これはなに
それは2025年のある日のこと。
🐶「AI系のアプリ作れるようになりたいなぁ〜」
👴『よう、もんた。なんか悩んでそうやん。』
🐶「あ、おぢ。」
🐶「いや〜、聞いてくれよ。AI使ったアプリケーションを開発できるようになりたいんだけどさ、何から手をつけたらいいかわかんねぇんだよな〜」
👴『おまっ、あつすぎ。まじで。AIとか未来じゃん。未来作ろうとしてんじゃん。』
🐶「言い過ぎだよwwwww」
🐶「でも、ありがとな。なんかそんな考えてくれてて嬉しいわ。がんばろって思えた。」
そしてもんたはAIアプリ開発ができるようになるために、駆け出していったのであった…
冗談はさておき真面目な背景を書いていきます。
『AIを使ったアプリケーションを開発するスキルを高めたいな〜』ということで、LangChainやLangGraphについて学習し、そのアウトプットとして読書メモからテストを作成してくれるというアプリを開発しました。
- ReadumのGitHubリポジトリ
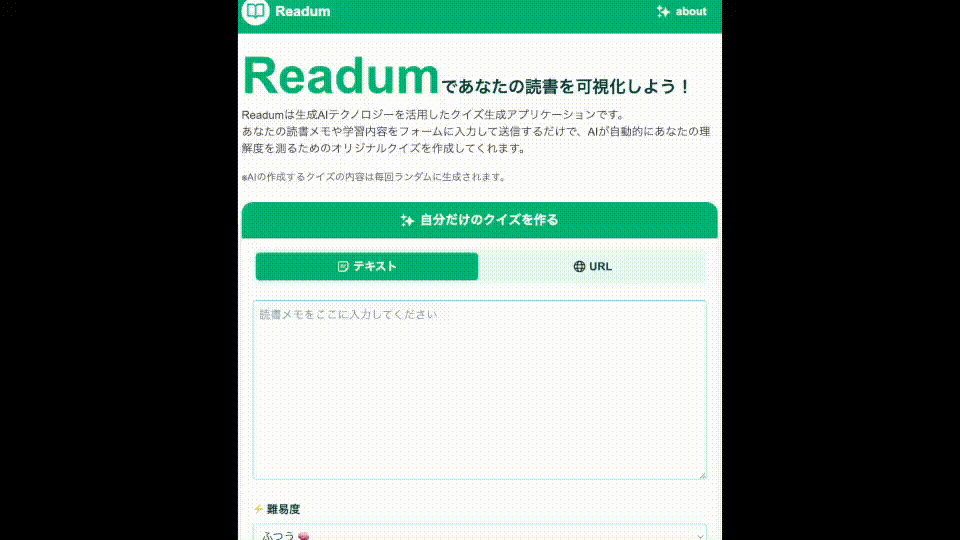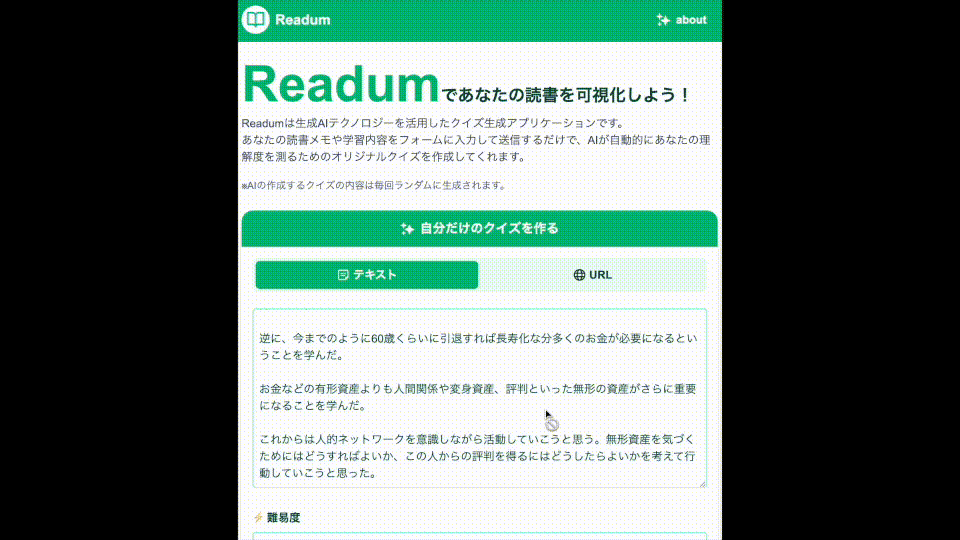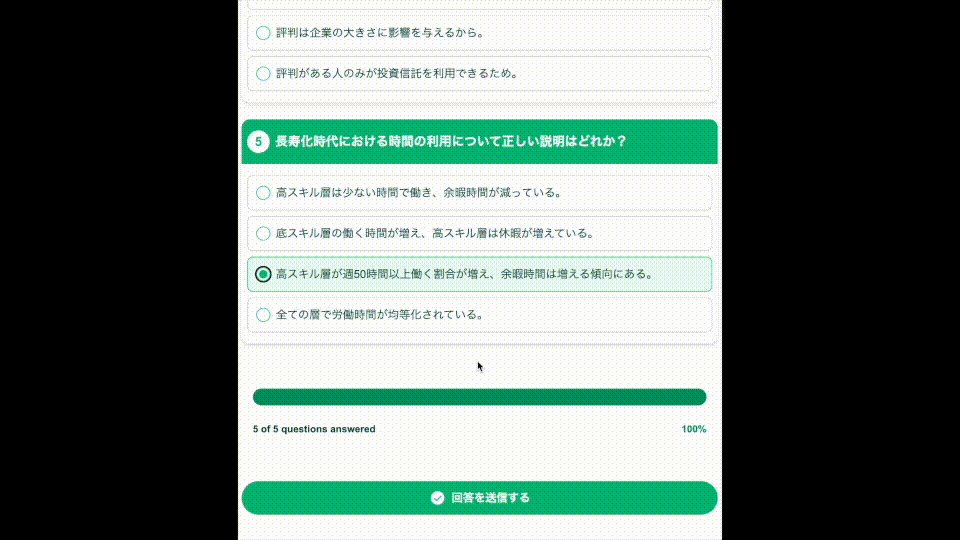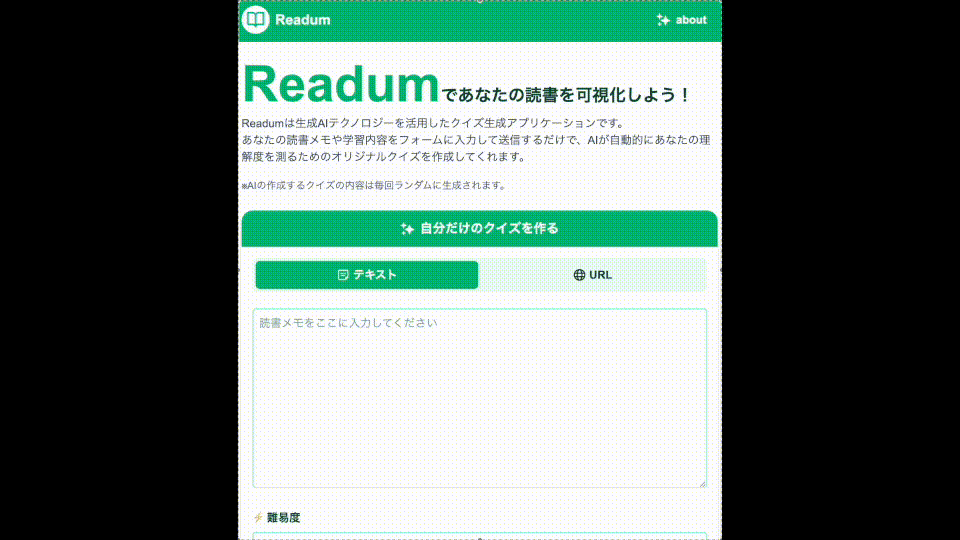
Readumはユーザーからの入力(読書メモ)から4択形式のクイズを作成してくれるアプリケーションになっています。
ユーザーはクイズに答えるだけで、自分の読書の理解度を可視化することができます。
Readumを使うことで、自分の読書の理解度がわかるので、モチベーションにもなるし、復習にも使えるかと思います。
🐶「クイズの生成には1分〜3分程度かかっちゃうのはご了承ください…(RAGや生成結果のレビューなどを行なっているため)」
個人開発だし、できるだけコストかけたくなかったという背景から、CloudRunにて必要最低限のスペックでデプロイしてます。
ちなみにReadumという名前ですが、「読む」を意味する英語のReadingと、「試す」「評価する」を意味するラテン語のtestum(英語のtestの語源)を掛け合わせた造語です。
個人的には結構いけてるんじゃあないかって思っています。
さて、この記事では私がReadumの開発を行うプロジェクト(通称、AIアプリ開発スキルを身につけるプロジェクト)でどんなことをしたのか、Readumのディレクトリ構成やフロントエンド、バックエンドに関して書いていこうかと思います。
特にバックエンドの部分ではlanggraph-supervisorというライブラリを使って実装したReadumのクイズ生成のフローについて詳しく解説しているのでぜひご覧ください!!
🐶「langgraph-supervisorのところだけでも読んでね!」
ぜひ最後までお読みいただけますと幸いです!
技術スタック
| 分野 | 技術・ライブラリ名 | 主な役割 |
|---|---|---|
| バックエンド | Python | サーバーサイド プログラミング言語 |
| FastAPI | 高パフォーマンス Web API フレームワーク | |
| AI | LangChain | AIロジック構築、LLMアプリケーション開発 |
| LangGraph | 複雑なAIエージェント・フロー構築 | |
| FAISS | RAGのための効率的なベクトル検索 | |
| フロントエンド | Next.js (App Router) | Reactフレームワーク (UI構築・ルーティング等) |
| React | ユーザーインターフェース構築ライブラリ | |
| Tailwind CSS | ユーティリティファースト CSSフレームワーク | |
| インフラ | Cloud Run (GCP) | フルマネージドなコンテナ実行環境 (サーバーレス) |
| Cloud Storage (GCP) | スケーラブルなオブジェクトストレージ | |
| IaC | Terraform | インフラのコードによる構成管理 |
| 開発支援 | LangSmith | LLMアプリケーションのデバッグ・監視・テスト |
Readumを開発するまでにやったこと
このプロジェクトで達成したいことやTODOをNotionでまとめた
Notionにてこのプロジェクトで達成したいことやTODOリストをまとめました。
以下のリンクより確認できます。
個人プロジェクトだったので、「なぜやるのか」「やった結果どうなりたいのか」「進捗はどんな感じか」を明確にしないと続かないなと思ったので、ここはしっかりと仕組み化するようにしました。
特に、モチベーションの維持に役立ったのは「Looker Studioで学習時間を可視化する」のと「1週間ベースでTODOリストを作成する」になります。
個人的にLooker Studioで学習時間を可視化するのはやった分だけグラフが積み上がっていく感じが癖になるので非常におすすめです。
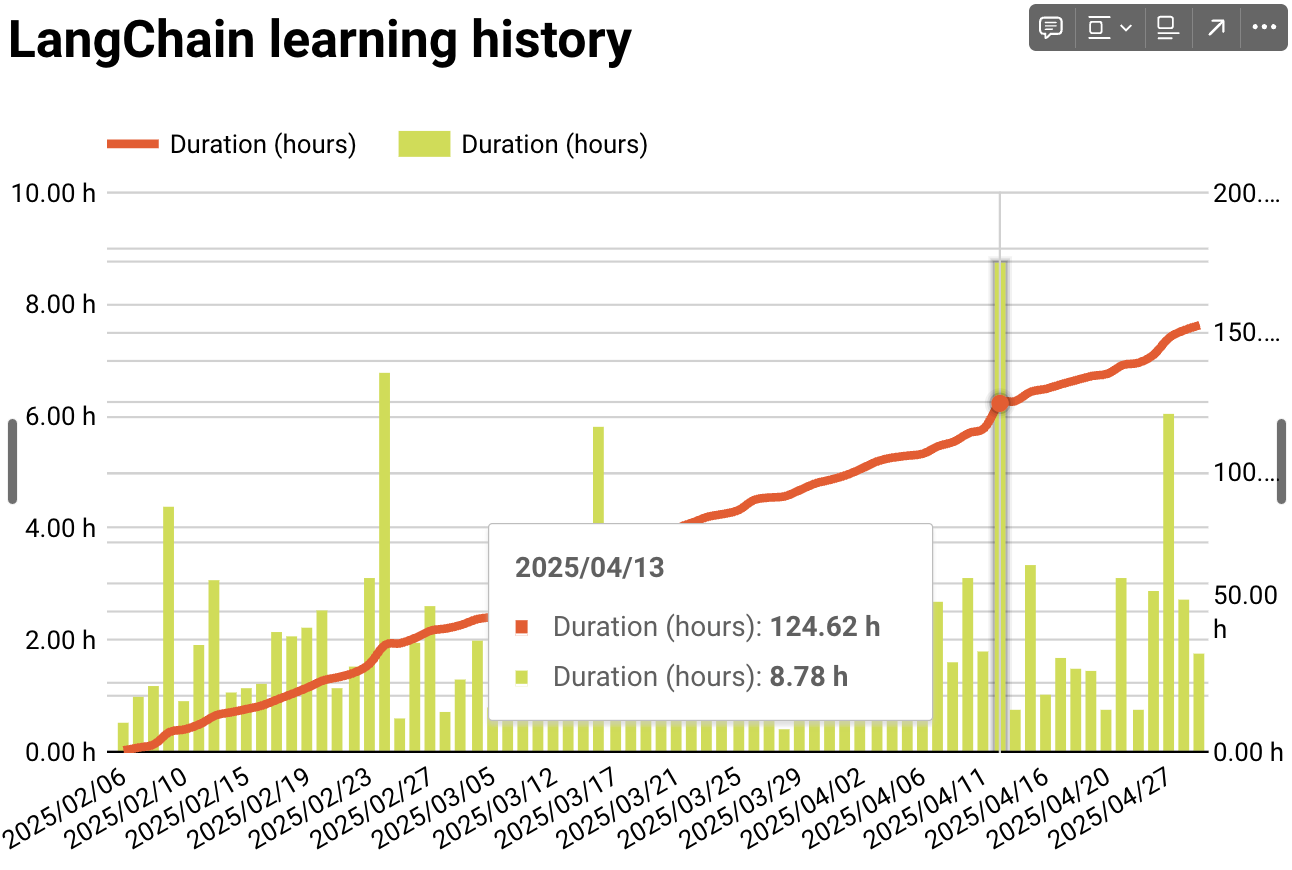
🐶「toggl trackとGASを使ってLooker Studioにグラフ化してるよ。もしかしたら記事にするかも。」
以下の画像のように、1週間ベースでTODOを管理するのもよかったです。
いい塩梅に区切りがつくので、「まぁ、集中すっか」っていう気になることが多かったです。
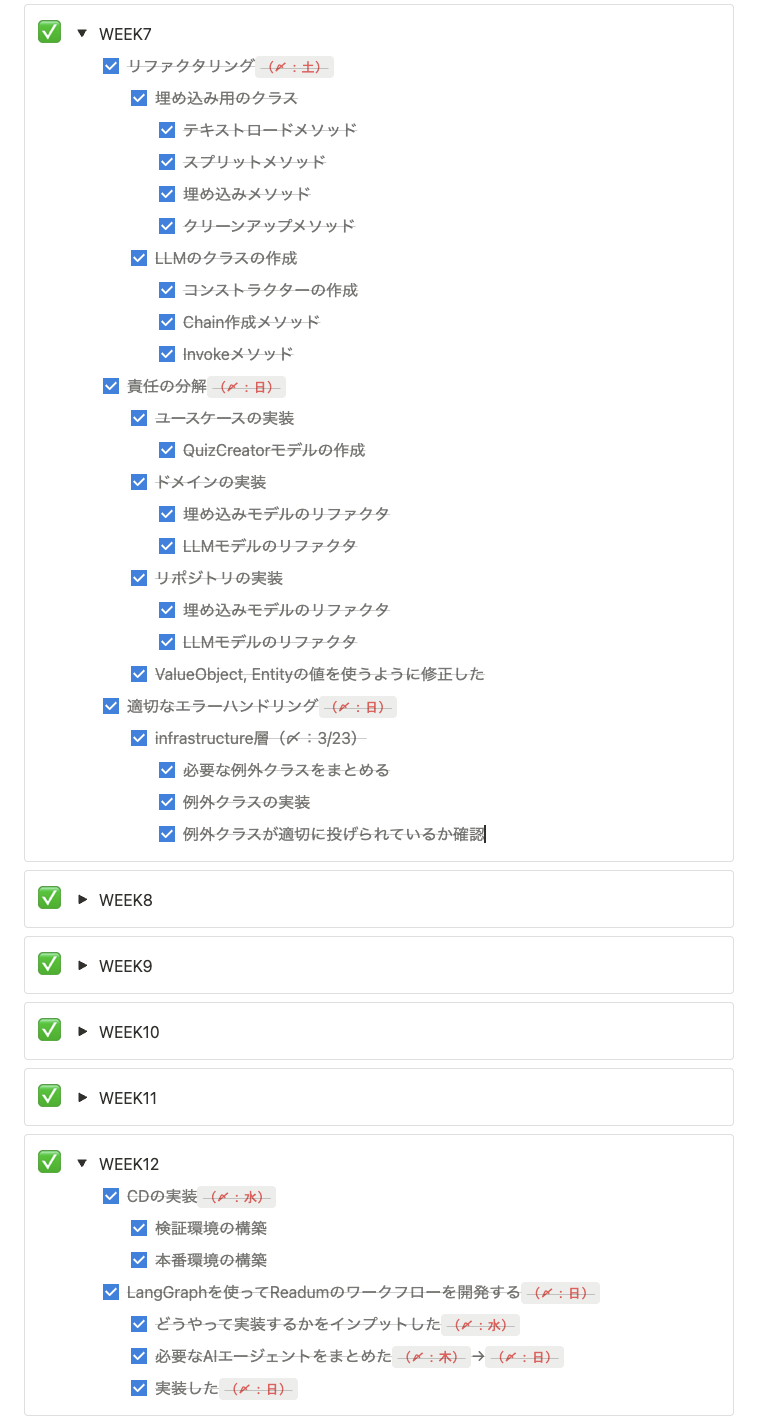
🐶「1週間ベースでタスクを区切ることの効果をおぢが解説」
🐶「ねえねえ、おぢ!ボク、毎日やることをちゃんとやりたいんだけど、『1週間ごと』にタスクを区切るっていうのが、なんだかボクには合ってそうな気がするんだ。もうちょっと詳しく、その効果を教えてくれない?」
👴『ほう、イッヌは勉強熱心じゃのう。1週間ごとにタスクを区切るというのは、確かに多くのイッヌや人間にとっても、とても効果的なやり方の一つじゃよ。』
🐶「うん!なんだか、毎日だと細かすぎる気もするし、1ヶ月だと長すぎて忘れちゃいそうで…」
👴『うむ、その感覚は正しいかもしれんな。1週間ごとにするメリットは、脳にとっても、実際の行動にとっても、いくつかあるんじゃ。』
🐶「どんなメリットがあるの?」
👴『まず一つは、「計画と実行のちょうど良いバランス」が取れることじゃ。1日だけだと、どうしても目の前のことだけで精一杯になりがちじゃが、1週間という期間で見ると、少し先のことも考えつつ、具体的な行動に落とし込みやすいんじゃ。脳は、あまりに遠い未来のことはイメージしにくいが、1週間くらいなら見通しを立てやすいからのう。』
🐶「なるほど。じゃあ、ボクが「今週は新しい公園のルートを3つ覚える!」って決めたら、毎日少しずつ挑戦できるし、途中で「今日は雨だから明日にしよう」って調整もしやすいってこと?」
👴『その通りじゃ。それが二つ目のメリット、「柔軟性を持って調整しやすい」ということにつながる。1週間の中であれば、ある日のタスクが終わらなくても、別の日にカバーしやすい。急に新しいおもちゃを買ってもらって遊びたくなっても、計画に少し余裕を持たせておけば対応できるじゃろう。』
🐶「うんうん、それは助かるな!毎日ギチギチだと疲れちゃうもんね。」
👴『そうじゃな。そして三つ目は、「モチベーションを維持しやすい」ことじゃ。週の初めに「今週はこれをやるぞ!」と目標を立てて、週末に「やった、できた!」と達成感を味わう。このサイクルは、脳にとってとても良い刺激になる。目標を達成すると、さっきも話した「ドーパミン」という嬉しい気持ちになる物質が出て、次も頑張ろうという気持ちにさせてくれるんじゃ。』
🐶「そっか!週末にご褒美のおやつをもらえる!みたいな感じかな?」
👴『まさにそうじゃ。そして四つ目は、「進捗が見えやすく、振り返りがしやすい」こと。1週間ごとに「どれくらいできたかな?」「次はどうしようかな?」と振り返ることで、自分の成長も感じられるし、次の1週間の計画も立てやすくなる。もし、あまり進まなくても、「じゃあ来週はもう少し頑張ろう」とか「やり方を変えてみよう」と考えるきっかけになるんじゃ。』
🐶「ふむふむ。1週間って、なんだか丁度いい長さなんだね。」
👴『そうじゃな。脳科学で言うと、「ツァイガルニク効果」というのも少し関係しておるかもしれん。これは、完了したことよりも、中断したり未完了だったりすることの方が記憶に残りやすい、という心の働きじゃ。週の目標を立てて意識することで、「あ、あれをやらなきゃ」という気持ちが働き、目標達成に向かいやすくなることもあるんじゃよ。』
🐶「へえー!面白いね!じゃあ、1週間ごとにタスクを区切るときに、何かコツってあるの?」
👴『うむ。いくつかあるぞ。
* 週の初めに、しっかりと計画の時間をとること。 何をどれくらいやるか、具体的に決めるんじゃ。
* 全部を詰め込みすぎないこと。 少し余裕を持たせておくと、急なことにも対応できるし、気持ちも楽じゃ。
* 週の終わりには、必ず振り返りの時間をとること。 できたこと、できなかったこと、次にどうするかを考えるんじゃ。
* 目に見える形にすると良いぞ。 例えば、カレンダーに書き込んだり、リストを作ったりするんじゃ。そうすると、イッヌも忘れにくいじゃろう。』
🐶「なるほどー!おぢ、ありがとう!1週間ごとにタスクを区切るの、もっと好きになったよ。なんだか、うまくやれそうな気がしてきた!」
👴『それは良かった。何事も、自分に合ったやり方を見つけて、楽しみながら続けるのが一番じゃからな。イッヌのペースで、色々試してみると良いじゃろう。』
なんかおぢが説明している感じだと効果がありそうですね。
UdemyでLangChainについて学習した
まず、LangChainの基礎を学ぶために以下のUdemy講座よりLangChainの基礎を学びました。
結論からいうと、こちらの講座はめちゃくちゃおすすめです!!
LangChainについて全く知らない人でも、「LangChainとは何か」がわかる内容となっています。
こちらの講座では、
- LangChainを用いて、X・LinkedInのプロフィールをスクレイピングし、ユーザーのまとめを作る
- RAGやベクトルDBを用いて、長いPDFを参照しながら回答してくれるチャットbotの開発
- LangGraphのハンズオン
- MCPの基礎
などいわゆるAIアプリケーション開発の基礎を学べます。
個人的にはベクトルDBを用いたRAGの実装の部分が大変ためになる内容でした!
実際、ReadumでもRAGを使っており、この実装部分はこのUdemy講座で学んだことが大きく貢献しています!!
🐶「字幕はあるけど音声は英語なので若干注意が必要だよ」
Readumのフロントエンドについて
ここからは、Readumのフロントエンドに関して話していこうかと思います。
1. v0で会話を進めながらデザインを爆速で固める
デザインの雛形はv0を使って作成しました。
クイズアプリのデザインってどんなのがいいのかパッと思い浮かばなかったので、AIと会話をしながら作っていき、アイデアを固めていきました。
🐶「AIがいい感じのデザインを作ってくれるから、『とりあえずアイデアなんかほしいな』ってときにはおすすめ!」
いい感じのデザインが思い浮かんだら、Figmaに落とし込んでデザインのブラッシュアップを行いました。
🐶「v0からFigmaにexportするみたいな機能ってないのかな?それがあるとデザインを作る作業はもっと楽になった…!」
余談ですが、Readumのクイズ結果画面のデザインは結構気に入っています。
数字が0から上がっていくデザインや直感的に理解度がわかる内容になっていると思ってます…はい。
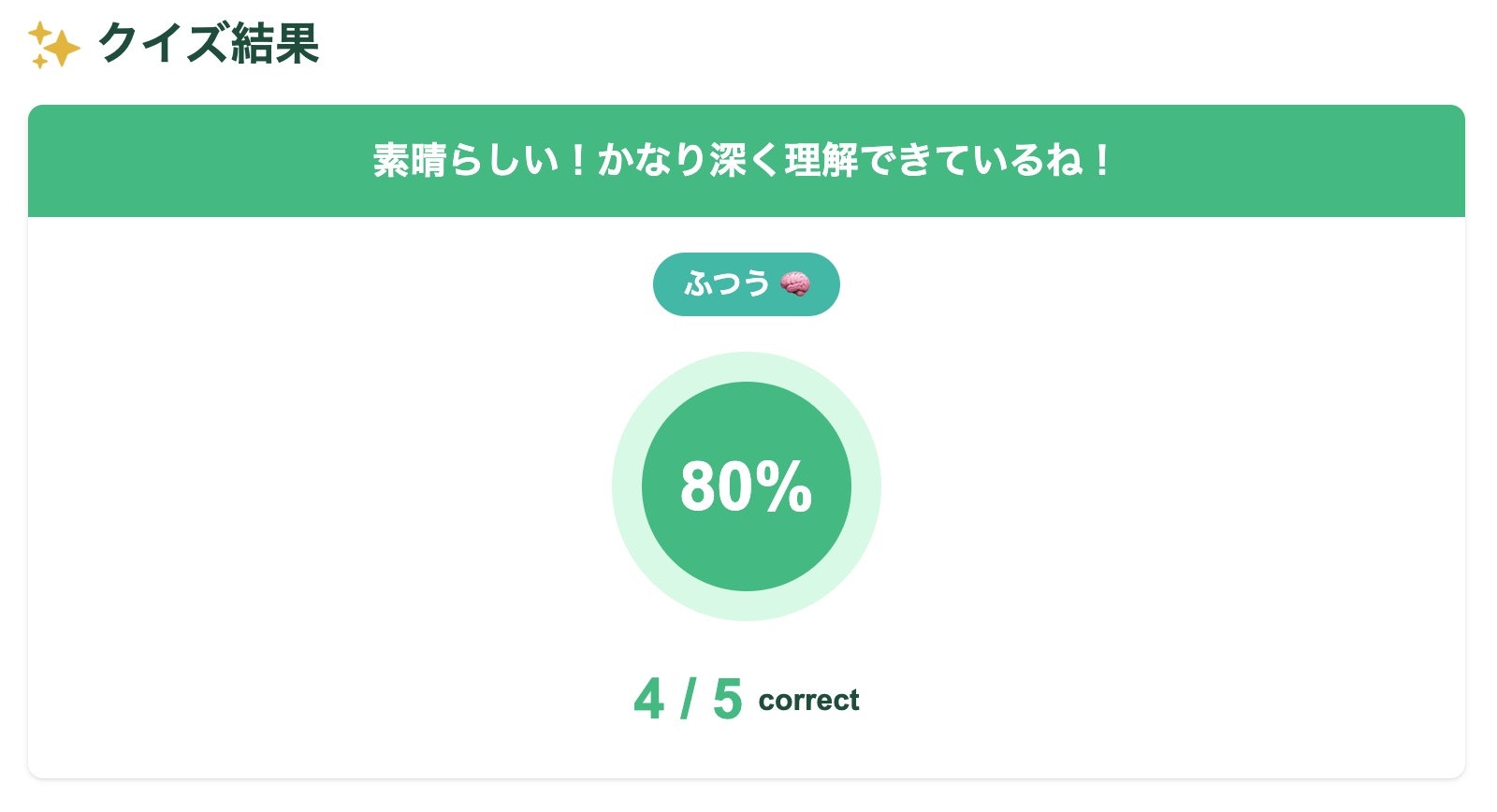
ちなみに、Readumのクイズの結果画面は動的に生成されるようになっているので、リンクをシェアするだけですぐに正答率がわかるようになっています。
🐶「ここはこだわりポイント」
2. コロケーションを意識したディレクトリ構成
Readumのフロントエンドのディレクトリ構成はコロケーションを意識した設計になっています。
コロケーションとは、『関連したファイルは近い場所に配置しましょうね。』という考え方です。
コロケーションを意識した設計になっていれば、関連するファイルが全て近い場所に配置されているので、「ディレクトリA」を開いて…「ディレクトリB」を開いて…みたいなことがなくなります。
一つのディレクトリに関連するファイルが全て格納されているので、そのような手間がなくなるんです。
🐶「コロケーションとは?」
🐶「ねぇねぇ、おぢ!最近よく聞く『コロケーション』って、なんだか難しそう…ぼくにも分かるように教えてほしい!」
👴『おお、イッヌか。コロケーションじゃな。よしよし、任せておけ。そんなに難しい話ではないんじゃよ。』
🐶「ほんと? ワクワク!」
👴『うむ。まずのう、「コロケーション」というのは、簡単に言うと 「関連するものを、同じ場所にまとめて置こうね」 という考え方じゃ。』
🐶「ふむふむ。関連するもの…?」
👴『そうじゃ。例えばイッヌが、お気に入りのオモチャで遊ぶとしよう。オモチャ箱、オモチャを投げるためのボール、オモチャを隠すための毛布…これらが全部バラバラの部屋にあったら、遊ぶたびにあちこち探し回って大変じゃろ?』
🐶「うーん、確かに!あっち行ったりこっち行ったりで、遊ぶ前に疲れちゃう!」
👴『じゃろう? これをプログラミング、特にNext.jsでウェブサイトを作るときに置き換えて考えてみるんじゃ。』
『以前はのう、例えば「お知らせページ」を作るとき、そのページの見た目を作るファイル(HTMLみたいなもの)、動きをつけるファイル(JavaScriptみたいなもの)、デザインを指定するファイル(CSSみたいなもの)、テスト用のファイル…これらが全部別々のフォルダに置かれていたんじゃ。』
🐶「えー!それじゃあ、「お知らせページ」をちょっと直したいなって思ったとき、いろんなフォルダを開けなきゃいけないの?」
👴『その通りじゃ。それがの、コロケーションだと、「お知らせページ」っていうフォルダを作って、その中に「お知らせページの見た目ファイル」「お知らせページの動きファイル」「お知らせページのスタイルファイル」「お知らせページのテストファイル」…ぜーんぶ一緒に入れちゃうんじゃ。』
🐶「わー!それなら、「お知らせページ」フォルダを開けば、全部そこにあるってことだね!便利そう!」
👴『そうなんじゃ。特に最近のNext.js(App Routerという仕組み)では、このコロケーションがとてもやりやすくなっておる。ページのファイル(page.tsxとかpage.jsって名前が多いのう)のすぐ隣に、そのページでしか使わない部品(コンポーネントって言うんじゃ)や、その部品専用のスタイルファイル、テストファイルを置けるようになったんじゃよ。』
🐶「へぇー!じゃあ、コロケーションのいいところって、ファイルが探しやすくなること?」
👴『うむ、それも大きなメリットじゃな。他にもこんないいことがあるんじゃ。』
- 👴『見通しが良くなる:どこに何があるかパッと見て分かりやすい。』
- 👴『部品の独立性が高まる:その部品と関連ファイルがセットになっているから、別の場所で使いたくなったときも、ごそっと持って行きやすい。』
- 👴『修正しやすい:「お知らせページ」のこの部品を直そう、と思ったら、関連ファイルが近くにあるから、あちこち見なくて済む。』
🐶「おー!なんだかスッキリ整理整頓されたお部屋みたい!」
👴『まさにその通りじゃ。でもな、注意点も少しあるぞ。』
🐶「注意点?」
👴『うむ。何でもかんでも一つの場所に詰め込みすぎると、逆にゴチャゴチャしてしまうこともある。それから、いろんなページで使う共通の部品(例えば、サイト全体で使うボタンとか)は、やっぱりみんながアクセスしやすい共有の場所に置いた方が良い場合もあるんじゃ。』
🐶「なるほどー。専用のものは近くに、みんなで使うものは共有場所に、って感じだね。」
👴『そういうことじゃ。具体的に、もし「ワンちゃんの日常ブログ」の記事ページを作るとしたら、どうなるか見てみようか。』
コロケーションしない場合(昔のやり方じゃと…)
/app
/blog
/[記事の名前]
page.tsx // ←記事の本体はここ
/components
BlogHeader.tsx // ←記事のヘッダー部品はここ
CommentForm.tsx // ←コメント入力部品はここ
/styles
blog-post.css // ←記事のデザインはここ
🐶「うーん、ファイルがあちこちにいるね…」
コロケーションした場合(Next.jsのApp Routerじゃと、こうできるんじゃ)
/app
/blog
/[記事の名前]
page.tsx // ←記事の本体
BlogHeader.tsx // ←記事のヘッダー部品も同じ場所!
BlogHeader.module.css// ←ヘッダーのデザインもすぐ隣!
CommentForm.tsx // ←コメント入力部品も同じ場所!
CommentForm.test.tsx // ←コメント部品のテストもすぐ隣!
🐶「わー![記事の名前]フォルダの中に、関連するものが全部集まってる!これなら、記事ページをいじりたいとき、このフォルダだけ見れば良さそう!」
👴『そうじゃろう? 特にそのページや機能のためだけに作られた部品やファイルは、こうして近くに置くと開発がとてもスムーズになるんじゃ。』
🐶「コロケーション、なんだか分かってきた!最初はちょっと慣れないかもしれないけど、確かに便利そう!」
👴『うむ。焦らず、少しずつ試してみると良いじゃろう。関連性の高いものを近くに置く、というシンプルな考え方じゃから、きっとイッヌもすぐに使いこなせるようになるぞ。』
🐶「うん!おぢ、ありがとう!これでぼくもコロケーションマスターを目指す!」
👴『はっはっは、頼もしいのう、イッヌ。頑張るんじゃぞ。』
ちなみにコロケーションを意識した設計にする上で、以下の記事を参考にしました!
🐶「おすすめだよ」
では、Readumのディレクトリについて説明していきます。
Readumの実際のディレクトリ構成は以下のようになっています。
frontend/
├── Dockerfile # コンテナ環境構築用定義
├── eslint.config.mjs # ESLint 設定
├── next-env.d.ts # Next.js 型定義ラッパー
├── next.config.ts # Next.js アプリ設定
├── postcss.config.mjs # PostCSS 設定
├── public/ # 静的ファイル配布ディレクトリ
│ └── icons/ # アイコン画像など
├── src/ # アプリケーションソース
│ ├── app/ # Next.js App ディレクトリ(ルーティング&ページ)
│ │ ├── about/ # “/about” ページ
│ │ │ └── page.tsx
│ │ ├── error.tsx # 共通エラーページ
│ │ ├── favicon.ico # ファビコン
│ │ ├── layout.tsx # 全ページ共通レイアウト
│ │ ├── not-found.tsx # 404 ページ
│ │ ├── opengraph-image.png # SNS シェア用 OG 画像
│ │ ├── page.tsx # ホームページ
│ │ └── result/ # “/result/[uuid]” 動的ルート
│ │ └── [uuid]/
│ │ ├── opengraph-image.tsx # 結果ページ OG 画像生成
│ │ └── page.tsx # 結果ページ本体
│ ├── components/ # 複数ページで使う汎用 UI コンポーネント
│ │ ├── footer/ # フッター
│ │ │ └── index.tsx
│ │ ├── header/ # ヘッダー
│ │ │ └── index.tsx
│ │ └── share-link/ # シェア用リンクボタン
│ │ └── index.tsx
│ ├── config.ts # フロントエンド全体の共通設定
│ ├── features/ # 機能別ディレクトリ(コロケーション)
│ │ ├── about/ # About 機能専用コンポーネント
│ │ │ └── index.tsx
│ │ ├── quiz-form/ # クイズ作成フォーム機能
│ │ │ ├── actions.ts # API 呼び出しや状態更新アクション
│ │ │ ├── components/ # quiz-form の UI パーツ群
│ │ │ │ ├── description/ # 説明入力用コンポーネント
│ │ │ │ │ └── index.tsx
│ │ │ │ ├── error-message/ # 入力エラー表示
│ │ │ │ │ └── index.tsx
│ │ │ │ ├── input-form/ # パラメータ入力フォーム本体
│ │ │ │ │ ├── actions.ts # 内部状態管理用アクション
│ │ │ │ │ ├── components/ # input-form 内パーツ群
│ │ │ │ │ │ ├── difficulty-level/ # 難易度セレクタ
│ │ │ │ │ │ │ ├── index.tsx
│ │ │ │ │ │ │ └── types.ts # 難易度選択型定義
│ │ │ │ │ │ ├── question-count/ # 問題数入力
│ │ │ │ │ │ │ └── index.tsx
│ │ │ │ │ │ ├── submit-button/ # 生成開始ボタン
│ │ │ │ │ │ │ └── index.tsx
│ │ │ │ │ │ └── textarea/ # メモ入力用テキストエリア
│ │ │ │ │ │ └── index.tsx
│ │ │ │ │ ├── index.tsx # input-form エントリーポイント
│ │ │ │ │ └── types.ts # input-form 型定義
│ │ │ │ └── quiz-list/ # 生成済みクイズ一覧表示
│ │ │ │ ├── components/ # quiz-list 用パーツ群
│ │ │ │ │ ├── progress-bar/ # 進捗バー
│ │ │ │ │ │ └── index.tsx
│ │ │ │ │ ├── question-card/ # 問題カード
│ │ │ │ │ │ └── index.tsx
│ │ │ │ │ └── submit-button/ # 回答送信ボタン
│ │ │ │ │ └── index.tsx
│ │ │ │ └── index.tsx # quiz-list エントリーポイント
│ │ │ ├── index.tsx # quiz-form 全体エントリーポイント
│ │ │ └── types.ts # quiz-form 型定義
│ │ └── result/ # クイズ結果表示機能
│ │ ├── components/ # result ページ UI パーツ
│ │ │ ├── result-card/ # 結果カード
│ │ │ │ └── index.tsx
│ │ │ └── top-message/ # トップメッセージ
│ │ │ └── index.tsx
│ │ ├── index.tsx # result 機能エントリーポイント
│ │ ├── types.ts # result 型定義
│ │ └── utils.ts # result ユーティリティ関数
│ └── styles/ # グローバルスタイル定義
│ └── globals.css
└── tsconfig.json # TypeScript コンパイラ設定
まずは、componentsディレクトリについて説明していきます。
componentsにはアプリケーション全体で使う汎用的なUIが格納されています。
headerやfooterなんかはどこでも使うUIなのでここに格納するようにしています。
components/
├── footer/
│ └── index.tsx
├── header/
│ └── index.tsx
└── share-link/
└── index.tsx
コロケーションではfeaturesが特に重要かなと思っています。
featuresにはドメイン領域のコードを格納します。
また、featuresのディレクトリ構成はappと1対1の関係になっています。
Readumにはresultページ(ユーザーのクイズの結果を表示する)があるのですが、そのresultページのロジック部分はfeatures配下にresultというディレクトリを作成し、管理するようにしています。
こうすることで、ルーティングとロジックを分離することができ、コード管理がしやすくなるかと思います!
🐶「appはルーティングの役割、featuresはロジックの役割とはっきりさせるためにもこれは大事!」
さらにReadumのディレクトリを理解してもらうために、featuresのquiz-formディレクトリについて解説していこうかと思います。
quiz-formは以下のような構成になっています。
features/
└── quiz-form/
├── actions.ts
├── components/
│ ├── description/
│ │ └── index.tsx
│ ├── error-message/
│ │ └── index.tsx
│ ├── input-form/
│ │ ├── actions.ts
│ │ ├── components/
│ │ │ ├── difficulty-level/
│ │ │ │ ├── index.tsx
│ │ │ │ └── types.ts
│ │ │ ├── question-count/
│ │ │ │ └── index.tsx
│ │ │ ├── submit-button/
│ │ │ │ └── index.tsx
│ │ │ └── textarea/
│ │ │ └── index.tsx
│ │ ├── index.tsx
│ │ └── types.ts
│ └── quiz-list/
│ ├── components/
│ │ ├── progress-bar/
│ │ │ └── index.tsx
│ │ ├── question-card/
│ │ │ └── index.tsx
│ │ └── submit-button/
│ │ └── index.tsx
│ └── index.tsx
├── index.tsx
└── types.ts
この中でも、入力フォームに関するコードを管理しているinput-formディレクトリに着目しましょう。
以下のように一つのディレクトリで全て管理してあるので、「入力フォームを修正したい場合は、input-formさえ意識していればOK」となるので、かなり保守が楽です。
components/
└── input-form/
├── components/
│ ├── difficulty-level/
│ │ ├── index.tsx
│ │ └── types.ts
│ ├── question-count/
│ │ └── index.tsx
│ ├── submit-button/
│ │ └── index.tsx
│ └── textarea/
│ └── index.tsx
├── index.tsx
└── types.ts
-
index.tsx:ベースとなるコード(server component)- データフェッチのAPIなどを
index.tsxで叩くようにする
- データフェッチのAPIなどを
-
types.ts:input-formディレクトリで扱う型を管理 -
actions.ts:server actionをここに書く。フォームのサブミットなどはここの役割。 -
components:index.tsx内で扱うUIコンポーネントを管理 -
utils.ts:ドメイン領域には関係ない関数などを管理
🐶「コロケーションを意識した設計だと、コンポーンエントを当てはめるだけでレイアウトができるし、保守する場所も明確なので、開発が楽!(になると思う)」
Readumのバックエンドについて
続いてReadumのバックエンドに関してです!
1. DDDをベースとしたクリーンアーキテクチャによるディレクトリパターン
Readumのバックエンドのディレクトリ構成は以下のようになっています。
backend/ # プロジェクトルート:環境構築・起動・テスト設定など
├── Dockerfile
├── Pipfile
├── Pipfile.lock
├── README.md
├── assets/ # サンプルドキュメント & 一時ファイル
│ ├── document.txt
│ └── tmp/ # FAISS インデックス用一時ディレクトリ
│ └── faiss
├── config/ # 設定管理(環境変数や各種設定値の読み込み)
│ └── settings.py
├── main.py
├── pytest.ini
├── src/ # アプリケーション本体
│ ├── api/ # HTTP レイヤー:エンドポイント定義と入出力モデル
│ │ ├── endpoints/
│ │ ├── exceptions/
│ │ └── models/
│ ├── application/ # ユースケース層:ビジネスロジックのオーケストレーション
│ │ ├── exceptions/ # ユースケース実行時の例外定義
│ │ ├── interface/ # ポート(抽象インターフェース)定義
│ │ ├── service/ # アプリケーションサービス実装(LLM呼び出しなど)
│ │ └── usecase/ # ユースケース実装
│ ├── domain/ # ドメイン層:エンティティ & ビジネスルール
│ │ ├── entities/ # ドメインモデル(エンティティ/値オブジェクト)
│ │ ├── repositories/ # リポジトリ抽象定義(永続化ポート)
│ │ └── service/ # ドメインサービス実装
│ └── infrastructure/ # インフラ層:外部連携・永続化の具体実装
│ ├── db/ # ベクトルDB 操作用クライアント
│ ├── exceptions/ # インフラ層の例外定義
│ ├── file_system/ # ファイル操作の具象実装
│ ├── llm/ # LLM連携の具象実装(RAG, 翻訳など)
│ └── storage/ # ストレージ(GCS等)具象実装
└── tests/ # 各レイヤーごとのユニットテスト
├── api/
├── application/
├── domain/
└── infrastructure/
Readum のバックエンドは、
-
クライアント→API層がリクエストを受け付ける -
API層→Application層のユースケースをトリガー Application層がDomain層のエンティティ/ドメインサービスを組み合わせてビジネス処理を実行-
Domain/Application層で定義した抽象インターフェースを、Infrastructure層が具体的に実装
という構造をとっています。
この分離により、ビジネスロジックは外部の技術変化に影響されず、純粋にドメインモデリングへ集中できるようになっています。
図にすると以下のようになります。
Application層、Domain層からInfrastructure層に矢印が向いているのは、Application層やDomain層で定義した抽象インターフェースの実装をになっているからになります。
Application層とDomain層に抽象インターフェースを定義し、具体的な実装はInfrastructure層の責任にすることで、Infrastructure に依存せず、ユースケースやドメインの処理フローだけを記述できる。
🐶「責任を分けることで、どんなコードを書けばよいかが明確になる!」
2. LangGraphを用いたクイズ生成のフローについて
Readumのクイズ生成ロジックにはLangGraphを用いました。
また、さらにLangGraphの中でもlanggraph-supervisorを用いて実装を行いました。
langgraph-supervisorについてさらっと解説する
langgraph-supervisorは複数の専門家(Agent)を束ねる管理者(Supervisor)が存在する中央集権型のマルチエージェントシステムを構築します。
supervisorが複数の専門Agentを管理し、タスクの割り当てなどを行います。
簡単な例を解説します。
🐶「GitHubに詳しく載ってるよ」
数学を専門とするAgent(math_agent)と検索を専門とするAgent(research_agent)を統括するSupervisorを例にしましょう。
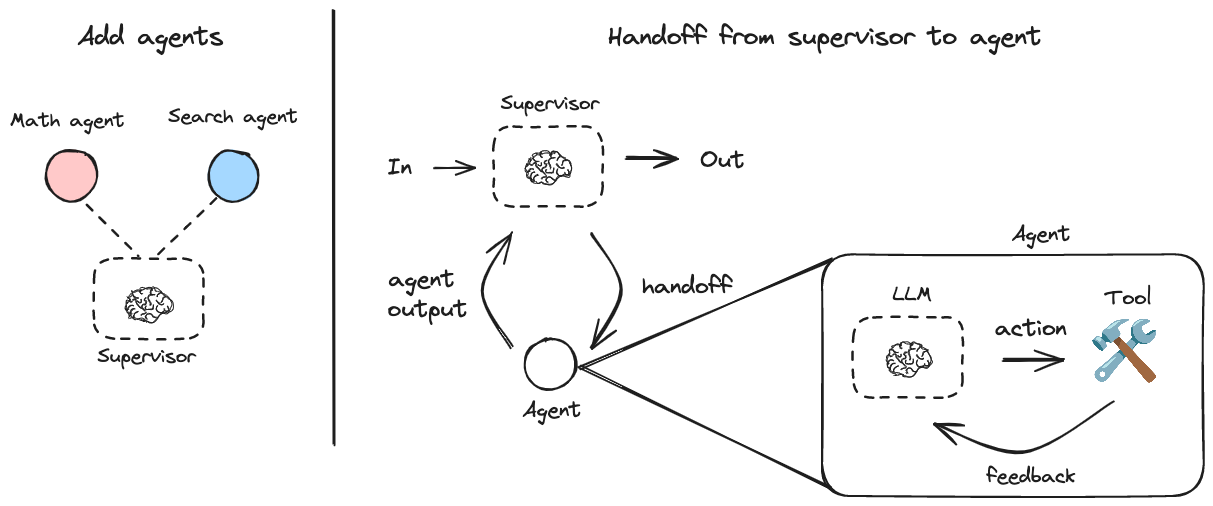
具体的なコードは以下のように書くことができます。
# 必要なライブラリをインポート
from langchain_openai import ChatOpenAI # OpenAIのチャットモデルを使うためのラッパー
from langgraph_supervisor import create_supervisor # 複数エージェントをまとめるスーパーバイザーを作成する関数
from langgraph.prebuilt import create_react_agent # “ReAct”スタイルのエージェントを簡単に作成する関数
# ChatOpenAIオブジェクトを生成(ここではGPT-4oを利用)
model = ChatOpenAI(model="gpt-4o")
# ─────────────────────────────────────────────────────
# ツール(関数)を定義:エージェントが利用できる機能
# ─────────────────────────────────────────────────────
def add(a: float, b: float) -> float:
"""2つの数を足し算する関数"""
return a + b
def multiply(a: float, b: float) -> float:
"""2つの数を掛け算する関数"""
return a * b
def web_search(query: str) -> str:
"""Web検索をエミュレートする関数(固定の回答を返す)"""
return (
"Here are the headcounts for each of the FAANG companies in 2024:\n"
"1. **Facebook (Meta)**: 67,317 employees.\n"
"2. **Apple**: 164,000 employees.\n"
"3. **Amazon**: 1,551,000 employees.\n"
"4. **Netflix**: 14,000 employees.\n"
"5. **Google (Alphabet)**: 181,269 employees."
)
# ─────────────────────────────────────────────────────
# エージェントの作成:React Agentを使って“ツールを適切に呼び出す賢いエージェント”を作る
# ─────────────────────────────────────────────────────
math_agent = create_react_agent(
model=model, # 先ほど作成したGPTモデルを渡す
tools=[add, multiply], # 足し算と掛け算のツールを渡す
name="math_expert", # エージェント名(ログ出力などで利用)
prompt="You are a math expert. Always use one tool at a time."
)
research_agent = create_react_agent(
model=model, # 同じGPTモデルを利用
tools=[web_search], # Web検索のツールを渡す
name="research_expert", # 別のエージェント名
prompt="You are a world class researcher with access to web search. Do not do any math."
)
# ─────────────────────────────────────────────────────
# スーパーバイザーの作成:2つのエージェントを役割分担して動かす
# ─────────────────────────────────────────────────────
workflow = create_supervisor(
[research_agent, math_agent], # 管理対象のエージェントリスト
model=model, # スーパーバイザー自体もモデルを使う
prompt=(
"You are a team supervisor managing a research expert and a math expert. "
"For current events, use research_agent. "
"For math problems, use math_agent."
)
)
# ─────────────────────────────────────────────────────
# 実行用のアプリケーションオブジェクトをコンパイルして呼び出し
# ─────────────────────────────────────────────────────
app = workflow.compile() # ワークフローを最終的に実行可能な形にコンパイル
result = app.invoke({
"messages": [
{
"role": "user",
"content": "what's the combined headcount of the FAANG companies in 2024?"
}
]
})
# 結果を表示
print(result)
このコードでは主に以下のことを行なっています。
- Agentが使うツールの定義
- 専門のAgentの定義(math_agent, research_agent)
- 専門Agentを統括するSupervisorの定義
- コンパイルおよび実行
これだけで中央集権型のマルチエージェントシステムの構築が可能になります。
後はプロンプトをSupervisorが理解し、それにあった適切なAgentを呼び出し処理を実行します。
例えばですが、「今日の天気について教えてください」というプロンプトがユーザーから投げられたら、Supervisorは以下のように解釈します。
🤖「おっ、ユーザーから『今日の東京の天気を教えて』って質問が来たな。math_agentは数学専門家だから、これはresearch_agentに任せよう。」
🧐 research_agent「了解です。web_search('東京 今日 天気') を実行します…」
🌐 web_search「東京都の今日の天気は晴れ、最高気温25℃、最低気温18℃です。」
🧐 research_agent「調べた結果をユーザーに返します:
『東京都の今日の天気は晴れです。最高気温は25℃、最低気温は18℃ですよ。』」
🤖「バッチリだ。これでユーザーに正しい情報を素早く返せたね!」
ってな感じです。すごいですね(小並感)
🐶「langgraph-supervisorを使うことでめちゃくちゃ簡単に中央集権マルチエージェントシステムを構築することができる!」
Readumではクイズ生成ロジックをどのように実装したか
では、Readumではこれをどのように実装したかを解説していきます。
大前提として、Readumでユーザーから入力を受け取ってからレスポンスするまで以下のような流れが存在します。
LangGraphを実行する前に、ユーザーが入力した読書メモはベクトルに変換され、FAISSインデックス(ベクトルDB)に埋め込みがされているのですが、説明が長くなるので今回は省略します。
🐶「とりあえずRAGを実行する上で、ベクトルDBに埋め込みをするという作業が必要ということだけ理解しておいてもらえるとOK」
それでは本題のLangGraphの実装をどうしたかについて説明していきます。
Readumのマルチエージェントシステムはグラフにすると以下のようになります。
各コンポーネントの役割
-
Supervisor(ワークフロー管理エンジン)
- クライアントからの「クイズ生成要求」を受け取り、
- RAG Quiz Agent に生成タスクを振り分け、結果を受け取り、
- Evaluation Agent に評価を依頼し、必要に応じて再生成を指示する
-
RAG Quiz Agent(クイズ生成エージェント)
-
generate_quiz_toolを呼び出して文脈を取得 - RAG チェーンを使い、指定の問題数・難易度でクイズを生成
- 生データとして JSON 形式のクイズを返却
-
-
Evaluation Agent(クイズ評価エージェント)
- 生成されたクイズをチェック
- 問題数、選択肢の正当性、解答と解説の整合性などを検証
- 問題があればフィードバックを提供し、なければ「問題なし」と判断する
このようになっています。
LangSmithにて、Agentの処理フローを確認してみましょう。
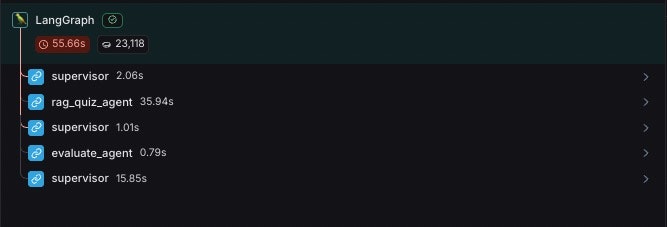
画像から、
supervisorrag_quiz_agentsupervisorevaluate_agentsupervisor
のようにステップが進んでいることがわかります。
ここでは、
- Supervisorがユーザーからのタスクを理解し、「RAG Quiz Agent」にクイズを作らせる必要があると理解、RAG Quiz Agentにタスクを割り振る
- RAG Quiz AgentがToolを使ってクイズを作成する
- RAG Quiz AgentからのアウトプットをSupervisorが解釈する。次にEvaluate Agentに評価してもらう必要を理解、タスクを割り振る
- Evaluate AgentはRAG Quiz Agentが生成したクイズが適切かを評価する
- Evaluate Agentから「OK」が来たのでSupervisorが最終的なアウトプットとしてクイズをレスポンスする
という流れでステップが進んでいます。
具体的なコードを見ていきましょう。
def _create_graph(self):
"""
LangGraph を使って AI エージェント群(RAGQuizAgent, EvaluateAgent, Supervisor)を構築する
"""
try:
# ログに開始を記録
logger.info("Creating LangGraph with Supervisor architecture")
# ──────────────────────────────────────────────────
# 1. ツール定義:generate_quiz_tool
# ──────────────────────────────────────────────────
@tool
def generate_quiz_tool(
question_count: int,
difficulty: str,
instruction: str | None = None,
) -> Quiz | None:
"""
・文脈を取得してクイズを生成する
・文脈が短すぎる場合は None を返す
・RAG Chain を呼び出して Quiz を作る
"""
# クイズ生成用のパラメータをまとめる
quiz_input = {
"input": instruction
or f"Generate {question_count} quiz questions of difficulty '{difficulty}'.",
"question_count": question_count,
"difficulty": difficulty,
}
logger.debug(f"Invoking chain with parameters: {quiz_input}")
try:
# RAG Chain にクイズ生成を依頼
result = self.rag_chain.invoke(quiz_input)
logger.debug(
f"Generated quiz with {len(result.questions)} questions"
)
return result # Quiz オブジェクトを返す
except Exception as e:
# 何らかのエラーが発生したらログを残し None を返す
logger.error(f"Error Generating quiz: {str(e)}")
return None
# ──────────────────────────────────────────────────
# 2. RAG Quiz Agent の定義
# ──────────────────────────────────────────────────
logger.info("Creating RAG quiz agent")
self.rag_agent = create_react_agent(
model=self.llm,
tools=[generate_quiz_tool],
name="rag_quiz_agent",
prompt=(
"You are RAGQuizAgent. "
"Generate a quiz based on the stored context using "
"generate_quiz_tool(question_count, difficulty, instruction). "
"Return None if context is insufficient. "
"Use output_schema() to ensure your result follows the required format. "
"YOUR FINAL OUTPUT MUST CONFORM TO THE SCHEMA PROVIDED BY OUTPUT_SCHEMA TOOL."
),
)
# ──────────────────────────────────────────────────
# 3. Evaluation Agent の定義
# ──────────────────────────────────────────────────
logger.info("Creating evaluation agent")
self.evaluate_agent = create_react_agent(
model=self.llm,
tools=[],
name="evaluate_agent",
prompt=(
"You are EvaluateAgent that reviews quizzes. Your task is to analyze a quiz and identify any issues.\n\n"
"Review Process:\n"
"1. Check if the quiz has EXACTLY the specified number of questions.\n"
"2. Verify each question has a valid answer (must be one of: A, B, C, or D).\n"
"3. Ensure the explanation for each question correctly matches the chosen answer.\n"
"4. Check for any inconsistencies or errors in the content.\n\n"
"If issues are found, explain them in detail. If no issues are found, simply state 'The quiz looks good.'\n"
"Your role is to provide feedback - you don't need to directly modify the quiz."
),
)
# ──────────────────────────────────────────────────
# 4. Supervisor Agent の定義
# ──────────────────────────────────────────────────
logger.info("Creating supervisor agent")
supervisor = create_supervisor(
agents=[self.rag_agent, self.evaluate_agent],
model=self.llm,
prompt=(
"You are RAGQuizAgent. Follow these steps STRICTLY IN THIS ORDER: "
"1. FIRST, generate a quiz based on the stored context using generate_quiz_tool(question_count, difficulty, instruction). "
"2. SECOND, you MUST evaluate the generated quiz using evaluate_agent to check if the questions are appropriate, accurate, and well-formed. "
"3. THIRD, if the evaluation suggests improvements OR if the number of questions does not match the requested amount, you MUST provide feedback to the rag_quiz_agent. "
"4. FOURTH, have the rag_quiz_agent generate a revised quiz with the feedback as instruction. "
"5. FIFTH, repeat steps 2-4 MAXIMUM 3 MORE TIMES (total of 4 quiz generation attempts). "
"6. FINALLY, after at most 4 attempts or when the quiz meets the requirements, return EXACTLY the output from the rag_quiz_agent WITHOUT ANY MODIFICATION. "
"IMPORTANT: DO NOT ATTEMPT MORE THAN 4 GENERATIONS TOTAL. After 4 attempts, return the best result available. "
"IF CONTEXT IS INSUFFICIENT OR GENERATE_QUIZ_TOOL RETURNS NONE, YOU MUST RETURN ONLY THE STRING 'None' WITHOUT ANY ADDITIONAL TEXT OR FORMATTING. "
"IMPORTANT: YOUR FINAL OUTPUT MUST BE EXACTLY THE SAME AS THE FINAL OUTPUT FROM THE RAG_QUIZ_AGENT. "
"DO NOT MODIFY, REFORMAT, OR ADD ANY TEXT TO THE RAG_QUIZ_AGENT'S OUTPUT. "
"DO NOT include any explanatory text, introductions, or descriptions before or after the JSON. "
"DO NOT use markdown code blocks or any other formatting. "
"RETURN EXACTLY THE RAW JSON FROM RAG_QUIZ_AGENT OR THE STRING 'None'. "
),
)
# グラフをコンパイルして返却
graph = supervisor.compile()
logger.info("LangGraph successfully created and compiled")
return graph
except Exception as e:
# 例外が起きた場合はログを残して独自例外へ変換
error_msg = f"Failed to create LangGraph: {str(e)}"
logger.error(error_msg, exc_info=True)
raise RAGChainSetupError(error_msg)
ステップバイステップで解説していきます。
1. Toolの定義
以下ではAgentが呼び出すToolの定義を行なっています。
# ──────────────────────────────────────────────────
# 1. ツール定義:generate_quiz_tool
# ──────────────────────────────────────────────────
@tool
def generate_quiz_tool(
question_count: int,
difficulty: str,
instruction: str | None = None,
) -> Quiz | None:
"""
・文脈を取得してクイズを生成する
・文脈が短すぎる場合は None を返す
・RAG Chain を呼び出して Quiz を作る
"""
# クイズ生成用のパラメータをまとめる
quiz_input = {
"input": instruction
or f"Generate {question_count} quiz questions of difficulty '{difficulty}'.",
"question_count": question_count,
"difficulty": difficulty,
}
logger.debug(f"Invoking chain with parameters: {quiz_input}")
try:
# RAG Chain にクイズ生成を依頼
result = self.rag_chain.invoke(quiz_input)
logger.debug(
f"Generated quiz with {len(result.questions)} questions"
)
return result # Quiz オブジェクトを返す
except Exception as e:
# 何らかのエラーが発生したらログを残し None を返す
logger.error(f"Error Generating quiz: {str(e)}")
return None
ここでは、クイズを生成するツールを呼び出しています。
クイズの生成ロジックはクラスメソッドであるself.rag_chain.invoke()を実行することで生成しています。
rag_chainは以下のようなChainを定義しています。
def _create_chain(self, retriever: VectorStoreRetriever) -> Runnable:
"""
RAG(Retrieval-Augmented Generation)を実行する Chain を組み立てて返す。
・retriever: ベクトル検索用のオブジェクト(VectorStoreRetrieiver)
・戻り値: 質問と文脈を組み合わせて LLM を呼び出す Runnable なパイプライン
"""
# 1. 入力マッピングの定義
# - ユーザーから受け取るパラメータをキーで取り出す関数(itemgetter)を設定
# - "context" には "input" をもとに retriever をチェーンした結果を入れる
rag_chain = (
{
# 問題数のパラメータを取得する
"question_count": itemgetter("question_count"),
# 難易度のパラメータを取得する
"difficulty": itemgetter("difficulty"),
# LLM へのメイン入力文を取得する
"input": itemgetter("input"),
# 検索文脈を作るため、"input" を渡して retriever でドキュメントを検索
"context": itemgetter("input") | retriever,
}
# 2. 自作のプロンプト(self.prompt)を挿入
| self.prompt
# 3. LLM を呼び出し、返ってきた JSON を Quiz 型にパースする設定
| self.llm.with_structured_output(Quiz)
)
# 完成した Chain を返して、後続の呼び出しで .invoke() などが可能になる
return rag_chain
この部分の処理を会話形式でまとめました。
🐶「このコードでやっていることってなに?」
🐶「おぢ、この _create_chain って関数、なにをやっているの?」
👴『これは RAG(Retrieval-Augmented Generation)用の「チェーン」を作って返すんじゃよ。』
🐶「チェーンって何?パイプみたいなもの?」
👴『そうじゃ。ここでは「複数の処理をパイプでつないだパイプライン」を指すんじゃ。ユーザーから渡されたパラメータを受け取り、文脈検索して、プロンプトを組み立てて、最後に LLM を呼び出す一連の流れをまとめているんじゃよ。』
🐶「最初の { "question_count": itemgetter("question_count"), ... } の部分は?」
👴『これは「入力マッピング」の定義じゃ。
-
"question_count"キーにはitemgetter("question_count")を使って、呼び出し時の辞書からquestion_countを取り出す関数を登録している。 - 同様に
"difficulty"や"input"も取り出す関数を設定しておる。』
🐶「"context": itemgetter("input") | retriever はどういう意味なの?」
👴『ここがポイントじゃ。
-
itemgetter("input")でユーザー入力(例:「何問生成?」の文字列)を取得し、 -
| retrieverでその入力を使ってベクトル検索(retriever)を実行する、
という2段階処理をパイプでつないで「context」として登録しているんじゃ。』
🐶「そのあとに | self.prompt が来てるね!これはなに?」
👴『うむ。self.prompt は「どういう形式で LLM に質問を投げるか」を定義したテンプレートじゃ。先ほどのパラメータや検索結果をこのプロンプトに流し込んで、実際の LLM 呼び出し用のメッセージを作るんじゃよ。』
🐶「最後の | self.llm.with_structured_output(Quiz) って?」
👴『そこが「LLM 呼び出し」部分じゃ。
-
self.llmで LLM を呼び出し、 -
with_structured_output(Quiz)を使うことで、返ってきた JSON をQuiz型にパースしてくれる機能を追加しているんじゃ。』
🐶「なるほど!じゃあまとめると…?」
👴『まとめるとじゃな
- ユーザー入力から
question_countやdifficulty、inputを取り出し、 -
inputを retriever で文脈検索してcontextを用意、 -
self.promptで質問フォーマットを組み立て、 - LLM を呼び出して
Quizオブジェクトに整形、
という一連の流れをパイプライン(チェーン)にまとめているんじゃ。そして、このチェーンを返すことで、.invoke()などで実行できるようになるわけじゃ。』
🐶「すっごくわかりやすい!ありがとうおぢ!」
このように、generate_quiz_toolの中でRAGを実行する関数を呼び出すことで、Toolが呼び出されるとクイズが生成されるようになります。
2. RAG Quiz Agentの定義
続いてRAG Quiz Agentの定義です。
# ──────────────────────────────────────────────────
# 2. RAG Quiz Agent の定義
# ──────────────────────────────────────────────────
# ログ出力:RAG Quiz Agent の生成開始を記録
logger.info("Creating RAG quiz agent")
# create_react_agent() を使って、ツール呼び出し機能をもつエージェントを作成
self.rag_agent = create_react_agent(
model=self.llm, # このエージェントが使う LLM モデル
tools=[generate_quiz_tool], # 利用可能なツール(関数)のリスト
name="rag_quiz_agent", # エージェントの識別名(ログやデバッグで使われる)
prompt=( # 初期プロンプト:エージェントへの指示文
"You are RAGQuizAgent. " # 自分は「RAGQuizAgent」であると自己紹介
"Generate a quiz based on the stored context using " # 何をするか指示
"generate_quiz_tool(question_count, difficulty, instruction). "
"Return None if context is insufficient. " # 文脈不足時は None を返す
"YOUR FINAL OUTPUT MUST CONFORM TO THE SCHEMA PROVIDED BY OUTPUT_SCHEMA TOOL."
),
)
先ほど、さらっとRAG Quiz Agentの役割は以下のように説明しました。
-
RAG Quiz Agent(クイズ生成エージェント)
-
generate_quiz_toolを呼び出して文脈を取得 - RAG チェーンを使い、指定の問題数・難易度でクイズを生成
- 生データとして JSON 形式のクイズを返却
-
このAgentの役割は先ほど説明したgenerate_quiz_toolを呼び出してクイズを生成することです。
さらに詳しい解説は以下に載せています。
🐶「RAG Quiz Agentってなにをやっているの?」
🐶「おぢ、この『RAG Quiz Agent』ってなにものなの?」
👴『これはな、LLM(大規模言語モデル)と「ツール呼び出し」を組み合わせた“知的エージェント”なんじゃよ。』
🐶「ツール呼び出しってどういうこと?」
👴『エージェントには generate_quiz_tool という関数をツールとして渡しておる。
問題を生成するためのロジックを、そのツールが担っておるんじゃ。』
🐶「じゃあ、エージェントがやることは何?」
👴『大まかに3ステップじゃ。
- 自分に渡された「プロンプト」を読んで役割を理解し、
- 必要に応じて
generate_quiz_toolを呼び出してクイズを作り、 - 最終的にその結果をユーザー向けに返す、という流れじゃ。』
🐶「プロンプトって?」
👴『create_react_agent の prompt 引数で渡してある、エージェントへの命令文じゃ。
「文脈を使ってクイズを作れ」「文脈不足なら None を返せ」「出力はスキーマに沿え」といったルールをここに書いておる。』
🐶「ほうほう。ちなみに、どうやってツールを呼ぶの?」
👴『エージェントが自分で考えて「ここはツールを使おう!」と判断すると、
内部で generate_quiz_tool(question_count, difficulty, instruction) を実行する仕組みなんじゃ。』
🐶「エージェント自身はどう動くのかイメージある?」
👴『まずプロンプトをもとに「クイズを作るべきだな」と判断し、
次にツールを呼び出してRAGチェーンを動かす。
最後に返ってきた Quiz オブジェクトをフォーマットしてユーザーに返すんじゃ。』
🐶「なるほどー。じゃあRAG Quiz Agentは“クイズ専門家”みたいなものなんだね?」
👴『その通り。文脈取得→生成→整形までを一気に担う、クイズ生成のエキスパートじゃよ。』
3. Evaluation Agentの定義
続いてEvaluation Agentについてです。
# ──────────────────────────────────────────────────
# 3. Evaluation Agent の定義
# ──────────────────────────────────────────────────
# ログ出力:Evaluation Agent(クイズ評価エージェント)の生成開始を記録
logger.info("Creating evaluation agent")
# create_react_agent() で「クイズをチェックする専門家エージェント」を作成
self.evaluate_agent = create_react_agent(
model=self.llm, # このエージェントが利用する LLM(大規模言語モデル)
tools=[], # 外部ツールは使わない(LLM単体で評価ロジックを実行)
name="evaluate_agent", # エージェントの識別名(ログやデバッグ用)
prompt=( # 初期プロンプト:このエージェントへの命令文
"You are EvaluateAgent that reviews quizzes. Your task is to analyze a quiz and identify any issues.\n\n"
"Review Process:\n"
"1. Check if the quiz has EXACTLY the specified number of questions.\n"
"2. Verify each question has a valid answer (must be one of: A, B, C, or D).\n"
"3. Ensure the explanation for each question correctly matches the chosen answer.\n"
"4. Check for any inconsistencies or errors in the content.\n\n"
"If issues are found, explain them in detail. If no issues are found, simply state 'The quiz looks good.'\n"
"Your role is to provide feedback - you don't need to directly modify the quiz."
),
)
このAgentの役割は以下の通りです。
-
Evaluation Agent(クイズ評価エージェント)
- 生成されたクイズをチェック
- 問題数、選択肢の正当性、解答と解説の整合性などを検証
- 問題があればフィードバックを提供し、なければ「問題なし」と判断する
ご覧の通り、RAG Quiz Agentが生成したクイズの内容を評価するAgentとなっています。
RAG Quiz Agentはたまに以下のような生成ミスを犯すことがあります。
- 10問生成してほしいのに、9問しか生成してくれない
- 答えはAとなっているのに、解説ではBが正解となっている
みたいなことです。
このようなクイズをユーザーに返すのは専門家としてはあってはならないことです。
そこで、このEvaluation Agentを生成フローに追加することで、「不適切なクイズは不適切だと評価し、再生成されるようにする」ことが可能になるのです。
🐶「クイズの質を担保する重要な専門AgentがEvaluation Agentってことだね!」
4. 全てを管理するSupervisorの定義
最後はReadumのクイズ生成ロジックの管理者である、Supervisorの定義に関してです!
具体的なコードは以下のようになっています。
# ──────────────────────────────────────────────────
# 4. Supervisor Agent の定義
# ──────────────────────────────────────────────────
# ログ出力:Supervisor(ワークフロー管理者)の生成開始を記録
logger.info("Creating supervisor agent")
# create_supervisor() で「複数エージェントを統括するSupervisor」を作成
supervisor = create_supervisor(
# 管理対象のエージェントリスト。
# ここでは、クイズ生成を担うrag_agent と評価を担うevaluate_agent を渡す。
agents=[self.rag_agent, self.evaluate_agent],
# Supervisor 自身が使う LLM モデル。
# このモデルが「誰に何を指示するか」を考えたり、
# 各エージェントへの命令を生成したりするのに使われる。
model=self.llm,
# Supervisor の振る舞いを細かく指定するプロンプト(初期命令文)。
# 以下のような手順を厳密に守るよう指示している:
# 1. generate_quiz_tool を呼び出してクイズを生成
# 2. evaluate_agent で生成クイズをチェック
# 3. 問題があれば rag_agent へフィードバックを返す
# 4. フィードバックを元に再生成(最大4回)
# 5. 最終的に rag_agent の「生の JSON 出力」または "None" だけを返す
# 6. それ以外のテキストやフォーマットは一切含めない
prompt=(
"You are Supervisor for quiz generation. Follow these steps STRICTLY IN THIS ORDER: "
"1. FIRST, generate a quiz based on the stored context using generate_quiz_tool(question_count, difficulty, instruction). "
"2. SECOND, you MUST evaluate the generated quiz using evaluate_agent to check if the questions are appropriate, accurate, and well-formed. "
"3. THIRD, if the evaluation suggests improvements OR if the number of questions does not match the requested amount, you MUST provide feedback to the rag_quiz_agent. "
"4. FOURTH, have the rag_quiz_agent generate a revised quiz with the feedback as instruction. "
"5. FIFTH, repeat steps 2-4 MAXIMUM 3 MORE TIMES (total of 4 quiz generation attempts). "
"6. FINALLY, after at most 4 attempts or when the quiz meets the requirements, return EXACTLY the output from the rag_quiz_agent WITHOUT ANY MODIFICATION. "
"IMPORTANT: DO NOT ATTEMPT MORE THAN 4 GENERATIONS TOTAL. After 4 attempts, return the best result available. "
"IF CONTEXT IS INSUFFICIENT OR GENERATE_QUIZ_TOOL RETURNS NONE, YOU MUST RETURN ONLY THE STRING 'None' WITHOUT ANY ADDITIONAL TEXT OR FORMATTING. "
"IMPORTANT: YOUR FINAL OUTPUT MUST BE EXACTLY THE SAME AS THE FINAL OUTPUT FROM THE RAG_QUIZ_AGENT. "
"DO NOT MODIFY, REFORMAT, OR ADD ANY TEXT TO THE RAG_QUIZ_AGENT'S OUTPUT. "
"DO NOT include any explanatory text, introductions, or descriptions before or after the JSON. "
"DO NOT use markdown code blocks or any other formatting. "
"RETURN EXACTLY THE RAW JSON FROM RAG_QUIZ_AGENT OR THE STRING 'None'. "
),
)
# Supervisor を compile() すると、内部で定義したルールに沿って
# rag_agent と evaluate_agent を順番に呼び出す「実行可能なワークフロー」が返ってくる。
graph = supervisor.compile()
supervisorはcreate_supervisor()を使って定義することができます。
また、agents引数にはこれまで定義したrag_quiz_agentやevaluation_agentを渡しています。
こうすることで、Supervisorの管理下に「RAG Quiz Agent」と「Evaluation Agent」がいるよ〜ってことを伝えることができるのです。
この定義があるから、Supervisorはタスクを割り振ることができるようになります。
🐶「supervisorの定義では何をやっているの?教えておぢ!」
🐶「おぢ、この create_supervisor の部分をもっと教えてほしい」
👴『よし、まずは引数から見てみよう。
agents=[self.rag_agent, self.evaluate_agent]
これは「Supervisor が管理する2つのエージェント」を渡しているんだ。ひとつはクイズ生成、もうひとつはクイズ評価を担当している。』
🐶「なるほど。それからどう動かすかは?」
👴『次に
model=self.llm
で「どの AI モデルを使うか」を指定する。Supervisor 自身もこのモデルを使って、誰に何を指示するかを考えるんだよ。』
🐶「そして prompt の中身が長いけれど、これは?」
👴『prompt は「黒板に書く指示書」のようなものだ。例えば:
1. generate_quiz_tool を呼んでクイズを生成
2. evaluate_agent で生成クイズをチェック
3. フィードバックを rag_quiz_agent に返す
4. 最大 4 回まで繰り返す
5. 最終的に生の JSON か 'None' を返す
これをすべて順番どおりに実行しなさい、と細かく書いているんだ。』
🐶「ふむふむ。それを compile() するとどうなるの?」
👴『graph = supervisor.compile() で「この指示書どおりに動くワークフロー」が組みあがる。あとは
result = graph.invoke({"messages": [...]})
を呼ぶだけで、生成 → 評価 → 必要あれば再生成… の流れを自動でやってくれる仕組みさ。』
🐶「Supervisor がいれば、プログラムの流れを全部まとめて見られるんだね。ありがとうおぢ!」
長くなりましたが、以上のステップを経てReadumではクイズを生成することができるようになっています。
🐶「Readumのクイズ生成ロジックはまとめると…」
🐶「おぢ、Readumのクイズ生成って、最初から最後までどんな流れで動くのか教えてほしいな!」
👴『いいぞ、イッヌ。順番に追っていこう。』
🐶「まずユーザーからの入力だよね?何を受け取るの?」
👴『ユーザーが「こんな内容から何問クイズを作ってほしい」というテキストと、問題数や難易度の指定を送ってくるんじゃ。これを最初の input として受け取るわけじゃ。』
🐶「ほうほう!そのあと何をするの?」
👴『次にその input をベクトルに変換するんじゃ。Readumでは、文章を数値ベクトルに変えることで、FAISSという高速ベクトル検索エンジンに入れられるようにしておる。』
🐶「ベクトルってどうして必要なの?」
👴『ベクトル化すると、入力テキストに似た内容を大量のドキュメントから素早く検索できるようになるんじゃ。これがRAG(Retrieval-Augmented Generation)の肝で、文脈となる情報をLLMに渡せるようになるんじゃよ。』
🐶「なるほど!ベクトル化したら何をするんだっけ?」
👴『FAISSインデックスに埋め込んでおくんじゃ。こうすると、たとえば「input」の一部が「脳科学」なら、その分野のドキュメントをすぐに引っ張ってこれるわけじゃ。』
🐶「そのあとにLangGraphを使うんだよね?」
👴『そうじゃ。_create_chain で作ったRAGチェーンを、generate_quiz_tool の中で呼び出すんじゃ。内部では先ほど埋め込んだFAISSから文脈を取り出し、テンプレートプロンプト(self.prompt)を埋め込んでLLMに投げる。』
🐶「それがクイズ生成の最初のステップなんだよね?」
👴『その通り。create_react_agent で作ったrag_quiz_agentが、このツールを使って実際にクイズを組み立てるんじゃよ。』
🐶「でもSupervisorがいるんだよね?どう関わるの?」
👴『Supervisorは「rag_quiz_agent」が作ったクイズを評価させるんじゃ。
- まず
generate_quiz_toolでクイズを生成 - 次に
evaluate_agentで問題数や選択肢、解答解説の整合性をチェック - もし修正が必要なら、
rag_quiz_agentにフィードバックを返して再生成 - 最大4回まで繰り返して、一番良い結果をそのまま返す』
🐶「評価はどうやってやるんだったっけ?」
👴『create_react_agent で作ったevaluate_agentが担うんじゃ。
- 問題数が指定どおりか
- 選択肢が A~D の中に収まっているか
- 解説が正しいか
- 文法や内容の不整合はないか
…などをLLMに判断させ、問題があればフィードバックを生成するんじゃよ。』
🐶「Supervisorはその全体を統括してるんだね!」
👴『まさに。create_supervisor に rag_quiz_agent と evaluate_agent を渡し、詳しいプロンプトで手順を指示しておく。
supervisor = create_supervisor(
agents=[self.rag_agent, self.evaluate_agent],
model=self.llm,
prompt=(
"1. generate_quiz_tool でクイズ生成\n"
"2. evaluate_agent で評価\n"
"3. 修正フィードバックを rag_quiz_agent に返却\n"
"4. 最大4回繰り返し\n"
"5. 最後に生の JSON か 'None' を返す"
)
)
graph = supervisor.compile()
これで graph.invoke(...) を呼ぶだけで、一連の流れが自動で実行されるわけじゃよ。』
🐶「じゃあ最後はどうなるの?」
👴『invoke() の返り値にある messages の中から、Supervisorがまとめた最終結果である生のJSON(または "None")を取り出して、アプリ側で Quiz オブジェクトに変換する。そこからユーザーに返却するんじゃ。』
🐶「まとめると…
- ユーザー入力を受け取る
- テキストをベクトル化→FAISSインデックスに埋め込む(RAGの準備)
- LangGraph のSupervisorを使い、rag_quiz_agent と evaluate_agent を orchestrate
- 最終的なJSONを
Quizにパースしてユーザーに返す
ってことかな!」
👴『それがReadumのクイズ生成の全体フローじゃ。どうじゃ、イッヌ?』
🐶「ばっちりわかったよ!ありがとうおぢ!」
3. バックエンドの実装で詰まったポイント
Readumのバックエンドのディレクトリ構成、LangGraphを用いたReadumのコア部分の実装についてお話ししました。
ここからはバックエンドの実装で詰まったポイントについて解説していこうかと思います。
最近はAIの進化が素晴らしく、AIに聞けば大体なんとかなることが多いのですが、今回はAIに聞いてもなかなか解決しなかった問題を解説しようかと思います。
RAGを実装するのが難しかった…!!
Readumではユーザーの読書メモをベクトル化し、FAISSインデックスに埋め込み、RAG(Retrieval-Augmented Generation)チェーンを実行することでクイズ生成を行っています。その全体像は次の通りです。
retriever:FAISSインデックスから関連ドキュメント(ベクトル検索結果)を取得するオブジェクト。
ReadumのRAG Chainは以下のように実装しています。
def _create_chain(self, retriever: VectorStoreRetriever) -> Runnable:
"""
RAG用の Chain を組み立てる。
・itemgetter で引数を抜き出し
・パイプで retriever → prompt → LLM とつなぐ
"""
rag_chain = (
{
"question_count": itemgetter("question_count"),
"difficulty" : itemgetter("difficulty"),
"input" : itemgetter("input"),
"context" : itemgetter("input") | retriever, # ← ここがミソ:input を取り出してから retriever に渡す
}
| self.prompt
| self.llm.with_structured_output(Quiz) # with_structured_output(ClassName)とすることで、ClassNameの型でアウトプットを生成してくれるようになる
)
return rag_chain
itemgetter()となっているのは、このChainを実行する際に以下のようにオブジェクトを渡して実装するからです。
response = self.rag_chain.invoke(
{
"input": f"Generate {question_count} quiz questions of difficulty '{difficulty}'.",
"question_count": question_count,
"difficulty": difficulty,
}
)
このオブジェクトで渡ってくる値から、特定のフィールドの値だけ取得するためにitemgetter()を使っています。
そして、この実装で特に難しかったのは、retriever(FAISSインデックス)をどのようにChainに渡すかです。
Chainを生成する際は、以下のように直接retrieverを渡すことはできません。これではエラーになってしまいます。
{
"question_count": itemgetter("question_count"),
"difficulty": itemgetter("difficulty"),
"input": itemgetter("input"),
"context": retriever, # これでは動かない
}
そうではなく、このようにitemgetter("input")のようにretrieverに関連ドキュメントを検索するための入力を取り出す必要があります。
{
"question_count": itemgetter("question_count"),
"difficulty": itemgetter("difficulty"),
"input": itemgetter("input"),
"context": itemgetter("input") | retriever, # ←こんな感じでretrieverを直接渡すのではなく、inputだけ抽出してから渡す必要がある
}
個人的にはこんな感じでちょい複雑なRAG Chainを実装する方法は調べてもなかなか出てこなかった印象があります。
冒頭の方で紹介したUdemyの講座にもこの方法は書かれていなかったです。
🐶「RAG Chain実装時、直接retrieverを渡すのはNG!どの文字列で検索するかを先に指定し、itemgetter("input") | retrieverの形式で渡すようにしよう!」
「ちょっとよくわからない…」って方は以下の解説をご覧ください。多分ちょい理解できるかと。
🐶「何言ってるかわからんから解説じゃ!」
🐶「おぢ、この _create_chain の中の "context": itemgetter("input") | retriever ってところがよくわからないかなあ?どうやって FAISS のリトリーバーを渡してるの?」
👴『よし、イッヌ。順を追って説明しようかの。まず、この関数は「RAG チェーン」を組み立てる役目を担っておる。RAG とは “Retrieval-Augmented Generation” の略で、ユーザーの入力(質問や命令)に対して、外部の知識ベースから “文脈” を引いてきて、それを使って LLM に応答を生成させる仕組みなんじゃよ。』
🐶「チェーンってパイプみたいなものだったよね?どうやってつないでるのか教えてほしい!!」
👴『そうじゃな。この実装では、まず最初に入力マッピングを用意する部分があるじゃろ。
{
"question_count": itemgetter("question_count"),
"difficulty" : itemgetter("difficulty"),
"input" : itemgetter("input"),
"context" : itemgetter("input") | retriever,
}
この辞書は、「関数のパラメータ名」と「それを計算する関数」をペアにしているんじゃ。』
🐶「itemgetter("input") は何をしてくれているの?」
👴『itemgetter("input") は、Python の標準ライブラリ operator から来ておって、
value = args["input"]
みたいに、呼び出し時の辞書(args)から "input" キーの値を取り出す関数を返してくれるんじゃよ。』
🐶「じゃあ itemgetter("input") | retriever はどう動くの?」
👴『ここが肝心じゃ。LangGraph のチェーンでは、パイプ演算子 | を使って、ある関数の出力を次の「Processor(処理単位)」に渡せるようになっておる。
-
itemgetter("input")が呼び出し時のargsからテキストを取り出す - そのテキストを
retrieverに渡して、FAISS インデックスから関連ドキュメントを検索(=ベクトル検索) -
retrieverの返り値が「context」として登録される
という一連の流れを一行で書けるわけじゃ。』
🐶「ああ、だから itemgetter("input") | retriever で『まず入力を取り出して、それを retriever に食わせる』って動きになるんだね!」
👴『そのとおり。そして続けて、
| self.prompt
| self.llm.with_structured_output(Quiz)
とあるけれど、これも同じパイプ処理じゃ。
-
self.promptは「どんな文章フォーマットで LLM に投げるか」のテンプレート(プロンプト)を表す処理 - その出力を
self.llm.with_structured_output(Quiz)が受け取り、実際に LLM を呼び出して、戻ってきた JSON をQuiz型にパースする
というステップがつながっておるんじゃ。』
🐶「なるほど!つまり…」
-
ユーザーの
question_countやdifficulty、inputはitemgetterで取り出す -
contextはinput→ retriever → FAISS 検索結果 -
self.promptで「文脈+パラメータ」をプロンプトフォーマットに流し込む -
self.llm.with_structured_output(Quiz)で LLM に投げて、Quizオブジェクトに変換
👴『その通りじゃ。こうして完成した rag_chain は、呼び出し側で
result = rag_chain.invoke({
"question_count": 5,
"difficulty": "easy",
"input": "〜読書メモのテキスト〜"
})
のように引数を渡すだけで、FAISS から文脈を取ってきて、LLM にプロンプトを投げてクイズを返してくれるんじゃよ。』
🐶「すっごくわかりやすいよ!FAISS の retriever を渡すって、こういうパイプでつなぐんだね!ありがとうおぢ!」
このプロジェクトで学んだことをまとめる
最後に、このReadumプロジェクトを通して学んだことをまとめていこうかと思います。
まずこのプロジェクトの目的は「生成AIアプリケーションを開発するだけの最低限の知識を身につけること」でした。
実際、Readumの開発やUdemyでの学習を通して以下のことを学べました。
LangChainの基礎-
RAGの実装方法- 読書メモをベクトル化し、FIASSインデックスに埋め込むロジックの実装方法を理解した
- FAISSインデックスの実装を通して、ベクトルDBについて理解できた
LangGraphの基礎-
langgraph-supervisorをどうやって実装するか- 専門Agentを駆使して、クオリティの高いクイズを生成するロジックを実装できた
-
クリンアーキテクチャを用いたデザインパターンについて- DDD的思想をどのようにデザインパターンに落とし込むか、そしてそれをどうやって実装すれば良いかを理解できた
-
テストコードの実装を通して、pytestについて深く理解した- Readumのテストコード実装を通してpytestのmockerやfixtureなどについて理解することができた
-
Terraformを用いたインフラ管理について- コストを抑えてデプロイするにはどうすればよいか(結果としては毎月100円程度までおさせることに成功)
- VPCアクセスコネクタをTerraformから実装する方法および、なぜアクセスコネクタを実装すると費用が高くなるかを理解した
- アクセスコネクタはCompute Engineを裏で動かしているので、コストが高くなることを学んだ
とざっとこれらの内容を学ぶことができました。
Readumのクイズ生成ロジックをRAGやLangGraphなどを用いて実装できていることからも、生成AIアプリケーションを実装する上で必要な知識は理解することができました!!
こちらのプロジェクトの目的であった、「生成AIアプリケーション開発スキルを身につける」は達成できたのかなと思います。
🐶「おめでとう!おれ!」
まとめ
最後までこんなクソ長い記事を読んでいただき本当にありがとうございました!
この「生成AIアプリケーションを実装するスキルを身につけるプロジェクト」は2月くらいから開始して、5月頭には終わったので、だいたい3ヶ月もあれば「生成AIアプリケーションを開発するスキル」は身につけるという証明にもなっているのかなと思います。
だいたい3ヶ月程度がんばれば『LangChainをゼロから理解するところ』から、『LangGraphを用いてマルチエージェントの実装をアプリケーションにまで落とし込むところ』まで学べるということです!!
この記事が誰かの生成AIアプリケーション開発欲に火をつけることに役立てばいいなと思います。
🐶「生成AIアプリ開発スキルは3ヶ月頑張れば基礎的なところは身につく!」
改めてですが、こんなクソ長い記事を最後までお読みいただきありがとうございました!
みなさまぜひ生成AI開発ライフをお楽しみくださいませ〜、それではまた。
🐶「ありがとうございました〜」