大学の授業でpandasを使う機会があったので、データの取得から分析までの流れを残しておこうと思います。
データの取得
どのデータを使うかですが、今回は、前回の記事で紹介した、D-Oceanというデータベースプラットフォームを使います。
D-Oceanにログインするとこのように最近アップロードされたと思われるデータがトップに出てきます。
今回は山梨県の市町村別人口、出生児数(男女)、死亡者数(男女)、自然増加数 2016年というデータを使うことにしましょう。
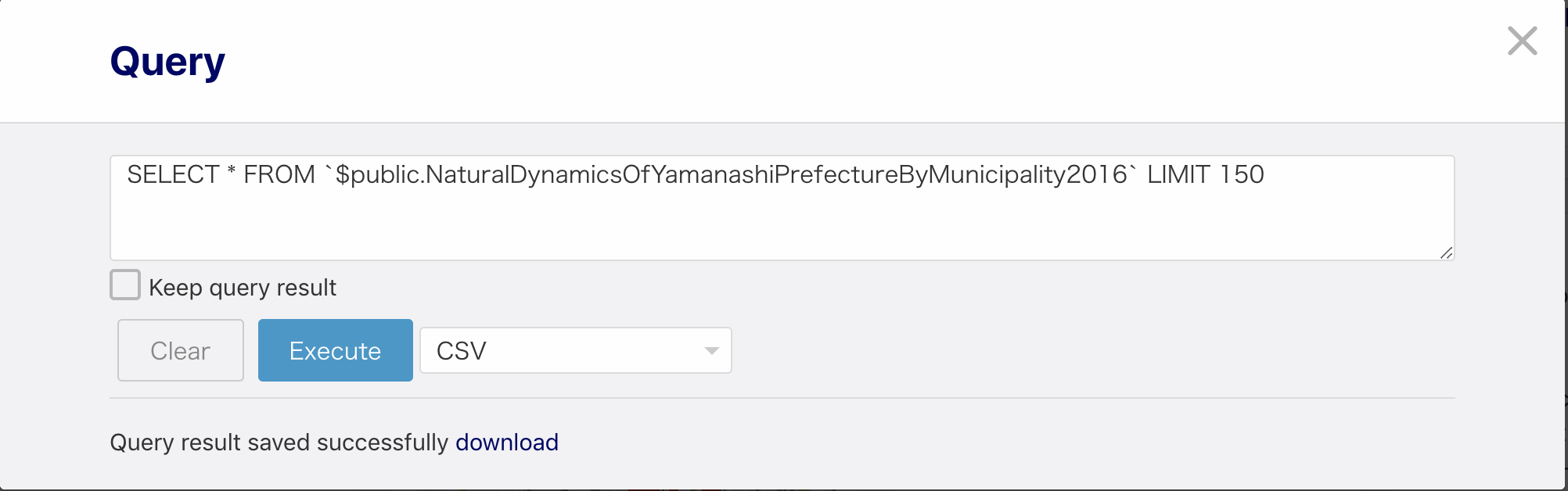
山梨県の市町村数はたかが知れているので、もともとボックスに入っているSQL文をそのまま実行して全部csvで持ってきます。多分大丈夫です。念の為、limit150を付けておきます。(あとで確認したら100未満だったので杞憂でした。)
データの読み込み
分析はローカルのjupyternotebook上で行います。余談ですが、最近jupyter labというのを知りました。anacondaを入れていれば、ターミナルでjupyter labと打つと起動します。IDEっぽくてかっこいいです。
それではcsvを読み込みましょう。
コード
import pandas as pd #pandasはpdとしてimportするらしい
popuyama=pd.read_csv("data/populationofYamanashi.csv") #これでcsvが読み込めます
popuyama.head() #headはデータの先頭5行を表示します。引数を指定することで、好きな行数を表示できます
・変数名がダサい、わかりにくいと叩かないでください。
・今回はcsvを読み込みますが、read_tsvでtsvも読み込めます。
・これらはDataFrameオブジェクトを作ります。この場合pupuyamaがそれに当たります。僕は各バリューが同じ長さのリストになっている辞書みたいな認識を持ってます。
・pandasを使うときは今データがどうなってるのか気になるので僕はしょっちゅうheadして中身を見てます。今回のデータくらいなら、全部出してみても大丈夫でしょうが、数千万行のデータの時は、出すだけでかなり時間がかかるので、headを使うのがいいと思います。
実行結果

なんとなく見たことある「パンダスの表」ですね。
上に並んでるGruoundDomainName,Population,...がキーでその列が値です。一番左の列はインデックスで勝手につきます。
自分のことを棚に上げておいてアレですが、キーの名前がちょこちょこ気になります。
データをいじる
カラム名の変更
どこかの授業で、変数は長くてもわかりやすくて情報量が多い方がいいと習いましたが、上の表をみる限り、キーが長すぎて見切れてしまっています。ブログ書く都合上よくないので、まず名前を変えたいと思います。
コード
popuyama=popuyama.rename(columns={"GroundDomainName":"Domain","NumberOfBirthChildren":"NumofBorn","AFewMenBorn":"MenBorn",
"AFewWomanBorn":"WomanBorn","TotalNumberOfDeaths":"NumofDeath","AFewMenDied":"MenDied",
"AFewWomanDied":"WomanDied","NaturallyIncreasingNumberOfPeople":"NumofNaturalIncrease"})
popuyama.head()
renameを使って、columnsで旧名と新名を対応させる辞書を渡すと名前を変更できます。
DataFrameのメソッドは少し使った感じだと、非破壊的なメソッドが多く、そのままだとpopuyamaが更新されないどころか、jupyternotebookだと、出力が始まるので地獄です。自分で代入するか、新しい変数を用意するかしましょう。
実行結果

隙間が詰まって全部入るようになりましたね。ちなみに一番右のナチュラルインクリースは、生死のみによるの人口の増減らしいです。
列の指定
列名を指定して、列を取り出す方法です。
コード
popuyama_pop=popuyama.Population #一つの列を指定
popuyama_pop.head()
popuyama_pops=popuyama[["Population","NumofNaturalIncrease"]] #複数の列を指定
popuyama_pops.head()
実行結果

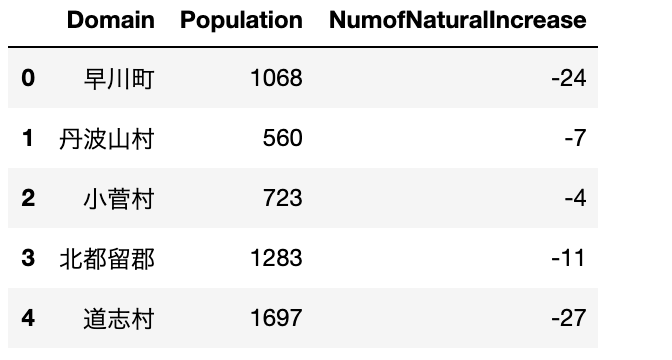
一つの列を指定するのに.<カラム名>を使うと、チープな表になるので、一つの時も、複数の時と同じようにするのが良さそう。
ソート
今作った、popuyama_popsを、人口が多い順にソートしてみます。sort_valuesメソッドを使います。
コード
pop_lank=popuyama_pops.sort_values("Population",ascending=False)
pop_lank.head()
実行結果

人口のランキングができました。ascendingはデフォルトだとTrueです。降順にする時はFalseにします。
カラム(列)の追加
カラムは辞書と同じように追加できます。今回は人口増加率を表す、IncreseRateというのを追加してみます。
次に、人口増加率の中身を計算していきます。applyというメソッドを使います。applyには、1次元配列に対して適用できる関数と、その軸(列か行か)を渡します。
コード
CalcRate=lambda x :x[-2]*100/x[1] #関数作る
popuyama["IncreaseRate"]=popuyama.apply(CalcRate,axis=1) #axisは列方向なら0 行方向なら1
popuyama.head()
実行結果
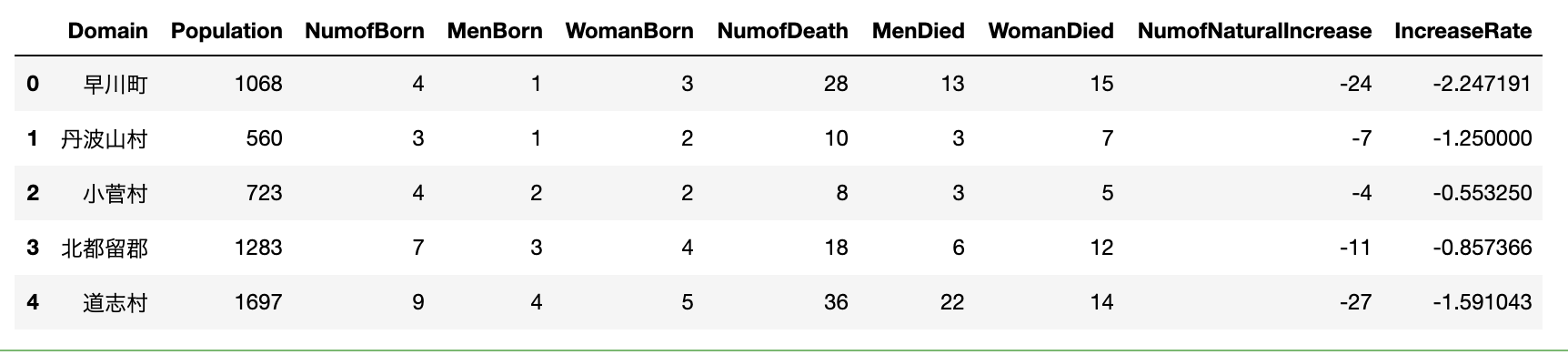 lamda式のxのインデックスは必要なカラムの番号を数えればわかります。
lamda式のxのインデックスは必要なカラムの番号を数えればわかります。
条件
列を指定して、値が条件と一致する行だけ取り出すことができます。
人口が多い自治体と少ない自治体に分けてみます。
コード
high_pop=popuyama[popuyama["Population"]>=20000]
low_pop=popuyama[popuyama["Population"]<20000]
high_pop.head()
low_pop.head()
実行結果


2000人で区切るとちょうど半々に分けられました。
集計
さっき自治体を二つの表に分けてしまいましたが、それだと、列の値を別の列の値ごとに集計するgroupbyメソッドと相性が悪いので、Popurationsizeというカラムを作り、bigかsmallかを入れていきます。
コード
separate=lambda x:"big" if x[1]>=20000 else "small"
popuyama["PopulationSize"]=popuyama.apply(separate,axis=1)
popuyama.head()
実行結果

見た感じsmallしかないですが、bigもあるはずです。
それでは、PopulationSizeの値ごと、つまり、bigとsmallそれぞれのIncreaseRateの平均を出してみます。
コード
popuyama.groupby("PopulationSize")["IncreaseRate"].mean()
実行結果

できました。子供を産むような若い人の割合は、人口の多い(すなわち都会)都市の方が高いと考えたので、IncreaseRateは、bigの方がsmallより大きいのではないかと思っていたのですが、予想どうりでした。差はそんなにないし、両方マイナスですが。。。
終わりに
pandasには少し慣れてきた気がします。
他にも楽しそうな分析があると思います。ここで紹介した以外にもメソッドはたくさんあるので、欲しい機能はだいたい網羅されてそうです。
それではおやすみなさい。