はじめに
データに重みを付けて分析する方法を整理しました。ここでは、決定木分析のCHAIDを使用します。
環境
Windows10
SPSS Modeler 18.3
SPSS Statistics 28.0.1
データの重みとは
データ分析で使用する各レコード(ケース)の重要度や影響度、また集計されているレコードの場合にはその度数を重み(Weight)と言います。
たとえば、選挙で言われる1票の格差のように地域や規模などによって1レコードの重要性や影響度が異なる場合にその度合いを重みとします。また、契約を解約する男性18人、女性15人、契約を継続する男性17人、女性20人など集計されているデータは1レコードが複数人を表すため度数を重みとして利用します。
クロス集計表で表すと以下の通りです。
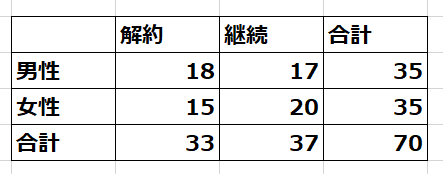
これをSPSS ModelerやSPSS Statisticsで分析するには、次のようにデータを入力します。
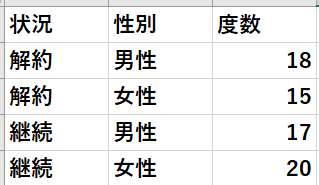
データに重みを付ける
データに重みを付けて分析を行うためには重み変数が必要です。
重み付けの方法は3つあります。

SPSS ModelerとSPSS Statisticsの決定木分析のCHAIDを使って、3つの手続きを実行し比較してみます。
データは、信用度の良好:1,不良:0を階級、給与支払方法、年代3グループ、アメックスの所有を使って予測するモデルを作成するために用意されたものです。
[重み]には、信用度が優良の場合には1,不良の場合には20の影響度を入力しています。
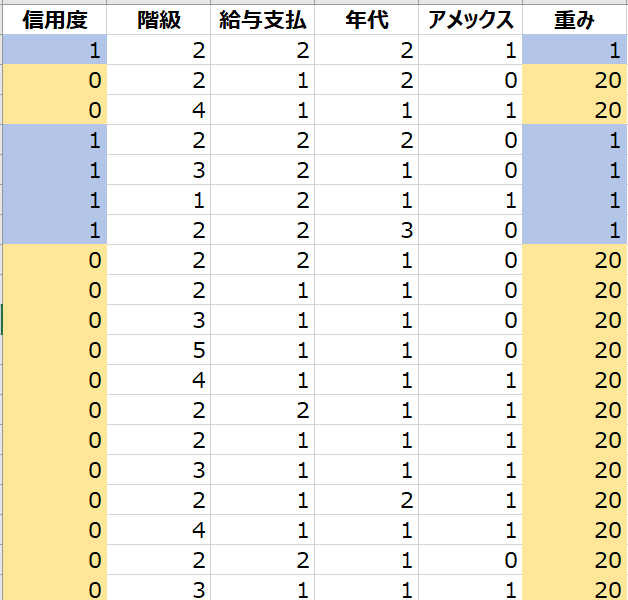
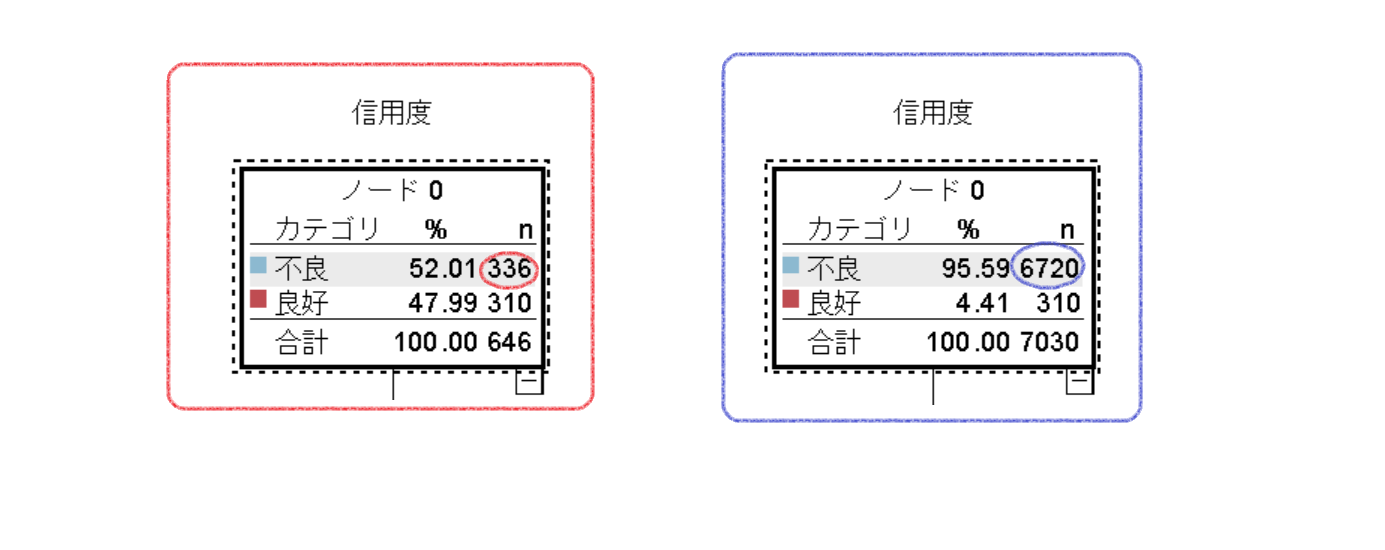
重みを付けずに元データの信用度を集計した結果は、以下の通りです。

不良が336、優良が310、合計で646レコードのデータです。
SPSS Modelerによる重み付け
①データに重み変数として指定する
SPSS Modelerの場合
データ型ノードで、重みフィールドの[ロール]を『度数』にします。
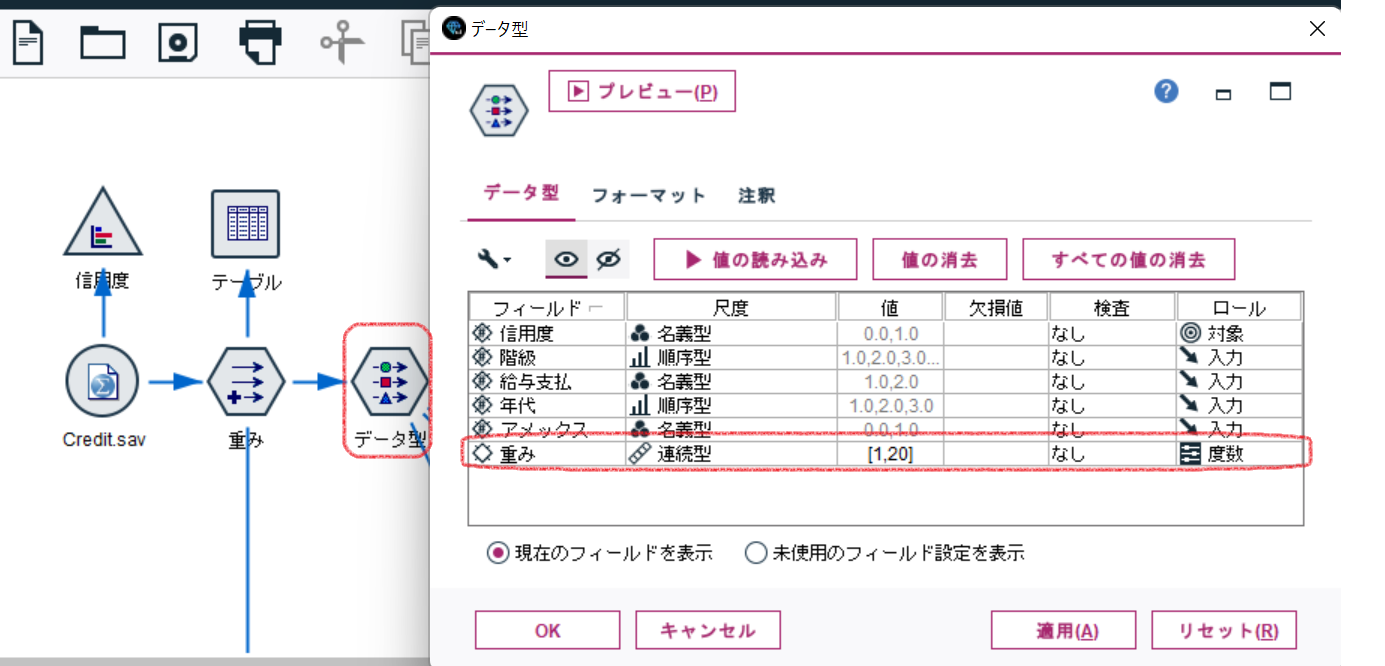
この設定を行うと各レコードが『度数』フィールドに入力されている値で重み付けされ、その入力値分のレコード数で処理されます。
データ型ノードにCHAIDノードをリンクします。
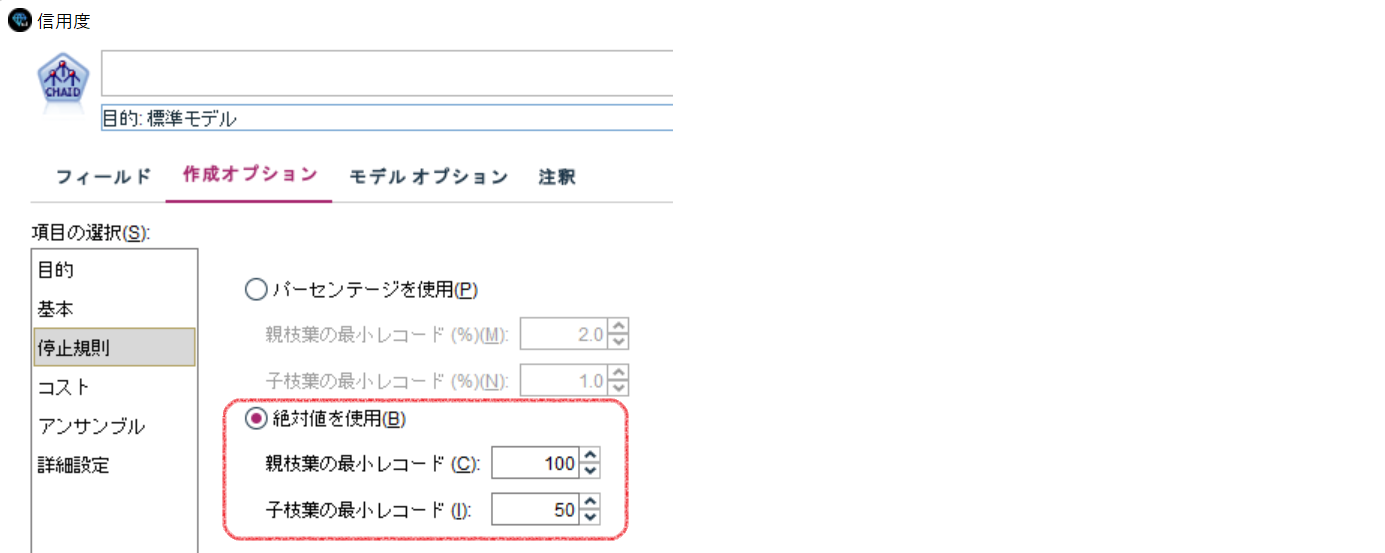
今回はSPSS Statisticsとも比較をしたいので、作成オプションタブの[停止規則]で、『絶対値を使用』を選択します。
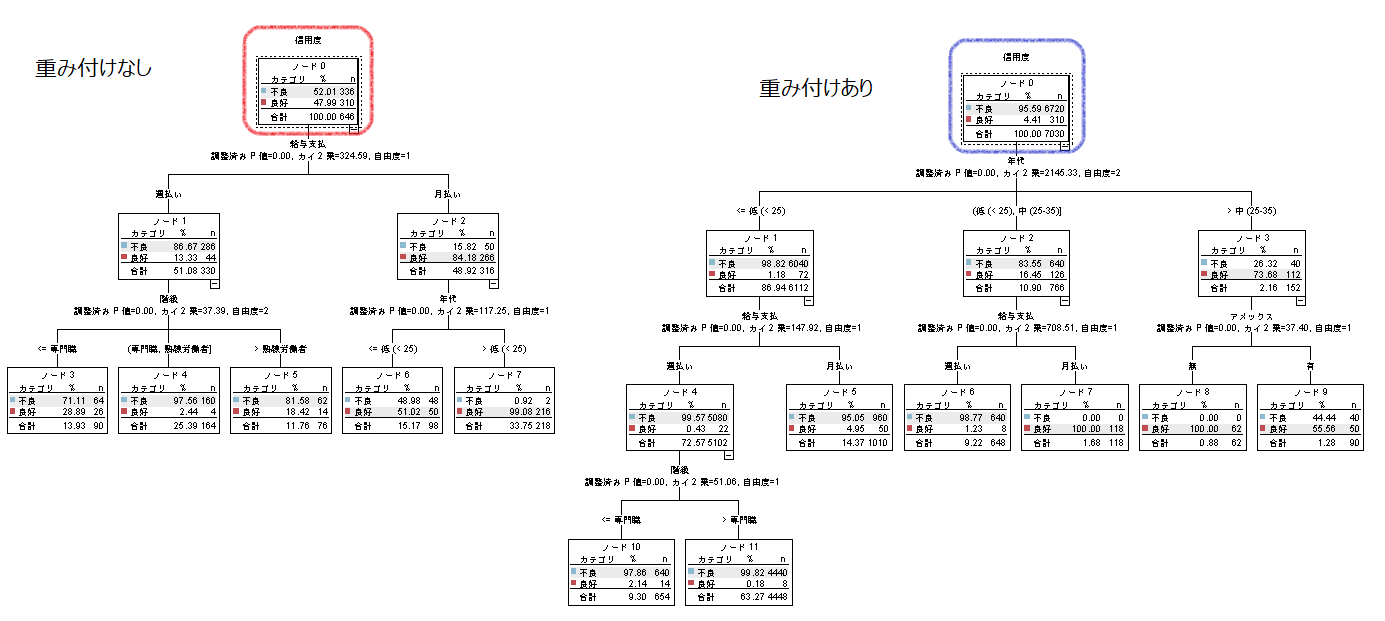
実行結果のモデルナゲットのビューアでツリー図を参照します。
左側のツリー図は、重みフィールドの[ロール]を『なし』にしてCHAIDを実行した結果です。ルートノードの不良の度数を左右のツリー図で比較すると、右側のツリー図のルートノードの不良の度数が6,720で元の度数の336から20倍となっています。データ型ノードの[ロール]を『度数』にしたフィールド(重み)の値をもとにレコードを増幅、つまり重みを付けてモデルを作成します。
ルートノード拡大してみます。
左右のツリー図(ルール)にも違いがあります。
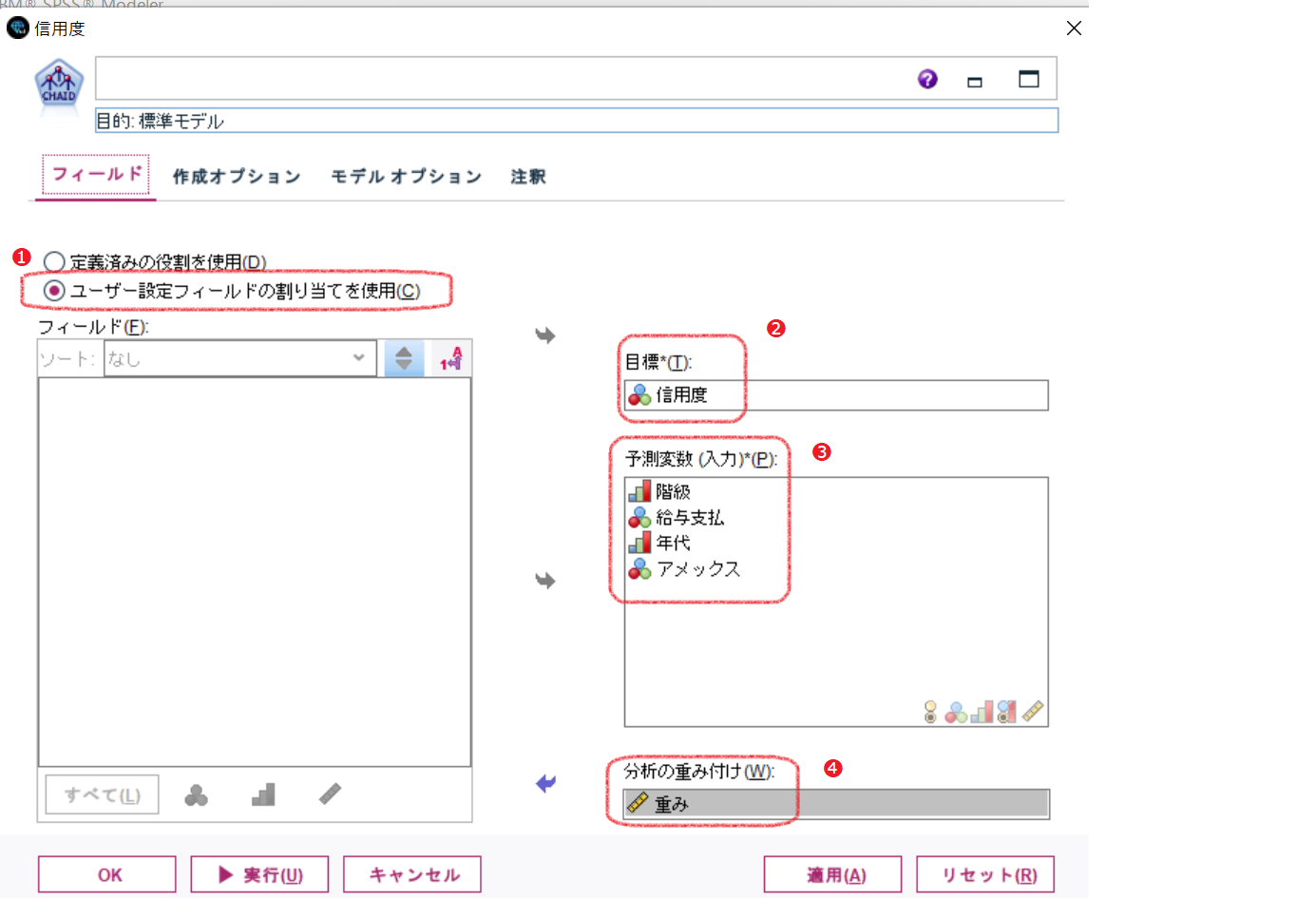
②分析に重み変数として指定する
今度は、重みフィールドをモデル作成ノードで指定します。データ型の重みフィールドの[ロール]は、『なし』にしておきます。
CHAIDノードのフィールドタブの『ユーザー設定フィールドの割り当てを使用』を選択し、目標フィールドに『信用度』、予測変数に『階級』、『給与支払』、『年代』、『アメックス』を指定します。そして、分析の重み付けに『重み』フィールドを指定します。
①と同様に、作成オプションタブの[停止規則]で、『絶対値を使用』を選択します。
実行結果のモデルナゲットのツリー図を参照します。赤枠のルートノードは先ほどの重み付けなしのときと同じ不良と優良の%とnです。緑枠のノード2と6を見ると%とnの少ない不良のカテゴリがグレーになっています。これは分析を実行する際に不良カテゴリに優良カテゴリの20倍の重みを付けているためです。つまり、ノード2の不良カテゴリのnを50X20=1000として、またノード6の不良カテゴリのnは、48X20=960として判定しています。
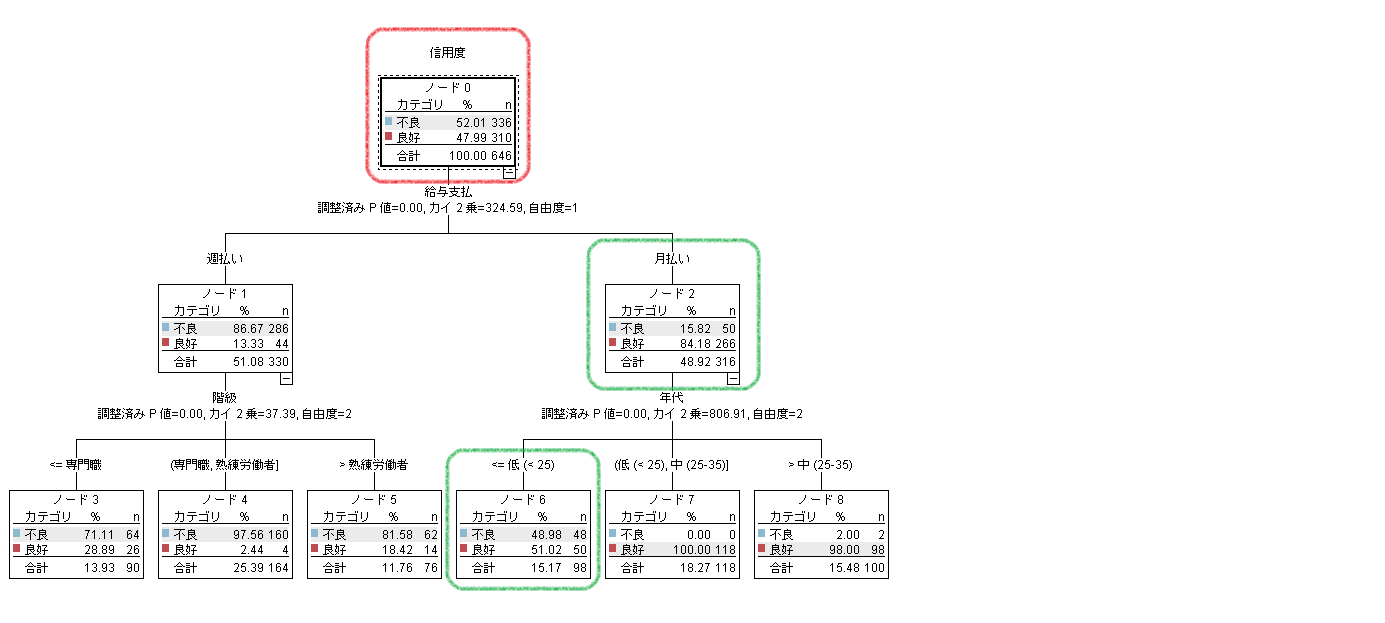
③分析に誤分類コストとして指定する
次に、重みフィールドは使わずに誤分類コストを使用します。この誤分類コストは、誤って予測してしまった場合の損失を考慮して、できるだけコストの高い間違いをしないように判定を制御するものです。優良を不良と予測した誤分類と不良を優良と予測した誤分類を天秤にかけ、どちらがより損失が大きいかで重みをつけます。デフォルトの誤分類行列は、正しい分類の部分はグレーアウトされていて、誤って分類の部分は1.0で同じ重みになっています。今回は、不良にもかかわらず優良と予測したしまった場合のコストが優良を不良と誤ってしまった場合の20倍のコストとして設定します。②と同様にCHAIDノードのフィールドタブの『ユーザー設定フィールドの割り当てを使用』を選択し、目標フィールドに『信用度』、予測変数に『階級』、『給与支払』、『年代』、『アメックス』を指定します。
①と同様に、作成オプションタブの[停止規則]で、『絶対値を使用』を選択します。
[コスト]の『誤分類コストを使用』を選択し、実測が0.0(不良)を予測が1.0(優良)と誤ってしまうセルを1から20に編集します。
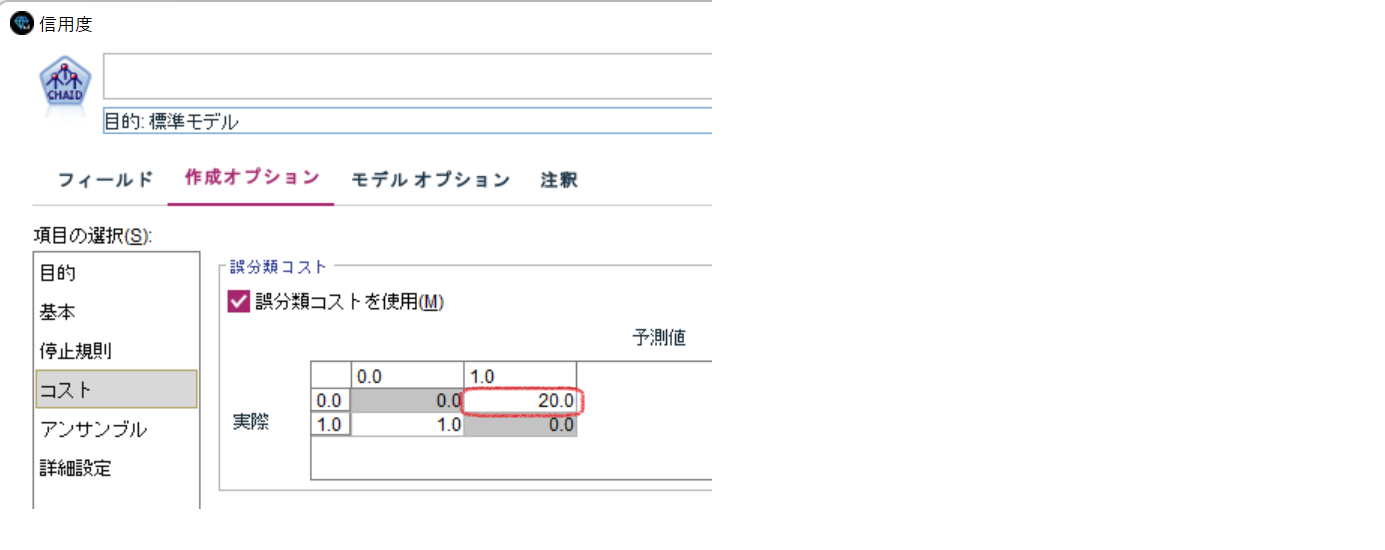
実行結果のモデルナゲットのツリー図を参照します。
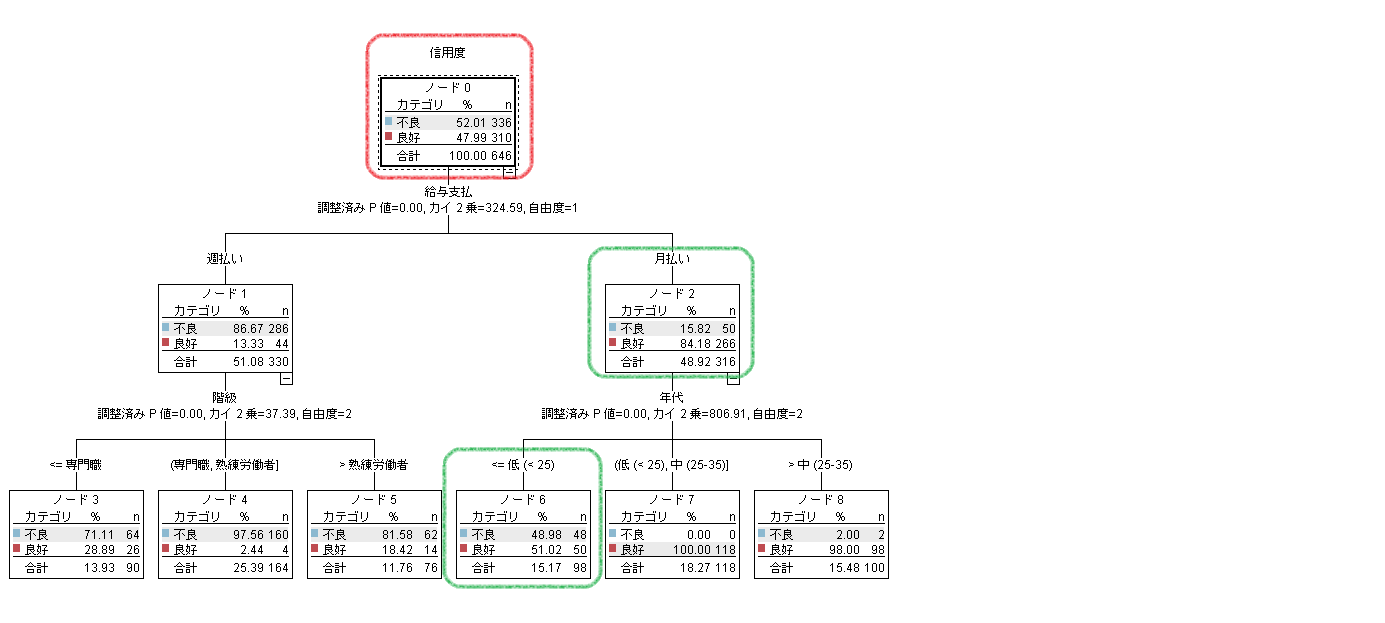
赤枠のルートノードは前の重み付けなしのときと同じ不良と優良の%とnです。そして、緑枠のノード2と6は、②と同じ結果になっています。つまり、誤分類コストも重み付けフィールドの使用も同じ仕様であることがわかります。ちなみに、ツリー図の分岐に記載されている統計量も同じです。手順やアプローチは異なりますが結果は同じです。
SPSS Statisticsによる重み付け
SPSS StatisticsでもSPSS Modelerと同様に3つのパターンを実行してみます。
①データに重み変数として指定する
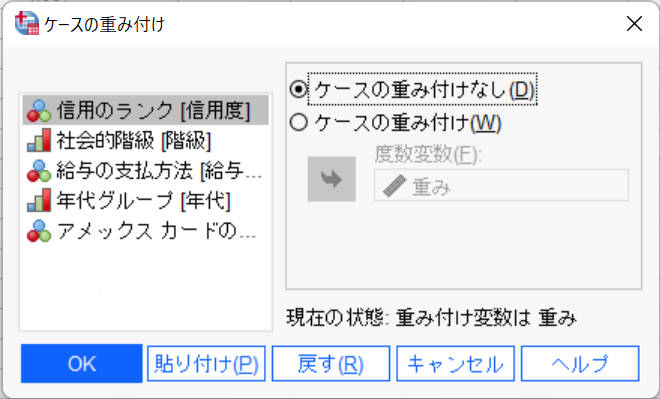
データメニュー>ケースの重み付けを選択します。『ケースの重み付け』を選択して、度数変数に『重み』変数を指定します。
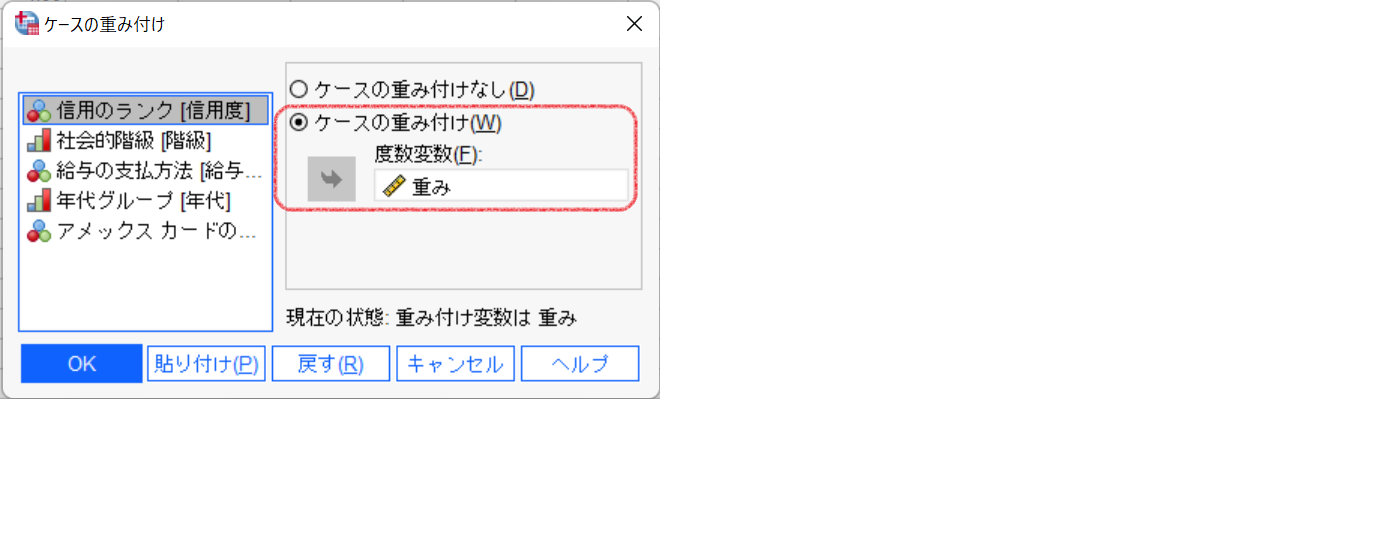
OKボタンをクリックすると、データエディタの右下ステータスラインに【重み付き オン】と表示されます。こでれ、データに重みが付きますので以降すべての操作はデータの重みが反映されます。分析メニュー>分類>ツリーを選択します。従属変数に『信用度』、独立変数に『年代』、『階級』、『アメックス』を指定します。OKボタンをクリックして実行します。
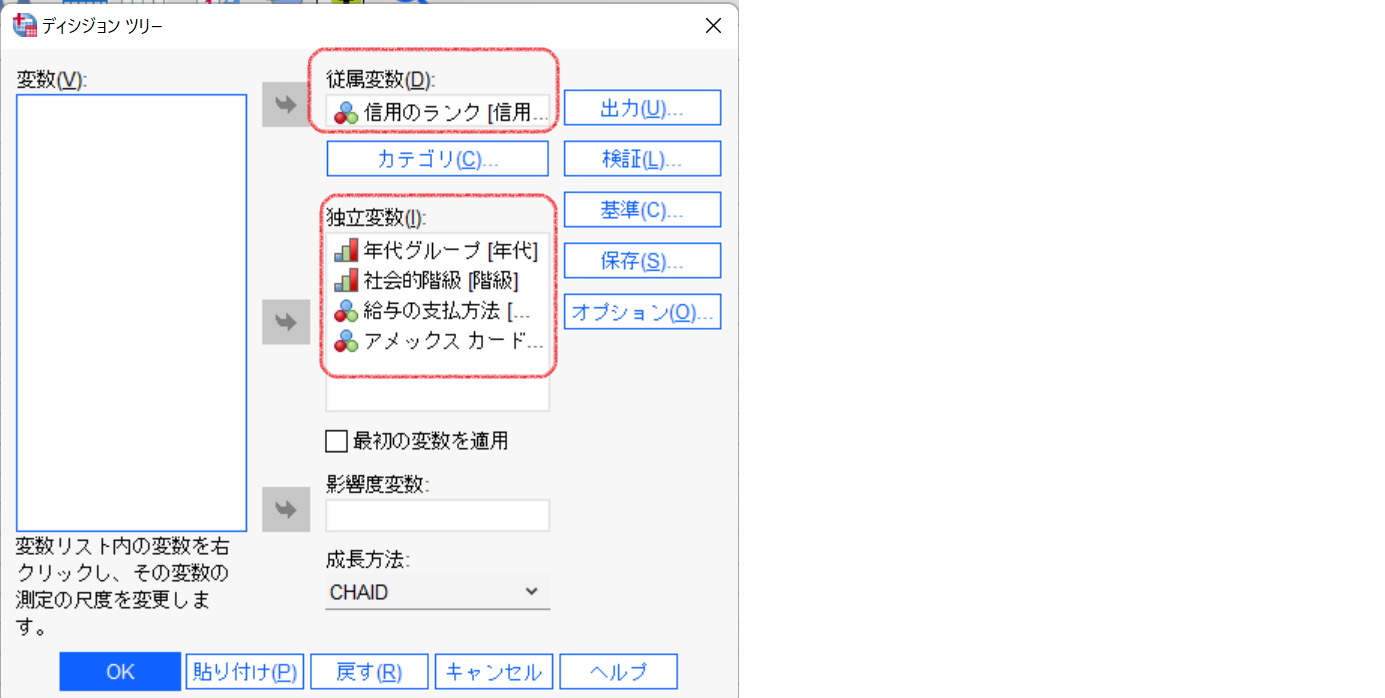
出力ウィンドウに表示されたツリー図を参照します。重みを付ける前のデータで実行した結果と並べてみます。左側が重み付けなし、右側が重み付けありです。SPSS Modelerと同様にルートノードを比較すると不良の度数が20倍になっています。
ルートノードを拡大しました。
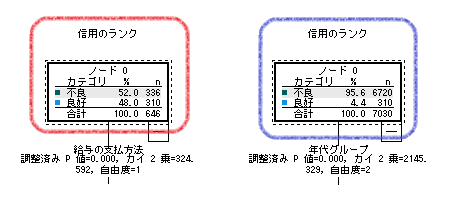
ツリー図にも違いがあります。
②分析に重み変数として指定する
データメニュー>ケースの重み付けを選択し、『ケースの重み付けなし』を選択して、OKボタンをクリックします。
ステータスラインの【重み付き オン】が消えていることを確認します。
分析メニュー>分類>ツリーを選択します。従属変数に『信用度』、独立変数に『年代』、『階級』、『アメックス』を指定します。影響度変数に『重み』変数を指定します。OKボタンをクリックして実行します。
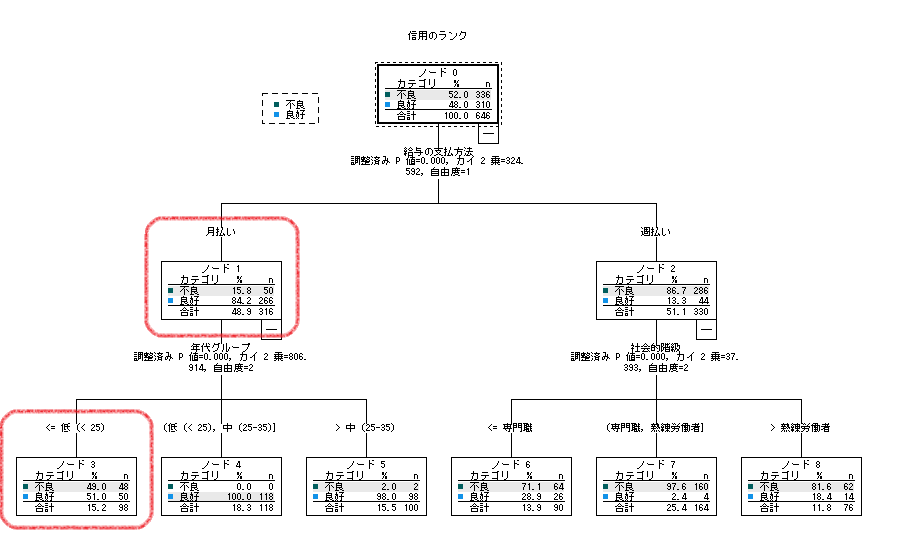
SPSS Modelerのときと同様(ノード番号は異なりますが)ノード1と3が最頻値の優良ではなく、不良を指示しています。
③分析に誤分類コストとして指定する
分析メニュー>分類>ツリーを選択します。従属変数に『信用度』、独立変数に『年代』、『階級』、『アメックス』を指定します。影響度変数の『重み』変数をもとに戻します。オプションボタンをクリックします。誤分類コストタブの『ユーザー指定』を選択します。誤分類行列の仕組みはSPSS Modelerと同様です。実際が不良で予測が良好のセルを1から20に変更します。
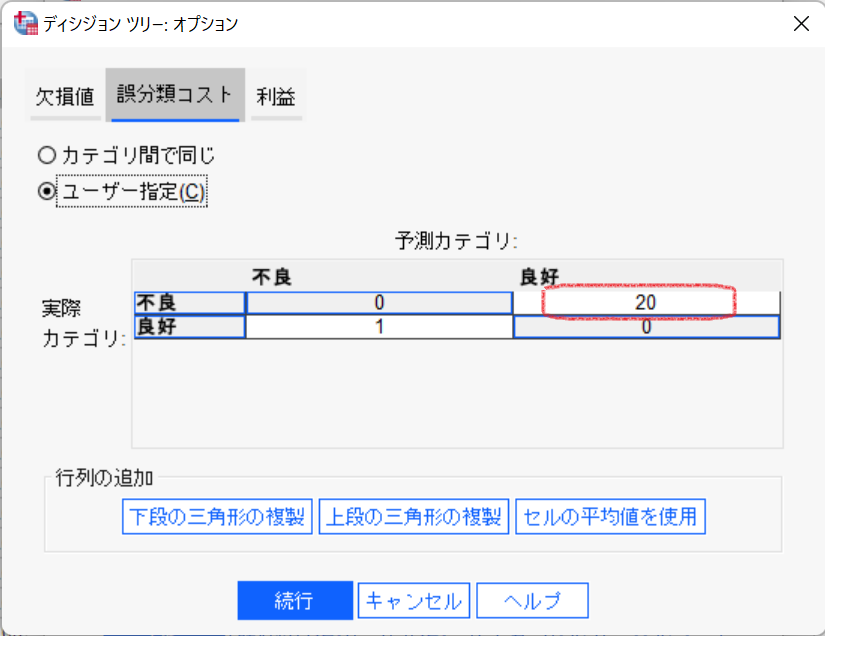
続行ボタンをクリックして、OKボタンをクリックします。
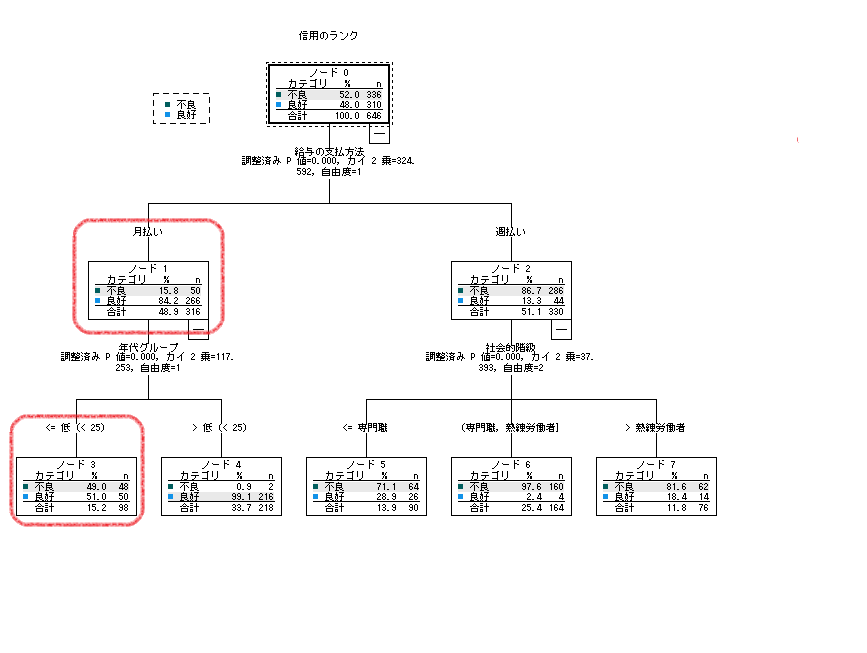
②の結果と同様にノード1と3が最頻値の優良ではなく不良を指示しています。
まとめ
SPSS Modeler、SPSS Statisticsどちらにもデータの重み付けの機能が備わっていて、指定する方法が複数あります。また、②と③は手順やアプローチが異なりますが同じ結果になりました。つまり、誤分類コストは、コストの値がレコードの重みとして処理されているということになります。ちなみに、重みにはゼロは使えませんので注意してください。
◆重み付けの方法
①データに重み変数として指定する
②分析に重み変数として指定する
③分析に誤分類コストとして指定する