データベースとは?
Wikipediaを参照すると、データベース=「検索や蓄積が容易にできるよう整理された情報の集まり」と書いてある。
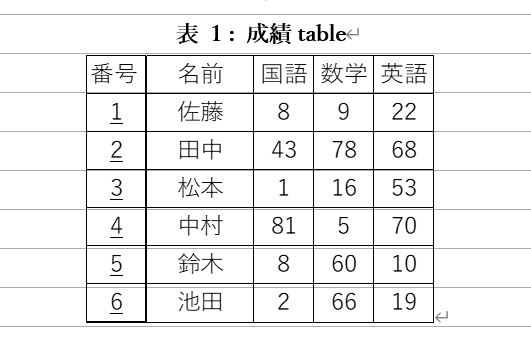
成績一覧のようなデータは、上記の表のように書くのが最も見やすいだろう。番号を付けて二次元的に並べていて、それぞれの人の成績が一目で理解できる。一つのセル(マス)には一つの情報のみ入っている。図書館貸出データや、顧客データ、財務データ、色々な場面でこのような表を作る必要性が出てくる。しかし、データベースは分かりにくいという声がある。これは、データベースは単体を指すのではなく、多くの場合は複数の表が互いに関係しあった関係データベースを扱うためである。
関係データベースは、エドガー・F・コッドという計算機学者が考案し、現在最も広く使われているという。(他には階層型データベースやネットワーク型データベースなどがある)。そもそも、関係とはどのような意味を指すのだろうか?
例えば、動画投稿サイトの色々な動画のタイトルとそれぞれのコメント一覧をExcelにまとめてくれとお願いされたとする。
一例として以下の表が考えられるだろう。

これは、一つの表の中にそれぞれの動画に対するコメントが複数存在する構造になっている。(このような関係を1対多という表現をする。他にも1対1、多対多がある。具体例を想像してみよう。)素直にこの書き方を徹底したとして、仮にそれぞれの動画に対してコメントが500件あったらどうなるのだろう?同じ重複の行が半端なく増えてしまう。これは、冗長すぎて、データの保存領域や、見やすさに大きな負担を強いてしまう。よって、表を分割して、冗長性を排除したいという欲求がでてくる。これにより分割された表同士は、関係をもつのである。その関係づけはどのように反映されるのか?以下を見てほしい。
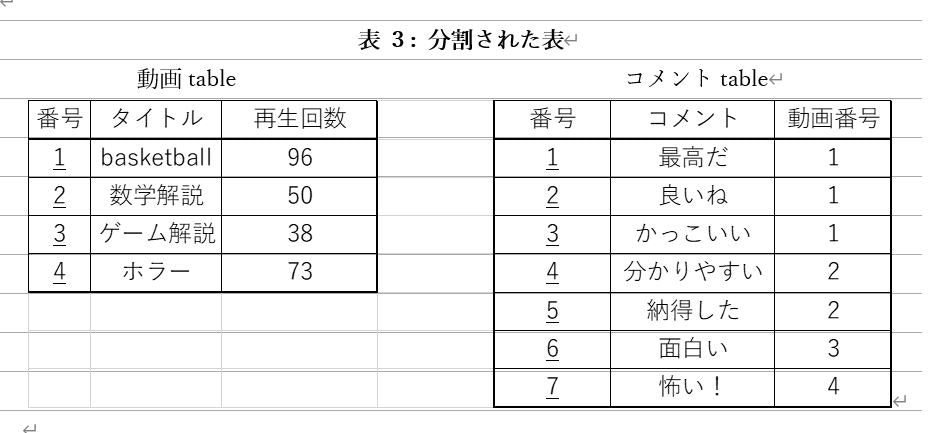
右表の動画番号という列は左表の動画tableの番号と一致している。例えば、「basketballというタイトルの動画のコメントは?」と質問されたら、動画番号1に該当するコメントが取得される。この場合上の3つである。このような右表の動画番号の列は、左表の動画tableの番号を参照するという意味で、外部キーと言う。また、それぞれの表の一番左の番号のことを主キーと言う。このように外部キーを用いて関係づけを表現しているのだ。データベースの更新で、例えばコメントが増えた場合には右表のみが増えていく。(ちなみに関係データベースにおいて、表2→表3のように冗長性を排除し、かつ整合性を保ちながらデータベースを設計することを正規化という。気になる人はぐぐってみよう)
ここでもう一つ大事な性質がある。それは、一意制約と呼ばれる。主キーに重複は許してはならないというルールと、一つのセルには一つの情報のみというルールである。もしこれが不成立の場合、例えば検索する際に、異なるデータ同士を区別、識別できなくなって不都合が生じる。表3の右表の動画番号で1と決まったら、その動画のタイトルはbasketballただ一つに決定される。また、たまたま同じタイトルの動画が2種類あったとしても区別ができる。これにより、データの検索、保守、更新を容易にしている。
SQL(簡単に)
SQLとは、上記の関係データベースにおいて、データの操作や定義を行う言語である。(SQLという名称の由来はかなり特殊?)仕組みは単純で、create(テーブル作成), insert(データの登録), select(データの参照,取得), delete(データの削除), update(データを変更)、この5つでほぼ完結する。データベースを扱う際、ターミナル(コマンドプロンプト)に色付きでこれらの文法が用いられている箇所が出てくると思う。注目してみると良いかもしれない。ここでは、プログラミングを作成する際によく用いるselect文について少し細かく触れる。
Select : 列を指定する
From : テーブルを指定する
Where : 条件を指定する
この3つがよく用いられる。
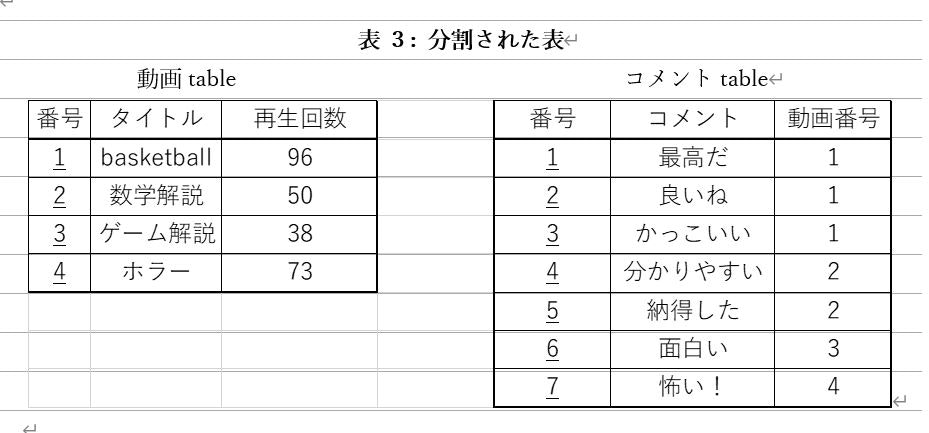
例えば、
Select * (全ての列を取得)
From 動画table ; (動画tableで)
と書かれた場合、左の動画tableが全てそのまま表示される。
「basketballというタイトルの動画のコメントは?」という質問の答えは、
select コメント (コメント列を取得)
from コメントtable (コメントtableで)
where 動画番号 = 1; (動画番号1のやつ)
で3つ取得できる。
#ruby on railsとデータベース(Modelについて)
Ruby on railsにはデータベースの定義と処理を簡便に実現できるmodelという概念が存在する。これはrailsとSQLを繋げる翻訳機とも言われる。例えば、上記のような動画tableとコメントtableの1対多の関係は、動画modelというファイルに「has_namy : コメント(英語では複数形で書く)」、コメントmodelというファイルに「belongs_to : 動画」と書くことで定義できる。
これを書くことで何がうれしいのだろうか?例えば、「basketballというタイトルの動画のコメントは?」という質問に関しては、SQL文法では
select コメント (コメント列を取得)
fromコメントtable (コメントtableで)
where 動画番号 = 1; (動画番号1のやつ)
と書くことで取得できる。しかし、毎回これを書くのは面倒なので、railsではmodelに定義しておけば、
動画.コメント (特定の動画に対するコメント)
で上記の3行の情報を表現できてしまう。参照する外部キーは列名に表名_idと書けば、railsは自動で識別してくれる。このように関係しあった表同士の情報を非常に分かりやすく表現できるという点でmodelに関係を定義するという方法論は有用である。これをrails用語でアソシエーションと言う。
また、もう一つ実際のrailsコードの例を挙げると
Modelの書き方で
@tweets = Tweet.allは
select * #全カラムのレコード一覧
from tweets; #tweetsテーブルで
というSQL文を翻訳してくれている。
最後にmodelはレコードに入れられる情報のルールを設定できる機能も担っている。これはvalidationと呼ばれる。
validates :body, length: {maximum: 140}
このように書くとbodyカラムの文字の長さは140字以内というルールを設定できる。
#ruby on railsとデータベース(migrationについて)
railsにはテーブルの作成削除、列の作成削除する際にMigrationというものを通して行う。例えば、
$ rails generate migration Add列名Toテーブル名 列名:データ型
というコマンドを入力すると、
class Add列名Toテーブル名 < ActiveRecord::Migration[5.1]
def change
add_column :テーブル名, :列名, :データ型
end
end
と書かれたMigrationファイルが生成され、
$ rails db:migrateコマンドで実際にデータベースに登録が可能となる。データベースの変更が2段階の工程になっている。おそらくデータベースの保守性を高める意図があるのだろう。データベースは建物で言うところの骨格に当たるので、簡単に変更できてしまうと良くない。しかし、この仕様のおかげで初学者にとってmigrationはやや分かりにくいものになっている。とはいえ、この一連の流れも実際はSQL言語に翻訳されて実現されている。これによるメリットは大きく二つある。
- SQL言語や各種データベースの特徴を学ぶコストを省ける。
- 実行順序を自動で記録してくれる。
データベースには色々な種類(postgresql, MySQLなど)があり、いずれを用いようとも、rails翻訳機のおかげで統一的に利用が可能となる。また、実行順序を記録しているおかげで、開発の進展の確認や後戻りを楽にしている。
#まとめ
関係データベースの仕組みを理解した。
ruby on railsはデータベースが簡便に扱えるように設計されていることを理解した。
modelの役割
①railsとSQLをつなぐ翻訳機
②アソシエーションを簡便に表現できる
③レコードのルールを設定できる
migrationのしくみ
①データベースのテーブル、カラムの変更を行う際に経由するもの
②2段階の工程になっている
③実行順序を記録してくれる