目的
-
shapを使用して、学習時や推論時に寄与度の高かった項目を可視化する
ライブラリ
| 項目 | 情報 |
|---|---|
| shap | 0.41.0 |
| lightgbm | 3.3.2 |
| matplotlib | 3.4.3 |
SHAPとは
ChatGPTに聞いてみました。
SHAP(SHapley Additive exPlanations)は、機械学習モデルの予測結果に対する特徴量の寄与を説明するための手法です。
SHAPは、ゲーム理論に基づくシャプレー値を用いて、機械学習モデルの特徴量が予測結果に与える影響を定量的に評価することができます。
Pythonでは、shapライブラリを使って、様々な機械学習モデル(例えば、決定木、ランダムフォレスト、勾配ブースティングマシン、ニューラルネットワークなど)のSHAP値を計算することができます。
shapライブラリを用いると、モデルの予測結果に対する特徴量の重要度を可視化し、モデルの解釈性を向上させることができます。
実際のソースコード
事前準備からモデル作成まで
import
shapのインストールやグラフを表示するための設定を行います。
# 必要なライブラリのimport
import pandas as pd
import numpy as np
import lightgbm as lgb
from sklearn import datasets
from sklearn.model_selection import train_test_split
from matplotlib import pyplot as plt
import shap
%matplotlib inline
shap.initjs()
学習データを準備
今回はscikit-learnで準備されている乳がんの診察データを使用して2値分類を行います。
正解ラベルが0の場合は悪性腫瘍、1の場合は良性腫瘍となります。
# 学習データを準備
bc = datasets.load_breast_cancer()
df_feature = pd.DataFrame(bc.data, columns=bc.feature_names)
target = pd.Series(bc.target)
X_train, X_test, y_train, y_test = train_test_split(
df_feature,
target,
stratify=target,
shuffle=True,
random_state=123
)
lgb_train = lgb.Dataset(X_train, y_train)
lgb_test = lgb.Dataset(X_test, y_test, reference=lgb_train)
モデル作成
今回使用するモデルはLightGBMです。
# モデル作成
params = {'boosting_type': 'gbdt',
'objective': 'binary',
'num_iteration': 100}
model = lgb.train(
params=params,
train_set=lgb_train,
valid_sets=[lgb_train, lgb_test]
)
学習時のSHAP情報を出力
準備
shap.TreeExplainerに作成したモデルと学習データを渡すことでSHAP値に関する情報を取得します。(shap_values)
explainer = shap.TreeExplainer(model, data=X_train)
shap_values = explainer.shap_values(X_train)
summary_plot
まずはどの項目が一番影響していたかを確認します。
shap.summary_plot(
shap_values=shap_values,
features=X_train,
feature_names=X_train.columns,
plot_type='bar'
)

今回のデータだと、worst perimeterという項目の寄与度が1番高いということが分かります。
続いて、各項目が悪性及び良性腫瘍の判断にどのように寄与していたかを確認します。
shap.summary_plot(
shap_values=shap_values,
features=X_train,
feature_names=X_train.columns
)

例えば、worst concave pointsという項目が大きい値の場合、SHAP値がマイナスであり悪性腫瘍と判断される傾向にある反面、データのボリュームゾーンはSHAP値プラス側にあるということが分かります。
推論時のSHAP情報を出力
今回は、事前にテストデータのインデックスをリセットしておきます。
X_test = X_test.reset_index(drop=True)
準備
学習時と同様に、推論時のSHAP情報を取得します。
explainer = shap.Explainer(model)
shap_values = explainer(X_test)
waterfall_plot
各推論データで、各項目のshap値がどのようになっていたかを確認します。
def draw_waterfall_plot(df, model, shap_values, index):
row = df.iloc[index]
predicted_value = model.predict(row.values.reshape(1, -1))[0]
predicted_class = int(predicted_value > 0.5)
shap.plots.waterfall(shap_values[index, :, 1])
draw_waterfall_plot(X_test, model, shap_values, 140)
draw_waterfall_plot(X_test, model, shap_values, 141)
140行目の出力結果(0: 悪性腫瘍)

141行目の出力結果(1: 良性腫瘍)
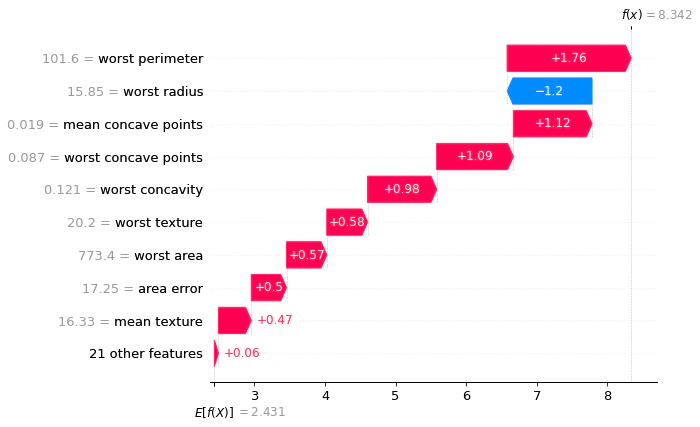
waterfall_plotを確認することで、それぞれの項目がプラスとマイナスどちら側に効いていたかを確認することが可能です。
高寄与度項目の確認
各行で寄与度がプラスとマイナスにそれぞれ大きかった項目TOP3を確認します。
top_n = 3 # 高寄与度項目の数
high_contrib_data = []
low_contrib_data = []
for test_sample_idx in range(len(X_test)):
test_sample = X_test.iloc[test_sample_idx]
predicted_value = model.predict(test_sample.values.reshape(1, -1))[0]
contributions = pd.DataFrame(
shap_values.values[test_sample_idx, :, 1],
index=df_feature.columns,
columns=["SHAP"],
).sort_values(by="SHAP", ascending=False)
top_contrib = contributions.head(top_n)
features_shap_values = [item for pair in zip(top_contrib.index.tolist(), top_contrib["SHAP"].tolist()) for item in pair]
high_contrib_data.append(features_shap_values)
contributions = contributions.sort_values(by="SHAP", ascending=True)
top_contrib = contributions.head(top_n)
features_shap_values = [item for pair in zip(top_contrib.index.tolist(), top_contrib["SHAP"].tolist()) for item in pair]
low_contrib_data.append(features_shap_values)
# 高寄与度項目とSHAP値をデータフレームにまとめる
column_names = [f"プラス_Top{int((i)/2+1)}" if (j+1) % 2 == 1 else f"プラスTop{i//2+1}_value" for j, i in enumerate(range(0, 2 * top_n))]
df_high_contrib = pd.DataFrame(high_contrib_data, columns=column_names)
column_names = [f"マイナス_Top{int((i)/2+1)}" if (j+1) % 2 == 1 else f"マイナスTop{i//2+1}_value" for j, i in enumerate(range(0, 2 * top_n))]
df_low_contrib = pd.DataFrame(low_contrib_data, columns=column_names)
df_pred_shap = pd.concat(
[pd.DataFrame({"index": X_test.index, "pred": model.predict(X_test)}), df_high_contrib, df_low_contrib], axis=1
)
display(df_pred_shap)
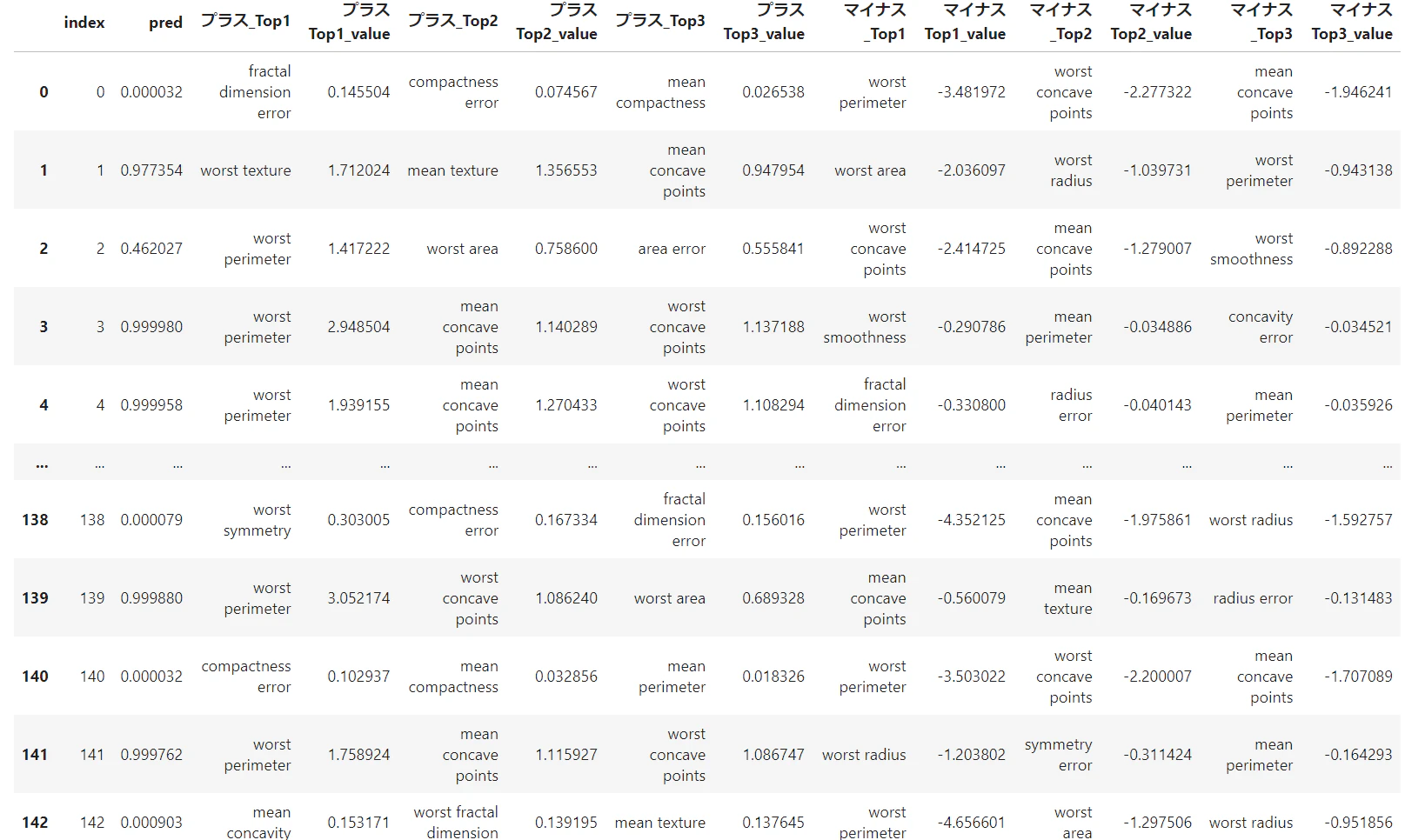
このように、推論スコアと合わせて高寄与度項目を出力することで、AIの推論結果に対する信憑性・妥当性を上げることが可能です。
まとめ
今回はshapライブラリを使用してAIに寄与している項目の可視化を行いました。shapには他にも様々な機能があるので興味のある方はぜひ調べてみてください。