Purpose
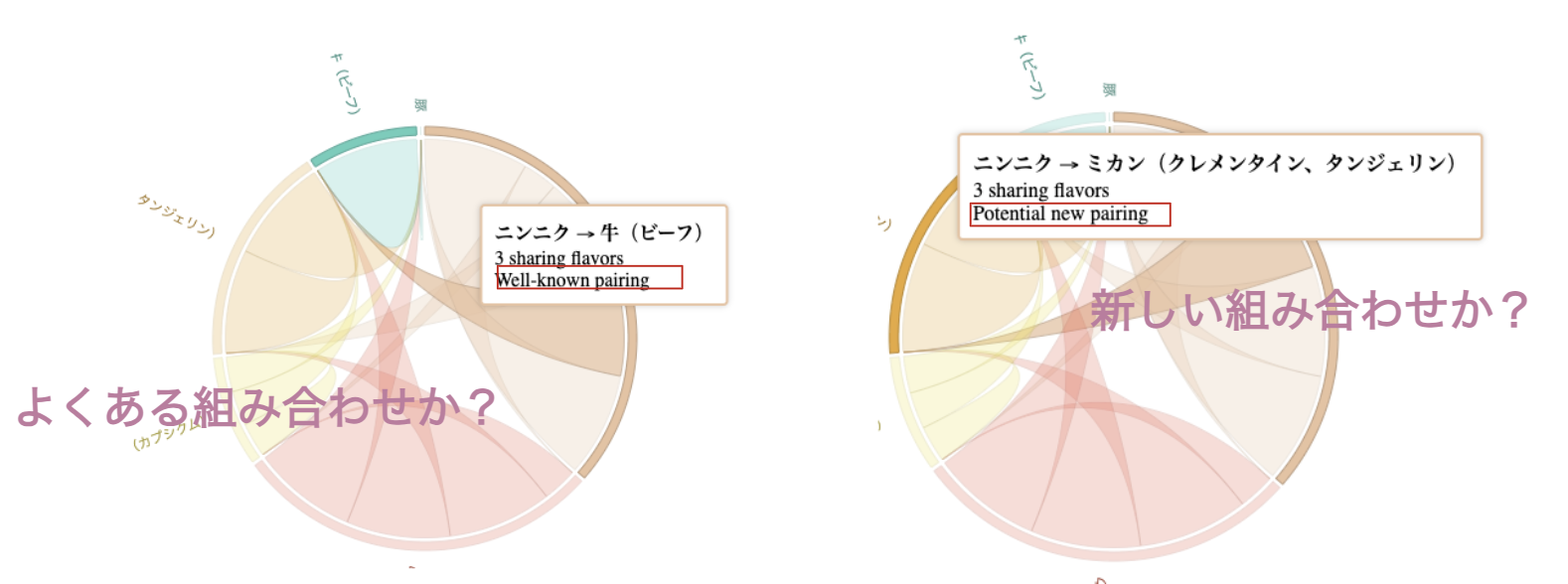
特定の食材のペアリングが「一般的によくあるもの」か、「珍しい組合せ」か
という推定をして結果を表示したいと思います。
よくあるペアリングは低リスクで安心してレシピに導入できるし、
革新的な新しいペアリングも模索して、新しいレシピも生み出したいです。
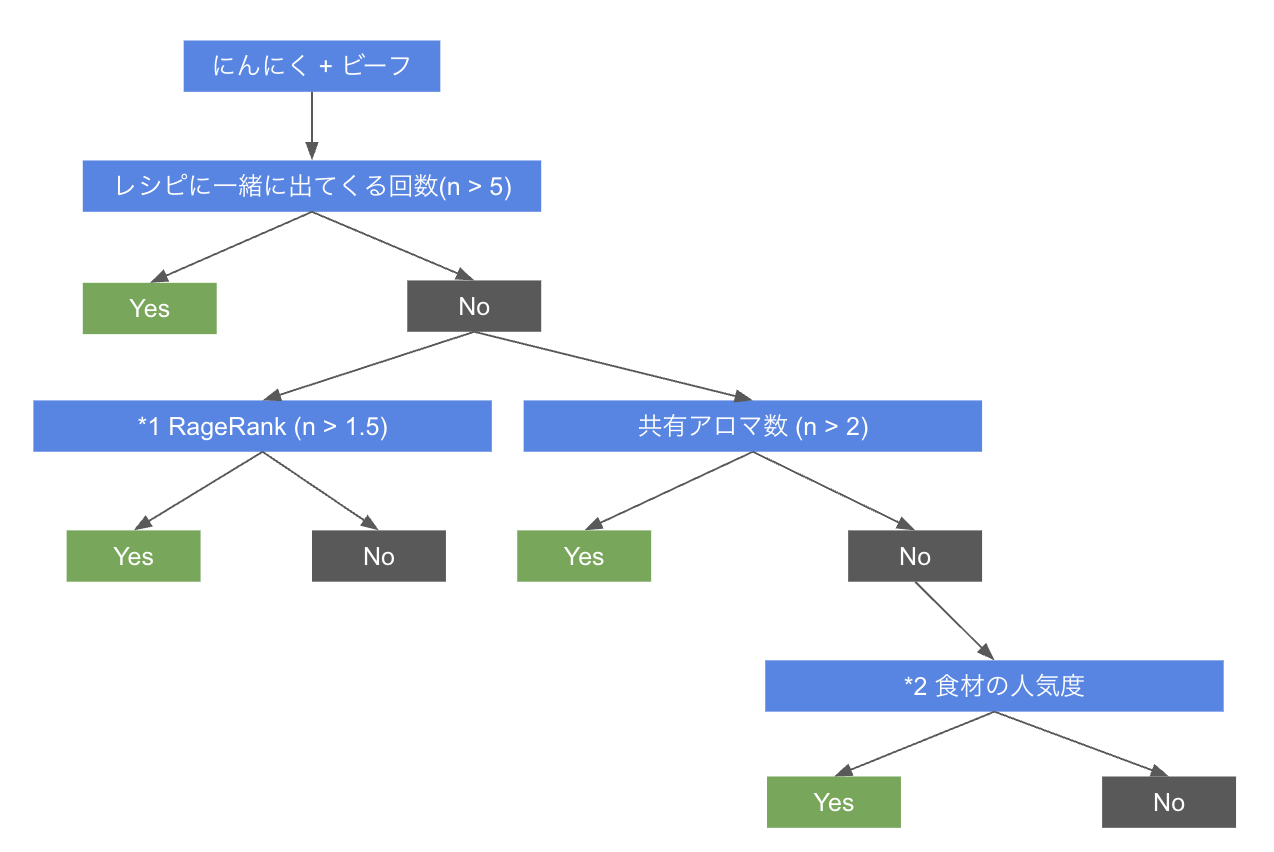
初学者レベルで決定木アルゴリズムについて理解していきたいと思います!
Decision Treeでペアリング
この推定を行うためのベストプラクティスを学びます!
アルゴリズムとモデルについて理解を深めましょう!
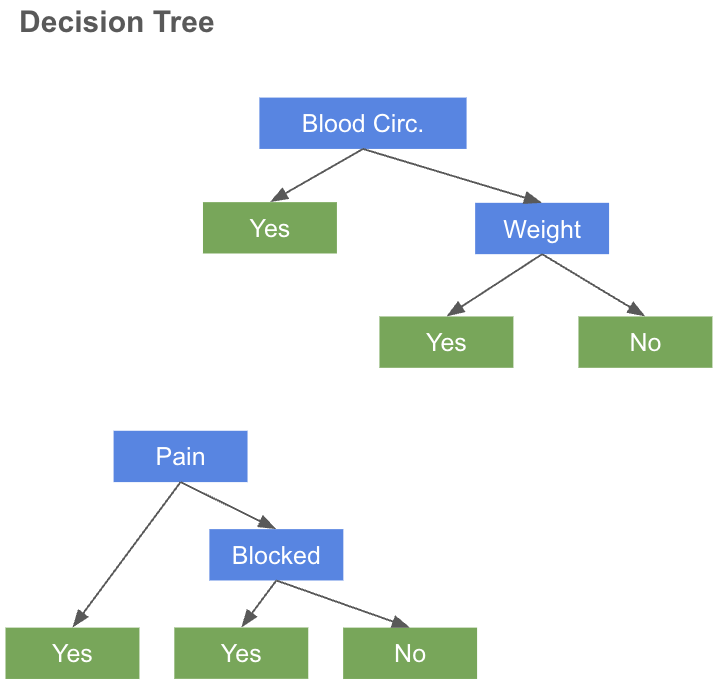
決定木(Decision Tree)のアルゴリズムは
「シンプルな決定木 → アンサンブル学習 → 勾配ブースティング」
と進化してきました。
アンサンブル学習である、RandomForest、AdaBoost、
ブースティング学習である、XGBoostについて詳しくみていきましょう!
| 手法 | タイプ | 仕組み | 特徴 |
|---|---|---|---|
| Random Forest | バギング | 複数の決定木を並列に学習して投票 | 過学習しにくく、並列処理で高速化が可能。ただし木のサイズは大きくなる傾向。 |
| Ada Boost | ブースティング | 弱学習器を逐次的に学習し、誤分類データに重みを置いて補正 | シンプルで理解しやすいが、ノイズに敏感で過学習しやすい |
| Gradient Boost | ブースティング | 誤差(損失関数)の勾配を利用して、次の決定木を追加 | 柔軟で高精度な予測が可能だが、計算コストが高く時間がかかる |
| XGBoost | ブースティング | Gradient Boosting に*1 正則化と並列処理・*2 欠損値処理などの高速化機能を追加 | Gradient Boosting に正則化と並列処理・欠損値処理などの高速化機能を追加 |
[]
Random Forest
| Flow | Decision Tree |
|---|---|
 |
 |
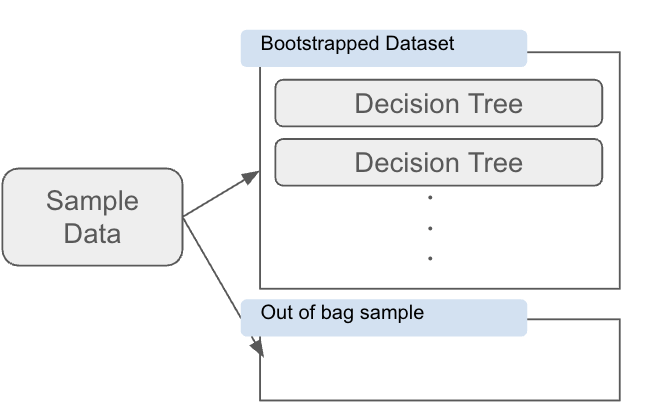
元のデータセットから ランダムに一部のデータを重複ありで抽出 し、それぞれのサブセットを使って 複数の決定木を学習する。
分類問題: 各決定木が予測し、最も多いクラス が最終的な予測値となる
回帰問題: 各決定木の出力の平均値 を最終的な予測値とする
-
OOBサンプル (Out-of-Bag Sample)
ブートストラップサンプリングで 選ばれなかったデータのこと。
これを使うことで、別途テストデータを用意しなくてもモデルの精度を評価できる。 -
OOBエラー(Out-of-Bag Error)
OOBサンプルを使って予測を行い、どれくらい間違えたか を測定することで精度評価が可能
これにより、過学習を抑えつつ、モデルの性能を推定できる。
常にフルサイズのツリーを作るので、あまりパフォーマンスが良くないという欠点がある
Ada Boost
| Flow | Decision Tree |
|---|---|
 |
 |
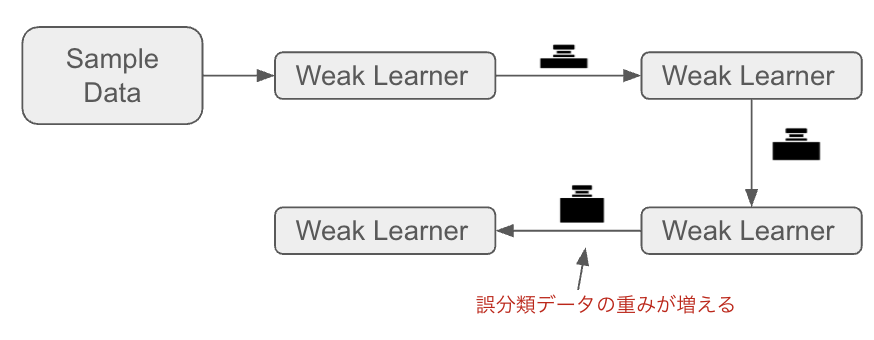
AdaboostはWeak Learnerと呼ばれる分類器を組み合わせ、
誤分類データに重点を置いて学習を進める。
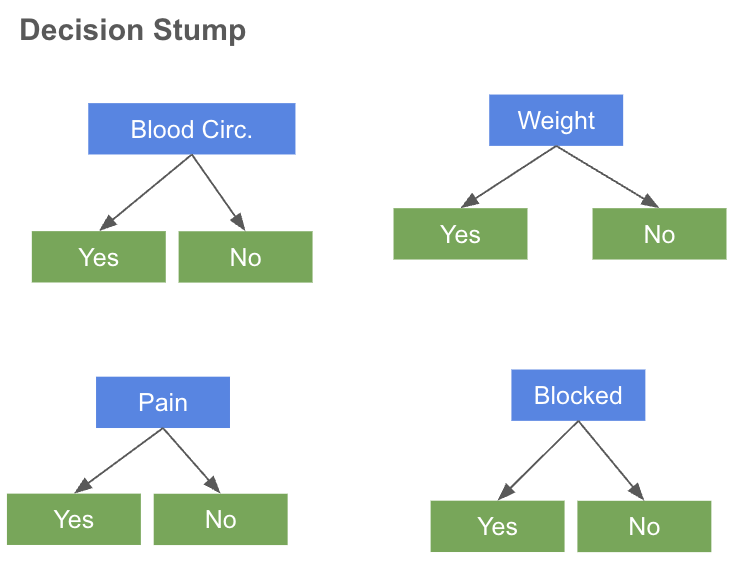
1ノード & 2リーフの単純な決定木 (Decision Stump)を
前のStumpのエラーをもとに作成していき、前の学習結果を次に引き継ぐ。
RandomForestはすべてのツリーが独立しているのに対して、
Adaboostは1つめのStumpの結果が次のStumpの結果に影響する。
RandomForestでは、決定木が「ランダム」であったが、
Adaboostでは誤りにフォーカスする。
誤りが大きいデータに適応するため、過学習のリスクがある。
誤分類を減らすために、特定のデータに過剰適応する可能性がある
Gradient Boost
| Flow | Decision Tree |
|---|---|
 |
 |
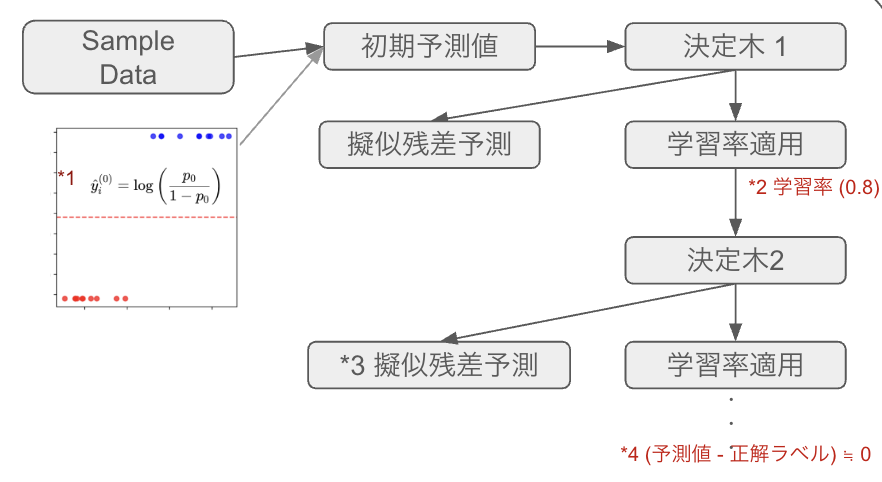
Gradient Boostは、Ada Boostと同様に、前のツリーのエラーをもとに
固定サイズのツリーを作成するが、それぞれのツリーはAdaBoostのものより大きい。
指定されたTreeの数または精度向上が失敗するまでツリーを作り続ける。
予測したい値の平均のリーフから学習を始める。擬似残差(損失関数の勾配)を計算し、それを用いて修正を繰り返しながら残差を埋めるように学習する。
分類問題の場合に初期値は、オッズとの残差をResidualとした場合の計算式
*1 オッズとは、ある事象が起こる確率と起こらない確率の比率。
「Aが起こる確率(p)が80%」なら「オッズは4(Aが起こらない確率の4倍)」
*2 学習率は明示的に指定するハイパーパラメーター
*3 擬似残差予測
*4 予測値と残差の差がほぼゼロになるまで、繰り返しを行う
残差計算式
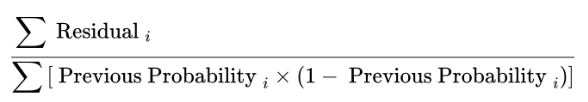
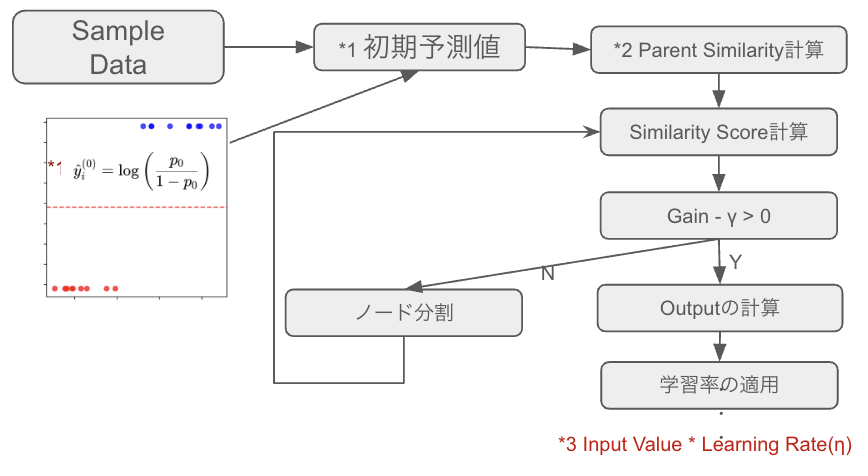
XGBoost (for Classification)
| Flow | Decision Tree |
|---|---|
 |
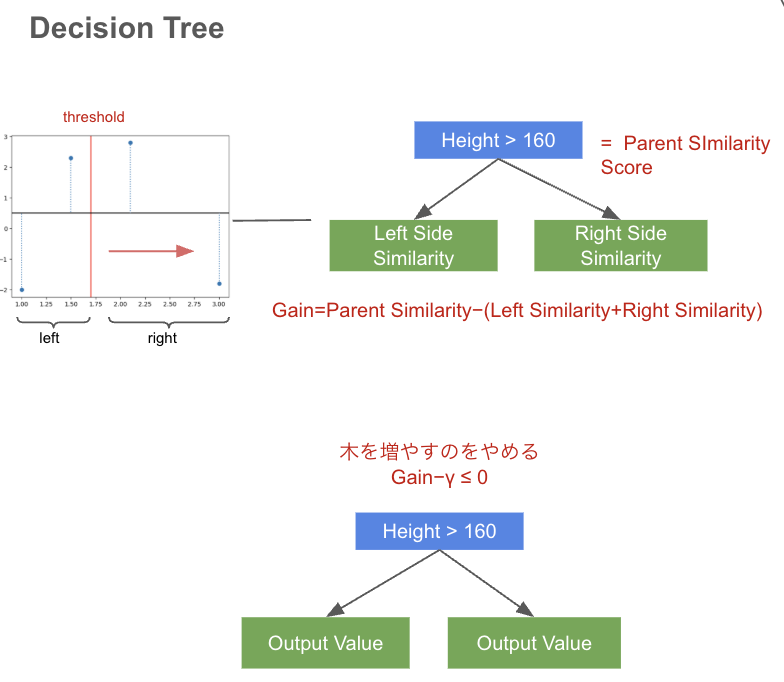 |
初期予測値から残差を計算し、それを使って Parent Similarity を求める。
Gainを求めて、Gain - γ > 0であれば、Outputの計算に進むが、
なければ再度ノードを分割してツリーを構築する。
OutputValueに学習率を適用、予測誤差が十分少なくなる、または、
予め指定した決定木の数まで繰り返す。
今回は、SimilarityScoreの計算は回帰と分類で別の計算式になるが今回は分類を扱っている。
*1 オッズとは、ある事象が起こる確率と起こらない確率の比率。
「Aが起こる確率(p)が80%」なら、オッズは4(Aが起こらない確率の4倍)
*2 Parent Similarityの計算式
最初のスプリットではParent Similarity Scoreはルートノードのそれに等しいが、2回目以降のスプリットでは親ノードのそれに等しい
*3 Gradient Boostと同様に学習率が適用される
学習率は予め指定されたハイパーパラメーター

- 過学習対策がしやすく、適用範囲が広い
- 決定木をベースとしたアルゴリズムであり、Gradient Boosting の仕組みを採用している
同じ勾配ブースティングの手法である、LightGBM / CatBoostについても抑えておくのがいい
XGBoost: Level-wise(幅優先)、データ小規模 / 過学習を防ぐ
LightGBM: Leaf-wise(深さ優先)、大規模データ/ 高速処理が必要
CatBoost: カテゴリ変数向き
木構造というと、今まで、Random Forestのイメージしかありませんでしたが、
もっと改良されていて、とても複雑な計算を重ねて、答えを導き出してくれているという事が分かりました。
他にも色々な説明動画で学ばせていただきました。
https://www.youtube.com/watch?v=Tqhs1YrZgeI
https://www.youtube.com/watch?v=rzi2BNAH5Lo