はじめに
前回AWSのS3とAthenaの概要を記事にしましたが、実際AthenaにSQLを記載して実行することもありましたので、記事にします。
今回はテーブル作成になります。
理解できているところとできていないところもあるのですが、分かっているところを主に記載します。
AWS Athenaとは
AWS上のストレージにあるCSV、JSON、Parquetファイルなどをまとめて1つのテーブルと見立てクエリを発行してデータを抽出するサービスです。
SQLを使います。
設定(クエリの結果)
Athenaの場合はクエリの結果をS3に吐き出しますが、吐き出し先のフォルダの設定をまずします。
Amazon Athenaからクエリエディタの「設定」タブ→「管理」ボタン選択して「クエリの結果の場所」を指定します。

クエリの記述
クエリの結果の場所を指定後は、クエリを書いていきます。
下記の赤枠にSQLを書いていくことでデータベースやテーブルを作成するクエリやデータを条件に従って取得するクエリなどを書くことができます。
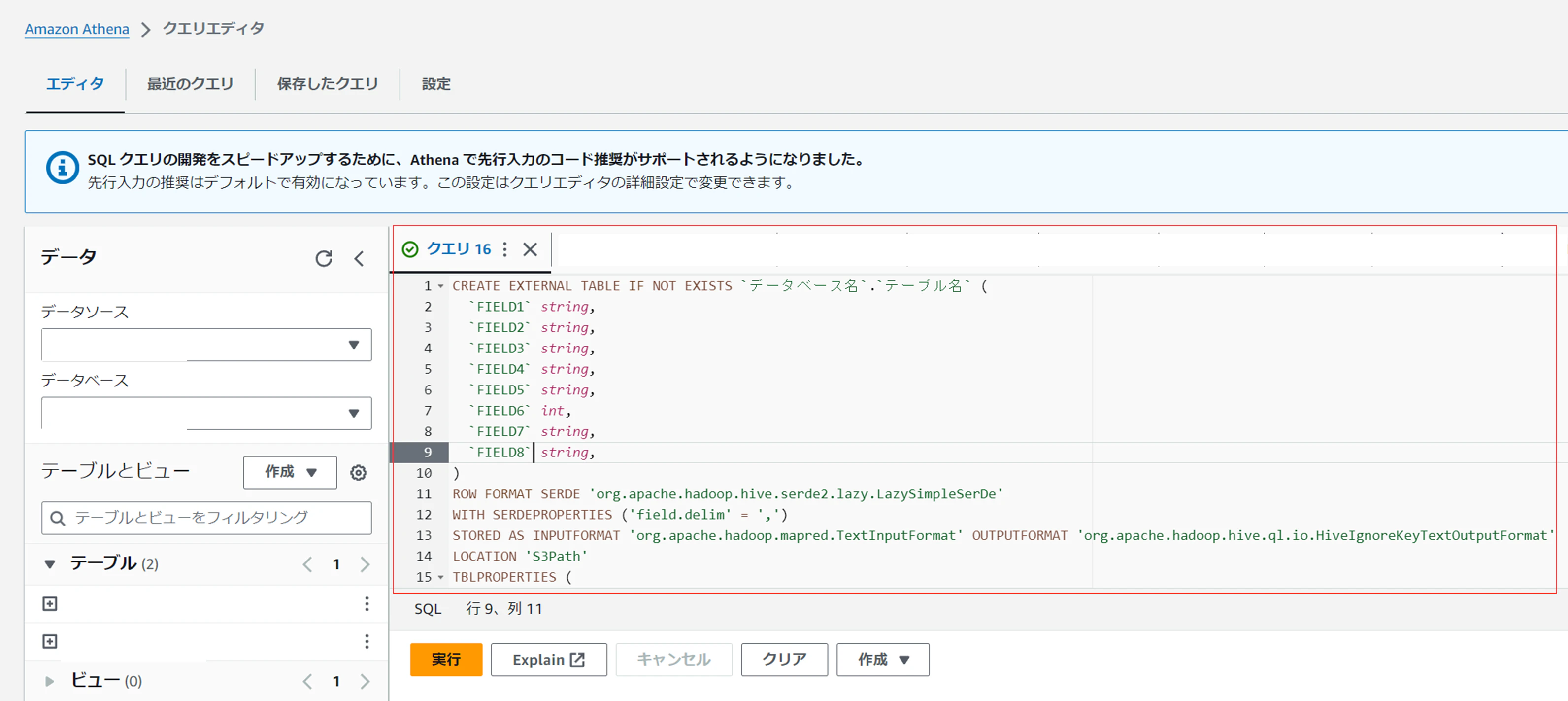
テーブル作成
AthenaはSQLでクエリを作成するのですが、下記のような形式で記載します。
CREATE EXTERNAL TABLE IF NOT EXISTS `データベース名`.`テーブル名` (
`FIELD1` string,
`FIELD2` string,
`FIELD3` string,
`FIELD4` string,
`FIELD5` string,
`FIELD6` int,
`FIELD7` string,
`FIELD8` string,
)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe'
WITH SERDEPROPERTIES ('field.delim' = ',')
STORED AS INPUTFORMAT 'org.apache.hadoop.mapred.TextInputFormat'
OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION 'S3Path'
TBLPROPERTIES (
'classification' = 'csv'
, 'skip.header.line.count'='1'
);
CREATE EXTERNAL TABLE IF NOT EXISTS
外部テーブルを作成するときの構文で、EXTERNALは外部を指します。
IF NOT EXISTSは作成済のテーブルを作ろうとするエラーを防げます。
FIELED1~FIELD8は列名を指して、string、intは列の型を指定します。
CREATE EXTERNAL TABLE IF NOT EXISTS `データベース名`.`テーブル名` (
`FIELD1` string,
`FIELD2` string,
`FIELD3` string,
`FIELD4` string,
`FIELD5` string,
`FIELD6` int,
`FIELD7` string,
`FIELD8` string,
)
ROW FORMAT SERDE
SERDE(シリアライザー/デシリアライザー)はAthenaが読み込んだデータを取り扱う際のルールらしいです。
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe'
WITH SERDEPROPERTIES
データの読み書きに関する詳細を定義できるらしいです。
'field.delim' = ','はファイルを読み込む際の区切り文字をカンマに指定できます。
WITH SERDEPROPERTIES ('field.delim' = ',')
STORED AS
テーブルのファイル形式を指定します。
STORED AS INPUTFORMAT 'org.apache.hadoop.mapred.TextInputFormat'
OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION
テーブルのを作成するもとのデータがあるS3の場所を指定します。
LOCATION 'S3Path'
TBLPROPERTIES
'classification' = 'csv'はファイルの種類を指して
'skip.header.line.count'='1'はヘッダー行1行をスキップして読み飛ばします。
TBLPROPERTIES (
'classification' = 'csv'
, 'skip.header.line.count'='1'
);
最後までお読みいただきありがとうございます。