各所でベンチマークをされていて、data.tableは速いということはわかっているのですが、ベーシックな処理でも違いは出るのでしょうか?昨日の試みのついでにやってみました。
データ構造による違い
data.frame(df)
普通にデータフレームで行選択します。
df <- data.frame(idx = 1:n1, v = runif(n1))
for (i in 1:n2) {
a <- df[df$v < 0.5,]
}
data.frame with dplyr(dfdplyr)
dplyrでデータフレームの行選択します。
df <- data.frame(idx = 1:n1, v = runif(n1))
for (i in 1:n2) {
a <- df %>% filter(v < 0.5)
}
data.table(dt,dtk)
データテーブルで行選択します。setkeyありなしを試しました。
dt <- data.table(idx = 1:n1, v = runif(n1))
if (key) {
setkey(dt, idx)
}
for (i in 1:n2) {
a <- dt[v < 0.5,]
}
data.table with dplyr (dtdplyr,dtdplyrk)
dplyrでデータテーブルの行選択します。
dt <- data.table(idx = 1:n1, v = runif(n1))
if (key) {
setkey(dt, idx)
}
for (i in 1:n2) {
a <- dt %>% filter(v < 0.5)
}
ベンチマーク
元データ数(n1) 100万-1000万(変化させる)
選択回数(n2) 100
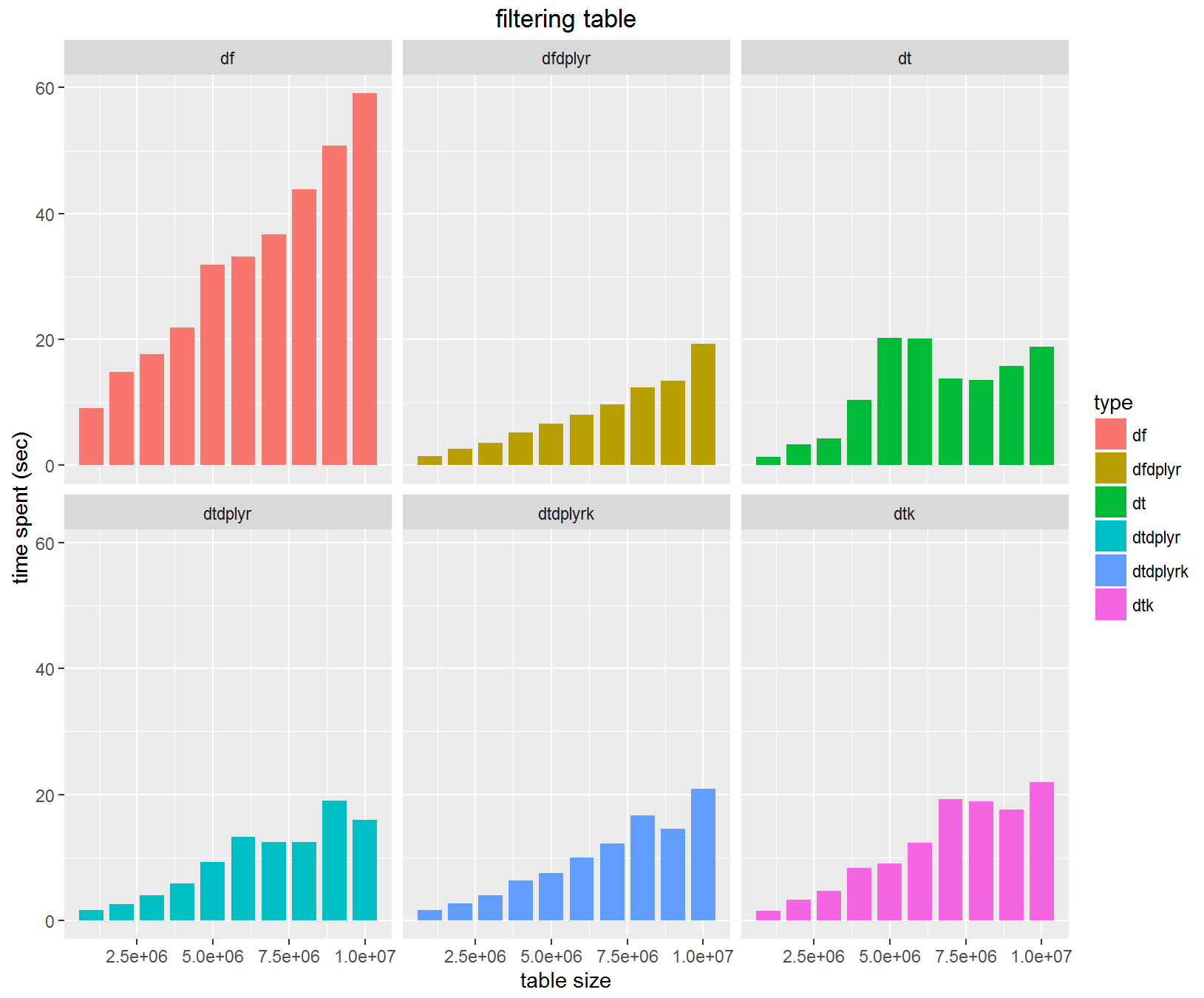
data.tableが速いという結果は確かなのですが、dplyrを使えばdata.frameでもそん色ないスピードが出るということがわかりました。
filter等の単純な処理ではdata.tableの効果は限定的でgroupbyやaggregateなどを行った場合に真価が発揮されるということですね。
フィルタ条件の記法による違い
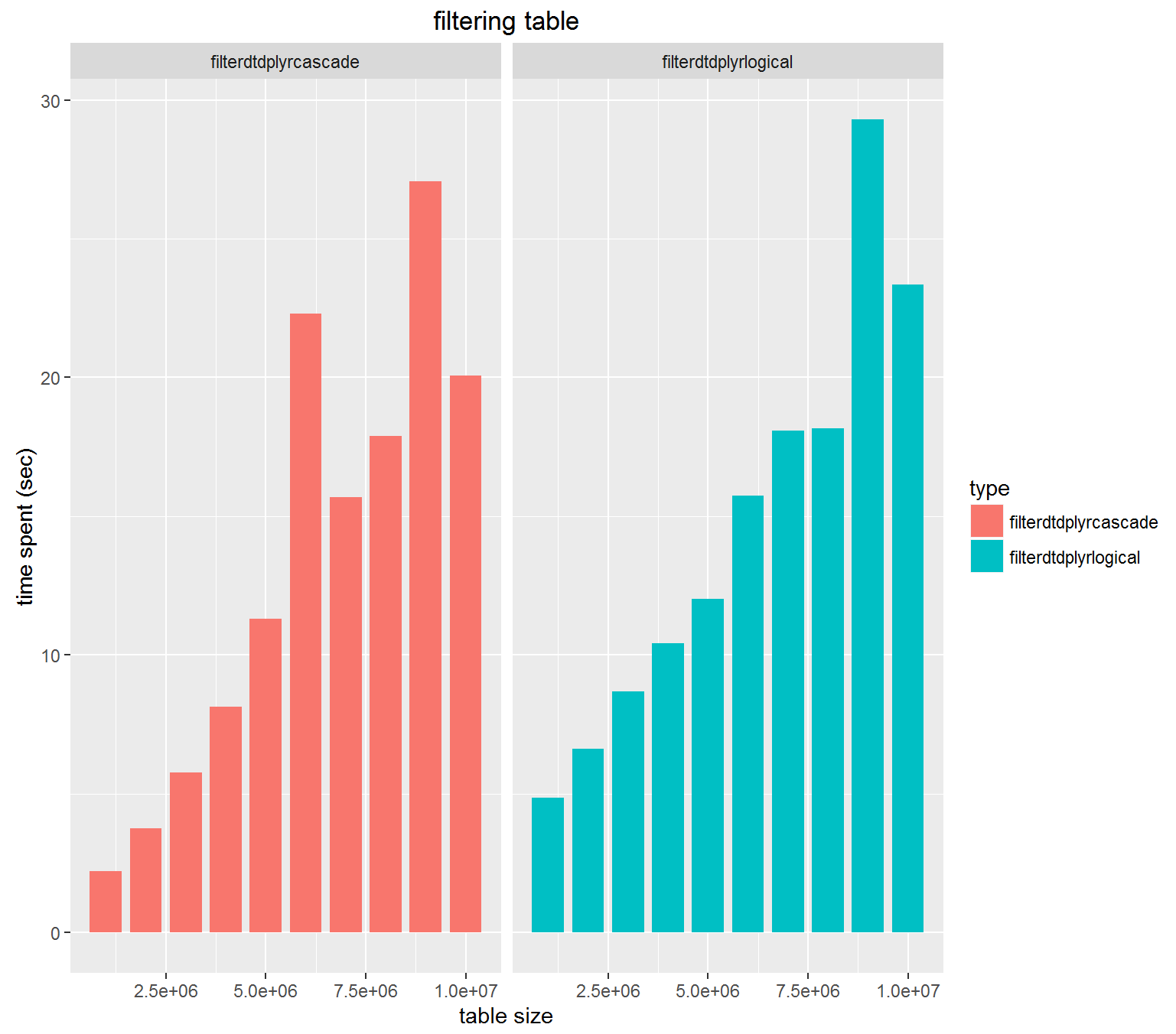
少し気になっていたことですが、filterを書く際に2つ以上の条件を一つのverbで書いたほうが良いのか、別々にverbをカスケードして使ったほうが良いのかどちらが速度的に有利なのでしょうか?
一度にやる方法(logical)
dt <- data.table(idx = 1:n1, v = runif(n1))
for (i in 1:n2) {
a <- dt %>% filter(v < 0.6 & v > 0.4)
}
分けて順次やる方法(cascade)
dt <- data.table(idx = 1:n1, v = runif(n1))
for (i in 1:n2) {
a <- dt %>% filter(v < 0.6) %>% filter(v > 0.4)
}
ベンチマーク
どちらも大差ないという結果になりました。おそらく内部的には同じコードに変換されているのではないでしょうか?