Rでデータフレーム同士の相互インデックスを張ろうと思い、複数のレコードに値を入れる方法を探っています。1000万件程度のデータフレームにインデックスを指定して一括セットしようとすると、なかなか思うようなパフォーマンスが出ません。
data.frameやdata.tableで試しましたが、具体的には、1000万レコードのデータフレームに1件100レコードごとの要素代入を数万回程度行う処理です。
いろいろなやり方が考えられますが、やはりdata.tableが一番早いようです。また記法による違いに気づかず、最速の方法を見逃していました。
ベンチマークをしてみたので参考までに掲載しておきます。
データ構造
data.frame(df)
普通にデータフレームに代入します。
df <- data.frame(idx = 1:n1, oidx = numeric(n1))
for (i in 1:n2) {
df[floor(runif(n3, 1, n1)),]$oidx <- i
}
data.table(dt)
データテーブルにデータフレームと同様の代入方法を行います。
dt <- data.table(idx = 1:n1, oidx = numeric(n1))
for (i in 1:n2) {
dt[floor(runif(n3, 1, n1)),]$oidx <- i
}
data.table with setkey (dtk)
データテーブルでキーを設定します。
dt <- data.table(idx = 1:n1, oidx = numeric(n1))
setkey(dt,idx)
for (i in 1:n2) {
dt[floor(runif(n3, 1, n1)),]$oidx <- i
}
data.table with ":=" (dt2)
data.tableでは := という演算子で代入を行うことができます。最初は記法の違いだけだと思っていましたが、大違いでした。
dt <- data.table(idx = 1:n1, oidx = numeric(n1))
for (i in 1:n2) {
dt[floor(runif(n3, 1, n1)), oidx := i]
}
data.table with ":=" and setkey (dtk2)
さらにsetkeyも組み合わせます。
dt <- data.table(idx = 1:n1, oidx = numeric(n1))
setkey(dt, idx)
for (i in 1:n2) {
dt[floor(runif(n3, 1, n1)), oidx := i]
}
list (list)
一度listとして抽出して代入する。
dt <- data.table(idx = 1:n1, oidx = numeric(n1))
l <- dt$oidx
for (i in 1:n2) {
l[floor(runif(n3, 1, n1))] <- i
}
dt$oidx <- l
vector (vector)
一度vectorとして抽出して代入する。
dt <- data.table(idx = 1:n1, oidx = numeric(n1))
v <- unlist(dt$oidx)
for (i in 1:n2) {
v[floor(runif(n3, 1, n1))] <- i
}
dt$oidx <- v
ベンチマーク1
代入先データ数(n1) 100万-1000万(変化させる)
代入回数(n2) 100
代入データ数(n3) 100
以下のように、data.frameの記法を使うと異様に遅くなることに気づきました。data.tableでも同じでした。おおよそ100倍以上のスピードの差があります。
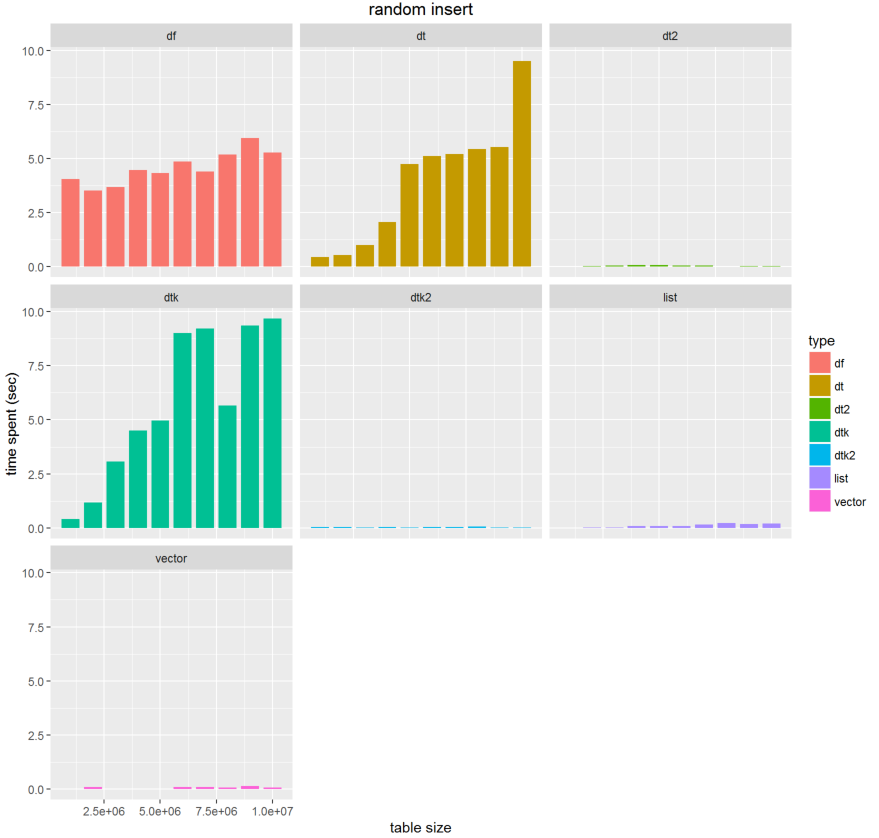
":="記法によるものが最も効果が高いように見えます。この数ですと、list,vectorにして外部で処理してもほとんど変化ないようなので、転送の手間を考えると":="を使うのが最もよさそうです。
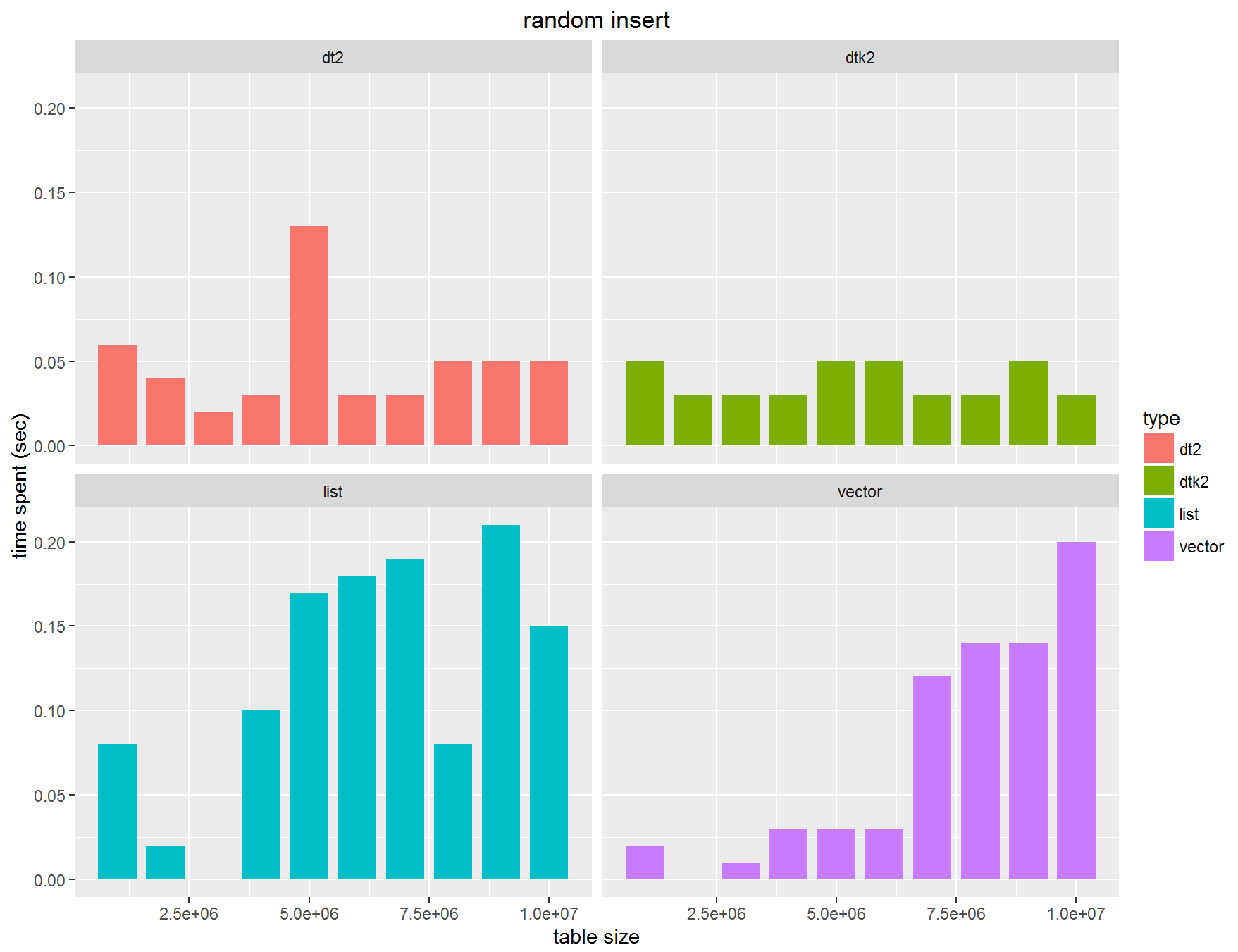
ベンチマーク2
代入先データ数(n1) 100万-1000万(変化させる)
代入回数(n2) 10000
代入データ数(n3) 100
代入回数をもう少し増やしました。1万回というのが現在行っているスペックに近いのでやってみます。何と先ほどとは大きく異なり、listやvectorで扱うほうがやはり速いとなりました。また100倍近い差が付きました。最初から考えると1万倍ですか。。。
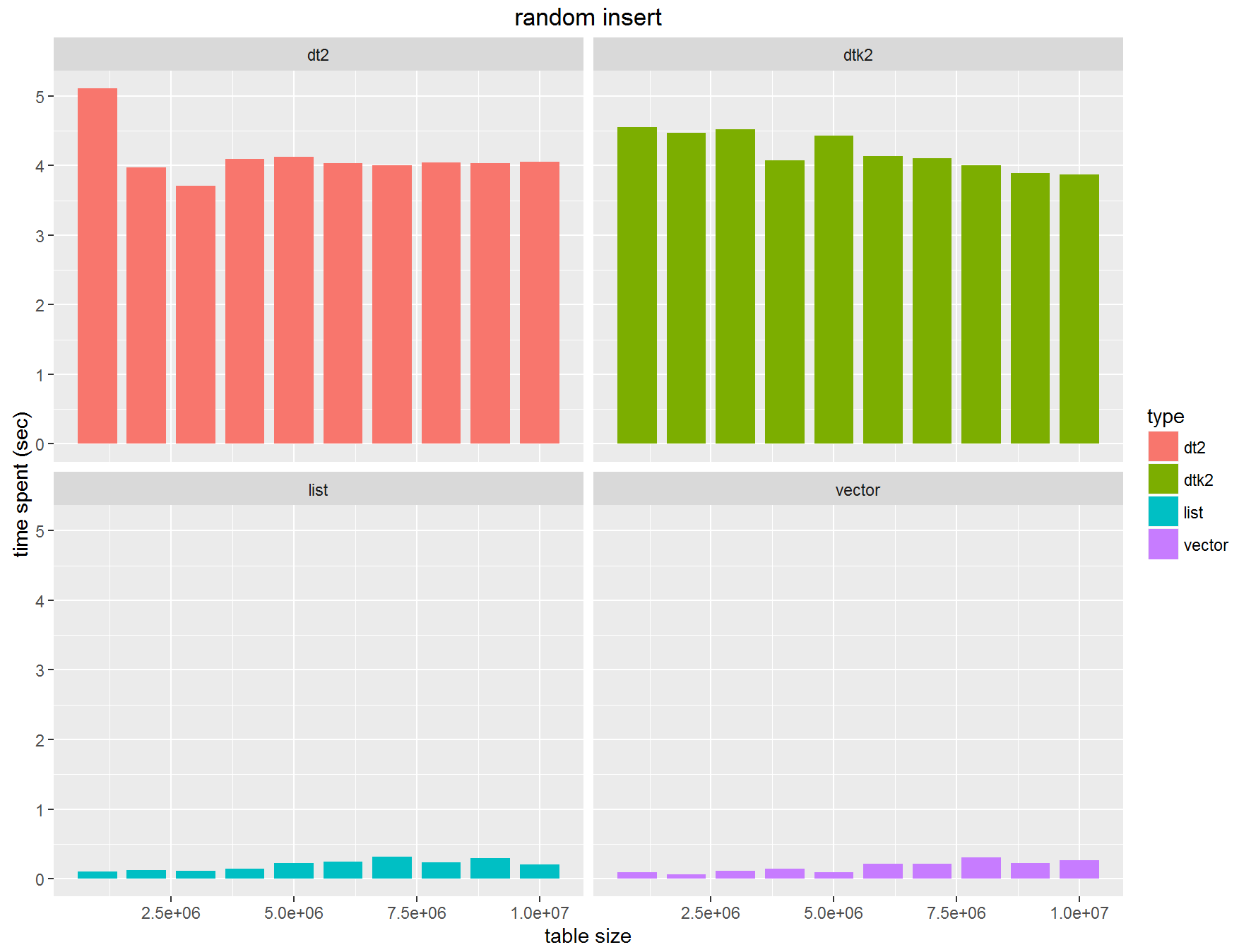
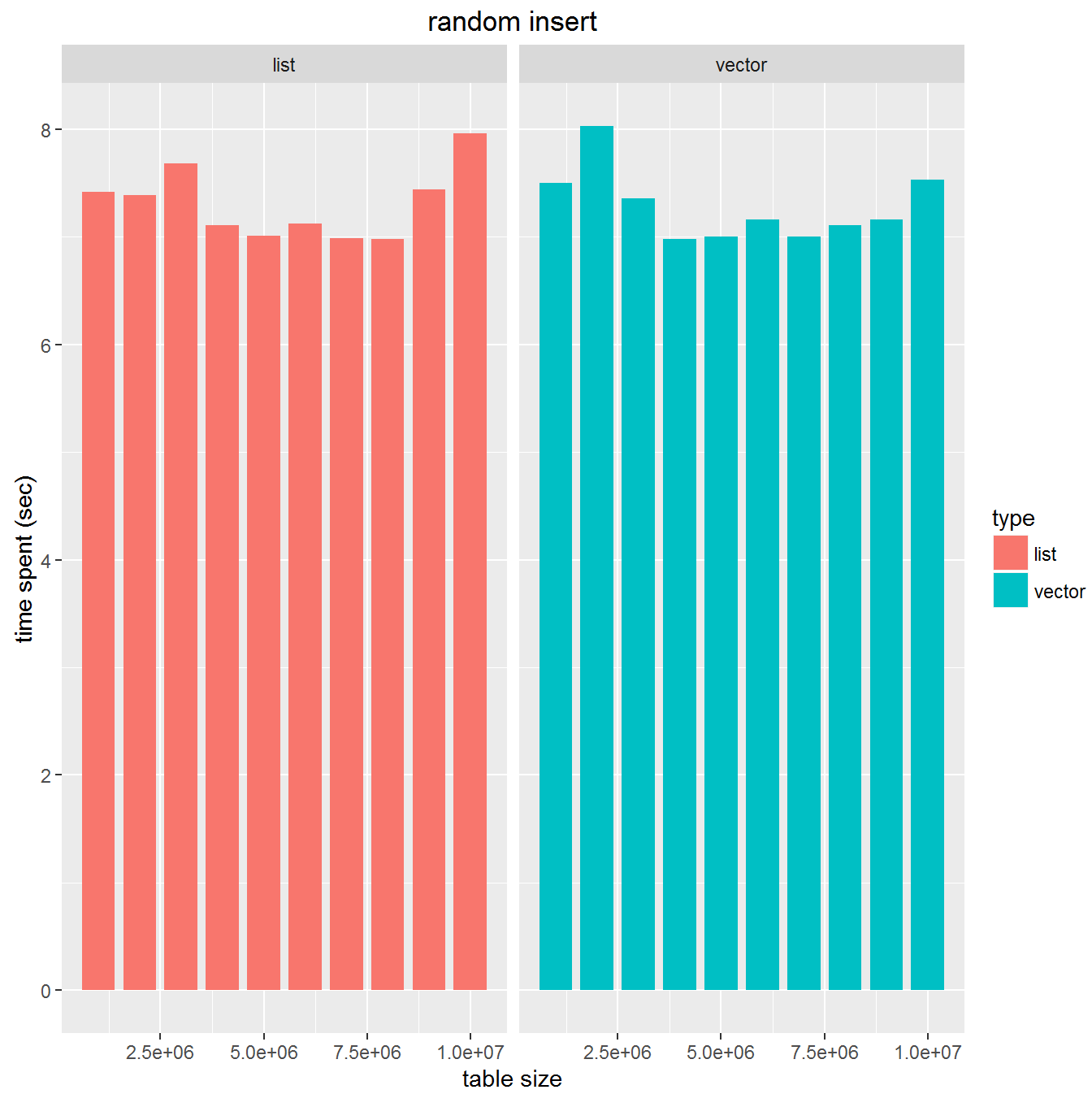
ベンチマーク3
代入先データ数(n1) 100万-1000万(変化させる)
代入回数(n2) 100000
代入データ数(n3) 1000
unlist する意味は本当にないのでしょうか?n2,n3をそれぞれ10倍しましたが、両者の違いは見られませんでした。
まとめ
相互インデックスを効率よくセットするにはdata.tableのカラムをlistとして扱い代入すると一番速い。ということでしょうか?
まさか1万倍以上の差が出るとは思いませんでした。。。