はじめに
マイクロサービスについてオライリーの マイクロサービスアーキテクチャ (以降「書籍」と呼ぶ)をもとに学習しているが、実際に自分でアウトプットしないとイメージが湧かないよねってことで
-
簡単なモノリスアプリケーションを用意する。
-
書籍で紹介されている考え方に沿って、 1 で用意したモノリスアプリをマイクロサービス化する。
という流れを体験してみた。
ただしデプロイやセキュリティなどは本記事の対象外とする(用意したのは単なるサンプルアプリでありデプロイする意図がないこと、また、動作確認の環境はローカル環境でセキュリティについて検討する必要がないため)。
サンプルアプリ
コードは Bitbucket に置いてある。
動作を確認した環境は以下の通り。
-
Mac
- macOS Mojave 10.14.6
-
Java
$ java --version openjdk 12.0.1 2019-04-16 OpenJDK Runtime Environment (build 12.0.1+12) OpenJDK 64-Bit Server VM (build 12.0.1+12, mixed mode, sharing) -
Gradle
$ ./gradlew --version --- Gradle 5.6.2 Build time: 2019-09-05 16:13:54 UTC Revision: 55a5e53d855db8fc7b0e494412fc624051a8e781 Kotlin: 1.3.41 Groovy: 2.5.4 Ant: Apache Ant(TM) version 1.9.14 compiled on March 12 2019 JVM: 12.0.1 (Oracle Corporation 12.0.1+12) OS: Mac OS X 10.14.6 x86_64
サンプルアプリの概要
ドメインモデル
サンプルアプリは エリックエヴァンスのドメイン駆動設計 で紹介されているレイヤー化アーキテクチャを採用している。ここではその中のドメイン層のみモデルを示す。
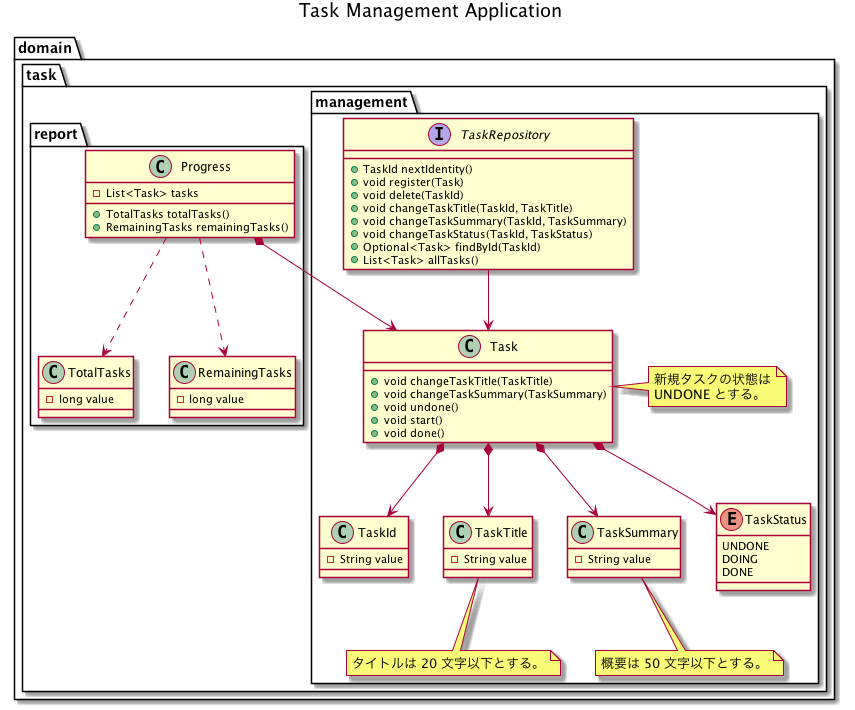
最初に言い訳をしておくと、本モデルには以下のようなイケていない部分がある(イケてないと知りつつも、面倒になって手を抜いてしまった)。
-
Taskクラスがイミュータブルじゃない。- 弊社では基本的にイミュータブルにすることになっている。
-
リポジトリのメソッド名に業務知識が反映されていない。
-
Taskクラスと同様にTaskRepository#changeTaskStatusをTaskRepository#undoneなどのようにすべき。
-
-
managementとreportでTaskクラスが共有されている。-
reportではTaskIdなどが不要なため別の型としてモデリングすべき。
-
タスク管理コンテキスト
-
ドメインモデルの
managementパッケージが属するコンテキストの呼び名。 -
タスクを登録、更新、削除する機能を提供する。
レポートコンテキスト
-
ドメインモデルの
reportパッケージが属するコンテキスの呼び名。 -
登録したタスクの内、残タスク数(
RemainingTasks)と全タスク数(TotalTasks)を算出する。- 残タスク数はタスク状態が
UNDONEまたはDOINGのタスクの総数である。 - 全タスク数は登録したタスクの総数である(タスク状態は関係ない)。
- 残タスク数はタスク状態が
サンプルアプリの動かし方
アプリの動作確認には curl を使うので、インストールがまだの方はインストールをすること(UI を用意するのが面倒だったため手抜きをした)。
アプリの起動
clone したディレクトリに移動し、以下のコマンドを実行する。
$ ./gradlew bootRun
タスクの登録
$ curl -D - -H "Content-type: application/json" -X POST -d '{"title":"タスクタイトル", "summary":"タスクサマリー"}' http://localhost:8080/task/management/register
'{"title":"タスクタイトル", "summary":"タスクサマリー"}' の値の部分は好きな値を設定できる。ただし title は 20 文字以下、 summary は 50 文字以下である必要がある。
登録したタスクの確認
$ curl http://localhost:8080/task/management/tasks
タスクタイトルの変更
$ curl -D - -H "Content-type: application/json" -X PUT -d '{"title":"新規タスクタイトル"}' http://localhost:8080/task/management/changeTaskTitle/<taskId>
<taskId> の部分はタイトルを変更したいタスクの ID を指定すること。タスク ID は 登録したタスクの確認 で紹介したコマンドで調べる。
タスクサマリーの変更
$ curl -D - -H "Content-type: application/json" -X PUT -d '{"summary":"新規タスクサマリー"}' http://localhost:8080/task/management/changeTaskSummary/<taskId>
<taskId> の部分はタイトルを変更したいタスクの ID を指定すること。タスク ID は 登録したタスクの確認 で紹介したコマンドで調べる。
タスク状態の変更
$ curl -D - -H "Content-type: application/json" -X PUT -d '{"taskStatus":1}' http://localhost:8080/task/management/changeTaskStatus/<taskId>
'{"taskStatus":1}' の値には 0, 1, 2 のいずれかの値を指定する。ちなみに 0 は未実施、1 は実施中、2 は実施済である。
また <taskId> の部分はタイトルを変更したいタスクの ID を指定すること。タスク ID は 登録したタスクの確認 で紹介したコマンドで調べる。
進捗の確認
$ curl http://localhost:8080/task/report/progress
残タスクの数と、全タスクの数を表示する。
マイクロサービスとは
マイクロサービスについては書籍で以下のように説明されている。
マイクロサービスとは、ThoughtWorks 社のマーチン・ファウラーとジェームス・ルイスが最初に提唱したソフトウェアアーキテクチャです。モノリシック(一枚岩)なアーキテクチャを、ビジネス機能に沿って複数の小さい「マイクロサービス」に分割し、それらを連携させるアーキテクチャにすることで、迅速なデプロイ、優れた回復性やスケーラビリティといった利点を実現しようとするものです。
モノリスなシステムを修正する際はサーバーの停止・再ビルド・再配備が必要となるため、システム担当者間でシステムへの影響確認や停止タイミングの調整が必要となる。マイクロサービスアーキテクチャを採用すると各マイクロサービスは独立しているため、このような調整作業が不要になるといったメリットがある。
個人的にはこの デプロイの容易性 がマイクロサービス化により得られる最大のメリットであると思っているが、書籍ではマイクロサービス化するメリットについて他にも以下が挙げられている。
| メリット | 説明 |
|---|---|
| 技術的特異性 | マイクロサービスごとに好きな技術を選ぶことができる。 |
| 回復性 | あるマイクロサービスに障害が発生しても、他のマイクロサービスは機能し続けることができる。 |
| スケーリング | スケーリングが必要なマイクロサービスのみをスケーリングできる。 |
| 組織面の一致 | あるマイクロサービスを開発する者達を同じ組織に配置させることで組織間のやり取りがなくなり、開発がスムーズになる( コンウェイの法則 )。コンウェイの法則については後述する。 |
| 合成可能性 | マイクロサービスでは様々な機能を目的に応じた方法で利用できる。もちろん機能を提供する口を用意してあるモノリスなシステムもあるが、その粒度は大抵荒く、使い勝手が悪いことが多い。 |
| 交換可能にするための最適化 | (モノリスなシステムと比べて)マイクロサービスは規模が小さいため、リファクタリングやリプレースするコストが管理しやすい。 |
マイクロサービス化するメリットを理解できただろうか?以降ではあらかじめ用意したサンプルアプリを順を追ってマイクロサービス化していく。
マイクロサービスの単位を決める
マイクロサービス化する際の課題の一つが適切なサービス境界を決めることだろう。マイクロサービスの規模が小さすぎるとサービス間の結びつきが強くなりマイクロサービス化のメリットを享受できないし、大きすぎても同じくメリットを享受できない。
書籍ではマイクロサービスの境界を定める際の大原則として 疎結合 と 高凝集 という 2 つの概念を挙げている。つまり関連する振る舞いが 1 つのマイクロサービスに存在し、他の境界との通信ができる限り発生しないで済むように境界を定めるべきということである。
そのような境界を探すツールとして『エリックエヴァンスのドメイン駆動設計』で導入された 境界づけられたコンテキスト がある(境界づけられたコンテキストについて知りたい方は 境界付けられたコンテキスト 概念編 - ドメイン駆動設計用語解説 を参照のこと)。
ただし境界づけられたコンテキストを見つけるには深い業務知識が必要になるため、新規システム開発にマイクロサービスアーキテクチャを採用すると失敗する可能性が高くなる。実際に書籍でも ThoughtWorks 社の失敗事例を挙げて、最初はモノリシックなシステムを構築し、業務に対する理解が深まってきたらマイクロサービス化する方法を推奨している。
(ThoughtWorks 社で新規開発するツールをマイクロサービスで開発したが、途中で 1 つのモノリシックシステムにマージし、業務に対する理解が深まってから再度マイクロサービス化したら綺麗に分割できたというエピソードを受けて)このような状況を目にしたのはこの例だけではありません。特に初めてのドメインでは、システムをマイクロサービスに分解するのが時期尚早だとコストがかかってしまう場合があります。いろいろな意味で、マイクロサービスに分解したい既存のコードベースがある方が、最初からマイクロサービスに取り組むよりもはるかに簡単です。
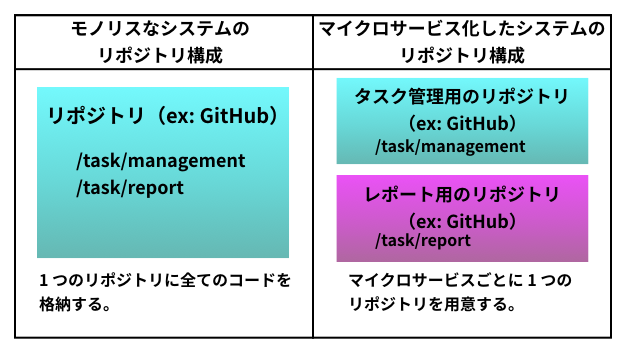
今回のサンプルアプリはあらかじめドメイン駆動設計の考えに従い設計・実装をしてあるため、既に 2 つの境界づけられたコンテキストに分かれている。 タスク管理コンテキスト と レポートコンテキスト である。今回はこの 2 つのコンテキストをマイクロサービスにする。
「マイクロサービスにする」と言っても特に難しい作業は発生せず、リポジトリ構成が以下のように変更になるだけである。
コンウェイの法則
本記事では境界づけられたコンテキストに沿ってサービスの境界を定めたが、他にも コンウェイの法則 に従う方法もある。コンウェイの法則とは 1968 年 4 月に発表された Melvin Conway(メルヴィン・コンウェイ)の論文 で述べられている下記記述のことである。
システム(ここでは単なる情報システムよりも広く定義されたシステム)を設計するあらゆる組織は、必ずその組織のコミュニケーション構造に倣った構造を持つ設計を生み出す。
噛み砕いて言えば 組織構造とソフトウェアアーキテクチャには密接な関係があるので、組織の構造に従ってサービス境界を定めるべし ということである。ちなみにこの逆(アーキテクチャに従い組織構造を変更すること)を逆コンウェイの法則と呼ぶ。
マイクロサービス化したリポジトリ
マイクロサービスの統合方法を決める
続いて、分割したマイクロサービス同士の統合(連携の仕方)について検討していこう。現状は 2 つのコンテキストで 1 つのデータベースを参照している。
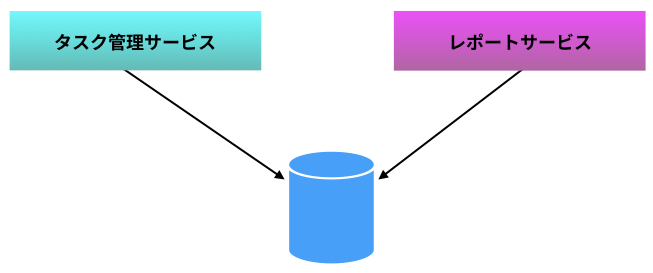
このように 1 つのデータベースを複数のマイクロサービスが参照するパターンを書籍では 共有データベース と呼び、アンチパターンとされている。タスク管理サービスの都合でデータ構造を変更する場合、関係のないはずのレポートサービスに影響が出る(マイクロサービス設計の原則 高凝集 と 疎結合 に反する)ためである。
そこで次のように参照するデータベースを分離する。

この構成にすることで、各マイクロサービスは他のマイクロサービスのことを気にせずデータ構造の変更などをすることができるようになる(つまりマイクロサービスの独立性が上がる)。
これでめでたしめでたし...ではなくて、新たにタスク管理サービスとレポートサービスのデータベースの同期をどのように取るか?という課題が生じる。
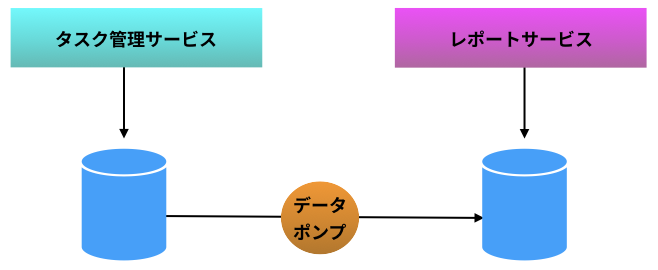
データポンプを利用する
この課題への対策案の 1 つとして、タスク管理サービスのデータベースが保持するデータを、定期的にレポートサービスに流すという案がある。この仕組みを データポンプ と呼ぶ。データポンプ自体は Cron で起動されるような簡単なプログラムである。
ただし、この手法には以下のような問題がある。
-
データポンプの開発者にはタスク管理サービスとレポートサービスが所有するデータベースについての深い知識が要求される。つまりマイクロサービスの独立性が損なわれてしまう。
-
リアルタイムにデータを同期することができない。
もし上記の問題を許容できない場合は イベントデータポンプ という手法が有効である。
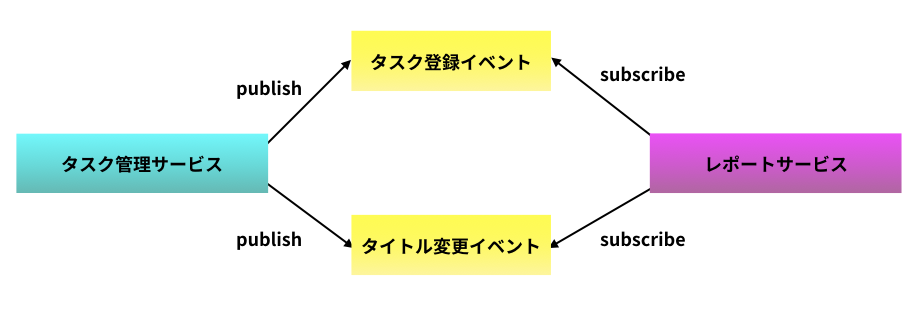
タスク管理サービスがタスク登録イベントやタイトル変更イベントなどの状態変化に関するイベントを publish し、レポートサービスがそれらイベントを subscribe する。イベントデータポンプは他サービスの内部詳細を知らずに済むので、マイクロサービス同士の結合を(データポンプと比べて)弱めることができる。
タスク管理サービスの公開 API を利用する
レポートサービスではデータベースを所有せず、タスク管理サービスが公開している API 経由で都度タスク管理サービスに問い合わせるという案もある。
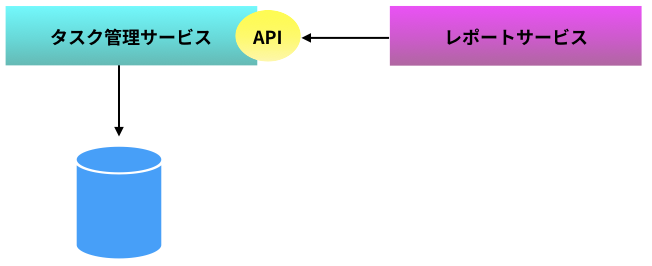
問い合わせた結果返ってくるデータ量(全タスク数)が少なく通信コストがかからない場合や、問い合わせ頻度が少ないなどの場合はわざわざデータポンプを作成せず、この手法で十分かもしれない。
今回は公開 API 経由で都度データを取得するで問題ないため、REST 通信で問い合わせることにする。
障害に備える
進捗を確認したい場合、レポートサービスからタスク管理サービスにネットワーク越しの問い合わせが発生する。つまりネットワーク障害が発生していた場合、この問い合わせは失敗する。ネットワーク障害に限らず、タスク管理サービスがメンテナンス中でサービスが停止していた場合も失敗する。
つまりマイクロサービスアーキテクチャを採用する場合は、サービス間通信が失敗する可能性をあらかじめ考慮に入れて設計する必要があるのだ。
サーキットブレーカーを導入する
サーキットブレーカーとは、「下流サービスの呼び出しが一定回数失敗したらその呼び出しを停止する(下流サービスが復旧したかをチェックし、復旧したら自動的に再開する)」仕組みのことである。
例えば今回の場合、ユーザがレポートサービスに進捗を問い合わせると、レポートサービスはタスク管理サービスからタスク一覧を取得する。もしこのタスク一覧を取得する API 呼び出しが何らかの理由で失敗したとする(下図)。
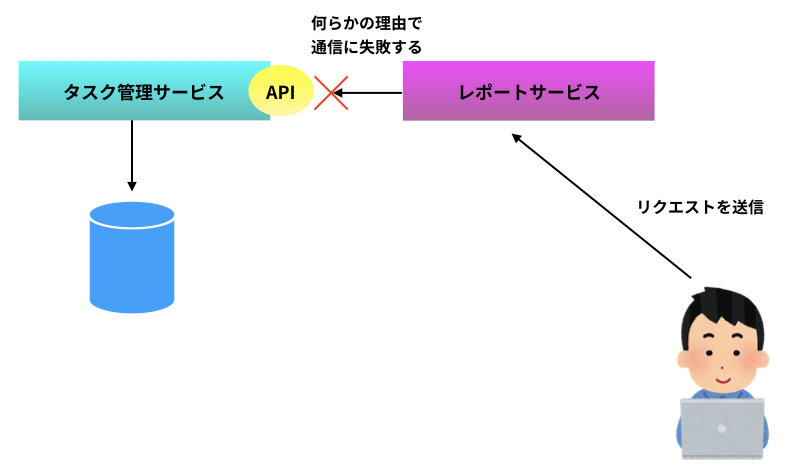
API 呼び出しが一定回数失敗した場合、レポートサービスはタスク管理サービスへの通信をやめ、あらかじめ決められたエラー処理の実行結果をユーザに返す(下図)。この状態を「サーキットブレーカーが落ちる」と呼ぶ。
サンプルではサーキットブレーカーが落ちた場合、ログを出力してデフォルトの進捗値(残タスク数・全タスク数が共に 0 の進捗値)を返す。
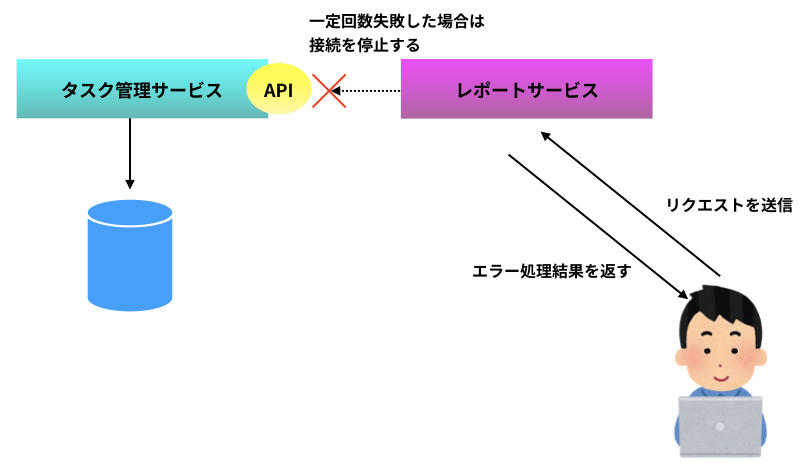
サーキットブレーカーが落ちた場合、ときどき健全性チェックを行い、タスク管理サービスとの通信が回復するとタスク管理サービスから取得した値をユーザに返すようになる(下図)。
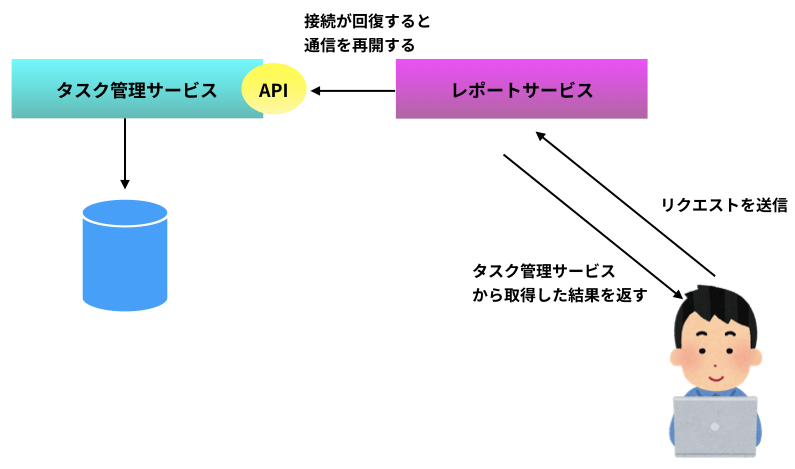
サーキットブレーカーについての説明は以上である。サーキットブレーカーの機能は一から実装する必要はなく、例えば Java での開発の場合は Hystrix というライブラリを利用すると簡単に実装できる。
@Service
@AllArgsConstructor
public class TaskReportService {
@Autowired private final RestComponent restComponent;
private static final Logger logger = LogManager.getLogger(TaskReportService.class);
@HystrixCommand(
fallbackMethod = "executeFallback",
commandProperties = {
@HystrixProperty(name = "execution.timeout.enabled", value = "true"),
@HystrixProperty(name = "execution.isolation.thread.timeoutInMilliseconds", value = "5000"),
@HystrixProperty(name = "circuitBreaker.requestVolumeThreshold", value = "5")
})
public Progress getProgress() {
// タスク管理サービスからタスク一覧を取得して進捗を Controller に返す処理(省略)
}
// タスク管理サービスと通信できない場合のエラー処理
private Progress executeFallback(Throwable throwable) {
logger.error(throwable.getMessage());
return new Progress(Collections.emptyList());
}
}
@HystrixCommand で指定している内容は以下の通り。
-
タスク管理サービスとの通信タイムアウトを有効化する(
execution.timeout.enabledをtrueにする)。 -
通信タイムアウト時間を 5000 ミリ秒にする(
execution.isolation.thread.timeoutInMillisecondsを5000にする)。 -
閾値を 5 回にする(
circuitBreaker.requestVolumeThresholdを5にする)。 -
タスク管理サービスとの通信タイムアウトが 5 回発生した場合に実行するエラー処理メソッドを指定する(
fallbackMethodをexecuteFallbackにする)。
ログ環境を構築する
今回は 1 つのホスト上で 2 つのマイクロサービスを稼働させるが、通常マイクロサービス化する場合は 1 つのホスト上で稼働させるマイクロサービスは 1 つにする。
サービスの状態確認やエラー解析のためにログを確認したい場合、各ホストに SSH して確認...では大変である(各サービスのログを集めて時系列に並べる必要があるため)。そこで Logstash を使い各マイクロサービスが出力するログを下流システム(今回は Elasticsearch を利用)に送る。また Elasticsearch に送ったログをリアルタイムで閲覧するために Kibana を使う。この構成を各システムの頭文字を取って ELK と呼ぶ。
ELK の環境構築
yaml ファイルの格納場所は各自の環境によって異なる可能性があるので、適宜読み替えること。
Elasticsearch をインストールする
まずは下記コマンドにて Elasticsearch をインストールする。
$ brew install elasticsearch
インストールが完了したら /usr/local/etc/elasticsearch/elasticsearch.yml を以下のように編集する。
#
# Set the bind address to a specific IP (IPv4 or IPv6):
#
network.host: localhost
Elasticsearch は以下のコマンドで実行する。
$ elasticsearch
Logstash をインストールする
続いて下記コマンドにて Logstash をインストールする。
$ brew install logstash
インストールが完了したら /usr/local/etc/logstash/logstash-sample.conf を以下のように編集する( file の path/to/log/file にはレポートサービスのログ出力先を指定する)。
# Sample Logstash configuration for creating a simple
# Beats -> Logstash -> Elasticsearch pipeline.
input {
file{
path => "path/to/log/file"
start_position => "beginning"
sincedb_path => "/dev/null"
}
}
output {
elasticsearch {
hosts => ["http://localhost:9200"]
}
}
Logstash は以下のコマンドで実行する。
$ sudo logstash -f /usr/local/etc/logstash/logstash-sample.conf
Kibana をインストールする
最後に下記コマンドにて Kibana をインストールする。
$ brew install kibana
インストールが完了したら /usr/local/etc/kibana/kibana.yml を以下のように編集する。
# Specifies the address to which the Kibana server will bind. IP addresses and host names are both valid values.
# The default is 'localhost', which usually means remote machines will not be able to connect.
# To allow connections from remote users, set this parameter to a non-loopback address.
server.host: "localhost"
(中略)
# The URLs of the Elasticsearch instances to use for all your queries.
elasticsearch.hosts: ["http://localhost:9200"]
Kibana は以下のコマンドで実行する。
$ kibana
以上で ELK の環境構築は完了である。
マイクロサービスの動作確認
以上でサンプルアプリをマイクロサービス化する作業は完了である。実際にマイクロサービスを動かしてみよう。
タスク管理サービスの起動
以下 3 つのコマンドを順に入力する。タスク管理サービスのポート番号は 8080 である。
$ git clone https://MasayaMizuhara@bitbucket.org/MasayaMizuhara/taskmanagement.git
$ cd taskmanagement
$ ./gradlew bootRun
レポートサービスの起動
以下 3 つのコマンドを順に入力する。レポートサービスのポート番号は 8082 である。
$ git clone https://MasayaMizuhara@bitbucket.org/MasayaMizuhara/taskreport.git
$ cd taskreport
$ ./gradlew bootRun
Elasticsearch の起動
以下のコマンドを実行する。
$ elasticsearch
Logstash の起動
以下のコマンドを実行する。設定ファイルの場所と名前は各自の環境に応じて変更すること。
$ sudo logstash -f /usr/local/etc/logstash/logstash-sample.conf
Kibana の起動
以下のコマンドを実行する。
$ kibana
タスクの登録
以下のコマンドを実行してタスク管理サービスにタスクを登録する。
$ curl -D - -H "Content-type: application/json" -X POST -d '{"title":"タスクタイトル", "summary":"タスクサマリー"}' http://localhost:8080/task/management/register
進捗の確認
以下のコマンドを実行してレポートシステムから進捗を取得する。
$ curl http://localhost:8082/task/report/progress
ログの確認
タスク管理サービスを停止させた状態で再び進捗を確認するコマンドを実行する。
$ curl http://localhost:8082/task/report/progress
上記コマンドを 6 回連続で実行した後にログを確認すると、下記ログが出力されていることを確認できる。
08:16:40.335 [http-nio-8082-exec-6] ERROR com.example.taskreport.application.TaskReportService - Hystrix circuit short-circuited and is OPEN
これは、レポートサービスとタスク管理サービスの間で接続が確認できず、サーキットブレーカーが落ちた状態に相当する。
ブラウザから Kibana にアクセスして、以下の操作を実施する。
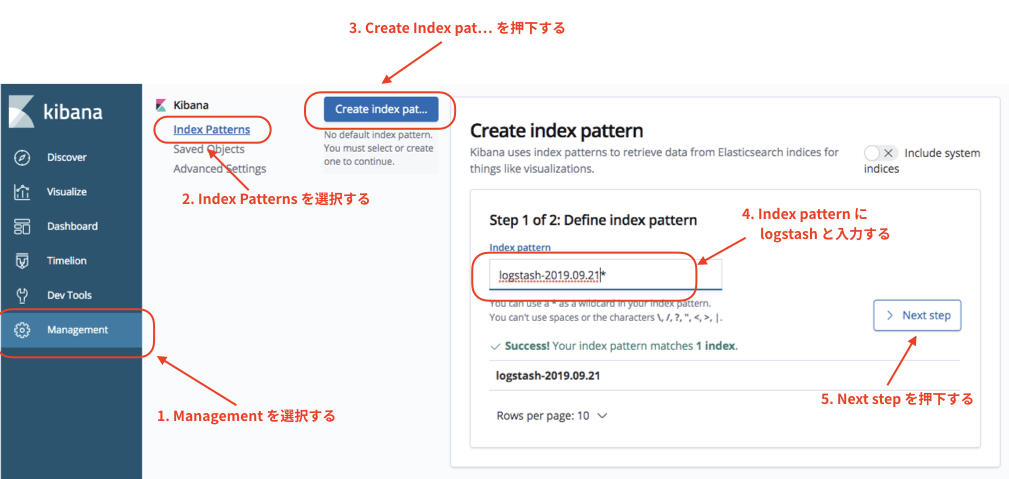
続いて以下の操作を実施する。
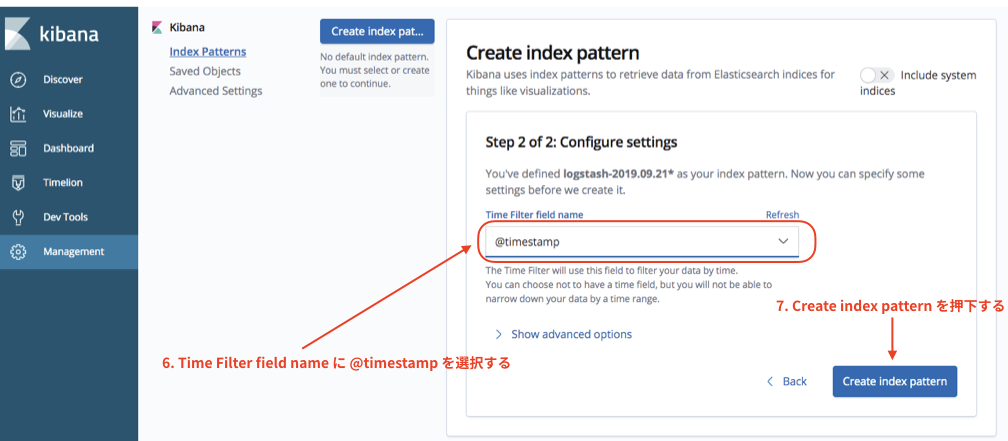
これで Index pattern の作成は完了である。左メニューにある Discover を選択するとログが出力されていることが確認できる。
まとめ
本記事では簡単なモノリスアプリを用意し、書籍で紹介されている考え方に沿ってマイクロサービス化した。今回はマイクロサービスの数も少なく規模が小さいものであるためそこまで煩雑にはならなかった(イベントデータポンプの導入を見送るなどができた)が、書籍で紹介されていた オンラインファッション小売業者の Gilt のような 450 を超えるマイクロサービスが稼働する環境ではデプロイ容易性などのメリットが得られる一方で、アーキテクチャが複雑になるというデメリットに向き合う必要が出てくる。
サービスの境界の定め方でマイクロサービス間の連携方法が変わってくるので、マイクロサービス化を成功させるためにはサービス境界を適切に定め、マイクロサービス間の連携をなるべく単純に保つことが大事である。