現在、個人開発で利用するツールとしてneo4jを使いはじめました
各種グラフアルゴリズムについて、詳しく理解できるように、説明動画などへのリンクなどをまとめています!

15 Tools for Visualizing Your Neo4j Graph Database
グラフDBって何?
グラフDB(グラフデータベース)とは、データの関係性や構造をグラフの形で表現するデータベースです。グラフ理論に基づいて、ノード(点)とエッジ(線)という概念を使用してデータを格納します。ノードはオブジェクトやエンティティ(例えば人、製品、場所など)を表し、エッジはそれらのノード間の関係(友達関係、リンク、依存関係など)を表します。
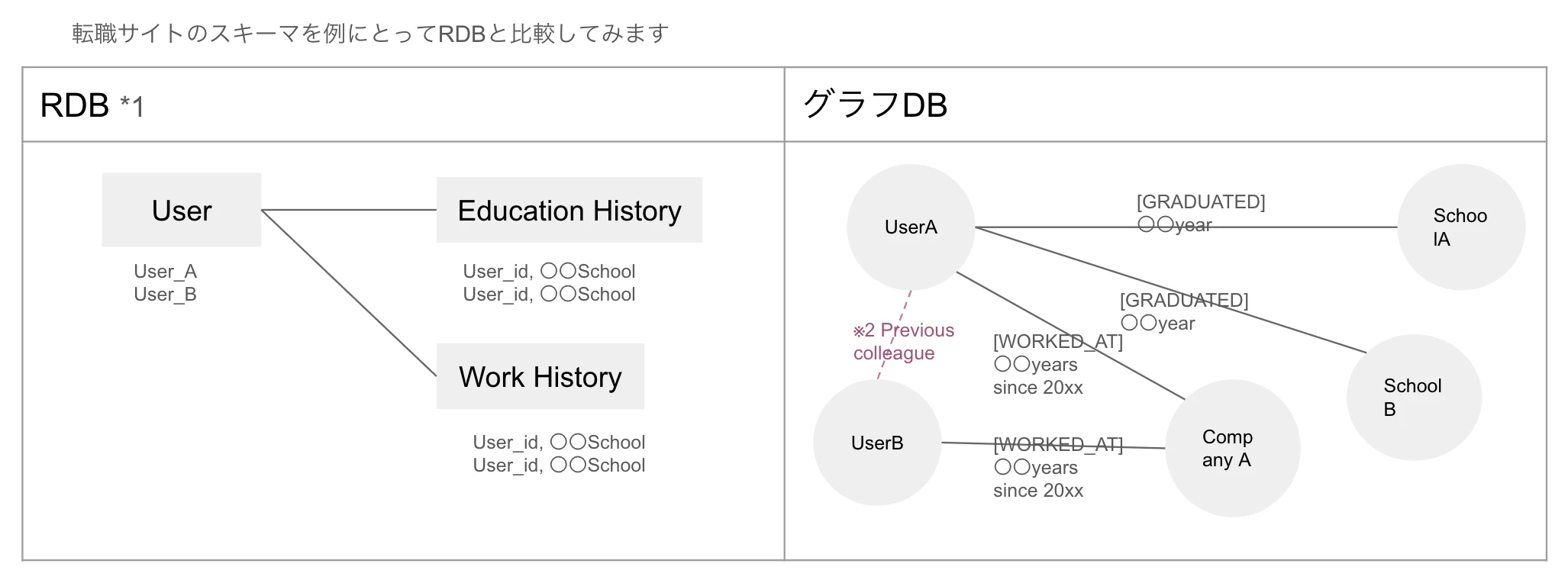
このように、Node、Edgeで結合されているグラフの事を、Labbeld Property Graph(LPG) といいます
※2 のようにRDBでは表現できていない隠れたリレーションもエッジとしてつなげる事で、見落としていたデータのつながりに気づき、さらなる分析に活用する事も容易に可能です。
Neo 4jを使う
Neo4j は、Neo4j Inc. によって開発されたグラフ データベース管理システム (GDBMS) です。Neo4j が保存するデータ要素は、ノード、それらを接続するエッジ、およびノードとエッジの属性です。 Neo4j は、ネイティブ グラフ ストレージと処理を備えた ACID 準拠のトランザクション データベースで2007年に最初のバージョンがリリースされました。
Download for Desktop
WindowsでもMACでもデスクトップにインストールして簡単に利用を開始することができる
Neo4j Browser
コマンドラインツールだけでなく付属のブラウザツールがある
Cypherクエリを発行してデータを確認できるもので、閲覧のしやすさが魅力的
プラグインサポート
APOCやDataScienceなど好みに合わせて使いたい機能を選べる
非常に多機能で一部を下記に抜粋して紹介する
- APOC - Dataのインポート機能などが使えるので、APIから取得したjsonをインポートするクエリを記述できるようになる、Cypherクエリという標準クエリでサポートしてない構文が使える
-
Data Science Library
PageRankやKmeansクラスタなど様々なアルゴリズムを活用できる - Neo4j Bloom - Neo4j Bloomで使われているTypeScriptで書かれたReact用のライブラリ、部機能から有償になるので申し込まなかった
グラフアルゴリズムいろいろ
Neo4jを利用するメリットは、なんといっても Data Science Library (GDS)にあります
各アルゴリズムの中から、用途に応じて、様々なアルゴリズムが選択できます
中央性アルゴリズム
ノードの重要性をスコア化するアルゴリズムです
以下の観点で評価されます
- 仲介者としての影響力: 他のノード間を仲介する役割
- 接続効率: 他のノードとの効率的な接続性
- 影響力のあるノードとの距離: 中心的なノードとの近さ
クラスタリングアルゴリズム
グラフ内のノードをクラスターに分割するアルゴリズムです
-
特徴
- ノード間のリンク密度や影響力のあるノードとの接続量を重み付け可能
- 特定のパラメーターに基づいてノードをグループ化する際に使用されます
類似性アルゴリズム
ノードペア間の類似性を計算するアルゴリズムです
-
計算基準
- ノードの近隣(接続関係)
- ノードの属性
-
結果
- 類似度スコアを算出
-
利用可能な指標例
- コサイン類似度 ジャッカード指数など
パス計算アルゴリズム
2つのノード間の最短距離を計算するアルゴリズムです
-
特徴
- ヒューリスティック関数を用いることで効率的に最短経路を検索可能
-
用途
- 物流における最短経路の算出など
DAGアルゴリズム
DAG(有向非巡回グラフ)を扱うアルゴリズムで依存関係を表現するのに使用されます
-
用途
- タスクのスケジューリング
- ワークフローの管理
- コンパイラの依存関係解析
- 知識グラフの構築
トポロジカルリンク予測
グラフのトポロジーに基づいてノード間の「親密度」や「関連性」を計算するアルゴリズム
グラフアルゴリズムでデータの分析 (1)
-
中央性(Centrality)
中央性は、グラフ内で重要なノードを見つけるために使用されます。
PageRank
ノードの重要性をランク付けするアルゴリズム(Googleの検索アルゴリズムで有名)
-
特徴
- 他のノードからリンクされているノードほど重要とみなされる
- リンク元のノード自体が重要であれば、そのリンクの影響力はさらに強くなる
-
用途例
- ウェブページのランキング
-
参考動画
Youtube Link
Betweenness Centrality
ノードがどれだけ他のノード間のショートカットに位置するかを計測するアルゴリズム
-
特徴
- SNSで影響力がある人物や交通網で重要な拠点を特定可能
- ウイルス感染モデルや情報拡散シミュレーションで重要ノードを特定
-
参考動画
Youtube Link
Degree Centrality
ノードが持つ直接のリンクの数を計測するアルゴリズム
-
特徴
- シンプルで高速
- ローカルな指数であり、グラフ全体の構造を反映しない
- ノードが多く接続していても、接続先が独立したノードばかりの場合は重要度が低い
-
参考動画
Youtube Link
Closeness Centrality
ノードが他のすべてのノードにどれだけ近いかを測定するアルゴリズム
-
特徴
- 用途はBetweenness Centralityと類似
- 計算コストが高い
- 孤立したノードの近接中心性は0になる
-
参考動画
Youtube Link
Harmonic Centrality
他のノードに対する平均的な「距離」を逆数で表現するアルゴリズム
-
特徴
- Closeness Centralityを改良した指標
- 到達可能な部分のみを評価するため、分断されたグラフにおいても有意なスコアを得られる
-
参考動画
Youtube Link
グラフアルゴリズムでデータの分析 (2)
ノードをグループ分けしてコミュニティを発見するアルゴリズムです
Louvain
大規模なネットワークでコミュニティを検出するアルゴリズム
-
特徴
- コミュニティ内のノードがどれだけ密接に接続されているかを、外部のコミュニティとの接続状態と比較する
-
用途
- ソーシャルネットワークや大規模グラフでのコミュニティ検出
-
参考動画
Youtube Link
Label Propagation
ネットワーク構造のみをガイドとしてコミュニティを検出するアルゴリズム
-
特徴
- 目的関数や事前のコミュニティ情報が不要
- ラベルを近隣ノードに伝播させてコミュニティを形成する
-
参考動画
Youtube Link
Triangle Count
無向グラフにおいてグラフ中の三角形の数を数えるアルゴリズム
-
特徴
- ソーシャルネットワークにおけるコミュニティの結束度を測定
- グラフの安定性を評価するために利用可能
-
参考動画
Youtube Link
Weakly Connected Components
有向グラフおよび無向グラフ内で接続されたノードの集合を特定するアルゴリズム
-
特徴
- 2つのノードがパスで接続されていれば同じコンポーネントに属する
-
参考動画
Youtube Link
Strongly Connected Components
有向グラフ内で互いに接続されたノードの最大集合を特定するアルゴリズム
-
特徴
- 集合内のすべてのノード間に双方向のパスが存在する必要がある
-
参考動画
Youtube Link

グラフアルゴリズムでデータの分析 (3)
ノードをグループ分けしてコミュニティを発見するアルゴリズムです
Node Similarity
ノードの接続先に基づいてノード間の類似性を比較するアルゴリズム
-
特徴
- 2つのノードが多くの共通の隣接ノードを持つ場合、それらは類似しているとみなされる
-
利用可能な指標
- Jaccard
- Overlap
- Cosine
-
用途
- 購買履歴を基にした通販サイトでのおすすめ商品の提示
-
参考動画
Youtube Link
K-Nearest Neighbors
グラフ内のすべてのノードペア間の距離を計算し、各ノードと距離が最も近い k 個の隣接ノード間に新しい関係を生成するアルゴリズム
-
特徴
-
類似ノードの特定
- 特定のプロパティに基づいてノード間の類似性を計算
-
関係構造の生成
- k 個の最も近いノードとの新しい接続を作成
-
ネットワーク分析
- グラフデータ内のクラスターやコミュニティの発見
-
類似ノードの特定
-
用途
- ソーシャルネットワークや推薦システムにおける近隣ノードの解析
-
参考動画
Youtube Link
ベクトル化した特徴量でマッチング
グラフ理論による探索アルゴリズムだけなく、
ベクトルデータを使ったマッチングができるのが検索や分類に利用できるのが魅力的です
ノードやエッジのプロパティに特徴量ベクトルを一緒に登録しておいて、ベクトル用の関数を使って検索ができます
6種類のベクター計算式
集合を扱う
集合の類似度について扱う事ができます
-
gds.similarity.jaccard
2つのセット間で、共通の要素の数を、両セットのユニークな要素の合計数で割った比率に関心がある場合に使用します
Jaccard Similarityと、Overlap Similarityは、データのサイズが同じであれば同じ結果を返します -
gds.similarity.overlap
共通の要素の数を、比較しているセットのうち小さい方のセットのサイズで割った比率に関心がある場合に使用します。この方法は、比較するセットのサイズが異なる場合に有用です
コサイン類似度を扱う
-
gds.similarity.cosine
Word2Vecを扱う場合など、ベクトルの向きがどれだけ似ているかを計算します
相関係数を扱う
2つの変数(ベクトル)間の線形相関を測定するための統計的指標変数がどれだけ同じ方向に変動するかに使用
1: 完全に正の相関
-1: 完全に正の相関
ユーグリット距離を扱う
-
gds.similarity.euclideanDistance
ユークリッド距離は、2点間の最短距離を測定する直線的
すべての成分の差を2乗し、その合計の平方根を取ることで、2点の間の距離を計算する -
gds.similarity.euclidean
この関数はユークリッド距離を基に、類似度を0から1のスケールに変換
0: 完全に異なるベクトル(最も遠い)
1: 完全に同じベクトル(最も近い)