5-2 1次ノード[モデル作成タブ]
1.ノードの目的
連続(スケール)型データを予測する線形回帰モデルを作成します。
2.解説動画(60秒)
3.クイックスタート
製品に同梱されているサンプルストリームのgoodslearn.strを開きます。
このストリームのシナリオは、収益増加率を商品の種別、価格、販促、販促前の収益から影響力のある要因を使って予測することです。なお、商品の種類は名義型の文字列で、それ以外はすべて連続型の数値データです。
データ型ノードに、[モデル作成]パレットの1次ノードを接続します。
1次ノードは、予測フィールドが文字列のデータもダミーコード(ワンホットベクトル)化などの前処理なしでそのままモデル作成に使うことができます。
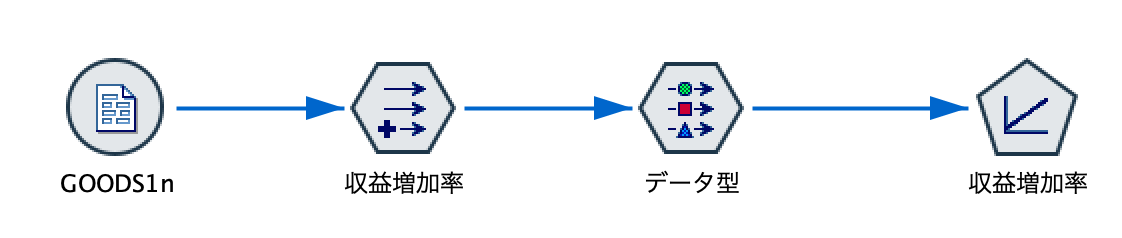
デフォルト設定のまま、ストリームを実行します。
生成されたモデルナゲットを参照します。
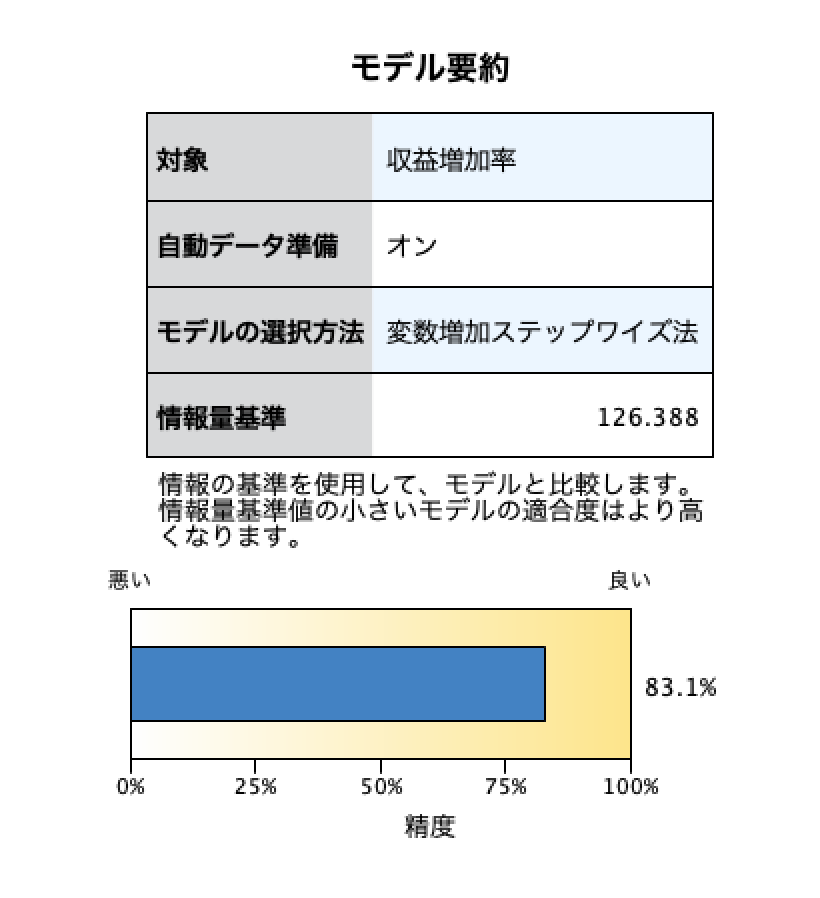
モデルの要約では、予測の対象フィールド、自動データ準備の実行の有無、モデル(予測フィールド)の選択方法、情報量基準、そして精度としてR2乗(決定係数)値が示されます。
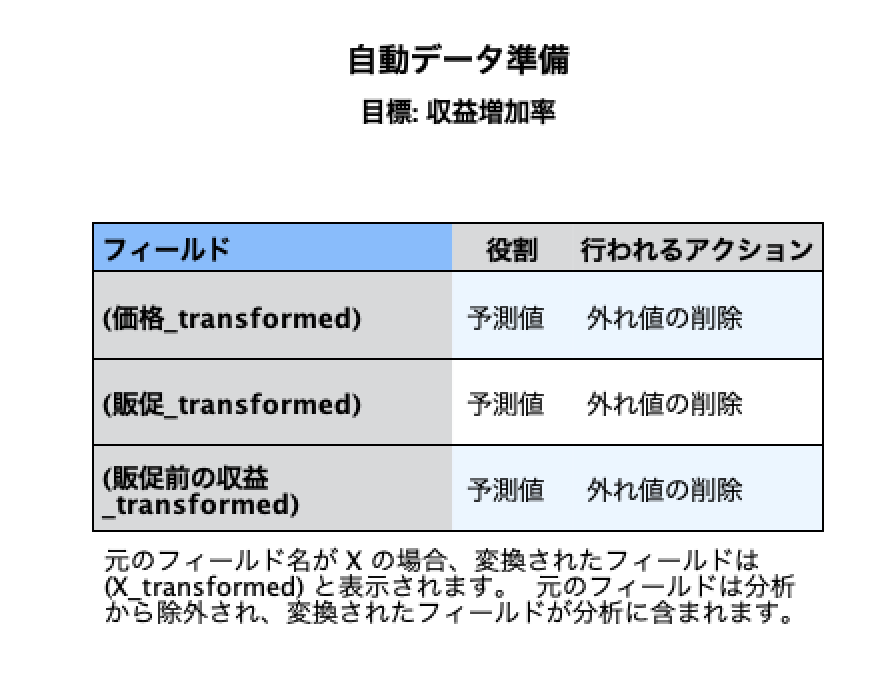
自動データ準備がオンの場合、どのフィールドにどのように対処したかを確認できます。
このモデルナゲットをデータ型ノードに接続します。さらに[出力]パレットのテーブルノードを接続します。
テーブルノードを実行して、予測値を算出(スコアリング)をします。
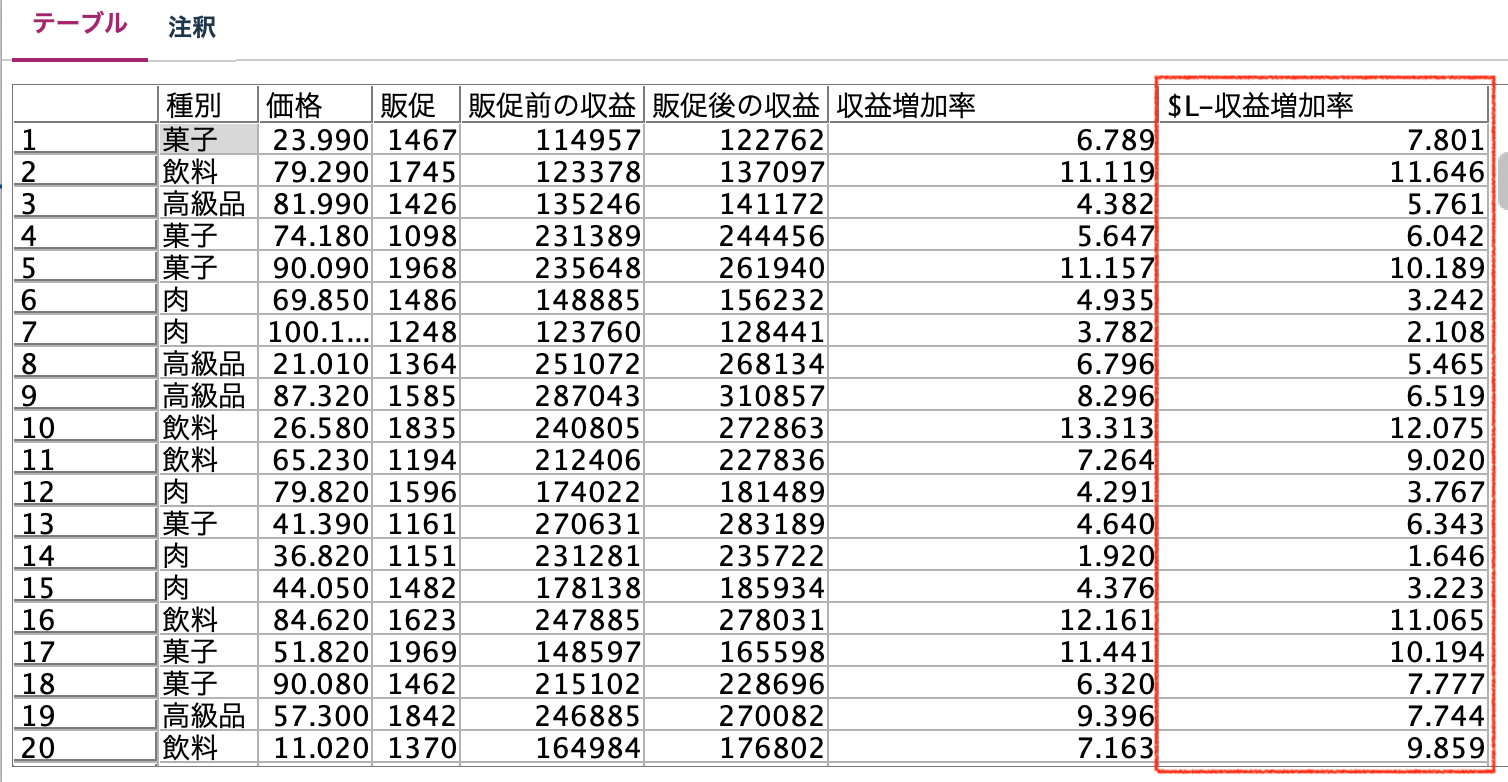
$L-収益増加率のフィールドに予測した結果が出力されます。
4.Tips
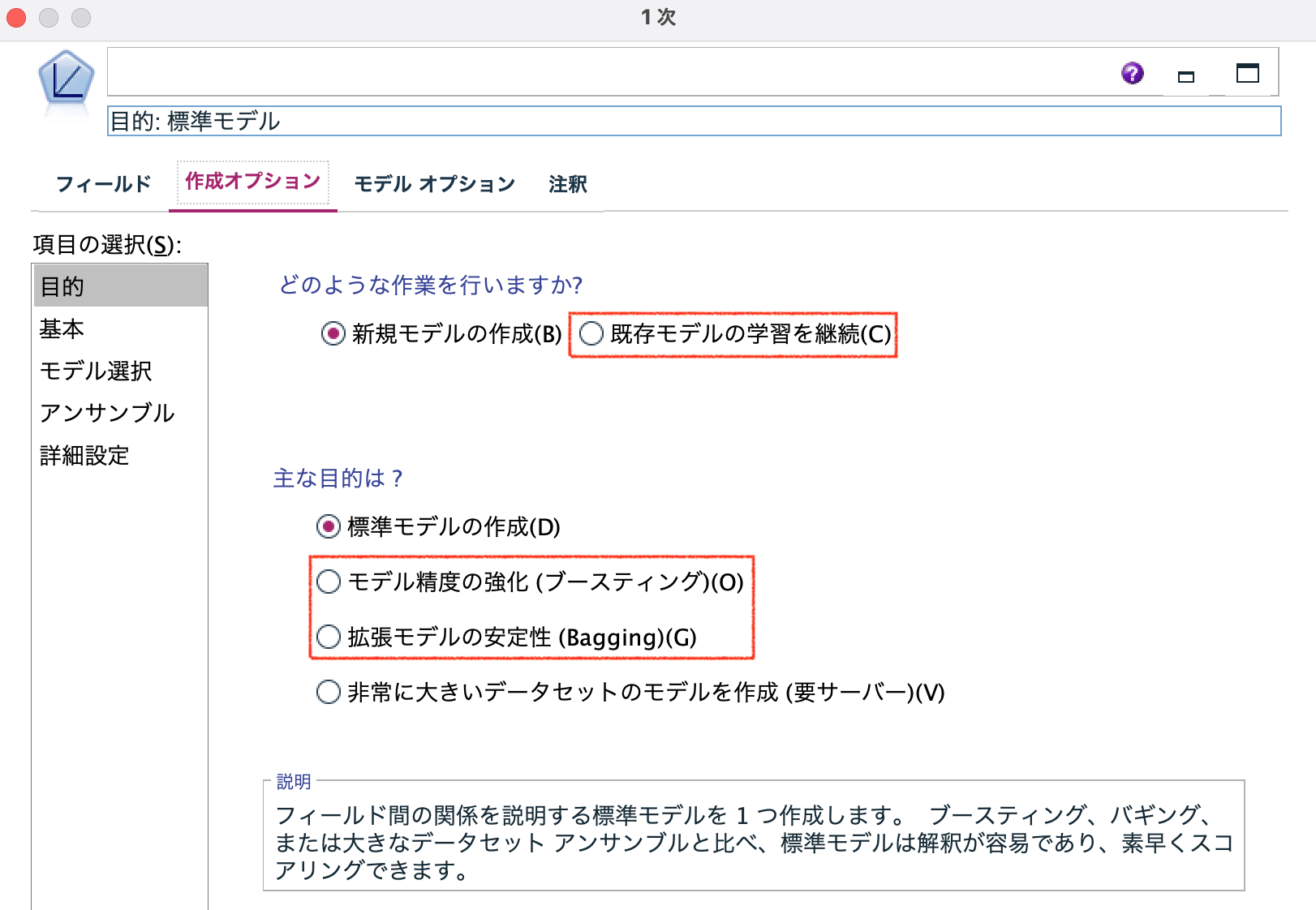
1次ノード編集ダイアログの[作成オプション]タブにある項目の選択:[目的]では、新規モデルの作成を行うか、既存のモデルの学習を継続するかの作業を選択できます。
既存のモデルの学習を継続では、新規に追加されたレコードや更新されたレコードのみを適用してモデルの更新を行うことができるので、継続的なモデル作成の際にパフォーマンス向上に役立ちます。
また、モデルの精度を強化するためのブースティング、モデルの安定性を図るためのバギングなどアンサンブルモデルの作成の選択も可能です。
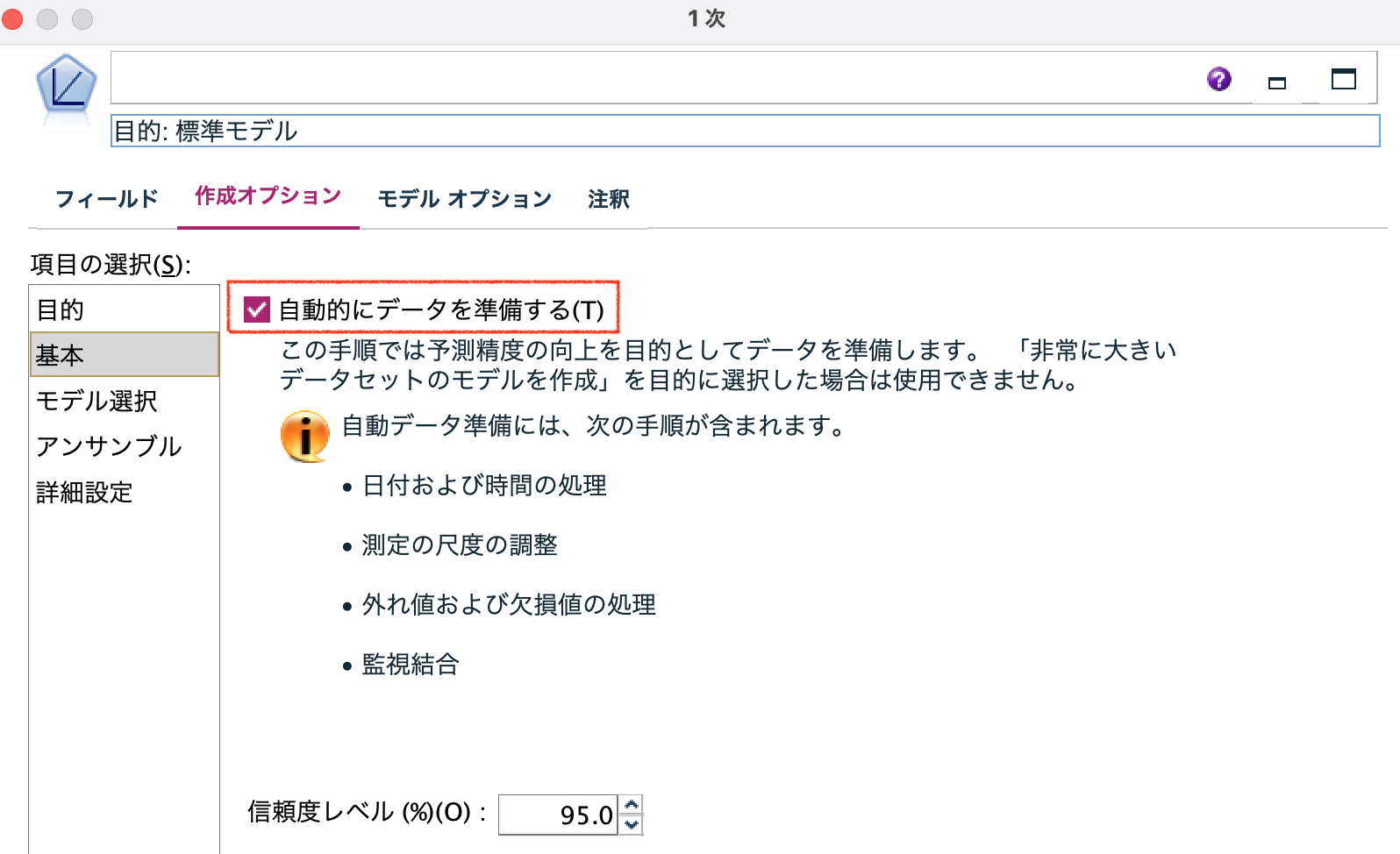
項目の選択:[基本]では、モデルの予測精度の向上を目的としたデータ加工を自動で行うことができます。たとえば、連続型データの平均値±3標準偏差の外側のレコードは外れ値として除外したり、欠損値は名義型データでは最頻値に、順序型データでは中央値に、連続型データでは平均値への置き換えをモデル作成時に行います。
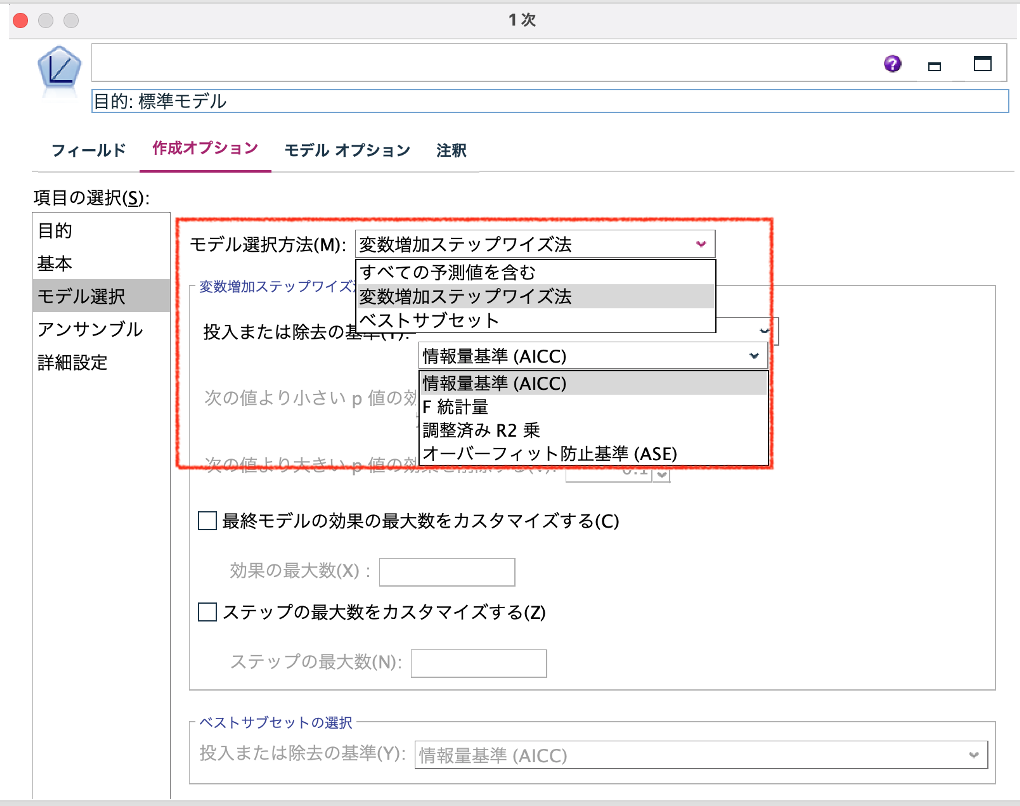
項目の選択:[モデル選択]では、予測フィールドの取捨選択をステップワイズ法やベストセットから選択できます。ベストセットでは、多くの予測フィールドの組み合わせを検討します。そのためテップワイズ法より処理時間がかかる可能性がありますが、よりよい予測フィールドの組み合わせを発見する可能性もあります。
変数の選択、除去の基準は、赤池情報基準値やF値、調整済みR2乗値、平方平均誤差など複数の中から選ぶことができます。
5.参考情報
利用データ
SPSS Modeler 同梱のGOODS1n.csv
ノードのヘルプ
SPSS Modeler ノードリファレンス目次