はじめに
Pythonもなにもかも初心者。。。
機械学習のために画像を大量にとるってどうやるのー!?!って思ってたらスクレイピングとかいう便利なものがありました!!!
でも、GoogleAPI???的なものはわけがわからず断念!!
粘っていたらGoogleAPI使わなくても出きるっぽいサイトをみつけたんです!
↓神サイト(本当に助かりました)
・PythonスクレイピングでGoogle画像検索ページから画像を取得
chromedriverをインストール
まず、chromedriverをインストールから始めました!
このサイトの通りやったらできました!
・ChromeDriverをwindows10でインストールする方法
他のサイトは環境変数のやり方とか書いて無くてわかんなかったです。。。
スクレイピング開始!
この ・PythonスクレイピングでGoogle画像検索ページから画像を取得 サイトからコピペしてきたら謎の赤い文字になってしまいました…。
ただのコメントなのになんだろう?

訳はわからないけど、まあ改行とか消せば直ると思って適当にやったら直りました!やったー!
import requests
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
import os
import time
import datetime
from selenium.common.exceptions import NoSuchElementException
from selenium.common.exceptions import ElementClickInterceptedException
tm_start = time.time() # 処理時間計測用
dt_now = datetime.datetime.now() # 現在日時
dt_date_str = dt_now.strftime('%Y/%m/%d %H:%M')
print(dt_date_str)
QUERY = '渚カヲル' # 検索ワード
LIMIT_DL_NUM = 300 # ダウンロード数の上限
SAVE_DIR = 'output_scraping/eva_kaworu' # 出力フォルダへのパス(フォルダがない場合は自動生成する)
FILE_NAME = '00' # ファイル名(ファイル名の後ろに0からの連番と拡張子が付く)
TIMEOUT = 60 # 要素検索のタイムアウト(秒)
ACCESS_WAIT = 1 # アクセスする間隔(秒)
RETRY_NUM = 3 # リトライ回数(クリック、requests)
DRIVER_PATH = 'C:\Program Files/chromedriver' # chromedriver.exeへのパス
# Chromeをヘッドレスモードで起動
options = Options()
options.add_argument('--headless')
options.add_argument('--no-sandbox')
options.add_argument('--disable-dev-shm-usage')
# options.add_argument('--start-maximized')
options.add_argument('--start-fullscreen')
options.add_argument('--disable-plugins')
options.add_argument('--disable-extensions')
driver = webdriver.Chrome(DRIVER_PATH, options=options)
# タイムアウト設定
driver.implicitly_wait(TIMEOUT)
tm_driver = time.time()
print('WebDriver起動完了', f'{tm_driver - tm_start:.1f}s')
# Google画像検索ページを取得
url = f'https://www.google.com/search?q={QUERY}&tbm=isch'
driver.get(url)
tm_geturl = time.time()
print('Google画像検索ページ取得', f'{tm_geturl - tm_driver:.1f}s')
tmb_elems = driver.find_elements_by_css_selector('#islmp img')
tmb_alts = [tmb.get_attribute('alt') for tmb in tmb_elems]
count = len(tmb_alts) - tmb_alts.count('')
print(count)
while count < LIMIT_DL_NUM:
# ページの一番下へスクロールして新しいサムネイル画像を表示させる
driver.execute_script('window.scrollTo(0, document.body.scrollHeight);')
time.sleep(1)
# サムネイル画像取得
tmb_elems = driver.find_elements_by_css_selector('#islmp img')
tmb_alts = [tmb.get_attribute('alt') for tmb in tmb_elems]
count = len(tmb_alts) - tmb_alts.count('')
print(count)
imgframe_elem = driver.find_element_by_id('islsp')
# 出力フォルダ作成
os.makedirs(SAVE_DIR, exist_ok=True)
# HTTPヘッダ作成
HTTP_HEADERS = {'User-Agent': driver.execute_script('return navigator.userAgent;')}
print(HTTP_HEADERS)
# ダウンロード対象のファイル拡張子
IMG_EXTS = ('.jpg', '.jpeg', '.png', '.gif')
# 拡張子を取得
def get_extension(url):
url_lower = url.lower()
for img_ext in IMG_EXTS:
if img_ext in url_lower:
extension = '.jpg' if img_ext == '.jpeg' else img_ext
break
else:
extension = ''
return extension
# urlの画像を取得しファイルへ書き込む
def download_image(url, path, loop):
result = False
for i in range(loop):
try:
r = requests.get(url, headers=HTTP_HEADERS, stream=True, timeout=10)
r.raise_for_status()
with open(path, 'wb') as f:
f.write(r.content)
except requests.exceptions.SSLError:
print('***** SSL エラー')
break # リトライしない
except requests.exceptions.RequestException as e:
print(f'***** requests エラー({e}): {i + 1}/{RETRY_NUM}')
time.sleep(1)
else:
result = True
break # try成功
return result
tm_thumbnails = time.time()
print('サムネイル画像取得', f'{tm_thumbnails - tm_geturl:.1f}s')
# ダウンロード
EXCLUSION_URL = 'https://lh3.googleusercontent.com/' # 除外対象url
count = 0
url_list = []
for tmb_elem, tmb_alt in zip(tmb_elems, tmb_alts):
if tmb_alt == '':
continue
print(f'{count}: {tmb_alt}')
for i in range(RETRY_NUM):
try:
# サムネイル画像をクリック
tmb_elem.click()
except ElementClickInterceptedException:
print(f'***** click エラー: {i + 1}/{RETRY_NUM}')
driver.execute_script('arguments[0].scrollIntoView(true);', tmb_elem)
time.sleep(1)
else:
break # try成功
else:
print('***** キャンセル')
continue # リトライ失敗
# アクセス負荷軽減用のウェイト
time.sleep(ACCESS_WAIT)
alt = tmb_alt.replace("'", "\\'")
try:
img_elem = imgframe_elem.find_element_by_css_selector(f'img[alt=\'{alt}\']')
except NoSuchElementException:
print('***** img要素検索エラー')
print('***** キャンセル')
continue
# url取得
tmb_url = tmb_elem.get_attribute('src') # サムネイル画像のsrc属性値
for i in range(RETRY_NUM):
url = img_elem.get_attribute('src')
if EXCLUSION_URL in url:
print('***** 除外対象url')
url = ''
break
elif url == tmb_url: # src属性値が遷移するまでリトライ
print(f'***** urlチェック: {i + 1}/{RETRY_NUM}')
# print(f'***** {url}')
time.sleep(1)
url = ''
else:
break
if url == '':
print('***** キャンセル')
continue
# 画像を取得しファイルへ保存
ext = get_extension(url)
if ext == '':
print(f'***** urlに拡張子が含まれていないのでキャンセル')
print(f'{url}')
continue
filename = f'{FILE_NAME}{count}{ext}'
path = SAVE_DIR + '/' + filename
result = download_image(url, path, RETRY_NUM)
if result == False:
print('***** キャンセル')
continue
url_list.append(f'{filename}: {url}')
# ダウンロード数の更新と終了判定
count += 1
# print(f'\r{count}/{LIMIT_DL_NUM}', end='') # 進捗表示
if count >= LIMIT_DL_NUM:
# time.sleep(1) # 進捗表示ウェイト
# print(f'\r{" " * 7}\r', end='') # 進捗非表示
break
tm_end = time.time()
print('ダウンロード', f'{tm_end - tm_thumbnails:.1f}s')
print('------------------------------------')
total = tm_end - tm_start
total_str = f'トータル時間: {total:.1f}s({total/60:.2f}min)'
count_str = f'ダウンロード数: {count}'
print(total_str)
print(count_str)
# urlをファイルへ保存
path = SAVE_DIR + '/' + '_url.txt'
with open(path, 'w', encoding='utf-8') as f:
f.write(dt_date_str + '\n')
f.write(total_str + '\n')
f.write(count_str + '\n')
f.write('\n'.join(url_list))
driver.quit()
QUERY = '渚カヲル' # 検索ワード
検索したいこと打ち込んで
LIMIT_DL_NUM = 300 # ダウンロード数の上限
画像のダウンロード枚数指定して
(画像100枚までとかの規制無いから便利!)
SAVE_DIR = 'output_scraping/eva_kaworu' # 出力フォルダへのパス
テキトーにフォルダ名決めて
FILE_NAME = '00' # ファイル名
001.jpg、002.jpg…的な感じで名前つけて
DRIVER_PATH = 'C:\Program Files/chromedriver' # chromedriver.exeへのパス
chromedriverあるとこ指定したら
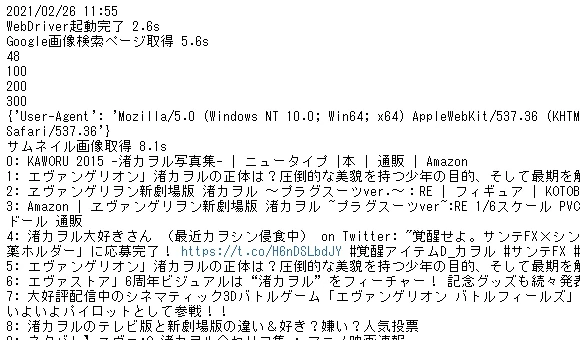
こんな感じでスクレイピングできました!!!
終わりに
初心者にはコピペでさえもなかなか難しい!!
でも、エラーが消えた時の嬉しさは半端ないのでこれからも色々やってみます!
Qiita初投稿でドキドキ…