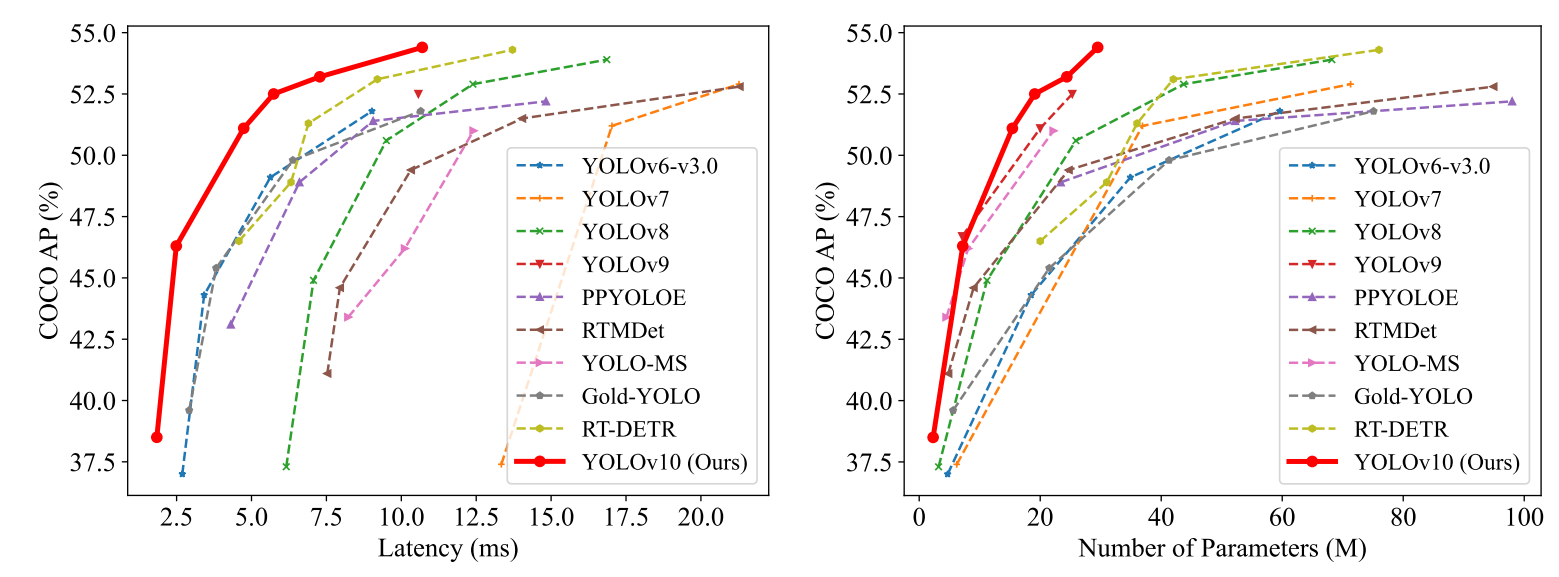
以下の図に、YOLOv10とその他のモデルにおける物体検出の精度および速度を示します。精度および速度ともに他のモデルを上回る結果となっています。
YOLO11
GELANの1種であるC3K2モジュールと軽量なdepthwise separable畳み込みを検出ヘッドに取り入れました。結果としてレイテンシを削減し、正答率を上げています。
YOLO12
Attentionの考え方を取り入れたモデルです。YOLO11まではCNNベースで構成されています。
Attention機構は計算の複雑さやメモリ利用の非効率性により、CNNより遅いといった問題がありました。YOLO12では上記の課題を解決し、より早く正確な画像認識モデルを達成しています。
YOLO12は、以下のような特徴を有しています。
-
領域アテンション機構
ウィンドウ分割を水平または垂直方向に等間隔で行うことにより、受容野を大きくしながら計算コストを削減し速度を向上

-
R-ELAN (Residual Efficient Layer Aggregation Networks)
特徴量の抽出を分割せずに一貫して行うことで計算コストとメモリ量を削減
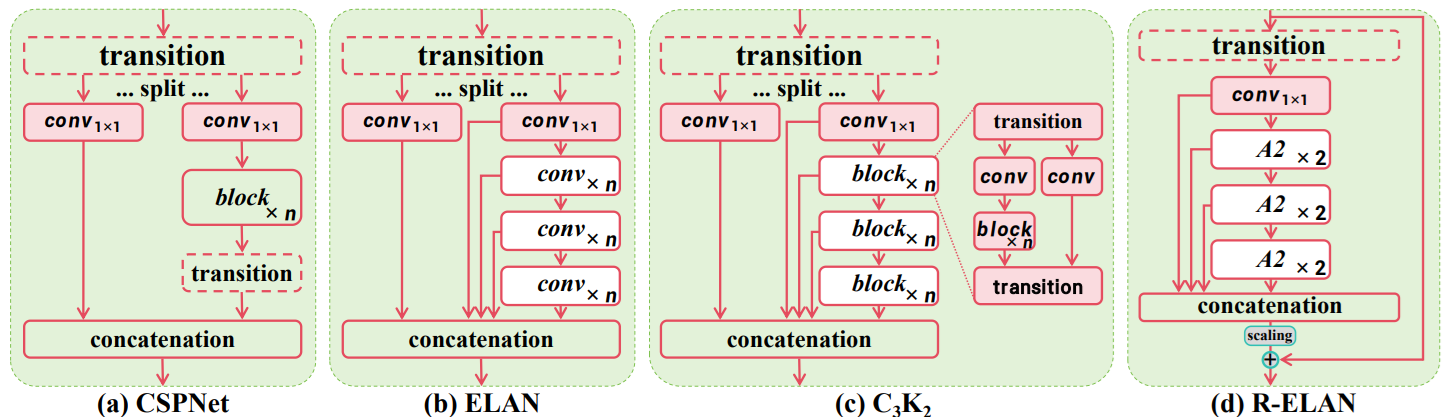
-
改良されたアーキテクチャ
位置エンコーディングを取り除き、分離可能な畳み込みを導入することにより領域アテンションで位置を認識
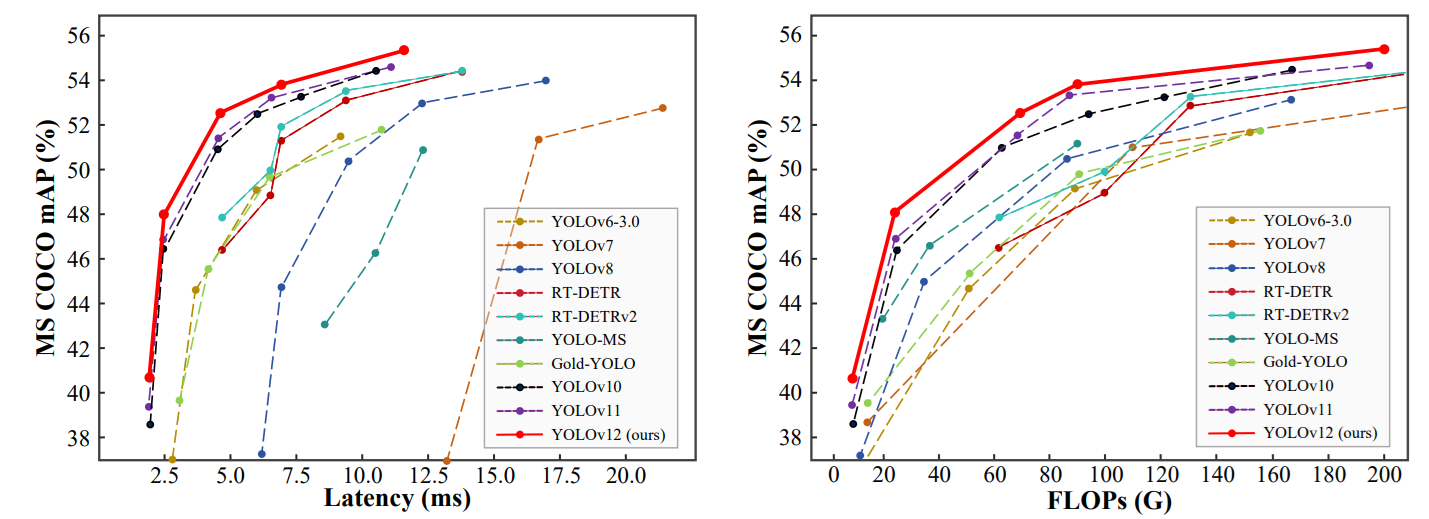
以下の図に、YOLO12とその他のモデルにおける物体検出の精度および速度を示します。他のモデルと比較してより正確で高速なモデルとなっています。
まとめ
今回は、物体検出モデルの1つであるYOLOについてまとめました。最新のモデルにおいて、精度と速度を両立させるために、様々な特徴が加えられていることが分かりました。特にYOLOv7から学習効率を重視して情報損失を抑えるための手法を導入していることが印象的でした。
YOLOのようなリアルタイムの物体検出は、自動運転だけでなく多くの分野で必須の技術となるため、今後もキャッチアップしていきます。
参考
本記事は、以下の記事を参考にして執筆しています。