本投稿について
本投稿は、Microsoft Learn で公開されている、「SQL Server でクエリのパフォーマンスを最適化する 」を確認していた際に、いくつかの情報を補足しながら日本語化したものとなります。
SQL Server / Azure SQL Database のパフォーマンスチューニングには様々な方法があり、「このケースであればこの方法」ということを断定することは難しいのではないでしょうか。
そのため、様々なケースで利用することが可能な、チューニング方法の基礎知識 (一般論) はとても重要です。
本投稿で、確認を行った「SQL Server でクエリのパフォーマンスを最適化する 」は、チューニングに対しての体系的な考え方を無償で学ぶのには適しているコンテンツではないかと思いました。
チューニング系の講義は様々なノウハウが絡みますので有償が多く、ノウハウがない状態で体系立てて学習するのは少し難しいのではないでしょうか。
本投稿で紹介した Microsoft Learn の内容で、基礎知識を体系立てて学習し、気になった点をさらに自助努力で探求していくことで、チューニングスキルは大きく向上すると思います。
このモジュールは、まもなく次の言語で使用できるようになります: 日本語。
という記載がありますので、近日、日本語のコンテンツとしても公開されるのではないでしょうか。
細かな内容については、本投稿ではなく、原文を確認していただいたほうが良いと思います。
割とボリュームのある投稿にすることができ、普遍的なチューニングのアプローチが含まれていますので、小出しにメンテナンスしていこうかと思います。(きっと、たぶん。。。)
ちなみに、SE の雑記 でなく、Qiita で書いた理由は、ブログで書いた場合と Qiita で書いた場合にどれくらいアクセス傾向が変わるのかを、確認できるかなと、ふと思ったからです。
1. SQL Server のクエリプラン (Describe SQL Server query plans より)
クエリプランの種類
コストベースのオプティマイザ
- 列に関する統計情報 / 各クエリプランの操作で利用可能なインデックスに基づいて、複数のプランのコストを算出する
使用される可能性のある全プランを評価するのではなく、ヒューリスティックにパフォーマンスの良いプランを決定し、そのプランの中で最もコストの低いプランを選択する- 適切な統計を持つことが重要となる
- 急激なデータの変化が発生した場合は、統計情報の自動更新のタイミングでは情報が更新されず、統計情報が不適切な可能性があることを考慮
クエリ実行の基本的な処理
-
クエリ構文の解析し、構文が正しい場合は Parse Tree を生成
- 構文の解析ツリーは、バインディングのため Algebrizer というデータベースエンジンコンポーネントヘの入力として使用される
- クエリ内のオブジェクトと列が存在するかを検証し与えられたクエリに対して、処理されるデータ型を特定
- 次ステップの入力となるクエリプロセッサツリーを出力
- 構文の解析ツリーは、バインディングのため Algebrizer というデータベースエンジンコンポーネントヘの入力として使用される
-
プランが存在しない場合、クエリオプティマイザは、コストベースのオプティマイザを使用して、クエリで使用される列 / テーブル / インデックスについての統計情報に基づいて、いくつかの実行プランを生成
- このプランの出力が実行計画となる
- 列の存在等が確認できた後に、クエリ用のハッシュ値を生成し、一致するハッシュ値がプランキャッシュ上に存在するかを確認する
-
プランキャッシュから取得されたプランまたは、上述のステップで出力されたプランを使用して実行される
クエリプランの役割
-
一連のデータ取得に対しての実行方法の生成
-
この生成の中には、Join / Sort で使用するために必要となるメモリ (ワークスペースメモリ) についても決定される
- Memory Grant と呼ばれる
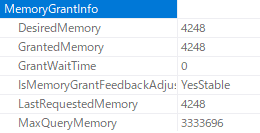
- メモリが不足すると、RESOURCE_SEMAPHORE による待ちが発生する可能性がある
- ワークスペース用のメモリの確保待ち
- クエリのコストの 25 倍の秒を待機してから再度実行するようになっており、最大で 24 時間待機することができる
- クエリを実行する際に使用可能なメモリが十分でない場合は、データが tempdb で処理されるため、メモリと比較すると低速となる
- Memory Grant と呼ばれる
-
プランの中には、データベースの互換性レベル / クエリの並列度 / パラメーター化されているクエリの場合はパラメーター等が格納されている
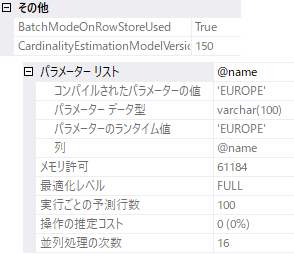
実行計画の種類
-
推定実行プラン (Estimated Execution Plan)
- クエリオプティマイザによって生成された実行計画 (プランキャッシュに格納されている実行計画はこのタイプになる)
- メタデータ / Memory Grant Size はクエリのコンパイル時にデータベースに存在する統計情報からの推定値に基づいたものとなる
- テキストベースで確認する場合は、SET SHOWPLAN_ALL ON
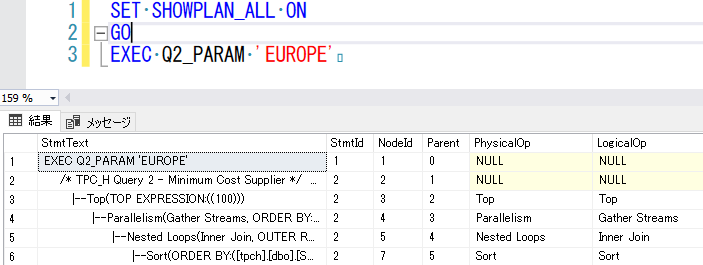
- クエリは実行されず、即時にプランを確認できる
- 統計情報をベースにして、実行プランを生成しているため、実際の実行は行わず高速に、使用される「可能性のある」プランを確認することができる
- 「推定」であるため、実際のデータ操作の際には、異なるプランが生成される可能性がある
- 統計情報をベースにして、実行プランを生成しているため、実際の実行は行わず高速に、使用される「可能性のある」プランを確認することができる
-
実際の実行プラン(Actual Execution Plan)
-
推定実行プランと同等であるが、クエリの実際の実行コンテキストが含まれており、推定行数と実際の行数、実行の警告、実際の並列度、実行中の経過時間と CPU 時間が含まれる
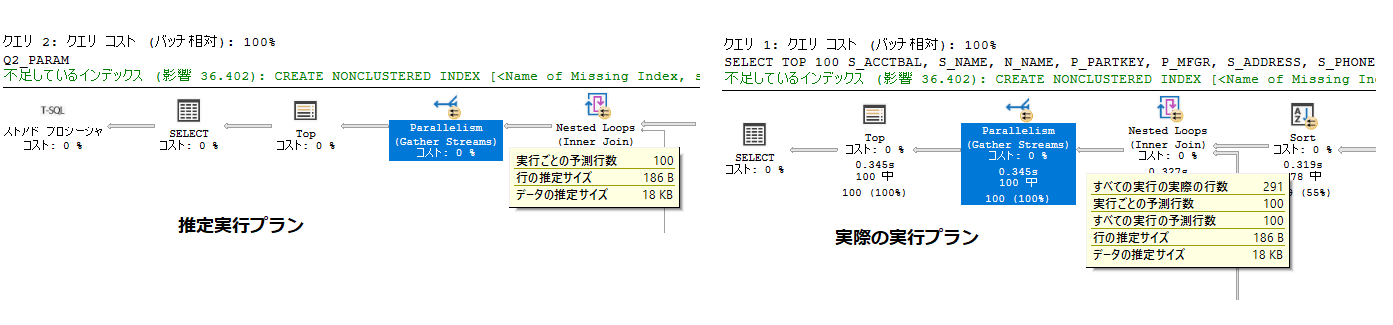
-
テキストベースで確認する場合は、SET STATSTICS PROFILE ON
-
-
ライブクエリ統計 (Live Query Statistics)
- 推定実行プランと実際の実行プランを組み合わせ、進捗状況を 1 秒単位で更新されるアニメーションで確認できる
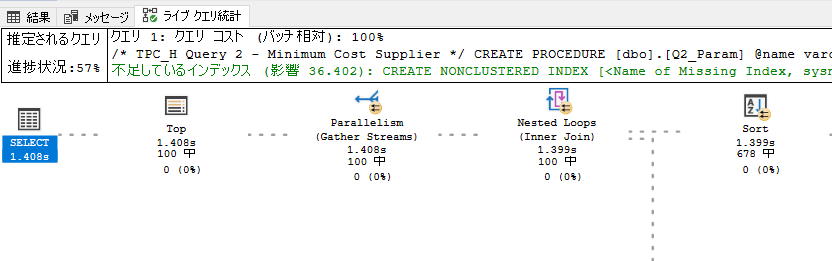
- クエリで実行される操作を、実際に取得されるデータの流れを表示しながら確認できる
- 大量にデータを取得されている処理 / どこが処理のブロッカーになっているのかが把握しやすくなる (データの流れが止まっている = クエリ内のブロッカー要素)
- 推定実行プランと実際の実行プランを組み合わせ、進捗状況を 1 秒単位で更新されるアニメーションで確認できる
推定と実際のクエリプラン
実行プランの確認方法
- 実行プラン内の操作の内容については、プラン表示の論理操作と物理操作のリファレンス から確認をすることができる
- 実行は、右から左 / 上から下へ流れる
- 演算子を結ぶ線の幅は次の演算子に流れるデータの行数の推定値に基づく
- 実際の実行プランの場合は、実際に処理された行数を確認することができる
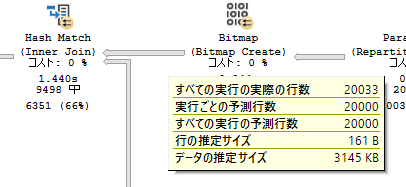
- 推定値と実際に処理された行数を比較することで、統計情報と実際に処理されたデータ件数で大きな乖離が発生していないかを確認することができる
- 実際の実行プランの場合は、実際に処理された行数を確認することができる
軽量なクエリプロファイリング
-
最大で約 2% 程度のオーバーヘッドが発生する
- SSMS / 拡張イベントを使用して実行プランをキャプチャするとオーバーヘッドが大きい可能性がある
- 負荷としては数 % の上昇かもしれないが、個々のクエリのパフォーマンスを大幅に低下させる可能性がある
- 実行回数の少ないクエリで負荷が上昇した場合は大きな問題にはならない可能性が高いが、頻繁に実行されるクエリについては、数 % の負荷増が、サーバー全体のパフォーマンスに大きく影響を与える可能性がある
-
SQL Server 2014 SP2 / SQL Server 2016 で最初に導入され SQL Server 2016 SP1 以降で機能が強化された
- query_thread_profile の拡張イベントで、クエリ内の各演算子のデータを検査できるようになった
- 初期バージョンでは、トレースフラグ (TF) 7412 を使用する必要があった
- [2016 SP2 CU3 / 2017 CU11 以降] (https://support.microsoft.com/ja-jp/help/4458593/update-adds-lightweight-query-profiling-hint-in-sql-server-2016-and-20)では、軽量なクエリプロファイリングがグローバルで有効になっていない場合に、、クエリヒント (QUERY_PLAN_PROFILE) で、クエリ単位で有効化できるようになった
- ヒントが設定されていると、query_plan_profile 拡張イベントが生成される
-
SQL Server 2019/ SQL Database / Managed Instance では、デフォルトで有効になっている
- LIGHTWEIGHT_QUERY_PROFILING データベース スコープオプションで、データベース単位で軽量なクエリプロファイリング機能を無効化することが可能
- 軽量なクエリプロファイリングを活用するとsys.dm_exec_query_profilesから、クエリの進行状況を DMV からリアルタイムで確認することもできる
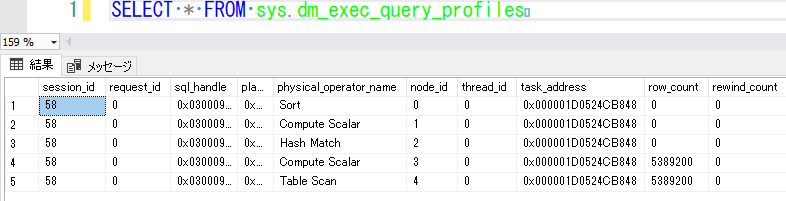
- ライブクエリ統計の GUI ではなく、DMV で参照することにより取得ができると、既に実行が行われたクエリの情報を柔軟に取得することができる
- 軽量なクエリプロファイリングを活用するとsys.dm_exec_query_profilesから、クエリの進行状況を DMV からリアルタイムで確認することもできる
- LIGHTWEIGHT_QUERY_PROFILING データベース スコープオプションで、データベース単位で軽量なクエリプロファイリング機能を無効化することが可能
-
最後の実際の実行プランの取得
-
sys.dm_exec_query_plan_stats により、最後の実際の実行プランを取得することができる
- プランキャッシュからは確認できない、最後に実行されたクエリの実際の処理行数を確認できる
- TF2451 を有効化または、LAST_QUERY_PLAN_STATS のデータベーススコープオプションを有効化
-
sys.dm_exec_query_plan_stats により、最後の実際の実行プランを取得することができる
問題のあるクエリの実行プランの特定
クエリのパフォーマンスが一貫して悪い
- ハードウェアリソースの制限 / 最適ではないクエリの構造 / データベースの互換性レベル / インデックスの欠落 / クエリオプティマイザで効率の悪いプランが生成されている
- 実行タイミングに依存して処理が遅いのではなく、恒常的に処理性能が悪いケース
- リリース当初から性能が出ていない / データが増加したことにより性能が劣化しているというような可能性がある
- 一貫して性能が出ていない場合は、テストが実施しやすい (再現性が確認しやすい) ため、Try & Error で改善点を見つけられる可能性がある
ある実行では問題はないが、他の実行では問題が発生する
- パラメーター化されたクエリでデータの偏りがあり、特定の実行では効率の悪いプランが生成された
- ストアドプロシージャ / パラメーター化クエリを使用していて、コンパイルが発生するタイミングで指定されたパラメーターにより生成された実行プランが、他のパラメーターには適しておらず、安定した性能が発揮できない
- テーブルアクセス時に他のクエリの完了を待つブロッキング / ハードウェアリソースの競合
- ロック競合のような論理的な待機の発生 / 複数のクエリ実行による、過度な CPU 負荷 / ディスク I/O の発生により、ハードウェアリソースへのアクセスが競合している可能性
ハードウェアの制約
- 単一のクエリ実行では発生しにくいが、負荷が発生し、CPU スレッドや、クエリ間で共有されるメモリのサイズが限定されている場合にハードウェアの制約が明らかになってくる
- ハードウェアパフォーマンスは、比較的簡単に確認できるため、トラブルシューティングの早期の段階で確認を行う
- 非効率なクエリが実行されていることでハードウェアに過度な負荷が発生しているかを確認する
- インデックスが存在せず、クエリの処理に必要となるデータの取得のために CPU / ストレージ / メモリを圧迫している
- ハードウェアの問題の対処 (ハードウェア性能の向上) の前に、最適でないクエリのチューニングの実施を検討する
- クエリのチューニングを実施しないと、ハードウェア性能を変更しても同様の事象が発生し、スペックを増強した効果が出ない可能性がある
- クエリのチューニングを適切に実施することで、ハードウェアスペックを増強しなくても、現状のスペックで対応できる可能性も考えられる
CPU の競合が発生している場合
- パフォーマンスカウンター : % Processor Time から確認
- 待ち事象 : SOS_SCHEDULER_YIELD / CXPACKET
ストレージのパフォーマンス
- パフォーマンスモニター : Disk Seconds/Read / Disk Seconds/Write
- ストレージのパフォーマンスが低下し、I/O の完了に 15 秒以上かかる場合は、ERRORLOG にメッセージの出力が行われる
- 待ち事象 : PAGEIOLATCH_SH
最適でないクエリの構成
-
RDBMS は結果セットベースの操作を実行した際に最高のパフォーマンスを発揮する
- INSERT / UPDATE / DELETE / SELECT を実行し、値のセットに対して作業を行う
- セットベースの代わりに、カーソルや While ループを使用し、行ベースの処理を実行することもできるが、処理対象の行の数に応じて、コストが処理対象の行の数に応じて、直線的に増加するため、アプリケーションのデータ量の影響を受けやすくなる
-
テーブル値関数 (TVF) / マルチステートメントテーブル値関数 (MSTVF) を使用した場合も、SQL Server 2017 以前では問題のある実行計画を生成する可能性があった
- どちらの TVF も動的に行が生成されるため、クエリプランのコストを見積もる際に固定の行数を使用していた
- ユーザー定義スカラ関数も同様で、推定行数の把握ができないため、効率の悪い実行プランを生成する可能性がある
- SQL Server 2017 以降は、互換性レベル 140 と 150 で Intelligent Query Processing により、この問題を解決することができる
SARGable (Search ARGument ABLE)
-
RDBMS における SARGable という用語は、クエリの実行を高速化するためにインデックスを活用できる、特定の形式の述語 (WHERE 句) を指す
- 正しい形式の述語は「検索引数 (Serch Argument)」または SARG と呼ばれる
- SQL Server で SARG を使用する = オプティマイザがインデックス (またはテーブル) 全体をスキャンして情報を取得するのではなく、SARG で参照している列の非クラスター化インデックスを使用して SEEK 操作を評価することを意味する
-
SARG / 検索引数は、効率の良いクエリには非常に重要となるが、述語の選択肢が高く、インデックスがサポートされていたとしても、インデックスが使用されることを保証するものではない
- クエリ オプティマイザがインデックスを活用できるように述語を記述する必要がある
- 述語の引数が検索可能な場合にのみインデックスを使用することができる
- 検索時に列に対して、関数を設定した場合は、非SARGable となり、オプティマイザがインデックスシークを評価できなくなる
- 列に対して関数を設定するのではなく、固定値のほうに設定を行うようにする
-
データベース開発のアンチパターンとして、データベースをデータストアではなくサービスとして取り扱うものがある
- データを JSON に変換し、文字列の操作を行う / 複雑な計算を行うためにデータベースを使用する
- このようなケースの場合、CPU を過剰に使用してレイテンシーが増加数r可能性がある
- すべてのレコードを取得してデータベース内で計算を実行しようとするクエリは過剰な IO / CPU 負荷を発生させる可能性がある
- データアクセスの操作と、集計のような処理に最適化されたデータベースを構築することを考慮する
- データを JSON に変換し、文字列の操作を行う / 複雑な計算を行うためにデータベースを使用する
インデックスの欠落
-
もっとも一般的なパフォーマンスの問題は、有用なインデックスが不足しているため、クエリの結果を返すために、必要以上に多くのページを読み込むことに起因している
- インデックスもリソースを消費するものとなる (書き込みパフォーマンスとストレージサイズに影響を与える) が、インデックスにより提供されるパフォーマンスの向上は、追加のリソースコストを何倍にもわたって相殺することができる
- パフォーマンスに問題を持つ実行計画は、クエリ演算子が、Clusterd Index Scan / NonClustered Index Scan + Keylookup の組み合わせ (インデックスだけで処理が完了していない) による特定できるケースがある
- データベースエンジンは、実行計画で欠落しているインデックスの報告を行うことで適切なインデックスがないことに対しての問題の解決を行おうとする
- 欠落しているインデックスについては、sys.dm_db_missiong_index_details から確認を行うことができる
-
sys.dm_db_index_usage_stats / sys.dm_db_index_operational_stats を使用することで、インデックスの利用状況を確認することができる
- 使用されていないインデックスを削除する際の判断基準にすることができる
-
欠落しているインデックスや実行プラン内の警告は、クエリのチューニングを実施する際の出発点としてのみ使用する
- 情報が必ずしも有益ということもなく、問題を解決するために主要なクエリはどれなのかを理解し、そのクエリをサポートするためのインデックスを構築することが重要
- 欠落したインデックスをすべて作成することは推奨されない
欠落している / 古い統計情報
-
クエリオプティマイザにとって、列とインデックスの統計情報は適切な実行プランを選択するために重要となる
- 古い統計情報での状態では、適切な実行プランが生成されない可能性を考慮する
-
SQL Server / SQL Database / Managed Instance では、統計情報の自動更新がデフォルトで有効になっている
- SQL Server 2016 より前の自動更新のデフォルトの動作は、インデックス内の列への変更が、テーブル内の行数の約 20% になるまで統計情報の更新を行わないというものであった
- トレースフラグ 2371 を有効にすることで、テーブルサイズに応じて、統計情報の自動更新のトリガーとなる必要な行数の割合が少なくなる
- 上記以降のバージョンでは、自動更新の閾値の動的な設定についてはデフォルトで有効になっている
- 互換性レベル 130 以上では、データベースエンジンによって制御されるため、TF の効果はない
- SQL Server 2016 より前の自動更新のデフォルトの動作は、インデックス内の列への変更が、テーブル内の行数の約 20% になるまで統計情報の更新を行わないというものであった
-
sys.dm_db_stats_properties から、統計情報が最後に更新された時間 / 更新後に変更された行数を確認することができ、手動で更新が必要な統計情報の特定に活用できる
オプティマイザーの不適切な選択
-
コストベースのオプティマイザーであり、すべてのパターンを網羅して実行プランを生成しているわけではないため、クエリ実行に影響のあるプランを生成する可能性がある
-
これらに対処する方法として、クエリヒント / トレースフラグ / 実行プランの強制 を行うといった、いくつかの調整方法がある
パラメータースニッフィング
-
SQL Server は将来的に使用するためのクエリの実行計画をキャッシュして再利用する
-
実行計画がキャッシュされているかについては、クエリのハッシュ値に基づき行われるため、クエリテキストの同一性が求められる
-
ストアドプロシージャや sp_executesql を使用することでクエリのパラメター化を行い、再利用効率を上昇させることができる
-
パラメーター化されたクエリは、パラメーターの初期値に応じてクエリの最適化が行われる
- この動作をパラメータースニッフィングと呼ぶ
- パラメーター化されたクエリにより、クエリの再利用効率が上昇することで、クエリのコンパイルに関しての全体的な作業をサーバー上で削減することができる
- データの偏り (Skew) がある場合は、パラメーターの初期値でコンパイルされたクエリは、すべてのパターンで最適というわけではないため、データの選択度によってはパフォーマンスに影響を与える可能性がある
- このような動作によるパフォーマンスの問題の発生は一般的である
-
いくつかの対処方法があるが、それぞれにトレードオフがある
- クエリ (ステートメント) に対して RECOMPILE ヒント または、ストアドプロシージャに対して WITH RECOMPILE オプション を指定
- クエリ / ストアドプロシージャが実行されるたびに再コンパイルされるため、CPU 使用率が上昇するが、常に現状のパラメーターが使用される
-
OPTIMIZE FORUNKNOWN クエリヒントを使用する
- パラメーター依存問題への対応
- クエリヒントを使用することで、パラメータースニッフィングを使用するのではなく、統計情報のヒストグラムと値を比較するようになる
- 実行時のパラメーターに適した最高のプランを得ることはできないが、一貫した実行プランの選択を可能とする
- RECOMPILE を実行するようにクエリの書き換えを行う
- パラメーターによって、動的にクエリを生成し (ここで示す動的なクエリはすべての文字列を結合したアドホックなクエリだけをさすのではなく、パラメーター化クエリの動的な生成についても考慮)、パラメーターによって「OPTION (RECOMPILE)」 のヒントを追加したクエリの生成を行い、実行する
- 大規模な開発が必要となるケースがあるため、ニーズに合わせての実装を検討する
- クエリ (ステートメント) に対して RECOMPILE ヒント または、ストアドプロシージャに対して WITH RECOMPILE オプション を指定
2. パフォーマンス改善の評価 (Evaluate performance improvements より)
動的管理ビューと機能
-
SQL Server では数百の動的管理オブジェクトが用意されており、これらのオブジェクト含まれているシステム情報か次のようなことを実現できる
- サーバーインスタンスの状態の監視
- 問題の診断
- パフォーマンスチューニング
-
動的管理ビュー (DMV) / 動的管理関数 (DMF) から、データベースやインスタンスの状態に関しての内部データを取得することができる
- DMV にはサーバースコープとデータベーススコープの 2 種類がある
- サーバースコープ : VIEW SERVER STATE の権限が必要
- データベーススコープ : VIEW DATABASE STATE の権限が必要
- DMV には次のような種類がある
- データベース関連の動的管理オブジェクト
- クエリ実行関連の動的管理オブジェクト
- トランザクション関連の動的管理オブジェクト
- サーバーとデータベースのパフォーマンスを監視するためのクエリについても公開されている
- DMV にはサーバースコープとデータベーススコープの 2 種類がある
-
SQL Server 2016 以降ではクエリストアを使用することができるが、古いバージョンでは、次の DMV を組み合わせて情報の確認を行う。
-
DMV で情報を取得した場合、クエリストアと異なり、クエリで使用されているプランの変化を辿ることはできない
-SQL Database では、SQL Server の DMV のフルセットの利用はできないため、参照可能な情報が多少制限される
待機統計 (待ち事象)
-
サーバーのパフォーマンスを全体的に監視するための方法として、サーバーがどのような事象により待機されているかを評価することがある
- SQL Server では、待機時間を追跡することができるシステムが実装されており、実行中の各スレッドの状態を監視し、スレッドで発生している待機リソースをログに記録している
-
待機統計は次の種類に分けられる
- リソース待機
- SQL Server のワーカースレッドが現在スレッドが使用しているリソースへのアクセスを要求している場合に発生
- 例としては、ロック / ラッチ / ディスク I/O 待機がある
- キュー待機
- ワーカースレッドがアイドル状態で、作業が割り当てられるのを待っているときに発生する
- 例としては、デッドロックの監視 / 削除されたレコードのクリーンアップがある
- 外部待機
- SQL Server がリンクサーバーに対してのクエリ実行のような、外部プロセスの完了を待っているときに発生する
- 例としては、クライアントアプリケーションに大きな結果セットを返した際の、ネットワーク待機がある
- リソース待機
-
待機統計は sys.dm_os_wait_stats (SQL Database については、sys.dm_db_wait_stats) に集計され、アクティブなセッションの待機情報については、sys.dm_exec_session_wait_stats から追跡することができる
- これらの待機統計から、DBA はサーバーのパフォーマンスの全体的な概要を把握し、設定やハードウェアに問題があるかを特定することができる
- データはインスタンスの起動時から保持されているが、必要に応じて、データをクリアして変化を観察することもできる
- 全体の待機状態から該当の待機状態の比率を算出することで、サーバー内でどの待機事象の発生が多いのかを確認することもできる
- 平均の待機時間を算出し、比率を確認する
- 単純に待機時間の降順で集計した場合は、通常時が待機状態のタスクの情報が上位に来てしまうため、ノイズとなる情報を除去することは意識する
パフォーマンスの問題に関連する一般的な待機事象
-
RESOURCE_SEMAPHORE
- メモリが利用可能になるのを待機しており、一部のクエリでメモリが過剰に確保されている可能性がある
- 通常、長い実行時間のクエリ / 長時間実行に伴うクエリタイムアウトが発生している可能性が考えられる
- 古い統計情報 / インデックスの欠落による不適切な実行プランの生成 / 過剰なクエリの同時実行により発生する可能性がある
-
LCK_M_X
- ブロッキングが発生している可能性がある
-
PAGEIOLATCH_SH
- 大量のデータをスキャンしているために、インデックスに問題がある (または、効果的なインデックスが不足している) 可能性がある
- 待機事象の発生回数が少なくても、待機時間が長い場合には、ストレージのパフォーマンスに問題がある可能性がある
- wait_tasks_count と wait_time_ms から平均待機時間を計算することでこの問題の調査を行うことができる
-
SOS_SCHEDULER_YIELD
- CPU 使用率が高い可能性がある
-
CXPACKET
- 待機が高い場合、並列クエリの並列度が高い (不適切な構成) になっている可能性がある
- SQL Server では、MAXDOP が 0 (すべての CPU を使用) するように設定されており、並列処理のコスト閾値 (Cost Threshold for Parallelism : CTfP) の設定はデフォルトで 5 に設定されている
- 小さなクエリが高い並列度で実行されている可能性も考えられる
- CXPACKET が発生しているということは、並列クエリが実行されていることを示すため、CPU 使用率が高いことを示す可能性もある
- インデックスチューニングで適切なクエリが実行されるようになると、SOS_SCHEDULER_YIELD / CXPACKET が低下し、パフォーマンスが向上する可能性もある
- 待機が高い場合、並列クエリの並列度が高い (不適切な構成) になっている可能性がある
-
PAGEIOLATCH_UP
- データページ 2:1:1 (DBID = 2 / File ID = 1 / Page ID = 1) の競合が発生している場合は、tempdb の Page Free Space (PFS) の競合が発生している可能性が考えられる
- tempdb のデータファイルが 1 つしかないことによる弊害
- PFS は約 64 MB ごとに存在し、その領域の更新が競合している
- ベストプラクティス
- CPU のコアごとに 1 つのデータファイルを追加し、最大で 8 ファイルとして設定を行う
- べてのデータファイルのサイズ / 自動拡張サイズを均等に設定し、ファイルが均一に利用されるようにする
- SQL Server 2016 以降は tempdb のデータファイルは同時に拡張が行われ、一貫したサイズを提供できる
- それより前のバージョンではTF1117 を利用することで、同様の動作とすることができる
- tempdb のデータファイルが 1 つしかないことによる弊害
- データページ 2:1:1 (DBID = 2 / File ID = 1 / Page ID = 1) の競合が発生している場合は、tempdb の Page Free Space (PFS) の競合が発生している可能性が考えられる
-
クエリストアでも待機情報は追跡されている
- DMV と同様の粒度ではないため、精度は低くなるが、クエリがどのような要因により待機しているかを確認するための重要な情報として活用できる
インデックス チューニング
-
クエリをチューニングするための最も一般的 (最も効果的) な方法は、インデックスを評価して調整すること
- 適切にインデックスが設定されたデータベースは、クエリの結果を返すために実行される I/O が少なく、これにより、I/O とストレージシステムの両方にかかる負荷を軽減することができる
- I/O を減らすことで、メモリの利用効率を高めることもできる
-
クエリの Read / Write の比率には注意をする
- Read と比較して、Write のワークロードが多い場合は、インデックスを追加することで、行の更新のコストが多くなり、インデックス追加のメリットが低い可能性がある
- Write でも更新を実行している場合、インデックスの追加により、Lookup 操作を最適化し、インデックス追加のメリットを受けることができる可能性がある
-
目標は常に最小数のインデックスで最大のメリットを得ることである
-
インデックスチューニングの一般的なアプローチ
- sys.dm_db_index_operational_stats と sys.dm_db_index_usage_stats を使用して、既存インデックスの使用状況を評価する
- 未使用のインデックスや重複したインデックスの削除を検討する
- 毎日使用されているのではなく、月次/四半期/年次で実行される処理で使用されている可能性を考慮する
- インデックスの削除後に処理を実行し、定期的なスケジューリング処理に影響がないことを確認することも検討する
- 毎日使用されているのではなく、月次/四半期/年次で実行される処理で使用されている可能性を考慮する
- クエリストアまたは、拡張イベントからコストの高いクエリを取得して評価し、それらのクエリをより効率的に実行するためのインデックスを手動で作成する
- 非本番環境でインデックスを作成し、クエリ実行とパフォーマンスをテストし、パフォーマンスの変化を観察する
- 本番と非本番環境でメモリサイズ / CPU 数が異なる場合、実行計画に影響を与える可能性があるため、ハードウェアに違いがあるかを認識しておく
- 慎重にテストを実施した後に、本番環境にインデックス変更を反映する
-
インデックスの列の順序を確認する
- インデックス列の先頭の項目が、通常オプティマイザが該当インデックスを使用するかどうかの決定に大きく影響を与える
- インデックスの列の先頭の項目が選択的であり、多くのクエリの WHERE 句で使用されるのが望ましい
- インデックス作成についてもソース管理の配下に置いておくことで、インデックス変更によるパフォーマンス影響が発生した場合に、以前のインデックスを素早く作成することにつながる
- インデックス列の先頭の項目が、通常オプティマイザが該当インデックスを使用するかどうかの決定に大きく影響を与える
インデックス メンテナンス
-
データがインデックスに挿入 / 更新 / 削除されると、インデックス内の論理的な順序が、インデックスを構成するページの内部やページ間の物理的な順序と一致しなくなる
-
時間の経過とともにデータの変更が行われると、データベース内にデータが散らばる / 断片化する可能性もある
- 断片化は、データベースエンジンが、必要なデータを見つけるため、追加のページを読む必要がある場合、クエリパフォーマンスを低下させる可能性がある
-
断片化の状態を検出するための DMV が提供されており、その情報から断片化の状態を確認できる
- B-Tree (行ストア) インデックス用 : sys.dm_db_index_physical_stats
- 列ストアインデックス用 : sys.dm_db_column_store_row_group_physical_stats
再構成 (REORGANIZE)
- リーフレベルのインデックスページを物理的に並び替え
- リーフノードの論理的なソート順に合わせて、インデックスをデフラグ
- インデックスのフィル ファクターに基づいて、インデックスページを圧縮
- オンライン作業として実行することができる
再構築 (REBUILD)
- インデックスのページを削除して再作成
- 統計情報が最新の情報で更新される (再編成では更新されない)
-
オンラインで実行するためにはオンライン用のオプションを指定する必要がある
- SQL Server 2017 以降では、再開可能なインデックスのオンラインメンテナンス機能が追加されている
- インデックスのメンテナンスを一時停止 / 再開することが可能となり、特定のメンテナンスウィンドウ内でのインデックスメンテナンスを効率的に実施することができる
- SQL Server 2017 以降では、再開可能なインデックスのオンラインメンテナンス機能が追加されている
再構成 / 再構築の一般的なガイドライン
- 断片化が 30% を超えた場合は再構築を行うというもの
- 実際にどの程度の断片化で解消を行えばよいかの閾値はケースによってことなる
- 断片化が 5% 未満のインデックスについては、デフラグを実施することのコストが、パフォーマンスのメリットよりも大きいため、低い断片化のインデックスはデフラグを見送るという考え方もある
- 断片化の解消により、ディスクサイズ (データファイル) の最終的な削減にも効果がある可能性がある
- インデックススキャンが頻繁に行われている場合は、断片化を解消することによる効果が大きいが、シーク操作が多い場合には、断片化を解消することによる性能の向上の効果は薄い可能性が考えられる
- 断片化を解消することで、問題に対してどのようにパフォーマンスが改善するかをイメージすることが重要
- 実際にどの程度の断片化で解消を行えばよいかの閾値はケースによってことなる
列ストアインデックスのメンテナンス
- sys.dm_db_column_store_row_group_physical_stats で、削除された行について調査を行う
- 列ストアインデックスの断片化の測定の指標は、インデックス内の削除されたデータに基づいて実施するのが一般的である
- 20% 以上の行が削除されている場合は、再構成によって、インデックスのメンテナンスを実施し、ワークロードのパフォーマンスが向上するかを検証する
3. パフォーマンスベースの設計 (Explore performance-based design より)
正規化
- 正規化はデータベース内のテーブルと列に与えられているデータセットを整理するために使用すされる設計のプロセス
- データベース内に含まれる重複なデータを減らし、データベースの挿入や更新によるパフォーマンスへの影響を軽減することが目的
第一正規化
- 関連するデータの集合ごとにテーブルを作成する
- 個々のテーブルでグループ化を繰り返すことを排除する
- 関連データの各セットを主キー (単一列だけでなく、複合列も検討) により識別する
第二正規化
- テーブルが複合キーを持つ場合、すべての属性は完全なキーに従属し、一部のキーだけに従属しない
第三正規化
- すべての非キー列は、主キーに非推移的に従属する
非正規化
- 第三正規化が望ましいが、この正規化がすべてのデータに対して可能であり、最適なパフォーマンスを発揮するとは限らない
- 正規化を行うことで、複数の結合操作を必要つすることがあるため、クエリのパフォーマンスに影響を与える可能性が出てくる
- データウェアハウスのような読み取りデータの多いワークロードの場合は、非正規化したデータのほうがより効率的にクエリを実行できる可能性がある
スター スキーマ
- 特定のイベント / 測定値 / メトリックを記録するファクトテーブルを使用し、ファクトテーブルをディメンジョンテーブルに結合する
- 読み取りのワークロードのパフォーマンスを向上させるために使用される
スノーフレーク スキーマ
- ディメンジョンを冗長性を減らすために正規化される
- ディメンジョン間でリレーションをつなぐようにスキーマを構成する
- ストレージスペースの節約につながるが、クエリにより多くの結合が必要になり、パフォーマンスが低下する可能性がある
適切なデータ型の選択
- SQL Server ではいくつかのデータ型を自動的に変換することができ、「暗黙の変換 (Implicit Conversion)」と呼ばれる
- 変換にはコストがかかり、クエリの実行プランに影響を与える可能性がある
- 明示的に変換をする場合も、必要以上に大きなデータ型に変換をすることで、多くのページを必要とする可能性がある
- 変換によって、追加の CPU オーバーヘッドの発生や、インデックススキャンが使用されることによるパフォーマンスへの悪影響が発生する可能性がある
- データ型の変換には優先順位があるため、変換が発生する場合、右辺 / 左辺のどちらが変換されるかも考慮する
インデックスの設計
クラスター化インデックス
-
キー値に基づいてソートされた順序で格納されたベースとなるテーブル
- 行はキーに指定した順序で格納されるため、テーブルには一つのクラスター化インデックスのみ作成することができる
- 一意性のある列や多くの種類がある列をキー項目として採用する
- ソートに使用される列をクラスター化インデックスとして設定することでソートコストを抑えることができる
-
クラスター化インデックスのないテーブルはヒープと呼ばれる
- 一般的にはステージングテーブルの用途として使用される
非クラスター化インデックス
- データ行とは別の構造体
- 一つのテーブルに複数の非クラスター化インデックスを作成することができる
- インデックスに対して定義されたキー値と、そのキー値を含むデータ行へのポインタが含まれる
- INCLUDEを使用することで、リーフレベルに追加の非キー列を追加しより多くの列をカバーすることができる
- PRIMARY KEY / UNIQUE 制約でインデックスが使用されており、テーブルにこれらを作成すると、インデックスが自動的に作成される
列ストアインデックス
-
大規模な集計ワークロードを実行するクエリのパフォーマンスを向上させる
- 当初はデータウェアハウスを対象としてたが、大規模なテーブル上でのクエリのパフォーマンスを改善するために、他のワークロードでも使用されるようになった
-
クラスター化列ストアインデックスと非クラスター化列ストアインデックスの 2 種類がある
- クラスター化列ストアについてはすべての列を含む
- 現状の SQL Server の実装では、列ストアインデックスはソートされていない状態でデータが格納される
-
列ストアインデックスでサポートされていないデータ型も一部ある
- XML / CLR / SQLVARIANT / NTEXT / TEXT / IMAGE
- ポートされていないデータ型を含む場合には、非クラスター化列ストアインデックスで該当の列を除外してインデックスを作成する
-
SQL Sever 2016 以降では、列ストアインデックスと行ストアインデックスを組み合わせて使用することができる
-
バッチモードでの処理により、最大で 10 倍のパフォーマンスを実現できる
- 列ストアインデックスでは、バッチモードにより一つずつ行を処理するのではなく、一連の行 (通常は約 900 行) をグループとしてまとめて処理を行うことができる
- これにより、CPU の命令数を大幅に削減することができる
- SQL Server 2019 では行ストア用のバッチモード動作も含まれている
- 行ストアのバッチモードでは、列ストアと同等のパフォーマンスは得られないが、分析のクエリでは最大で 5 倍のパフォーマンスが得られる可能性がある
- 列ストアインデックスでは、バッチモードにより一つずつ行を処理するのではなく、一連の行 (通常は約 900 行) をグループとしてまとめて処理を行うことができる
-
102,400 行 (約 10 万行) 以上の一括挿入 (Bulk Insert) を実行する場合に最適化されたロードパスがある
- 102,400 行は列ストアに直接ロードさせる場合の最小値
- 行グループと呼ばれる各行のコレクションについては最大で 1,024,000 行 (約 100 万行) になる
-
COMPRESS_ALL_ROW_GROUPS を使用してインデックスを再構成することで、強制的に行ストアを格納しているデルタストアを列ストアインデックスに圧縮することもできる
データ圧縮
- SQL Server では列ストアインデックス以外にもデータを圧縮するための方法が提供されている
- データを圧縮することで 8KB ページの中により多くのデータを格納することができ、読み取りが必要となるページ数を減らす / 一度のページ読み込みでより多くの行を読み取ることができる
- 物理的な I/O の削減と、バッファプールに格納しておける行数を増やすことにもつながる
- 圧縮のトレードオフは CPU のオーバーヘッドであるが、たいていの場合は、追加の CPU オーバーヘッドをはるかに上回るストレージ I/O のメリットがある
- オブジェクトレベルで実装されており、インデックス / テーブル / パーティションに対して個別に圧縮の設定を行うことができる
-
sp_estimate_data_compression_savings を使用することで、圧縮による効果を評価することができる
- SQL Server 2019 以降は、列ストアインデックス / 列ストアアーカイブ圧縮による効果を評価することもできるようになっている
行圧縮
- 基本的な圧縮方法でオーバーヘッドはあまり発生しないが、ページ圧縮ほどの圧縮の効果は得られない
- 行内の各列の値をその値を格納するために必要となる最小限の領域として格納する
ページ圧縮
- 行圧縮の上位セットであり、ページ圧縮を適用する前には、最初に行圧縮が行われる
- プレフィックスの圧縮 / ディクショナリ圧縮が用いられ、冗長なデータを排除することで、使用される領域の効率化が行われる
列ストア アーカイブ圧縮
- 列ストアのデータに対して、Microsoft XPRESS 圧縮アルゴリズム を使用するアーカイブ圧縮をすることでさらに圧縮をすることができる
- 読み取られる頻度は低いが、ルールやビジネス上の理由でデータを保持し続ける必要がある場合に最適
- データはさらに圧縮されるが展開にかかるCPUコストが、I/O 削減によるパフォーマンスの向上を上回る傾向がある