初めに
大学のセミナーにてUser-defined Reduction について調べることになったのですが、その時に日本語でこのテーマを解説しているサイトが見当たらず、テーマを理解するのに苦労しました。
ここのサイトで記事を書くのは初めてなのですが、もし今後自分と同様にこのテーマを初めて扱う初心者が居たら…といった感じで自分が分かった事を 初心者なりに可能な限り分かりやすくまとめてみます。 もし「ここは間違ってるよ」、「こういった説明の方が分かりやすいよ」といった場所があればご指摘していただけるとありがたいです。
初心者向けに最初にざっくりとOpenMPとReductionについて予備知識を書いてます。
予備知識:OpenMPとは
並列プログラミングをするためのAPI。FORTANやC,C++の言語で使えれる
指示文を書くだけでコンパイラが自動で並列化してくれる
他にも並列化プログラミングをするAPIに比べて、扱いやすい。
もしコンパイラがOpenMP指示文を知らなければ、ただのコメントとして無視して代わりに単純処理をしてくれる
なので、移植性が高くて便利
予備知識:Reductionとは
カンタンにざっくり言えば、大きな処理を小さく分割して並行処理する。そしてその結果を統合する。
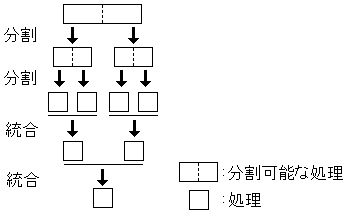
図に表すとこんな感じ
つまりこんな感じでArrayの長さを分割してそれぞれを並列に処理したり、for文の繰り返しを分割してそれぞれの範囲をそれぞれのThreadが担当したり、(5+2)*(3+4)といった計算をするときに括弧ごとに分割して計算することで物事を早く処理できる。
並列処理は大抵こんな感じで処理してくれる。
でももし複数のThreadが1つの変数に対して書き込みを行う際、競合が起こることがある。
例えば2つのThreadが1つの変数に対して1つ数字を足すときとか…
詳しくはこのWikipediaサイトの情報処理 の例を読んでね
https://ja.wikipedia.org/wiki/%E7%AB%B6%E5%90%88%E7%8A%B6%E6%85%8B
とりあえず、OpenMPではこの競合状態を防ぐためにReduction関数がある。
Reduction関数を使うことによって変数をReduction変数に指定できる。
コードでの使い方
reduction(reduction-identifier:list)
reduction-identifier:演算子を指定する。
list: Reduction変数にしたい、変数の名前を入れる。
大抵 #pragma omp parallel とかとセットで使う。
例
for (i = 0; i < 100; i++){
t += z[i];
}```
### Reduction変数になると、どうなるの?
変数がReduction変数になると、並列処理を行う際は それぞれのThreadにおいてprivate変数として扱われて、並列処理が終わったときには それぞれのReduction変数が指定された演算子を元に統合される
# User-defined Reduction(UDR)ってナニ?
ユーザーの要望によりOpenMP 4.0で追加された新機能
名前の通り、ユーザーが独自の演算子を作成して、それをReductionで使う事が出来るようになる
### そもそも何でそんなものが必要なの?
従来のReduction関数ではプリミティブ型変数のみOpenMPの提供する演算子で処理することができた。
※プリミティブ型はintやbooleanとか…
※Arrayも従来のReduction関数で扱うことは可能、ただしC,C++においてはOpenMP4.5以降のバージョンで扱えれる。FORTANではそれ以前のバージョンでも扱えれる。
ただ場合によっては、Structや、Arrayを使ったReductionを行いたかったり、OpenMPの提供する演算子以外の機能をReductionしたい場合はユーザーがとても複雑なコードを書く必要がある。
例えば座標の点の情報を持ったStructの配列があって、その配列の中から一番(0,0)に近い座標点のStructを探し出す…とかは従来の機能でやろうとすると、とても複雑になる。
その場合手間は増えるし、コードが複雑になれば、もちろんバグも増えて、デバッグとかで大変になる。
なのでユーザーが作った関数を、演算子として使えるように指定するのが、このUDR関数の役割
### UDRの使い方
この機能を使う前に、まずOpenMPのバージョンが 4.0より最新であるか確認してください。
とても大事な事なのでもう一度言います。 バージョンが4.0より新しい物であるか確認してください
(自分は使っているバージョンが古い事に気が付かず、この事を見つけるのに数日かかりました…)
UDRを使うには以下の様に記述する必要がある
```#pragma omp declare reduction(reduction-identifier : typename-list : combiner )[initializer-clause] ```
reduction-identifier: 演算子の名前を指定する
typename-list: 演算子の型指定
combiner: 演算子の仕組みの指定
initializer-clause: 初期値の設定
既に存在する演算子と同じ型で同じ名前の演算子を作ることができないようになっている
既に存在する演算子と違う型で同じ名前の演算子を作った場合、型によってどの関数が使われるか自動で分けられる
combinerではomp_outとomp_inの2つの変数のみを使い、どうやって2つの変数が1つの変数となってomp_outに格納されるか指定する(つまりどうやって結果が統合されるか)
ユーザーが作った関数にomp_outとomp_inのポインタを上げて関数側でomp_outの値を書き換えたり、関数の戻り値をomp_outに代入することができる
initializer-clauseでは、omp_privとomp_origの2つの変数のみ使う事が出来る
リダクション変数がThread実行時にプライベート変数と化した際、その変数の値を定義するための物。もしここで記述しなかったら、空の変数が使われる
omp_privに入れられた値が、プライベート変数と化した際に使われる
omp_origは、リダクション変数と化する変数が元々持っていた値を示す。
omp_priv=omp_orig とすることで、元々の変数が持っていた値を初期値として使う事が出来る。
```c
int A=num
# pragma omp declare reduction(Bsp01:typ:combiner) \
initializer(omp_priv=omp_orig)
# pragma omp parallel for reduction(Bsp01: A)
こうすることで、変数Aはnum値を初期値として扱う
OpenMPが用意した演算子(+,*,- などなど)では既に omp_privやomp_out,omp_inが使われていて、このサイトにあるテーブル表を見たら直感的に理解できると思います
UDRを使ったいくつかの例
https://passlab.github.io/Examples/contents/Examples_udr.html
よりいくらか真似てみた
Combinerの例
// 関数からの戻り値が直接 omp_priv に
# pragma omp declare reduction(Bsp01: struct Point: omp_out = func01(omp_out,omp_in) ) \
initializer( omp_priv = { INT_MAX, INT_MAX } )
// 関数内で omp_out の値が変更される
# pragma omp declare reduction(Bsp02: struct Point: func02(&omp_out,&omp_in) \
initializer( omp_priv = { INT_MAX, INT_MAX } )
// Combiner 内で仕組みを定義して、関数を使わずに変更することも可能.
# pragma omp declare reduction(Bsp03: struct Point: \
omp_out.x= omp_in.x < omp_out.x ? omp_in.x : omp_out.x, \
omp_out.y= omp_in.y < omp_out.y ? omp_in.y : omp_out.y) \
initializer( omp_priv = { INT_MAX, INT_MAX } )
// Array omp_in が Combiner 内で omp_out とくっつけられる
// std::vector<int> は Int の Array
// .insert() によって omp_in の全ての最初から最後までの内容が、 omp_out の後ろに引っ付く.
# pragma omp declare reduction (merge : std::vector<int>: \
omp_out.insert(omp_out.end(), omp_in.begin(), omp_in.end()))