ETLツールはあまり使わないのですが、Talendのエントリ製品である、データプレパレーションはユニークな使い方を提供するので、紹介します。
導入が的をついています。
「IT部門は営業部門から寄せられるデータへの要件を満たすことに忙殺され、データアナリストは労働時間の8割をデータクリーニングに費やしています。」
ふむふむ。同感。
「Talendのデータプレパレーション製品は、これらの課題に対処するために、直感的なセルフサービス型データプレパレーションとデータ統合を組み合わせています。」
おお!で、何ができるの?
データの準備とかクレンジングといっても、データ型マッチング、文字列変換、外れ値除去、スムージング様々で、そのほか定型化できそうもないものが沢山あるのですが、どの辺に刺さる製品なのでしょうか?
Talend Data Preparationの入手、インストール
以下のページからダウンロードします。無償版があり、気軽に導入できます。
Talend Data Preparation Desktop
インストールすると、こんなアイコンができるので、これを起動すればOKです。

実はこのソフトウェアはWebベースになりますので、以下のようにブラウザが起動します。
以下のようにローカルホストを使って起動しますので、特にWebサーバーなどの準備は必要ありません。

今後はこのような形態のBIツールが増えるんでしょうね。
Talend Data Preparationの起動
起動すると以下のようなデータセットを選択する画面になります。
Preparationsというのはすでに処理済みのプロジェクトのようです。

CRM Phone Numbersというプロジェクトを開いてみましょう。これは単なる電話帳リストです。

左側のペインから、
- recipe (クリーニングの処理がリストになっているもの)
- データセットの表
- 属性ビュアー
となっているようです。
recipeペイン
Power BIのクエリーエディタのようにステップバイステップでレシピを構築していきます。
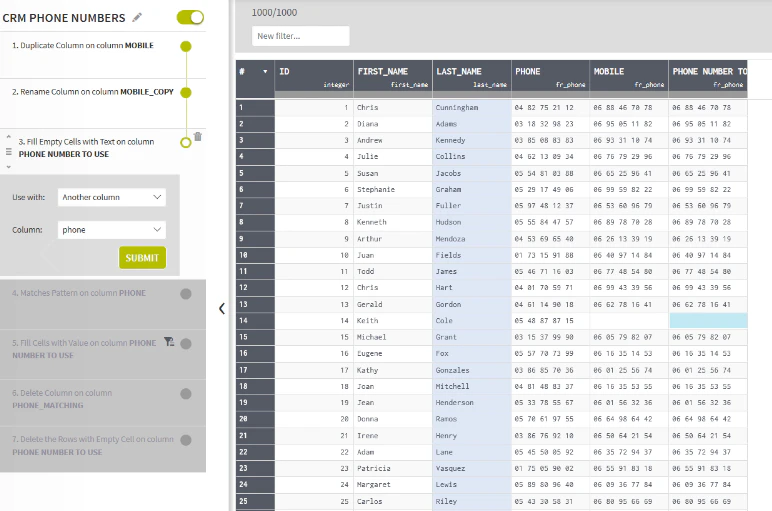
デフォルトで入っているレシピの途中の行まで戻ると、そこまでの処理が実行された結果が表に現れます。
ここでは3番目のステップで"Fill empty Cells with Test on column"という処理を行っていますが、最終列に追加されたPHONE NUMBER TO USEの空行に、PHONEという列の値を補完するという処理になります。
対象となる空セルがハイライトされており、非常に直感的に確認しながらステップを追加できます。
表ペイン
こちらは通常のデータテーブルのような使い方ができます。セル、行や列を選択してそれぞれの特徴を右の属性ビュアーで確認できます。ここでは列ごとにその特徴を見てみましょう。
属性ビュアーペイン
まずIDを見てみましょう。これはシーケンシャルなIDで、生データでは1~1000までの連番が入っていましたが、クレンジング時に1行消されています。
VALUEタブで見てみると以下のように総数が999となっていることで確認できます。

CHARTタブで見ると、以下のように抜けているIDがどのあたりにあるかがわかります。

PATTERNタブでみると、以下のように何桁の数値がどれだけ存在するかがグループ集計されて出ます。

最後のADVANCEDでは、以下のように統計的なビューが用意されています。メディアンやクオンタイル値を見ることが可能です。

このID列では、抜け値以外はあまり有意義な分析とは言えないですが、他の列を使うとこの機能が強力なものであることがわかります。
FIRST列でCHART : Justinという名前が最も多いことがわかります。

FIRST列でPATTERN : 名前はすべて大文字から始まっていることと、5文字の名前が最も多いことがわかります。最低3文字、最高11文字ということもわかります。この時11文字はChristopherさんであることもこのバーチャートを選択することですぐにわかります。

PHONE列でPATTERN : すべて同じフォーマットでいくつかの空行があることがわかります。

このような集計はなかなか通常の処理ではできないので、生データをどのような方針でETLをしていくかの指針になります。
フォーマットの乱れ、外れ値や文字化けなどをつぶさに見つけるには非常に強力な武器になるでしょう。
以下のようなワークフローがヘルプにありましたが、このようにETLの初期段階からデプロイ、Hadoopクラスタでの実行などライフサイクルにわたって適用できるのはさすがTalendという感じですね。
