はじめに
議事録自動化に取り組んでおりその途中経過を記載します。
S3に格納してある動画を文字起こしして要約してくれるところまでのフローをAWS Step Functionsで作成しました。
AWS Step Functionsワークフロー
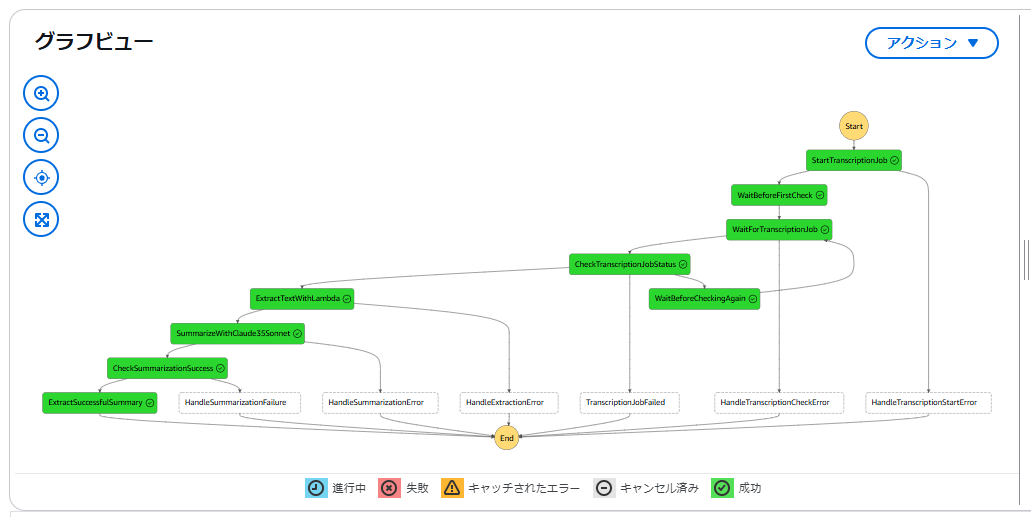
AWS Step Functionsワークフローの全体像はこんな感じです。

処理の流れを簡単に説明します。
- 1.文字起こし
- Amazon Transcribeで、文字起こし処理結果をjsonファイルで出力
- 2.抽出
- AWS Lambdaでjsonファイルから要約に必要な文字起こし情報のみ抽出し、txtファイルで出力(元のjsonファイルではサイズが大きすぎて、AIが処理できないため)
- 3.要約
- txtファイルをプロンプトに入力し、Amazon Bedrockで要約した結果をtxtファイルで出力(AIの呼び出しもAWS Lambdaを使用)
なので入力は動画(音声ファイル)1つ、出力はjson1つtxt2つの合計3つです。
実装
1.AWS Step Functions
下記のコードからワークフローを作成することができます。
<コード内で行っているAmazon Transcribeの設定>
・LanguageCode:言語
・ShowSpeakerLabels:話者分離を行うかどうか(trueは行う)
・MaxSpeakerLabels:話している人数(必須ではないが正確に指定した方が精度は上がると思われる)
※14行目:YOUR_BUCKET_NAMEは動画や出力結果を格納するS3バケット名
※134行目、188行目:"transcribe-text-extractor"、"bedrock-text-summarizer"は作成したLambda関数名(後述)
{
"Comment": "Transcription job followed by text extraction and Claude 3.5 Sonnet summarization with comprehensive error handling",
"StartAt": "StartTranscriptionJob",
"States": {
"StartTranscriptionJob": {
"Type": "Task",
"Resource": "arn:aws:states:::aws-sdk:transcribe:startTranscriptionJob",
"Parameters": {
"TranscriptionJobName.$": "States.Format('transcription-{}', $$.Execution.Name)",
"LanguageCode": "ja-JP",
"Media": {
"MediaFileUri.$": "$.inputFile"
},
"OutputBucketName": "YOUR_BUCKET_NAME",
"OutputKey.$": "States.Format('transcripts/{}.json', $$.Execution.Name)",
"Settings": {
"ShowSpeakerLabels": true,
"MaxSpeakerLabels": 3
}
},
"Retry": [
{
"ErrorEquals": [
"States.ServiceException",
"States.ThrottlingException"
],
"IntervalSeconds": 2,
"MaxAttempts": 3,
"BackoffRate": 2
}
],
"Catch": [
{
"ErrorEquals": [
"States.ALL"
],
"ResultPath": "$.error",
"Next": "HandleTranscriptionStartError"
}
],
"Next": "WaitBeforeFirstCheck"
},
"HandleTranscriptionStartError": {
"Type": "Pass",
"Parameters": {
"status": "FAILED",
"error.$": "$.error",
"message": "Failed to start transcription job",
"timestamp.$": "$$.State.EnteredTime"
},
"End": true
},
"WaitBeforeFirstCheck": {
"Type": "Wait",
"Seconds": 10,
"Next": "WaitForTranscriptionJob"
},
"WaitForTranscriptionJob": {
"Type": "Task",
"Resource": "arn:aws:states:::aws-sdk:transcribe:getTranscriptionJob",
"Parameters": {
"TranscriptionJobName.$": "States.Format('transcription-{}', $$.Execution.Name)"
},
"Retry": [
{
"ErrorEquals": [
"States.ServiceException",
"States.ThrottlingException"
],
"IntervalSeconds": 2,
"MaxAttempts": 3,
"BackoffRate": 2
}
],
"Catch": [
{
"ErrorEquals": [
"States.ALL"
],
"ResultPath": "$.error",
"Next": "HandleTranscriptionCheckError"
}
],
"Next": "CheckTranscriptionJobStatus"
},
"HandleTranscriptionCheckError": {
"Type": "Pass",
"Parameters": {
"status": "FAILED",
"error.$": "$.error",
"message": "Failed to check transcription job status",
"timestamp.$": "$$.State.EnteredTime"
},
"End": true
},
"CheckTranscriptionJobStatus": {
"Type": "Choice",
"Choices": [
{
"Variable": "$.TranscriptionJob.TranscriptionJobStatus",
"StringEquals": "COMPLETED",
"Next": "ExtractTextWithLambda"
},
{
"Variable": "$.TranscriptionJob.TranscriptionJobStatus",
"StringEquals": "FAILED",
"Next": "TranscriptionJobFailed"
}
],
"Default": "WaitBeforeCheckingAgain"
},
"WaitBeforeCheckingAgain": {
"Type": "Wait",
"Seconds": 30,
"Next": "WaitForTranscriptionJob"
},
"TranscriptionJobFailed": {
"Type": "Pass",
"Parameters": {
"status": "FAILED",
"error": {
"cause": "Transcription job failed",
"details.$": "$.TranscriptionJob.FailureReason"
},
"jobDetails.$": "$.TranscriptionJob",
"timestamp.$": "$$.State.EnteredTime"
},
"End": true
},
"ExtractTextWithLambda": {
"Type": "Task",
"Resource": "arn:aws:states:::lambda:invoke",
"Parameters": {
"FunctionName": "transcribe-text-extractor",
"Payload": {
"Records": [
{
"s3": {
"bucket": {
"name": "takeda-transcript"
},
"object": {
"key.$": "States.Format('transcripts/{}.json', $$.Execution.Name)"
}
}
}
]
}
},
"Retry": [
{
"ErrorEquals": [
"Lambda.ServiceException",
"Lambda.AWSLambdaException",
"Lambda.SdkClientException"
],
"IntervalSeconds": 2,
"MaxAttempts": 3,
"BackoffRate": 2
}
],
"Catch": [
{
"ErrorEquals": [
"States.ALL"
],
"ResultPath": "$.error",
"Next": "HandleExtractionError"
}
],
"ResultPath": "$.extractionResult",
"Next": "SummarizeWithClaude35Sonnet"
},
"HandleExtractionError": {
"Type": "Pass",
"Parameters": {
"status": "FAILED",
"error.$": "$.error",
"message": "Failed to extract text from transcription",
"timestamp.$": "$$.State.EnteredTime"
},
"End": true
},
"SummarizeWithClaude35Sonnet": {
"Type": "Task",
"Resource": "arn:aws:states:::lambda:invoke",
"Parameters": {
"FunctionName": "bedrock-text-summarizer",
"Payload": {
"bucket": "takeda-transcript",
"key.$": "States.Format('transcripts/{}.txt', $$.Execution.Name)"
}
},
"Retry": [
{
"ErrorEquals": [
"Lambda.ServiceException",
"Lambda.AWSLambdaException",
"Lambda.SdkClientException"
],
"IntervalSeconds": 2,
"MaxAttempts": 2,
"BackoffRate": 2
}
],
"Catch": [
{
"ErrorEquals": [
"States.ALL"
],
"ResultPath": "$.error",
"Next": "HandleSummarizationError"
}
],
"ResultPath": "$.summarizationResult",
"Next": "CheckSummarizationSuccess"
},
"HandleSummarizationError": {
"Type": "Pass",
"Parameters": {
"status": "FAILED",
"error.$": "$.error",
"message": "Failed to summarize text with Claude 3.5",
"timestamp.$": "$$.State.EnteredTime"
},
"End": true
},
"CheckSummarizationSuccess": {
"Type": "Choice",
"Choices": [
{
"Variable": "$.summarizationResult.Payload.statusCode",
"NumericEquals": 200,
"Next": "ExtractSuccessfulSummary"
}
],
"Default": "HandleSummarizationFailure"
},
"HandleSummarizationFailure": {
"Type": "Pass",
"Parameters": {
"status": "FAILED",
"message.$": "$.summarizationResult.Payload.body.message",
"sourceFile.$": "$.summarizationResult.Payload.body.sourceFile",
"modelId.$": "$.summarizationResult.Payload.body.modelId",
"region.$": "$.summarizationResult.Payload.body.region",
"timestamp.$": "$$.State.EnteredTime"
},
"End": true
},
"ExtractSuccessfulSummary": {
"Type": "Pass",
"Parameters": {
"status": "SUCCESS",
"summary.$": "$.summarizationResult.Payload.body.summary",
"sourceFile.$": "$.summarizationResult.Payload.body.sourceFile",
"summaryFile.$": "$.summarizationResult.Payload.body.summaryFile",
"model.$": "$.summarizationResult.Payload.body.model",
"execution.$": "$$.Execution.Name",
"completedAt.$": "$$.State.EnteredTime"
},
"End": true
}
}
}
2.AWS Lambda
次に抽出と要約のためのLambda関数をそれぞれ作成します。
2-1 抽出用関数(transcribe-text-extractor)
この関数ではAmazon Transcribeの処理で出力されたjsonファイルから話者とテキスト部分のみを抽出します。
抽出結果の例

import json
import boto3
import os
s3_client = boto3.client('s3')
def lambda_handler(event, context):
try:
# Step Functionsから渡されるペイロードを処理
bucket = event['Records'][0]['s3']['bucket']['name']
key = event['Records'][0]['s3']['object']['key']
# 出力先の設定
output_bucket = os.environ.get('OUTPUT_BUCKET', bucket)
base_key = key.replace('.json', '')
output_key = f"{base_key}.txt"
print(f"Processing file {bucket}/{key}")
# S3からJSONファイルを取得
response = s3_client.get_object(Bucket=bucket, Key=key)
transcribe_json = json.loads(response['Body'].read().decode('utf-8'))
# 話者分離の結果を抽出
extracted_text = ""
# 話者分離が有効かどうかを確認
if ('results' in transcribe_json and 'speaker_labels' in transcribe_json['results'] and
'segments' in transcribe_json['results']['speaker_labels']):
print("Processing speaker diarization results")
results = transcribe_json['results']
speaker_segments = results['speaker_labels']['segments']
items = results['items']
# 単語と時間情報をマッピング
word_timing = {}
for item in items:
if 'start_time' in item:
start_time = float(item['start_time'])
word_timing[start_time] = item
# 各話者セグメントを処理
current_speaker = None
current_utterance = []
for segment in speaker_segments:
speaker = segment['speaker_label']
# 話者が切り替わったら出力
if current_speaker and current_speaker != speaker and current_utterance:
# 単語をスペースなしで結合
utterance_text = "".join(current_utterance)
extracted_text += f"【{current_speaker}】: {utterance_text}\n\n"
current_utterance = []
current_speaker = speaker
# セグメント内の単語を処理
for word_segment in segment['items']:
if 'start_time' in word_segment:
start_time = float(word_segment['start_time'])
if start_time in word_timing:
word_item = word_timing[start_time]
if 'alternatives' in word_item and word_item['alternatives']:
word = word_item['alternatives'][0]['content']
current_utterance.append(word)
# 最後の話者の発話を追加
if current_speaker and current_utterance:
utterance_text = "".join(current_utterance)
extracted_text += f"【{current_speaker}】: {utterance_text}\n\n"
# 話者分離がない場合は通常の文字起こし
else:
print("No speaker diarization found, using standard transcript")
if 'results' in transcribe_json and 'transcripts' in transcribe_json['results']:
for transcript in transcribe_json['results']['transcripts']:
extracted_text += transcript['transcript'] + '\n'
print(f"Extracted text length: {len(extracted_text)} characters")
# テキストファイルとしてS3に保存
s3_client.put_object(
Body=extracted_text,
Bucket=output_bucket,
Key=output_key,
ContentType='text/plain'
)
print(f"Text saved to {output_bucket}/{output_key}")
return {
'statusCode': 200,
'body': {
'message': 'Text with speaker labels successfully extracted and saved',
'source_file': f"{bucket}/{key}",
'output_file': f"{output_bucket}/{output_key}"
}
}
except Exception as e:
print(f"Error: {str(e)}")
return {
'statusCode': 500,
'body': {
'message': f"Error processing file: {str(e)}",
'source_file': f"{bucket}/{key}" if 'bucket' in locals() and 'key' in locals() else "unknown"
}
}
2-2 要約用関数(bedrock-text-summarizer)
この関数では先ほど抽出したテキストを含めたプロンプトをAmazon BedrockでAIモデルに問い合わせて、結果を取得し、txtファイルで出力します。
※諸事情によりオレゴンリージョンに設定していますが、本来はStep FunctionsやLambdaと同じリージョンのBedrockを使うのが望ましいです。
import json
import boto3
import os
from botocore.exceptions import ClientError
# S3クライアントの初期化
s3_client = boto3.client('s3')
# Bedrockクライアントの初期化 - オレゴンリージョン(us-west-2)を明示的に指定
bedrock_runtime = boto3.client(
service_name='bedrock-runtime',
region_name='us-west-2' # オレゴンリージョンに固定
)
# Claude 3.5 Sonnet v2 のモデルID(2024年10月22日リリース版)
MODEL_ID = "anthropic.claude-3-5-sonnet-20241022-v2:0"
def lambda_handler(event, context):
try:
# 入力パラメータの取得
bucket = event['bucket']
key = event['key']
print(f"Processing text file for summarization with Claude 3.5 Sonnet v2 (us-west-2): {bucket}/{key}")
# S3からテキストファイルを取得
response = s3_client.get_object(Bucket=bucket, Key=key)
source_text = response['Body'].read().decode('utf-8')
# テキスト長の確認と調整(Claude 3.5 Sonnet は約200,000トークン処理可能)
# トークン数は大まかに文字数の3/4と見積もる
estimated_tokens = len(source_text) * 0.75
max_tokens = 180000 # 200,000から余裕を持たせる
if estimated_tokens > max_tokens:
print(f"Text too long (estimated {estimated_tokens} tokens), truncating...")
# 最大トークン数から逆計算して文字数制限
source_text = source_text[:int(max_tokens / 0.75)]
# Claude用のプロンプトを作成(JSON形式)
messages = [
{
"role": "user",
"content": [
{
"type": "text",
"text": f"""以下のテキストは日本語の会議やインタビューの書き起こしです。
このテキストの要点をまとめて、簡潔かつ包括的な要約を作成してください。
話者ごとにまとめを作ってください。
要約には以下を含めてください:
1. 主要な議題とトピック
2. 重要なポイントや提案
3. 決定事項や結論
4. 将来の計画や次のステップ
可能な限り明確で構造化された要約を作成し、元の内容を正確に反映することを心がけてください。
専門用語が使われている場合は、それを維持してください。
テキスト:
{source_text}"""
}
]
}
]
# Bedrock APIリクエストを構築
request_body = {
"anthropic_version": "bedrock-2023-05-31",
"max_tokens": 4000,
"messages": messages,
"temperature": 0.3, # 要約には低い温度設定が適切
"top_p": 0.9
}
print(f"Calling Bedrock with model ID: {MODEL_ID}")
# Bedrockを呼び出して要約を生成
response = bedrock_runtime.invoke_model(
modelId=MODEL_ID,
body=json.dumps(request_body),
contentType="application/json",
accept="application/json"
)
# レスポンスを解析
response_body = json.loads(response.get('body').read())
# 応答を抽出
summary = ""
if "content" in response_body and len(response_body.get('content', [])) > 0:
summary = response_body.get('content', [{}])[0].get('text', '')
if not summary:
print("Warning: Empty response from Bedrock")
print(f"Response body: {response_body}")
summary = "要約を生成できませんでした。"
print(f"Summary generated successfully. Length: {len(summary)} characters")
# 要約結果をS3に保存
summary_key = key.replace('.txt', '-summary.txt')
s3_client.put_object(
Body=summary,
Bucket=bucket,
Key=summary_key,
ContentType='text/plain; charset=utf-8'
)
print(f"Summary saved to {bucket}/{summary_key}")
# 結果を返す
return {
'statusCode': 200,
'body': {
'message': 'Text successfully summarized with Claude 3.5 Sonnet v2',
'sourceFile': f"{bucket}/{key}",
'summaryFile': f"{bucket}/{summary_key}",
'summary': summary,
'model': MODEL_ID,
'region': 'us-west-2',
'sourceTextLength': len(source_text)
}
}
except ClientError as e:
error_code = e.response.get('Error', {}).get('Code', 'UnknownError')
error_message = e.response.get('Error', {}).get('Message', str(e))
print(f"AWS Client Error: {error_code} - {error_message}")
return {
'statusCode': 500,
'body': {
'message': f"AWS Client Error: {error_code} - {error_message}",
'sourceFile': f"{bucket}/{key}" if 'bucket' in locals() and 'key' in locals() else "unknown",
'region': 'us-west-2',
'modelId': MODEL_ID
}
}
except Exception as e:
print(f"Unexpected Error: {str(e)}")
import traceback
traceback.print_exc()
return {
'statusCode': 500,
'body': {
'message': f"Error summarizing text: {str(e)}",
'sourceFile': f"{bucket}/{key}" if 'bucket' in locals() and 'key' in locals() else "unknown",
'region': 'us-west-2',
'modelId': MODEL_ID
}
}
3.IAMロール
AWS Step Functionsを実行するためには適切な権限設定が必要です。
AWS Step Functions
・transcribe:StartTranscriptionJob - 文字起こしジョブの開始
・transcribe:GetTranscriptionJob - 文字起こしジョブのステータス確認
・lambda:InvokeFunction - Lambda関数の呼び出し
AWS Lambda(抽出用)
・s3:GetObject - 入力ファイルを取得する権限
・s3:PutObject - 出力ファイルを保存する権限
AWS Lambda(要約用)
・s3:GetObject - テキストファイルを読み取る権限
・s3:PutObject - 要約結果を保存する権限
・bedrock:InvokeModel - Claude 3.5 Sonnetモデルを呼び出す権限
実行
実行手順
1.要約したい動画や音声を自身で作成したS3バケットに格納します。
2.AWS Step Functionsの「実行を開始」ボタンをクリック
3.json形式で格納した動画(音声)のS3 URIを指定
{
"inputFile": "s3://YOUR_BUCKET_NAME/test/サンプル会議音声1.wav"
}
4.「実行を開始」ボタンをクリック
結果
実行開始後は視覚的に処理を追跡することができます。

最後まで正常に完了したらこのようになります。
S3バケットを確認するとtranscriptsというフォルダの中に、要約されたテキストファイルが作成されています!

おわりに
今後は
・Amazon Transcribeの出力に含まれる信頼度を用いて文字起こし結果の精度向上
・複数AIモデルの比較およびプロンプトの検証
・Step Functionsの起動方法やファイル入出力の場所の検討
など行っていきたいと考えています。