ポケモンGOがリリースされたのでどうしてもtwitter情報を効率よく見たいと思います。
Python3でword2vecしてみて口コミデータを検索して欲しい情報にリーチしましょう。
事前準備
PythonのInstallationはこちらを参考
Mecab + neologdのInstallationはこちらを参考
- Meacabをインストール
- python3がコマンドラインで動く事を確認
- Eclipse(STS)にアドオンを追加
- pip3でモジュールインストール
- HelloWold
- Twitterで情報を取得
- トレーニングモデル作成とデータ抽出
やってみよう!
2.python3がコマンドラインで動く事を確認
[murotanimari]$ python3 --version
Python 3.5.2
[murotanimari]$ pip3 --version
pip 8.1.2 from /Library/Frameworks/Python.framework/Versions/3.5/lib/python3.5/site-packages (python 3.5)
3. Eclipse(STS)にアドオンを追加
4. pip3でモジュールインストール
pip3 install gensim
pip3 install argparse
pip3 install prettyprint
pip3 install word2vec
pip3 install print
pip3 install pp
pip3 install nltk #日本語の場合いらない
pip3 install tweepy
pip3 install scipy
# for japanese
brew install mecab
brew install mecab-ipadic
pip3 install mecab-python3
5. HelloWold
HelloWorld.py
import nltk
nltk.download('all');
import argparse
from gensim.models import word2vec
print("Hello, World!")
6. Twitterで情報を取得
ParseJP.py
# !/usr/bin/env python
# -*- coding: utf-8 -*-
import nltk
import sys
import tweepy
import json
import subprocess
import datetime
import MeCab
from tweepy.streaming import StreamListener
from tweepy import OAuthHandler
from tweepy import Stream
from numpy.core.multiarray import empty
# Variables that contains the user credentials to access Twitter API
access_token = "*****************"
access_token_secret = "*****************"
consumer_key = "*****************"
consumer_secret = "*****************"
# This is a basic listener that just prints received tweets to stdout.
class StdOutListener(StreamListener):
def on_data(self, data):
jsondata = json.loads(data)
sentence = jsondata["text"]
try:
#print(sentence)
t = MeCab.Tagger("-Ochasen")
tagged = t.parse(sentence)
#print(tagged)
out = "";
for item in tagged.split('\n'):
item = str(item).strip()
if item is '':
continue
fields = item.split("\t")
#print(fields)
found = ""
if 'EOS' not in item:
if "名詞" in fields[3]:
found = fields[2]
if "動詞" in fields[3]:
if "助動詞" not in fields[3]:
found = fields[2]
if("//" not in str(found).lower()):
if(found.lower() not in ["rt","@","sex","fuck","https","http","#",".",",","/"]):
if(len(found.strip()) != 0):
found = found.replace("'", "/'");
out += found + " "
today = datetime.date.today()
cmd = "echo '"+ out + "' >> /tmp/JP" + today.isoformat() +".txt"
#print(cmd)
subprocess.check_output(cmd, shell=True)
return True
except:
print("Unexpected error:",found, sys.exc_info()[0])
return True
def on_error(self, status):
print(status)
#### main method
if __name__ == '__main__':
#This handles Twitter authetification and the connection to Twitter Streaming API
l = StdOutListener()
auth = OAuthHandler(consumer_key, consumer_secret)
auth.set_access_token(access_token, access_token_secret)
stream = Stream(auth, l)
#This line filter Twitter Streams to capture data by the keywords: 'python', 'javascript', 'ruby'
#stream.filter(track=['#pokemongo','#PokemonGo', '#PokémonGo', '#Pokémon' ,'#Pokemon', '#pokemon'], languages=["en"])
stream.filter(track=['#ポケモン','#pokemongo','#PokemonGo', '#PokémonGo', '#Pokémon' ,'#Pokemon', '#pokemon'], languages=["ja"])
#stream.filter(track=['#pokemon'], languages=["en"])
7. トレーニングモデル作成とデータ抽出
とりあえず、コマンドラインでデータがちゃんと取れるか確認してみます。
>>> # !/usr/bin/env python
... # -*- coding:utf-8 -*-
... from gensim.models import word2vec
>>>
>>> data = word2vec.Text8Corpus('/tmp/JP2016-07-23.txt')
>>> model = word2vec.Word2Vec(data, size=200)
>>> model.most_similar(positive=u'Pokemon')
[('Pokémon', 0.49616560339927673), ('ND', 0.47942256927490234), ('妖怪ウォッチ', 0.4783376455307007), ('I', 0.44967448711395264), ('9', 0.4415249824523926), ('j', 0.4309641122817993), ('B', 0.4284788966178894), ('CX', 0.42728638648986816), ('l', 0.42639225721359253), ('bvRxC', 0.41929835081100464)]
>>>
>>> model.most_similar(positive=u'ピカチュウ')
[('SolderingArt', 0.7791135311126709), ('61', 0.7604312896728516), ('ポケットモンスター', 0.7314165830612183), ('suki', 0.7087007761001587), ('チュウ', 0.6967192888259888), ('docchi', 0.6937340497970581), ('ラテアート', 0.6864794492721558), ('EjPbfZEhIS', 0.6781727075576782), ('はんだ付け', 0.6571916341781616), ('latteart', 0.6411304473876953)]
>>>
>>> model.most_similar(positive=u'ピカチュー')
[('タバコ', 0.9689614176750183), ('作成', 0.9548219442367554), ('渋谷', 0.9207605123519897), ('EXCJ', 0.9159889221191406), ('ポイ捨て', 0.8906601667404175), ('ゴミゲット', 0.7719830274581909), ('あるある', 0.6942187547683716), ('ありがとう', 0.6873651742935181), ('お願い', 0.6714405417442322), ('GET', 0.6686745285987854)]
>>>
>>> model.most_similar(positive=u'レアポケモン')
[('表', 0.8076062202453613), ('早見', 0.8065655827522278), ('生息地', 0.7529213428497314), ('入手', 0.7382372617721558), ('最新', 0.7039971351623535), ('日本版', 0.6925774216651917), ('基地', 0.6455932855606079), ('300', 0.6433809995651245), ('YosukeYou', 0.6330702900886536), ('江ノ島', 0.6322115659713745)]
>>>
>>> model.most_similar(positive=u'大量発生')
[('区域', 0.9162761569023132), ('カオス', 0.8581807613372803), ('桜木町駅', 0.7103563547134399), ('EjPbfZEhIS', 0.702730655670166), ('大蔵', 0.6720583438873291), ('殿町', 0.6632444858551025), ('今井書店', 0.6514744758605957), ('丿', 0.6451742649078369), ('パリ', 0.6437439918518066), ('入口', 0.640221893787384)]
レアポケモンで基地とか江ノ島とか気になります!
大量発生で桜木町駅、大蔵、殿町、今井書店とか何でしょうね?
追記:おまけ
EC2にDeployでデータ処理始めました。お金ないとAPIにして公開できないですw
注: まだ精度が低いのでググッて真意を確認してね!!!!
▼ポケモン「スポット」口コミキワードランキング by twitter & word2vec
1. 錦糸公園
2. 愛知県
3. gamespark
4. 名古屋
5. 公園
6. 商店街
7. 三ヶ所
8. 大濠公園
▼ポケモン「大量発生」口コミキワードランキング by twitter & word2vec
1. ポケモンイベントコラボ
2. 桜木町駅
3. 大蔵
4. 西新宿
5. 商店街
6. パリ
7. 中央公園
8. 福島
9. 今井書店
▼ポケモン「レアポケモン」口コミキワードランキング by twitter & word2vec
1. 伝説
2. デマ
3. 生息地
4. 深夜
5. 民家
6. 東
7. ミュウツー
8. デマ情報
9. アップデート
10. 評価
11. 群馬県伊勢崎市馬見塚町
追記:neologd
https://github.com/neologd/mecab-ipadic-neologd
をよくよく読むと下記のようにinstall-mecab-ipadic-neologdで最新版をインストールできるらしい。
git clone --depth 1 https://github.com/neologd/mecab-ipadic-neologd.git
cd mecab-ipadic-neologd
/usr/local/lib/mecab/dic/mecab-ipadic-neologd
./bin/install-mecab-ipadic-neologd -n
echo `mecab-config --dicdir`"/mecab-ipadic-neologd"
vi /usr/local/etc/mecabrc
dicdir = /usr/local/lib/mecab/dic/mecab-ipadic-neologd
追記:user辞書の追加
こちらを参考にしてユーザー辞書を追加します。
駅名一覧と都内の公園とモンスター名を入れます。
cd /usr/local/lib/mecab/dic/ipadic
# add pokemon list
/usr/local/libexec/mecab/mecab-dict-index -u pokemon.dic -f utf-8 -t utf-8 /mnt/s3/resources/pokemons.csv
# add station list
/usr/local/libexec/mecab/mecab-dict-index -u station.dic -f utf-8 -t utf-8 /mnt/s3/resources/stations.csv
/usr/local/libexec/mecab/mecab-dict-index -u park.dic -f utf-8 -t utf-8 /mnt/s3/resources/park.csv
# copy into dict folder
cp pokemon.dic /usr/local/lib/mecab/dic/mecab-ipadic-neologd/
cp station.dic /usr/local/lib/mecab/dic/mecab-ipadic-neologd/
cp park.dic /usr/local/lib/mecab/dic/mecab-ipadic-neologd/
おまけ
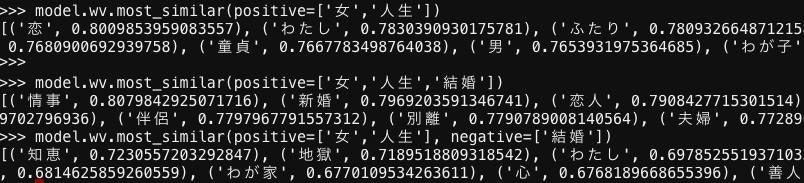
2018年にwikipediaのデータモデルで試した結果を追記しておきます。
女の人生は「恋」である
女の人生に「結婚」を足すと「情事」である
女の人生から「結婚」を引くとそれは「知恵」である
由緒正しき、WikiPediaデータ・モデルからの解答
ちなみに就活、成功、事例で検索すると六ヶ所再処理工場が出てきてしまう・・・