はじめに
こんにちは。まっちゃ![]() です。
です。
今回は、画像認識モデルのSwin Transformerについて、まとめていきます。
なぜ重要か
画像認識モデルのアーキテクチャは、主流であったCNNからTransformerベースに置き換わりつつあります。本記事では、Transformerベースの画像認識モデルであるSwin Transformerを取り上げ、従来モデルからの改善手法を解説します。
目次
- Transformer
- ViT(Vision Transformer)
- Swin Transformer
- まとめ
- 参考
Transformer
まず、前提知識となるTransformerについて解説します。Transformer以前における自然言語処理などの系列データ処理では、RNN(Recurrent Neural Network)が主に用いられていました。しかしRNNを用いたモデルには、以下に示す問題点がありました。
- 逐次処理であり、並列な実行が不可
メモリ使用量が増加 - 長文における依存関係の学習難易度が高い
入力シーケンスが長い場合、記憶が困難
これらの問題を解決するため、以下の特徴をもつTransformerが提唱されました。
- Attentionのみで構成されたモデル
CNNやRNNを用いられておらず並列処理が可能となり、メモリ使用量を節約 - 長文における依存関係を学習することが可能
長期記憶が可能であり、翻訳タスクにおける精度を向上
ここからTransformerの中身を見ていきます。以下の図に、Transformerのアーキテクチャを示します。論文で示されているモデルは、エンコーダ・デコーダモデルのTransformerです。このモデルにおけるデータの入力から出力までの流れは、以下のようになります。
- 入力した文をベクトル化して位置情報を加算した後、エンコーダに入力(Input Embedding + Positional Encoding)
- 受け取った値に対してAttentionを算出(エンコーダ側のMulti-Head Attenrion)
- エンコーダから出力された値とデコーダにおいて算出された中間の値からAttentionを算出(デコーダ側のMulti-Head Attenrion)
- 出力された値にソフトマックス関数を適用して、最終的な値を出力

以下で、Transformerにおける各処理を解説していきます。
-
Self-Attention
Attentionは、1文における各単語の関連度(注目度)であり、次式を用いて算出されます。
$$\mathrm{Attention}(Q, K, V) = \mathrm{softmax}\Bigl(\frac{QK^T}{\sqrt{d}}\Bigr)V$$
ここでQはクエリ、Kはキー、Vはバリューとなります。検索システムで考えた場合、検索クエリQに一致するKを検索ストアから探索し、Kに対応するVを返す処理に由来します。
式中の$\mathrm{softmax}\Bigl(\frac{QK^T}{\sqrt{d}}\Bigr)$は関連度の重みを表しており、Attentionは関連度に応じてベクトルをまとめる処理となります。この時、次元数の平行根$(\sqrt{d})$で除算する理由は、分散を均すことで勾配消失を削減するためです。
Q, K, Vに同じ情報源を用いた場合のAttentionは、Self-Attentionと呼ばれます。 -
Multi-Head Attention
以下の図に、Multi-Head Attentionの概要図を示します。単一のAttentionのみで算出した場合、関連度の小さいベクトルの影響が無視されます。結果として、作成されるベクトルは重要度に関する特徴が乏しい状態となり、汎用性が低いモデルとなります。そこで、多くの特徴を抽出し汎用性が高いモデルを獲得するため、複数のAttentionを並列実行します。
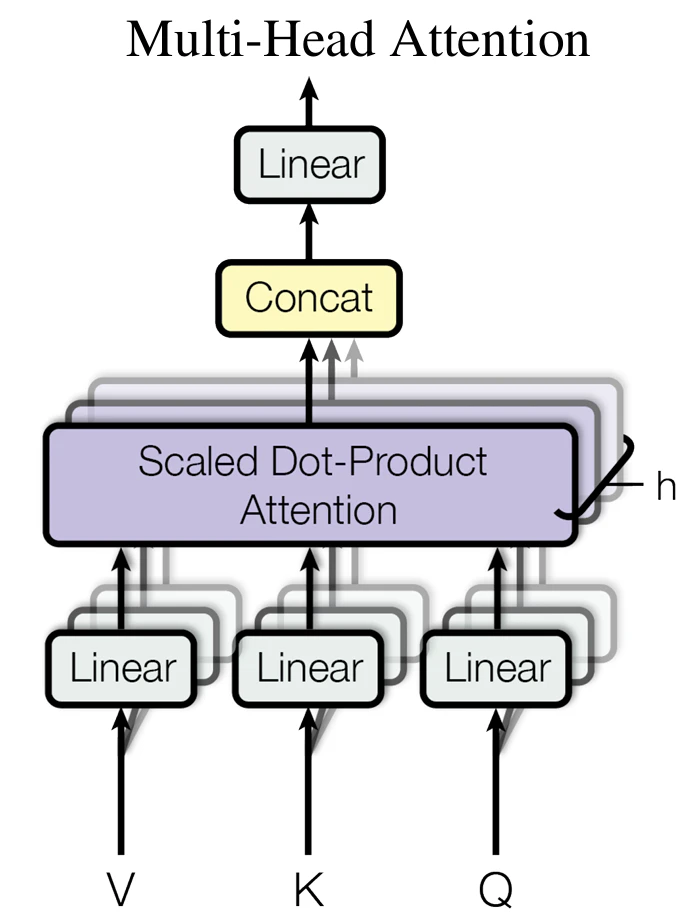
-
Masked Multi-Head Attention
Attentionの計算をそのまま行うと、モデルは予測する単語の情報が分かる状態になります。この状態で学習を行った場合、完璧に翻訳できるものの汎用性がないモデルになります。この状態を避けるため、未来の情報にアクセスしないよう、マスキングを行ったMasked Multi-Head Attentionを計算します。 -
Positional Encoding
Embeddingにおいてベクトル化したデータは位置情報を持たず、そのまま学習した場合には位置の入れ替えに対して不変性がないモデルとなります。そこで、ベクトル化したデータに位置エンコーディングを加算することで、位置の学習を可能にしています。
ViT(Vision Transformer)
続いて、Transformerを用いた画像認識モデルのViTについて解説します。ViTはそれまで主流であったCNNベースの画像認識モデルに対して同等以上の性能を発揮し、注目されました。
以下の図に、ViTのアーキテクチャを示します。ViTは、前述したTransformerのエンコーダ部分を取り出して、入力データを画像に置き換えたモデルとみなすことが出来ます。ViTにおけるデータの入力から出力までの流れは、以下のようになります。
- 画像をパッチに分割後、ベクトル化(Linear Projection of Flattened Patches)
- ベクトルを埋め込み、位置情報を加算してエンコーダに入力(Patch + Position Embedding)
- 受け取った値に対してAttentionを算出(Multi-Head Attenrion)
- 出力された値を全結合層に入力し、分類を実行

以下の図に、モデルが学習した各パッチにおける位置情報の関連度を示します。各パッチについて、それぞれ異なる位置で関連度が高くなっています、また、同じ行、列において類似した箇所の関連度が高い傾向も見られます。

Swin Transformer
最後にSwin Transformerについて解説します。前述したViTは画像認識に関して十分な性能を発揮しましたが、以下に示す問題点がありました。
- 入力シーケンスの長さの2乗に比例して計算コストが増加
大きなサイズの画像や小さなパッチへの適用が困難
上記の問題を解決するため、以下の特徴をもつSwin Transformerが提唱されました。
- Attentionの計算範囲が限定的
- 特徴マップの構造が階層
以下の図に、Swin Transformerのアーキテクチャを示します。このモデルにおけるデータの入力から出力までの流れはViTと同様です。

以下で、Swin Transformerにおける各処理を解説します。
-
Window-Multi-head-Self-Attention(W-MSA)
以下の図に、W-MSAの概要図を示します。ここでは左側のLayer lに着目します。灰色で示されている重なりがないように画像を分割したパッチは、赤枠で示されるウィンドウにより囲まれます。W-MSAではウィンドウ内でのみAttnetionを計算することにより、計算複雑度を線形にしています。結果として、入力シーケンスに対する計算コストを削減しています。

-
Shift-Window-Multi-head-Self-Attention(SW-MSA)
前述したW-MSAではウィンドウ内でのみAttentionの計算を行うため、隣り合うウィンドウ間の情報は無視されます。そこで、上図における右側のLayer l+1のように、ウィンドウの領域をシフトさせたSW-MSAが用いられます。ウィンドウをシフトさせることにより隣り合うウィンドウ間で計算を行うことで、その情報を得ることが可能となります。 -
cyclic shift
以下の図に、SW-MSAの計算で用いられるcyclic shiftの概要図を示します。シフトさせたウィンドウをそのまま計算すると、9個の領域を計算する必要があり、実装が複雑になります。そのため図におけるcyclic shiftのように、もともと上側と左側にある計5個のウィンドウを、A, B, Cの領域に時計回りでシフトさせます。この手法を用いることで、計算する領域がW-SMAと同じになるため、複雑な実装を回避することができます。この時、シフトさせて隣り合った無関係なパッチ間におけるAttentionを計算しないように、マスクを設定します。

-
Patch Merging
以下の図に、Patch Mergingの概要図を示します。Patch Mergingにおいて、特徴マップのサイズを半分にし、チャネル数を2倍にします。Swin Transformerではこのような階層構造を持たせることで、計算領域を小さくしメモリ使用量を削減しています。

まとめ
Transformerの解説から入り、Transformerを用いた画像認識モデルであるViT, さらに改善したSwin Transformerの解説を行いました。CNN, Transformerそれぞれの特徴を生かした画像認識モデルが次々と開発される中で基本的な部分が知りたくなり、本記事を執筆しました。
これからどのようなアーキテクチャを用いたモデルが出てくるかを楽しみにしつつ、各モデルにおける手法の改善も確認していきたいと考えています。
参考
- Transformer
- ViT
- Swin Transformer