MXNetって何?
ディープラーニング界隈では古参ながら、最近話題急上昇になっている MXNet を使ってみました。
Rから使える、唯一のメジャーなディープラーニングフレームワークとして認知されており、Rユーザーにとっては貴重な存在です。ディープラーニングをRのワークベンチから呼び出したい場合にはほぼ一択という状況ですね。CMUで開発されていましたが、大学由来のライブラリにしては、対応ハードウェア(CPU&GPU)、対応言語(C++, Python, R, Scala, Julia, Matlab,Javascript)が豊富で、ライブラリの安定感も申し分無いイメージですので、AWSで採用されたのもよくわかります。
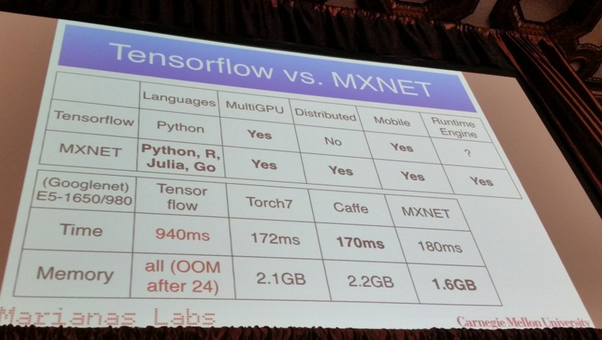
以下のように、Tensor Flowよりも効率がよく、対応言語も多いため、応用範囲が広そうです。
R&MXNet
Rへの導入は比較的容易です。公式サイトからPrebuildパッケージをダウンロードしていくつかのコマンドを実行すればOKです。
MXNetがインストールされれば、Rの場合はいつものインストールコマンド+αで接続完了です。
install.packages("drat", repos="https://cran.rstudio.com")
drat:::addRepo("dmlc")
install.packages("mxnet")
また、RからMXNetのリビルドなども行えるため、Rセントリックな環境でいろいろ試せて便利そうです。
RのMXNetでCNNで画像認識
色々できますが、とりあえずディープラーニングの効果が見えやすい、画像認識にトライしてみました。
画像認識はそれほどやったことが無いため、見当違いなことをやっていると思いますが、使い方を覚えるにはとっつきやすいです。
MXNetでは他のフレームワーク同様、DBN,CNN、RNNを構成でき、マルチプロセッサ、クラスタ、GPGPUの広範なサポートがある非常にバーサタイルな環境です。
CNNのサンプルも豊富にありましたので、初心者でも比較的とっつきやすいのではないでしょうか?
参考にしたリンク集です:
- Tutorials - MXNet official お約束のMNISTサンプルやNLP系のチュートリアルもあり、Pythonよりは削られているものの、必要十分です。
- Deep Learning with MXNetR - DMLC Rでの基本的なデータ処理、MXNetでの学習、予測のフローが簡潔なプログラムで記述されており大変参考になりました。
- Image recognition tutorial in R using deep convolutional neural networks (MXNet package) - The Beginner Programmer より実践的に画像の取り込み~識別までのコードが記されています。ほぼこれで最小限のワークフローは構築可能です。
画像の下ごしらえ
よくある(特にCaltechデータセットのような)フォルダでラベル付けされた画像データセットから始めたかったのですが、定評のある変換ライブラリみたいなものは見つかりませんでした。TensorFlow、Caffe、Chainer、CNTKなどのチュートリアルを探しましたが、画像集から必要なファイル/ラベル記述の構成を得るプログラムはなさそうでした。
それに近いものを作ってみました。
以下は、画像フォルダとラベルを指定して、そのリストをdataframeで得る関数です。画像のロード時にリサイズしています。今回はカラー画像でやりたかったので、カラー対応としました。
imageToDataset <- function(basedir, save_to,label, isGray) {
imagefiles <- list.files(basedir)
w <- 30
h <- 30
img_size <- w*h
df <- data.frame()
for (i in 1:length(imagefiles)) {
result <- tryCatch({
imgname <- imagefiles[i]
img <- readImage(paste0(basedir,"/",imgname))
img_resized <- resize(img, w = w, h = h)
if (isGray) {
img_resized <- channel(img_resized,"gray")
}
img_matrix <- img@.Data
img_vector <- as.vector(array(img_matrix,dim=c(1,w*h*3)))
vec <- c(label, img_vector)
df <- rbind(df, vec)
},
error = function(e) { print(e) })
}
names(df) <- c("label", paste0("pixel", c(1:img_size)))
write.csv(df, save_to, row.names = FALSE)
return(df)
}
この関数を使ってデータセットを作りますが、MXNet独自の書式にのっとって作るのは上記リンクを参考にして、以下のようになりました。ランダムサンプリングをして二つに割っているだけですので、マルチクラスにはすぐ対応できませんが。
buildDataset <- function() {
df0 <- imageToDataset("directoryF", "./satds0.csv", 0,FALSE)
df1 <- imageToDataset("directoryT", "./satds1.csv", 1,FALSE)
new <- rbind(df0, df1)
shuffled <- new[sample(1:nrow(new)),]
half <- nrow(new) %/% 2
train <- shuffled[1:half,]
test <- shuffled[(half + 1):nrow(new),]
write.csv(train, "./train.csv", row.names = FALSE)
write.csv(test, "./test.csv", row.names = FALSE)
}
学習
そして、このデータセットから学習させます。CNNのサンプルほぼそのままです。パラメータ設計は難易度高く、ぼちぼちやっていきたいと思います。
trainCNN <- function(train.x,train.y,dim,channels) {
train_array <- train.x
dim(train_array) <- c(dim, dim, channels, ncol(train.x))
# Model
data <- mx.symbol.Variable('data')
# 1st convolutional layer 5x5 kernel and 20 filters.
conv_1 <- mx.symbol.Convolution(data= data, kernel = c(5,5), num_filter = 20)
tanh_1 <- mx.symbol.Activation(data= conv_1, act_type = "tanh")
pool_1 <- mx.symbol.Pooling(data = tanh_1, pool_type = "max", kernel = c(2,2), stride = c(2,2))
# 2nd convolutional layer 5x5 kernel and 50 filters.
conv_2 <- mx.symbol.Convolution(data = pool_1, kernel = c(5,5), num_filter = 50)
tanh_2 <- mx.symbol.Activation(data = conv_2, act_type = "tanh")
pool_2 <- mx.symbol.Pooling(data = tanh_2, pool_type = "max", kernel = c(2,2), stride = c(2,2))
# 1st fully connected layer
flat <- mx.symbol.Flatten(data = pool_2)
fcl_1 <- mx.symbol.FullyConnected(data = flat, num_hidden = 500)
tanh_3 <- mx.symbol.Activation(data = fcl_1, act_type = "tanh")
# 2nd fully connected layer
fcl_2 <- mx.symbol.FullyConnected(data = tanh_3, num_hidden = 2)
# Output
model <- mx.symbol.SoftmaxOutput(data = fcl_2)
# Set seed for reproducibility
mx.set.seed(100)
# Device used. Sadly not the GPU :-(
device <- mx.cpu()
# Train on 1200 samples
model <- mx.model.FeedForward.create(model, X = train_array, y = train.y,
ctx = device,
num.round = 30,
array.batch.size = 100,
learning.rate = 0.05,
momentum = 0.9,
wd = 0.00001,
eval.metric = mx.metric.accuracy,
epoch.end.callback = mx.callback.log.train.metric(100))
return(model)
}
評価
これらをつなぎ合わせて評価するコードですが、これもサンプルほぼそのままです。
カラー対応でchannelとかで切り返していますが、この辺は他のフレームワークでも一緒かと思います。
train <- read.csv('./train.csv', header = TRUE)
test <- read.csv('./test.csv', header = TRUE)
train <- data.matrix(train)
test <- data.matrix(test)
train.x <- t(train[,-1])
train.y <- train[,1]
test.x <- t(test[,-1])
test.y <- test[,1]
dim <- 30
channels <- 3
test_array <- test.x
dim(test_array) <- c(dim,dim,channels,ncol(test.x))
model <- trainCNN(train.x,train.y,dim,channels)
DrawNetwork(model)
preds <- predict(model, test_array)
dim(preds)
pred.label <- max.col(t(preds)) - 1
table(pred.label)
confusion_matrix <- table(test.y,pred.label)
print(confusion_matrix)
prec <- sum(diag(confusion_matrix)) / sum(confusion_matrix)
print(prec)
実験
地理的なデータをよく扱いますので、それに関連した実験をしてみました。ある緯度経度データがありまして、その緯度経度周辺の衛星画像と、それ以外の画像を学習させる単純なものです。
例えば、陸地と水面、農地や森林など土地利用区分などをタグとして衛星画像を引っ張ってくれば、緯度経度のデータだけで、簡単に学習用のデータが作れます。今回はgoogle mapsから衛星画像をとってきました。この辺もRなら定評のあるライブラリがあるのですぐです。
以下はあるタグを使った衛星画像パッチです。正例としては非常に雑多なイメージを受けます。ほとんど成功する可能性はないと思っていました、必然的に負例の方はさらにバリエーションが増えて、こんなおおざっぱな2値識別問題は簡単なようで、難しいのではないかと想像できます。
-
正例

-
負例

衛星画像をディープラーニングで識別する場合多くは多スペクトラム画像(IR帯なども使う)を使うものがほとんどで、形状というよりも色や輝度そのものを使う場合が多そうですので、今回のような趣旨にはgoogle の衛星画像じゃだめなんじゃないかと思いつつも、高解像度の多スペクトラム画像なんて世の中に存在しないか、高額になるだろうと容易に想像つくため、あきらめました。
結果
Start training with 1 devices
[1] Train-accuracy=0.517631578947368
[2] Train-accuracy=0.51974358974359
[3] Train-accuracy=0.51974358974359
[4] Train-accuracy=0.51974358974359
[5] Train-accuracy=0.51974358974359
[6] Train-accuracy=0.534102564102564
[7] Train-accuracy=0.623846153846154
[8] Train-accuracy=0.58
[9] Train-accuracy=0.595128205128205
[10] Train-accuracy=0.527948717948718
[11] Train-accuracy=0.574871794871795
[12] Train-accuracy=0.703846153846154
[13] Train-accuracy=0.783589743589744
[14] Train-accuracy=0.789230769230769
[15] Train-accuracy=0.786153846153846
[16] Train-accuracy=0.817692307692308
[17] Train-accuracy=0.82974358974359
[18] Train-accuracy=0.840512820512821
[19] Train-accuracy=0.85
[20] Train-accuracy=0.861794871794872
[21] Train-accuracy=0.876410256410256
[22] Train-accuracy=0.895641025641026
[23] Train-accuracy=0.905128205128205
[24] Train-accuracy=0.899487179487179
[25] Train-accuracy=0.917948717948718
[26] Train-accuracy=0.936153846153846
[27] Train-accuracy=0.955384615384615
[28] Train-accuracy=0.958717948717948
[29] Train-accuracy=0.959487179487179
[30] Train-accuracy=0.936153846153846
お、結構いけますね。95%とは。Predictしても80%程度の精度は出ましたので、おぼろげな画像でもこの用途にはそこそこの意味があることがわかりました。これは、もう少し突っ込んでみる価値はありそうです。
update 20170321
以下のようなライブラリとしてgithubに登録しました。
satobjextract
devtools::install_github("Masutani/satobjextract")
で、使えるようになります。