生成AIが便利だと言われ、企業でも導入が進んでいます。皆様の企業では導入されていますか?
企業に導入しても一部の社員にしか使われないという調査結果があり、導入を支援する立場からすると少し悲しくも感じます。
なぜこのようなことになるのか、私なりに考えてみました。
また、その課題を解決するための1つの方法として、手前味噌ですがUiPathのソリューションで解決する方法もあわせて説明します。2024年現在パブリックプレビュー中のため、無料で使用することができますので、興味のある方は試してみてください。
企業の生成AI導入ステップ
おそらく、次のようなステップで生成AIの活用を進めている企業が多いかと思います。
私の個人的な認識ではSTEP3まで進んでいる企業は多くありません。
- STEP1.生成AIチャットボットの導入
- STEP2.全社員用共通RAG機能の拡張
- STEP3.業務部門固有RAG機能の拡張
- STEP4.チャット以外から呼び出して業務に組み込む

STEP1.生成AIチャットボットの導入
利用者にフロントエンドアプリケーションで質問を入力してもらい、バックエンドプログラムが生成AIに対して質問を送信して回答を得る仕組みをAzureなどのクラウドサービスを利用して構築します。

生成AIはある期間までの情報まで知らず、社内の情報について回答できないため、社内情報に回答できる仕組みを構築する必要があります。
STEP2.全社員用共通RAG機能の拡張
社内情報に回答できる仕組みとしては、ファインチューニングなど色々な方法がありますが、現在はRAG(Retrieval Argument Generation)という手法が一般的です。
RAGは、類似性を判断するためにベクトルデータベースを利用して実現します。
事前にドキュメントをベクトル化してデータベースに格納しておき、質問と類似した情報を取得してプロンプトに補足情報として追記して回答を得る仕組みです。

全社プロジェクトとして発足されることが多いため、IT管理の担当者が保守運用することが多いです。
STEP3.業務部門固有RAG機能の拡張
全社プロジェクトから進み、全社員で使えるRAGから業務固有のRAGへ機能を拡張していきます。
ここで、全社員共通RAGや業務部門固有RAGは次のようなイメージです。
- 全社員用共通RAG ≒ 旅費規則、業務ルールの問い合わせ
- 業務部門固有RAG ≒ 特定のドキュメント(契約書、年間報告書)から情報を読み取る

ここでは、利用者の権限をチェックして、実行可否をチェックしたり、参照するドキュメントを切り替えたりする必要があります。人事部の給与データが入ったRAGを構築した際に他の人が「Aさんの給料を教えて」と言って回答を得ることができると、問題になってしまいます。権限周りの処理追加や評価、各部のドキュメントを最新に保つことがIT管理者のリソースが足りなくなります。
STEP4.チャット以外から呼び出して業務に組み込む
生成AIの使われ方としては、大きく分けて2つあると言われています。
・人間の作業を支援する
・人間の作業を自動化で代替する
前者はUIとしてはチャットボットですが、後者はプログラミングでAPIを呼び出す方法が一般的に採用されますが、保守性からRPAやiPaaSなどのローコードアプリが採用されるケースもあります。

RAGの課題
最終的な「STEP3.業務部門固有RAG機能の拡張」まで進めていない企業が多い理由はいくつかあると思われますが、大きく分けると次の3つかと考えています。
- 全社員用共通RAG機能を持つ生成AIの利用シーンがあまり無い
- IT管理担当者のリソースが少ないため、次のステップへ進むことができない
- 業務部門個別でやろうとしても障壁が高い
課題1. 全社員用共通RAG機能を持つ生成AIの利用シーンがあまり無い
全社員が使えるRAGとなると、旅費規則、業務ルールの問い合わせなどが一般的です。
これらはあると便利なのですが、普段の業務に比べると利用シーンは限られてしまいます。
課題2. IT管理担当者のリソースが少ないため、次のステップへ進むことができない
全部署で使えるRAGを展開し、部署からドキュメント追加をリクエストされるも、うまく進みません。
ここにも妨げる大きな要因があります。
- IT管理担当者のリソースが無い
- 別の質問で間違って参照されてハルシネーション(誤回答)のリスクが高まる
- 特定の部署だけ参照できるようにセキュリティを簡単に制御できない
課題3. 業務部門個別でやろうとしても障壁が高い
IT管理担当者が対応してくれないのであれば、部署個別でやろうとしても、障壁があります。
- インフラ、プログラミングの知識が無いとRAGの構築が難しい
- 構築できたとしても、ドキュメントのアップロードが業務ユーザーには難しい
使ってもらえるRAGに必要な機能
このような課題を解決するためにはどうしたらいいのでしょうか?
IT管理者のリソース不足を解決する必要があるため、個人的には「RAGの民主化」が1つの解決策になるのではないかと考えています。
IT管理担当者に集約しているドキュメントのアップロード作業は、各部署の業務ユーザーが行います。
これには、IT管理担当者が業務担当者に任せられるセキュリティが担保されていることが条件になります。
また、効率化の効果を高めるためにも、チャットベースで業務の一部ではなく業務全体に生成AIの機能を組み込めることが理想的です。
簡単!
・簡単にドキュメントをアップロードできること
・簡単にRAGを実行して社内情報に関しても生成AIから回答を得ることができる
安心!
・特定の人しかドキュメント参照できない
・特定の人しかRAGの実行ができないこと
楽!
・前後の処理を含めて業務を自動化することができる
UiPathのソリューション
RAGに必要な機能を網羅したソリューションなんてあるのでしょうか?
私も現在絶賛調査中ですが、今回はUiPathを利用して実現する方法を説明していきたいと思います。
2024年現在パブリックプレビュー中のため、無料で使用することができますので、興味のある方は試してみてください。現在はPDF、CSV、JSON形式に対応しています。

簡単にRAGが導入可能なコンテキスト グラウンディング
UiPathのコンテキスト グラウンディングを利用することで、UiPathプラットフォームだけでRAGを構築でき、生成AIが社内情報を検索できます。
バックエンドプログラムの構築、ベクトルデータベースや生成AIの契約も不要です。
プレビュー中は無料ですが、一般リリース後にはAI Unitというライセンスが消費される仕組みになる予定です。
GPT4からGeminiに変更したいとなった場合でも、ボタン1つで契約の変更不要ですぐに変更することができます。

生成AI活用に必須のセキュリティとガバナンスをサポート
企業で生成AIを活用していく際に懸念されるのはガバナンスやセキュリティといった観点です。
Studioから呼び出される生成AIアクティビティは「AI Trust Layer」を通過して生成AIにアクセスします。
AI Trust Layerは生成AIを安全に活用するために必要となるガバナンスや機能を盛り込んだフレームワークです。
利用状況を可視化するダッシュボードや個人情報をマスキングする機能などありますが、コンテキストグラウンディングもAI Trust Layerの1つの機能として追加されました。
今後のリリース予定
今後リリースを予定しているチャットUIを持つAutopilot for Everyoneも同じようにAI Trust Layerを通過するため、コンテキストグラウンディングを利用することができます。

業務ユーザーでも簡単にドキュメントの追加が可能
RAGを構築・運用していく上で重要な点はドキュメントを最新に保つことです。
コンテキストグラウンディングでは、SharePoint、GoogleDrive、Boxなどのクラウドファイルストレージサービスと連携することができます。
無料プレビュー中の制限事項
一般リリースで予定されているクラウドファイルストレージサービスとの連携機能は、無料プレビュー時には利用することができません
これらのクラウドストレージサービスと契約していない場合でも大丈夫です。管理ツールOrchestratorにはストレージバケットというファイルを格納する置き場がありますので、コンテキスト グラウンディングに利用できます。
無料プレビュー中の制限事項
無料プレビュー時は、Sharedフォルダおよびそのサブフォルダのみコンテキスト グラウンディングに利用することができます。
追加したドキュメントは、生成AIが使えるようにするためには事前に情報検索用のLLMでベクトルDBに格納しておく必要があります。このインデックス作成はOrchestratorからできますので、プログラミングの知識は不要です。
無料プレビュー中の制限事項
無料プレビュー時は、管理ツールOrchestratorからのインデックス作成機能は提供されていません。
また、インデックス作成はアクティビティ(部品)として提供されているため、UiPath Studio/ StudioWebで自動化することができます。Integration Serviceを利用することでクラウドストレージが更新されたタイミングでインデックスを更新することも可能です。
特定の人しかRAGの実行ができない仕組みがある
管理ツールのOrchestratorではフォルダ単位で権限を管理することができます。
RAGで使用するドキュメントのインデックスはOrchestrator上のフォルダ単位で紐づくため、RAGを使用できる人を管理ツールから制限することができます。
ハルシネーションのリスクを防止
生成AI、RAGを利用する上で問題となることはハルシネーション(AIのでっちあげ)です。
UiPathの生成AIアクティビティ経由のコンテキスト グラウンディングでは、インデックスを指定します。
これは、一般的なRAGでは採用されていることは少ないですが、大胆ですが良い方法だと思います。
一般的にはドキュメントが多くなると、間違って参照してしまう確率も高くなります。ドキュメントを追加することで今まで正常に動いていた場合にも影響を与える可能性があります。
このようにインデックスを指定して生成AIに参照すべきドキュメント群を指定する方法は、RAGで回答を自動生成する場合、非常に有効になるかと思います。
また、RAGのバックエンドのプログラムはアップデートされていくため、RAGの精度は自動的に向上していく点もRAGの民主化を進める上でも良いと考えます。
UiPathであれば前後の処理も自動化するので便利
UiPathのコンテキストグラウンディングは、アクティビティが用意されているので部品をドラッグ&ドロップするだけで、社内情報を生成AIから聞くことができます。チャットシステムだと自分で調べて回答を得るだけで終わりですが、UiPathの場合はその回答をメールやチャットで連絡することもできますし、システムに入力することもできます。業務全体を自動化していく前後の処理を含めて業務を自動化することができる点は利用者にとっても便利で継続的に使いたいと考えるのではないでしょうか。
コンテキスト グラウンディングの使い方
コンテキスト グラウンディングを始めるためには、事前準備が必要です。
準備が完了すれば、3ステップで使うことができるようになっています。

事前準備
コンテキスト グラウンディングを利用するためには、次の環境が必要です。
・v2024.4以降のStudio WebまたはStudio Desktopを使用する必要があります。
・Automation Cloud環境への接続が必須です。
既存ユーザーで、うちはオンプレだからとあきらめるのは早いです。
最新のライセンスでは、オンプレとクラウドのハイブリッド構成で構築することが可能ですので、Automation Cloud側で生成AI機能を試すこともできます。
個人利用であれば、Automation Cloud Community版に登録することで、無料プレビュー中は無料で利用することが可能です。
コンテキスト クラウンディングを使ってみよう
今回は10K Formから文書を読み取っていきたいと思います。
10K Formとは、日本での有価証券報告書に該当する文書です。
AppleやGoogleなど、インターネット上から様々な企業の10K Formを取得することができます。
Apple、Google、UiPathの3社のフォームを読み取り間違いが起きないか検証するために配置します。
Appleの分析をコンテキストグラウンディングで行ってもらいます。

STEP1. ドキュメントのアップロード
Automation Cloudにログインし、メニューから管理ツールの「Orchestrator」を選択します。

OrchestratorのフォルダからSharedフォルダから、ストレージバケットを選択します。
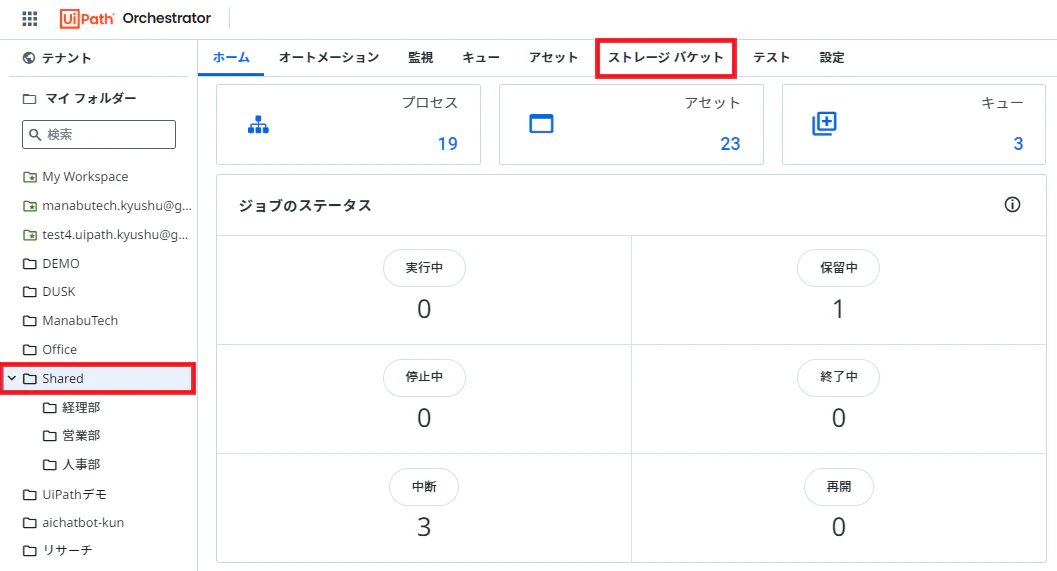
無料プレビュー中の制限事項
無料プレビュー時は、Sharedフォルダおよびそのサブフォルダのみコンテキスト グラウンディングに利用することができます。
ストレージバケットを追加ボタンより、ストレージバケット(ドキュメントを格納する箱)を追加します。
ここでは、「10Ks」という名前にしました。

新しいファイルをアップロードボタンより、インターネットから取得した各社の10K Formをアップロードします。
今回は、Apple、Google、UiPathの3社を格納します。

STEP2. インデックス作成
ドキュメントが格納されただけでは使用することはできません。
これをLLMが類似性を検証できるようにベクトルデータベースに格納する作業が必要になります。
この作業をインデックス化、インデックス作成と呼びます。
インデックス指定では、生成AIアクティビティを利用して作成します。
::: note info
一般リリースでの機能改善
管理ツールOrchestratorからのインデックス作成機能が提供されます。
:::
事前にIntegration ServiceでUiPath GenAI Activitiesのコネクタを作成しておく必要があります。
Integration Serviceに移動します。

Sharedフォルダにコネクションを追加します。
Sharedフォルダ、コネクションを選択し、コネクションを追加ボタンをクリックします。

接続先として、UiPath GenAI Activitiesを選択します

接続ボタンをクリックしてください。

その後、Studio WebまたはStudio Desktop上からインデックスを作成します。
ここでは、Studioからインデックスを作成してみます。
Studioで新しくプロジェクトを開きます。
Ctrl+Fで、ユニバーサル検索を呼び出します。
「インデックス」と検索すると「インデックス作成とデータ取り込み」が見つかると思いますので、デザイナーパネルに追加してください。

Orchestratorのフォルダー:Shared
Orchestratorのバケット:"10Ks"
インデックス名:"10Ks"
インデックス名は任意の名前で良いのですが、ストレージバケットとの対応が分かりやすいように同じ名前にしています。
データ型:PDF
ファイルglobパターン: インデックス化を行うファイルの拡張子を選択します。
複数ファイル種別ある場合は指定する必要がありますが、今回はPDFファイルだけなのでデフォルトのままで問題ありません。

実行してエラー無く完了すればインデックスが作成できています。
インデックスの作成は、ストレージバケットのドキュメントのサイズに依存するのですが、10分から2時間程度時間用を要します。
STEP3. コンテンツ生成
最後に、コンテンツ生成アクティビティを使用して、ドキュメントの情報を参照して生成AIに回答を作ってもらいます。

- コンテンツ生成アクティビティをデザイナーパネルに配置します。
- モデル名:生成AIを選択します。今回は
gpt-4o-2024-05-13を利用します。 - Prompt:質問文を入力します。
今回は以下のようにしています。
Apple の 10K を確認し、次の指標の簡潔な分析を提供してください。収益、負債、キャッシュ フロー、収入 - システムプロンプト:生成AIへの命令を入力します。
ロールを明確に与えることで精度が向上するため、今回は以下のようにしています。
あなたは 10K を理解するプロの金融アナリストです。 - コンテキストグラウンディング:
Existing index - インデックス:作成したインデックスを指定します。
"10Ks"

メッセージをログやメッセージボックスで変数を使用から「上位のテキスト」を選択することで、回答を確認することができます。
今回は、次のような結果が得られました。
正しくAppleの10K Formの内容を取得できているようです。

コンテキスト グラウンディングを利用することで、このような英語の文書から日本語で情報を取得することもできます。今回の業務はマーケターが行う作業を想定していますが、RPAなので、前段のインターネットからドキュメントをダウンロードする処理、後段のシステムに入力する処理やメールやSlackで通知する処理も自動化することができますので、業務全体の効率化が可能です。
その他のユースケース
その他のユースケースも紹介したいと思います。
スキャンされた画像PDFの読み取り
生成AI コンテンツ生成アクティビティは、インデックスを指定する方法とは別にファイルを指定する方法があります。これはインデックス作成時に行われていたドキュメントのアップロードやインデックス作成などの処理が内部で行われます。事前にインデックスを指定していた方が速く回答を得ることができますが、ドキュメントのアップロードが不要になり、より市民開発向けではあると思います。

現在、文字情報の入っていない画像PDFの場合、コンテキストグラウンディングはサポートされていませんが、このファイル指定を使う方法で対応できます。

Document Understandingの「ドキュメントをデジタル化アクティビティ」を用いて、画像PDFからテキスト情報を抽出します。それをテキストファイルに書き込みます。そのテキストファイルを指定することで画像PDFであっても情報を参照することができます。
コンテキスト グラウンディングの画像ファイル対応は、将来的な開発ロードマップに含まれていますので、将来的にはコンテキスト グラウンディングだけで対応することが可能です。
よくある質問の回答案作成
代表的なユースケースは、よくある質問の回答案作成でしょう。
FAQサイトやチケット管理システムからスクレイピングして情報を取得してきてもいいのですが、RAGの精度を高めるためには、CSV形式にして1行毎に質問と回答をセットにして記載したほうが良いとされています。
今回はDevDivesイベントで想定問答をExcelで作っていたので、それをCSV形式にして回答できるか確認しました。
ここで大事なことは質問と回答が1行でまとまっていることです。

プロンプト:
"コンテキストグラウンディングでは大規模言語モデルの変更は可能?"
システムプロンプト:
"質問に対して、パブリックプレビュー時点の動作とGA後の仕様を教えてください。開発ロードマップが存在すれば、そのバージョンを教えてください。"
回答:
"コンテキストグラウンディングで使用する大規模言語モデル(LLM)の変更については、埋め込みに利用するLLMは変更できないですが、RAGの実行時に使用するLLMは選択可能です[9]。"
これは、与えたプロンプトが、CSV No.9の「使用するLLMは変更することができますか?」と類似していると判断されているためです。大規模言語モデルとLLMとの類似性を正確に判断しています。
最後に
今回作成したコンテキストグラウンディングの処理は、公開することで他の人も使えるようになりますが、Orchestratorのフォルダで公開範囲を制限することにより、使用する人を制限できます。
これまでの全社共通のRAGでは、業務に特化したドキュメントは他への影響を考慮したり、IT管理担当者のリソース不足から優先度が下げざるを得なかったと思いますが、このUiPathの仕組みを利用することにより、安全に生成AIを利用できると思います。
インデックスを指定することで、他への影響も考慮せず、追加していくことができます。
今回はハルシネーションが起こらずにドキュメントの内容から上手く回答を得ることができました。
現在、無料プレビュー中なので、皆さんの部署で固有のドキュメントから回答を得ることができるか試してみてはいかがでしょうか?