トピックモデルとしてよく使われるLDAですが、Rでやる場合いくつかライブラリが存在します。
代表的なのは、以下のようですが、どちらも甲乙つけがたいと思いました。
| library | Author | Organization | Download | Document |
|---|---|---|---|---|
| topicmodels | Bettina Grün,Kurt Hornik | U. Linz, U. Wien | CRAN | Manual |
| lda | Jonathan Chang | google,facebook | CRAN | CRAN |
topicmodel の場合
どちらの場合でも元は文に分割されたテキストから始めます。文を切るのは自明ではありませんので、タグがある場合などは一工夫必要です。
doc.list <- read()
準備
topicmodelの場合は、tmというライブラリを使って、Corpusというtermベクタに分割されたコーパス形式に一度変換後、doc-term行列にします。特別なクラスが用意されているので、途中触るのは結構難しいです。
library(tm)
doc.corpus <- Corpus(VectorSource(unlist(doc.list)))
doc.dtm <- DocumentTermMatrix(doc.corpus, control = list(removeNumber = FALSE, minWordLength = 1))
モデル構築
これは特に工夫は必要ありません、基本的にはk-meansのようにトピック数(preferable)を指定するだけです。
Variational EMアルゴリズムもしくはギブスサンプラによりモデル推定が行われます。
library(topicmodels)
doc.model <- LDA(doc.dtm, k);
ldaの場合
こちらも、使い方に戸惑うことはありません。## 準備
こちらは、corpusとして直接変換可能です。
library(lda)
doc.corpus2 <- lexicalize(doc.texts, lower = TRUE)
ldaライブラリでは、ギブスサンプラによる推定クラスに、先ほどのコーパスオブジェクトの中の、ドキュメントそのものと、ボキャブラリーというプロパティがありますので、それを指定します。
パラメータ推定が行われ、モデルが生成されます。
また、ldaライブラリでは、Networks Uncovered By Bayesian Inference (NUBBI)やRelational Topic Models(RTM)のパラメータ推定についても実装されています。
doc.model2 <- lda.collapsed.gibbs.sampler(doc.corpus2$documents,
k,
doc.corpus2$vocab,
25, # iterations
0.1, # α
0.1, # η
compute.log.likelihood = TRUE)
モデルの可視化
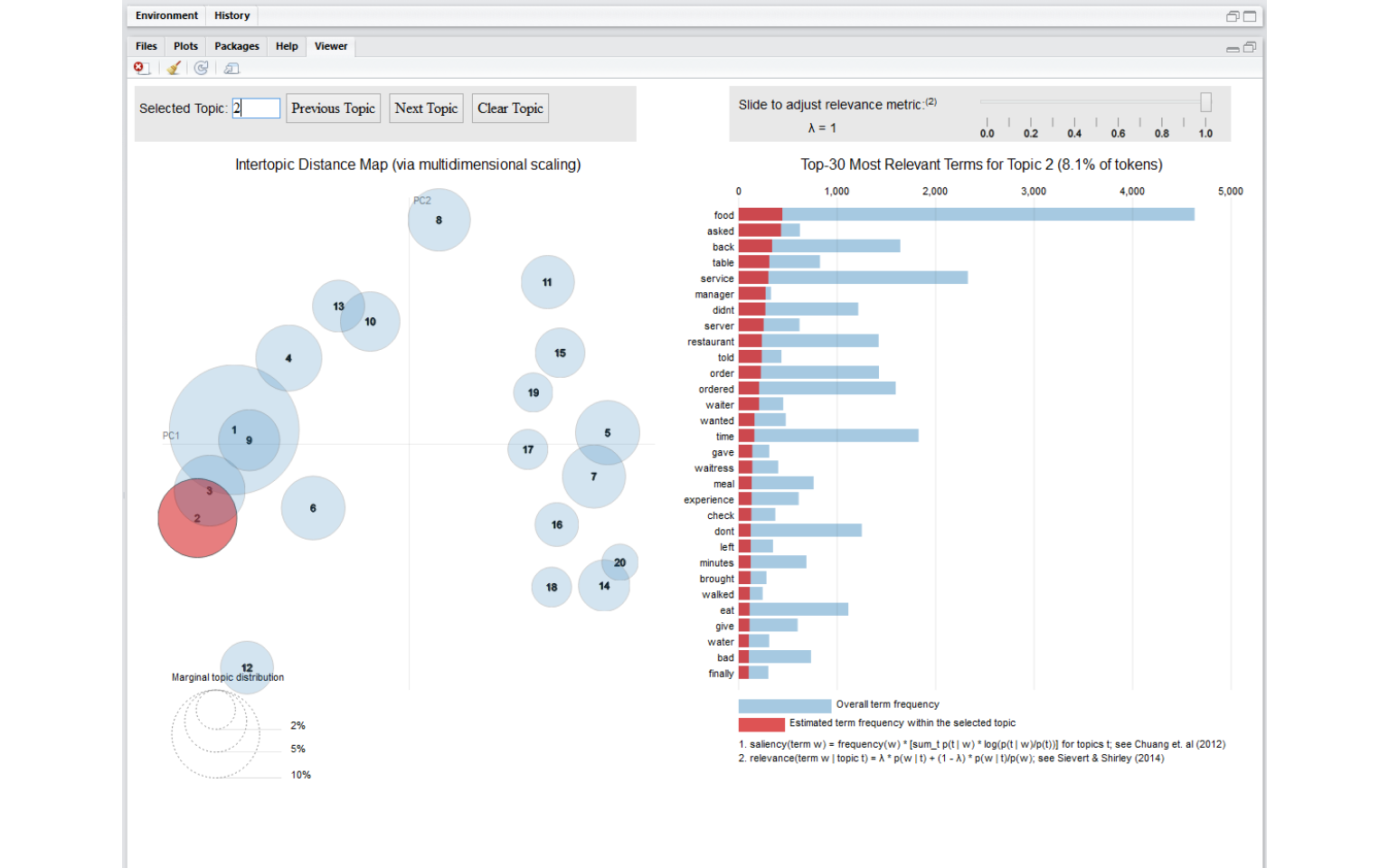
できたモデルは、各トピックの構成単語などを見ることができますが、モデルを理解、再定義する際の、より分かりやすい方法としてLDAvisという可視化ライブラリがあります。
library(LDAvis)
これを使うと、トピック間の関連度をもとに、PCAで2次元マッピングし、さらにインタラクティブに各トピックの構成単語を見ることができます。

こちらは、ldaライブラリの出力をベースに利用されることが多いのですが、基本的にはLDAそのものというよりも、ソフトクラスタリングの結果を表示するものと考えればよいので、トピックのパラメータさえ渡せば、どんなモデル出力でも翻訳できそうなのでやってみました。
json <- createJSON(
phi = phi,
theta = theta,
doc.length = doc.length,
vocab = vocab,
term.frequency = term.frequency
)
serVis(json, out.dir = 'vis',
open.browser = FALSE)
こちらが、ラップした関数です。どちらのモデルもfitという変数で受け取ります。ただ、スイッチする部分は書いていないので、buildVisdataの番号を切り替えます。
VisualizeModel <- function(corpus, fit, doc_term,dir) {
params <- buildVisdata1(corpus, fit, doc_term)
#params <- buildVisdata2(corpus, fit)
json <- createJSON(phi = params$phi,
theta = params$theta,
doc.length = params$doc.length,
vocab = params$vocab,
term.frequency = params$term.frequency)
serVis(json, out.dir = dir, open.browser = TRUE)
}
JSONを作って、serVisという関数で、shinnyアプリに送ります。
paramsという変数に必要なパラメータをまとめています。
必要なのは、phi、thetaというパラメータですそれぞれ、単語の構成比率(周辺確率)と、トピックの構成比率です。
topicmodelの場合にも、必要なパラメータはモデルのプロパティからそのまま得られるものが多いので、比較的簡単です。一部文書サイズを逆算するのがモデルデータからだと難しいので、そこだけロジックが必要でした。別途テキストデータがあれば特に必要ない。
buildVisdata1 <- function(corpus, fit, doc_term) {
phi <- posterior(fit)$terms %>% as.matrix
theta <- posterior(fit)$topics %>% as.matrix
vocab <- colnames(phi)
doc_length <- vector()
for (i in 1:length(corpus)) {
temp <- paste(corpus[[i]]$content, collapse = ' ')
doc_length <- c(doc_length, stri_count(temp, regex = '\\S+'))
}
term.frequency <- colSums(as.matrix(doc_term))
params <- list(phi = phi,
theta = theta,
doc.length = doc_length,
vocab = vocab,
term.frequency = term.frequency)
return(params)
}
LDAでは、例がたくさんあるので、そのままです。以下の例では、スムージングなどをしていますが、特筆するべきところはないですね。
buildVisdata2 <- function(corpus, fit) {
term.table <- table(do.call(cbind, corpus$documents))
names(term.table) <- corpus$vocab
D <- ncol(fit$document_sum)
W <- ncol(fit$topics)
doc.length <- sapply(corpus$documents, function(x) sum(x[2,]))
N <- sum(doc.length)
term.frequency <- as.integer(term.table)
alpha <- 0.02
eta <- 0.02
theta <- t(apply(fit$document_sums + alpha, 2, function(x) x / sum(x)))
phi <- t(apply(t(fit$topics) + eta, 2, function(x) x / sum(x)))
params <- list(phi = phi,
theta = theta,
doc.length = doc.length,
vocab = corpus$vocab,
term.frequency = term.frequency)
return(params)
}
上記のように変換すれば、topicmodelでもldaでも結果が表示できます。