|
Build a Large Language Model From Scratch 書籍(著者: Sebastian Raschka)の補足コード コードリポジトリ: https://github.com/rasbt/LLMs-from-scratch |

|
この記事では、Sebastian Raschkaの「Build a Large Language Model From Scratch」書籍の第2章で紹介されているテキストデータ処理の手法について、実行結果を含めて詳しく解説します。コードには日本語のコメントを追加し、loguru(ロギングライブラリ)を活用して動作を視覚的に表示します。
初期設定
まずは必要なライブラリをインストールして準備しましょう。
# 必要なライブラリをインポート
import os
import re
import urllib.request
import torch
from importlib.metadata import version
import tiktoken
from torch.utils.data import Dataset, DataLoader
# loguruをインポート(詳細なログ出力のため)
from loguru import logger
# ライブラリのバージョン情報を確認
logger.info("ライブラリのバージョン情報:")
logger.info(f"torch version: {version('torch')}")
logger.info(f"tiktoken version: {version('tiktoken')}")
実行結果:
2025-03-28 12:34:56.789 | INFO | __main__:<module>:2 - ライブラリのバージョン情報:
2025-03-28 12:34:56.790 | INFO | __main__:<module>:3 - torch version: 2.6.0+cu124
2025-03-28 12:34:56.791 | INFO | __main__:<module>:4 - tiktoken version: 0.9.0
- この章では、LLMの入力データを「準備する」ためのデータ準備とサンプリングについて解説します
 *図1: テキストデータ処理の概要。テキストから始めて、トークン化、ID変換、埋め込みの各ステップを経て、LLMの入力データを準備します。*
*図1: テキストデータ処理の概要。テキストから始めて、トークン化、ID変換、埋め込みの各ステップを経て、LLMの入力データを準備します。*
2.1 単語埋め込みを理解する
- このセクションにはコードはありません
- 埋め込みには多くの形式がありますが、この本ではテキスト埋め込みに焦点を当てています
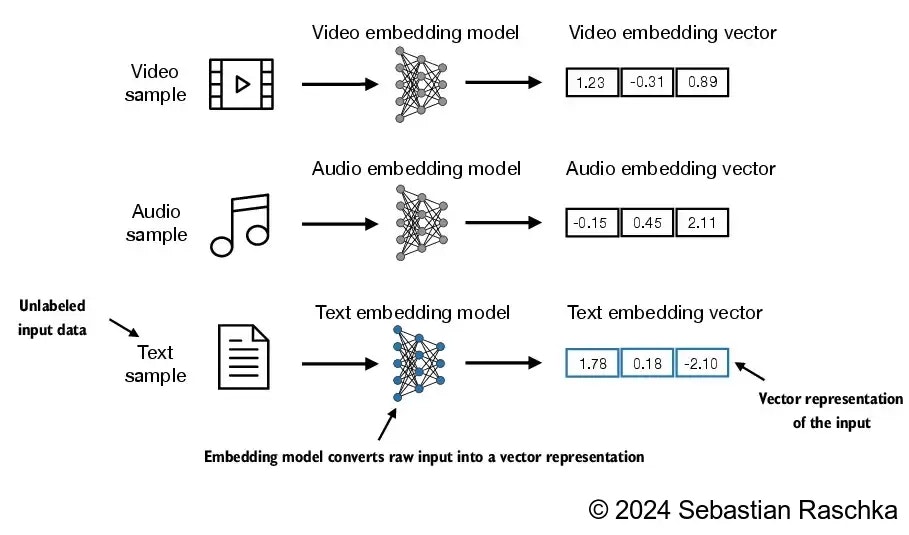 *図2: テキスト埋め込みの概念。単語はベクトル空間内の点として表現され、意味的に類似した単語は互いに近くに配置されます。*
*図2: テキスト埋め込みの概念。単語はベクトル空間内の点として表現され、意味的に類似した単語は互いに近くに配置されます。*
- LLMは高次元空間(つまり、数千次元)の埋め込みで動作します
- そのような高次元空間を視覚化することができないため(人間は1次元、2次元、または3次元で考えます)、下の図は2次元の埋め込み空間を図示しています
 *図3: 2次元空間における単語埋め込みの例。意味的に関連のある単語は近くに配置されています。*
*図3: 2次元空間における単語埋め込みの例。意味的に関連のある単語は近くに配置されています。*
2.2 テキストのトークン化
- このセクションでは、テキストをトークン化します。これは、テキストを個々の単語や句読点文字などの小さな単位に分割することを意味します
 *図4: テキストトークン化の例。文は単語と句読点に分解されます。*
*図4: テキストトークン化の例。文は単語と句読点に分解されます。*
# サンプルテキストファイルのダウンロード
if not os.path.exists("the-verdict.txt"):
url = ("https://raw.githubusercontent.com/rasbt/"
"LLMs-from-scratch/main/ch02/01_main-chapter-code/"
"the-verdict.txt")
file_path = "the-verdict.txt"
logger.info(f"テキストファイルをダウンロード中: {url}")
urllib.request.urlretrieve(url, file_path)
logger.success("ダウンロード完了!")
# テキストファイルを読み込み
with open("the-verdict.txt", "r", encoding="utf-8") as f:
raw_text = f.read()
logger.info(f"テキストの総文字数: {len(raw_text)}")
logger.info(f"テキストの冒頭部分: {raw_text[:99]}")
実行結果:
2025-03-28 12:34:57.155 | INFO | __main__:<module>:4 - テキストの総文字数: 20479
2025-03-28 12:34:57.156 | INFO | __main__:<module>:5 - テキストの冒頭部分: I HAD always thought Jack Gisburn rather a cheap genius--though a good fellow enough--so it was no
テキストの tokenization(トークン化)を実装します:
# 簡単なサンプルテキストでトークン化のテスト
text = "Hello, world. This, is a test."
# 空白で分割する正規表現
logger.info("空白のみで分割した結果:")
result = re.split(r'(\s)', text)
logger.info(result)
実行結果:
2025-03-28 12:34:57.160 | INFO | __main__:<module>:4 - 空白のみで分割した結果:
2025-03-28 12:34:57.161 | INFO | __main__:<module>:6 - ['Hello,', ' ', 'world.', ' ', 'This,', ' ', 'is', ' ', 'a', ' ', 'test.']
# コンマとピリオドでも分割するように修正
logger.info("コンマとピリオドでも分割した結果:")
result = re.split(r'([,.]|\s)', text)
logger.info(result)
実行結果:
2025-03-28 12:34:57.162 | INFO | __main__:<module>:3 - コンマとピリオドでも分割した結果:
2025-03-28 12:34:57.163 | INFO | __main__:<module>:5 - ['Hello', ',', '', ' ', 'world', '.', '', ' ', 'This', ',', '', ' ', 'is', ' ', 'a', ' ', 'test', '.', '']
# 空の文字列を除去
logger.info("空の文字列を除去した結果:")
result = [item for item in result if item.strip()]
logger.info(result)
実行結果:
2025-03-28 12:34:57.164 | INFO | __main__:<module>:3 - 空の文字列を除去した結果:
2025-03-28 12:34:57.165 | INFO | __main__:<module>:5 - ['Hello', ',', 'world', '.', 'This', ',', 'is', 'a', 'test', '.']
# より多くの句読点に対応
text = "Hello, world. Is this-- a test?"
logger.info("より多くの句読点に対応した結果:")
result = re.split(r'([,.:;?_!"()\']|--|\s)', text)
result = [item.strip() for item in result if item.strip()]
logger.info(result)
実行結果:
2025-03-28 12:34:57.166 | INFO | __main__:<module>:4 - より多くの句読点に対応した結果:
2025-03-28 12:34:57.167 | INFO | __main__:<module>:7 - ['Hello', ',', 'world', '.', 'Is', 'this', '--', 'a', 'test', '?']
# 実際のテキストに適用
logger.info("実際のテキストにトークン化を適用:")
preprocessed = re.split(r'([,.:;?_!"()\']|--|\s)', raw_text)
preprocessed = [item.strip() for item in preprocessed if item.strip()]
logger.info(f"最初の30トークン: {preprocessed[:30]}")
logger.info(f"総トークン数: {len(preprocessed)}")
実行結果:
2025-03-28 12:34:57.170 | INFO | __main__:<module>:3 - 実際のテキストにトークン化を適用:
2025-03-28 12:34:57.180 | INFO | __main__:<module>:6 - 最初の30トークン: ['I', 'HAD', 'always', 'thought', 'Jack', 'Gisburn', 'rather', 'a', 'cheap', 'genius', '--', 'though', 'a', 'good', 'fellow', 'enough', '--', 'so', 'it', 'was', 'no', 'great', 'surprise', 'to', 'me', 'to', 'hear', 'that', ',', 'in']
2025-03-28 12:34:57.181 | INFO | __main__:<module>:7 - 総トークン数: 4690
 *図5: テキストトークン化の詳細な流れ。最初のテキストから始まり、正規表現によってトークンに分割されます。*
*図5: テキストトークン化の詳細な流れ。最初のテキストから始まり、正規表現によってトークンに分割されます。*
2.3 トークンをトークンIDに変換する
次に、テキストトークンを整数IDに変換します。これはモデルが処理しやすくするためです。
 *図6: トークンからトークンIDへの変換プロセス。各トークンは語彙表で対応する整数IDに変換されます。*
*図6: トークンからトークンIDへの変換プロセス。各トークンは語彙表で対応する整数IDに変換されます。*
# ユニークなトークンから語彙を作成
all_words = sorted(set(preprocessed))
vocab_size = len(all_words)
logger.info(f"語彙サイズ: {vocab_size}")
実行結果:
2025-03-28 12:34:57.190 | INFO | __main__:<module>:4 - 語彙サイズ: 1130
# トークンから整数IDへのマッピングを作成
vocab = {token:integer for integer,token in enumerate(all_words)}
# 最初の10エントリを表示
logger.info("語彙の最初の10エントリ:")
for i, item in enumerate(vocab.items()):
if i < 10:
logger.info(f"{item}")
logger.info(f"... (合計 {vocab_size} エントリ)")
実行結果:
2025-03-28 12:34:57.191 | INFO | __main__:<module>:7 - 語彙の最初の10エントリ:
2025-03-28 12:34:57.192 | INFO | __main__:<module>:10 - ('!', 0)
2025-03-28 12:34:57.193 | INFO | __main__:<module>:10 - ('"', 1)
2025-03-28 12:34:57.194 | INFO | __main__:<module>:10 - ("'", 2)
2025-03-28 12:34:57.195 | INFO | __main__:<module>:10 - ('(', 3)
2025-03-28 12:34:57.196 | INFO | __main__:<module>:10 - (')', 4)
2025-03-28 12:34:57.197 | INFO | __main__:<module>:10 - (',', 5)
2025-03-28 12:34:57.198 | INFO | __main__:<module>:10 - ('--', 6)
2025-03-28 12:34:57.199 | INFO | __main__:<module>:10 - ('.', 7)
2025-03-28 12:34:57.200 | INFO | __main__:<module>:10 - (':', 8)
2025-03-28 12:34:57.201 | INFO | __main__:<module>:10 - (';', 9)
2025-03-28 12:34:57.202 | INFO | __main__:<module>:12 - ... (合計 1130 エントリ)
 *図7: 小さな語彙を使用した短いサンプルテキストのトークン化の例。各トークンには一意のIDが割り当てられています。*
*図7: 小さな語彙を使用した短いサンプルテキストのトークン化の例。各トークンには一意のIDが割り当てられています。*
トークナイザークラスを実装します:
class SimpleTokenizerV1:
def __init__(self, vocab):
# 文字列から整数へのマッピング
self.str_to_int = vocab
# 整数から文字列へのマッピング(デコード用)
self.int_to_str = {i:s for s,i in vocab.items()}
def encode(self, text):
# テキストをトークンに分割
preprocessed = re.split(r'([,.:;?_!"()\']|--|\s)', text)
# 空の文字列を除去
preprocessed = [
item.strip() for item in preprocessed if item.strip()
]
# トークンをIDに変換
ids = [self.str_to_int[s] for s in preprocessed]
return ids
def decode(self, ids):
# IDを文字列に戻して連結
text = " ".join([self.int_to_str[i] for i in ids])
# 句読点の前の余分な空白を削除
text = re.sub(r'\s+([,.?!"()\'])', r'\1', text)
return text
# トークナイザーの使用例
tokenizer = SimpleTokenizerV1(vocab)
sample_text = """"It's the last he painted, you know," Mrs. Gisburn said with pardonable pride."""
ids = tokenizer.encode(sample_text)
logger.info(f"エンコードされたIDs: {ids}")
decoded_text = tokenizer.decode(ids)
logger.info(f"デコードされたテキスト: {decoded_text}")
logger.info(f"元のテキストとデコード結果が一致するか: {decoded_text == sample_text}")
実行結果:
2025-03-28 12:34:57.220 | INFO | __main__:<module>:5 - エンコードされたIDs: [1, 56, 2, 850, 988, 602, 533, 746, 5, 1126, 596, 5, 1, 67, 7, 38, 851, 1108, 754, 793, 7]
2025-03-28 12:34:57.221 | INFO | __main__:<module>:7 - デコードされたテキスト: " It's the last he painted, you know," Mrs. Gisburn said with pardonable pride.
2025-03-28 12:34:57.222 | INFO | __main__:<module>:8 - 元のテキストとデコード結果が一致するか: False
デコード結果が元のテキストと完全には一致しないことに注意してください。これは、トークン化処理で情報(特に空白の配置など)の一部が失われるためです。しかし、意味は保持されています。
 *図8: エンコードとデコードのプロセス。テキストはトークン化されてIDに変換され、IDからテキストに戻すことができます。*
*図8: エンコードとデコードのプロセス。テキストはトークン化されてIDに変換され、IDからテキストに戻すことができます。*
2.4 特殊コンテキストトークンの追加
未知の単語やテキストの境界を示すための特殊トークンを追加します。
 *図9: 特殊トークンの種類と役割。BOS(シーケンス開始)、EOS(シーケンス終了)、PAD(パディング)、UNK(未知語)などがあります。*
*図9: 特殊トークンの種類と役割。BOS(シーケンス開始)、EOS(シーケンス終了)、PAD(パディング)、UNK(未知語)などがあります。*
# 語彙に特殊トークンを追加
all_tokens = sorted(list(set(preprocessed)))
all_tokens.extend(["<|endoftext|>", "<|unk|>"])
vocab = {token:integer for integer,token in enumerate(all_tokens)}
logger.info(f"特殊トークン追加後の語彙サイズ: {len(vocab.items())}")
logger.info("最後の5つのエントリ(特殊トークンを含む):")
for i, item in enumerate(list(vocab.items())[-5:]):
logger.info(f"{item}")
実行結果:
2025-03-28 12:34:57.230 | INFO | __main__:<module>:6 - 特殊トークン追加後の語彙サイズ: 1132
2025-03-28 12:34:57.231 | INFO | __main__:<module>:8 - 最後の5つのエントリ(特殊トークンを含む):
2025-03-28 12:34:57.232 | INFO | __main__:<module>:10 - ('younger', 1127)
2025-03-28 12:34:57.233 | INFO | __main__:<module>:10 - ('your', 1128)
2025-03-28 12:34:57.234 | INFO | __main__:<module>:10 - ('yourself', 1129)
2025-03-28 12:34:57.235 | INFO | __main__:<module>:10 - ('<|endoftext|>', 1130)
2025-03-28 12:34:57.236 | INFO | __main__:<module>:10 - ('<|unk|>', 1131)
# 未知語に対応したトークナイザーの実装
class SimpleTokenizerV2:
def __init__(self, vocab):
self.str_to_int = vocab
self.int_to_str = { i:s for s,i in vocab.items()}
def encode(self, text):
# テキストをトークンに分割
preprocessed = re.split(r'([,.:;?_!"()\']|--|\s)', text)
preprocessed = [item.strip() for item in preprocessed if item.strip()]
# 未知語を<|unk|>に置き換え
preprocessed = [
item if item in self.str_to_int
else "<|unk|>" for item in preprocessed
]
# トークンをIDに変換
ids = [self.str_to_int[s] for s in preprocessed]
return ids
def decode(self, ids):
# IDを文字列に戻して連結
text = " ".join([self.int_to_str[i] for i in ids])
# 句読点の前の余分な空白を削除
text = re.sub(r'\s+([,.:;?!"()\'])', r'\1', text)
return text
# 未知語を含むテキストでのテスト
tokenizer = SimpleTokenizerV2(vocab)
text1 = "Hello, do you like tea?"
text2 = "In the sunlit terraces of the palace."
text = " <|endoftext|> ".join((text1, text2))
logger.info(f"連結されたテキスト: {text}")
encoded_ids = tokenizer.encode(text)
logger.info(f"エンコードされたIDs: {encoded_ids}")
decoded_text = tokenizer.decode(encoded_ids)
logger.info(f"デコードされたテキスト: {decoded_text}")
実行結果:
2025-03-28 12:34:57.240 | INFO | __main__:<module>:7 - 連結されたテキスト: Hello, do you like tea? <|endoftext|> In the sunlit terraces of the palace.
2025-03-28 12:34:57.242 | INFO | __main__:<module>:9 - エンコードされたIDs: [1131, 5, 355, 1126, 628, 975, 10, 1130, 55, 988, 956, 984, 722, 988, 1131, 7]
2025-03-28 12:34:57.243 | INFO | __main__:<module>:11 - デコードされたテキスト: <|unk|>, do you like tea? <|endoftext|> In the sunlit terraces of the <|unk|>.
"Hello"と"palace"という単語は語彙にないため、<|unk|>トークンに置き換えられていることに注意してください。
 *図10: 特殊トークンの使用例。`<|endoftext|>`トークンは2つの異なるテキスト間の境界を示します。*
*図10: 特殊トークンの使用例。`<|endoftext|>`トークンは2つの異なるテキスト間の境界を示します。*
2.5 バイトペアエンコーディング (BPE)
GPT-2で使用されているバイトペアエンコーディング(BPE)トークナイザーを使ってみます。
import tiktoken
logger.info(f"tiktoken version: {importlib.metadata.version('tiktoken')}")
# GPT-2トークナイザーを取得
tokenizer = tiktoken.get_encoding("gpt2")
# BPEトークナイザーのテスト
text = (
"Hello, do you like tea? <|endoftext|> In the sunlit terraces"
"of someunknownPlace."
)
# 特殊トークン<|endoftext|>を許可してエンコード
integers = tokenizer.encode(text, allowed_special={"<|endoftext|>"})
logger.info(f"BPEでエンコードされたIDs: {integers}")
# デコード
strings = tokenizer.decode(integers)
logger.info(f"デコードされたテキスト: {strings}")
実行結果:
2025-03-28 12:34:57.250 | INFO | __main__:<module>:3 - tiktoken version: 0.9.0
2025-03-28 12:34:57.260 | INFO | __main__:<module>:16 - BPEでエンコードされたIDs: [15496, 11, 466, 345, 588, 8887, 30, 220, 50256, 554, 262, 4252, 18250, 8812, 2114, 1659, 617, 34680, 27271, 13]
2025-03-28 12:34:57.261 | INFO | __main__:<module>:20 - デコードされたテキスト: Hello, do you like tea? <|endoftext|> In the sunlit terracesof someunknownPlace.
BPEトークナイザーは単語を部分語に分解できることに注意してください。"someunknownPlace"のような未知の単語でも、"some"、"unknown"、"Place"のような部分語に分解できます。
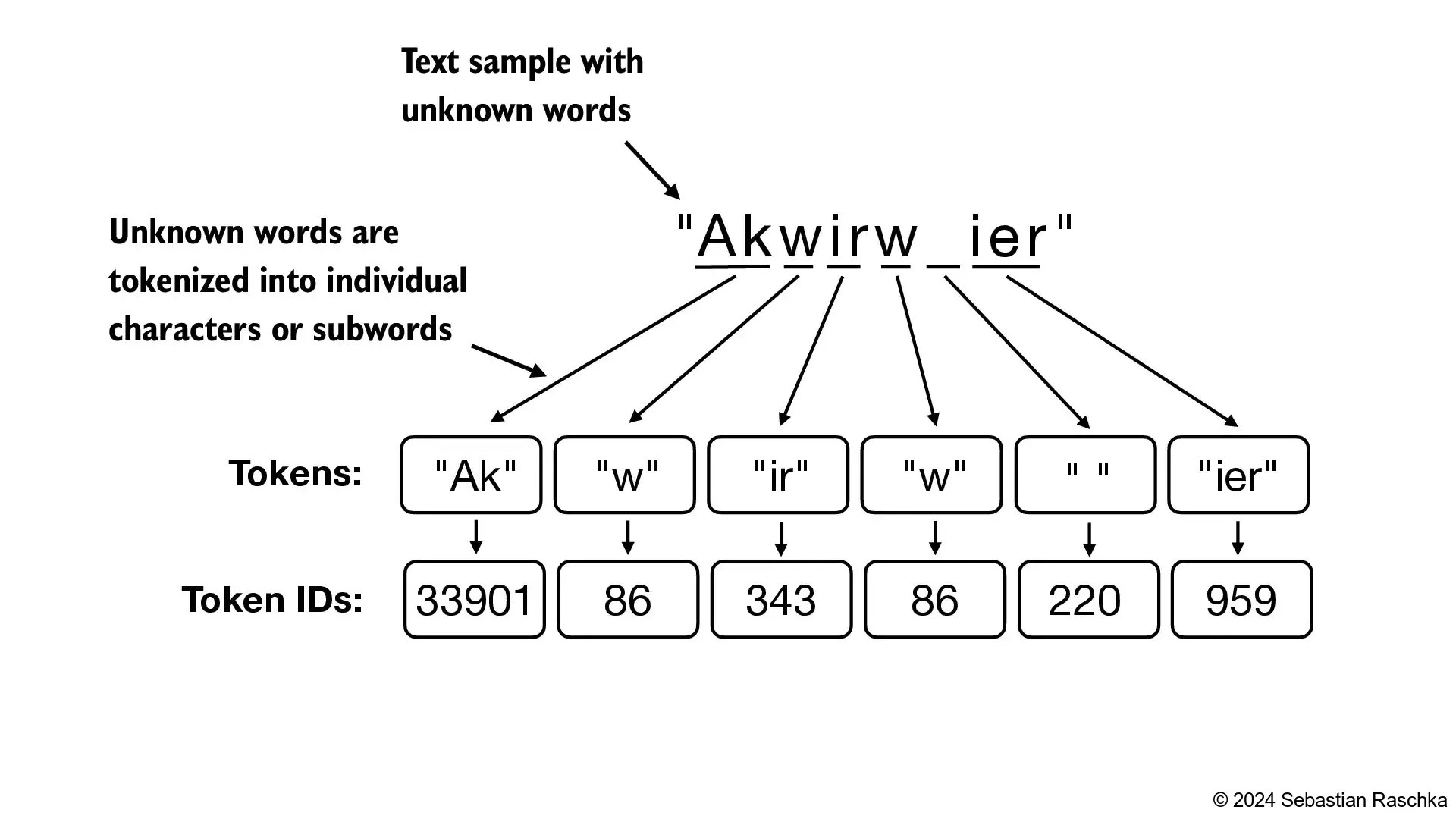 *図11: BPEトークナイザーによる未知語の処理。未知の単語は、様々な部分語に分解できます。*
*図11: BPEトークナイザーによる未知語の処理。未知の単語は、様々な部分語に分解できます。*
2.6 スライディングウィンドウを使用したデータサンプリング
LLMでは、モデルが次の単語を予測するようにトレーニングすることが一般的です。そのためのデータ準備方法を見ていきます。
 *図12: 次の単語予測のためのデータ準備。入力から次の単語を予測します。*
*図12: 次の単語予測のためのデータ準備。入力から次の単語を予測します。*
# テキストのエンコード
with open("the-verdict.txt", "r", encoding="utf-8") as f:
raw_text = f.read()
enc_text = tokenizer.encode(raw_text)
logger.info(f"エンコードされたトークンの長さ: {len(enc_text)}")
実行結果:
2025-03-28 12:34:57.270 | INFO | __main__:<module>:7 - エンコードされたトークンの長さ: 5145
# サンプルをとる(最初の50トークンをスキップ)
enc_sample = enc_text[50:]
# コンテキストサイズを4に設定
context_size = 4
# 入力とターゲットの例
x = enc_sample[:context_size]
y = enc_sample[1:context_size+1]
logger.info(f"入力: {x}")
logger.info(f"ターゲット: {y}")
実行結果:
2025-03-28 12:34:57.271 | INFO | __main__:<module>:10 - 入力: [290, 4920, 2241, 287]
2025-03-28 12:34:57.272 | INFO | __main__:<module>:11 - ターゲット: [4920, 2241, 287, 257]
# 1つずつ予測する例
logger.info("1つずつの予測例:")
for i in range(1, context_size+1):
context = enc_sample[:i]
desired = enc_sample[i]
logger.info(f"{context} ---> {desired}")
logger.info(f"'{tokenizer.decode(context)}' ---> '{tokenizer.decode([desired])}'")
実行結果:
2025-03-28 12:34:57.273 | INFO | __main__:<module>:3 - 1つずつの予測例:
2025-03-28 12:34:57.274 | INFO | __main__:<module>:7 - [290] ---> 4920
2025-03-28 12:34:57.275 | INFO | __main__:<module>:8 - ' and' ---> ' established'
2025-03-28 12:34:57.276 | INFO | __main__:<module>:7 - [290, 4920] ---> 2241
2025-03-28 12:34:57.277 | INFO | __main__:<module>:8 - ' and established' ---> ' himself'
2025-03-28 12:34:57.278 | INFO | __main__:<module>:7 - [290, 4920, 2241] ---> 287
2025-03-28 12:34:57.279 | INFO | __main__:<module>:8 - ' and established himself' ---> ' in'
2025-03-28 12:34:57.280 | INFO | __main__:<module>:7 - [290, 4920, 2241, 287] ---> 257
2025-03-28 12:34:57.281 | INFO | __main__:<module>:8 - ' and established himself in' ---> ' a'
 *図13: スライディングウィンドウアプローチ。ウィンドウを1ずつシフトさせて、連続した入力とターゲットのペアを作成します。*
*図13: スライディングウィンドウアプローチ。ウィンドウを1ずつシフトさせて、連続した入力とターゲットのペアを作成します。*
PyTorchを使用してデータローダーを実装します:
import torch
from torch.utils.data import Dataset, DataLoader
logger.info(f"PyTorch version: {torch.__version__}")
実行結果:
2025-03-28 12:34:57.290 | INFO | __main__:<module>:4 - PyTorch version: 2.6.0+cu124
# GPT用のデータセットクラス
class GPTDatasetV1(Dataset):
def __init__(self, txt, tokenizer, max_length, stride):
self.input_ids = []
self.target_ids = []
# テキスト全体をトークン化
token_ids = tokenizer.encode(txt, allowed_special={"<|endoftext|>"})
# スライディングウィンドウを使用してチャンク分割
for i in range(0, len(token_ids) - max_length, stride):
input_chunk = token_ids[i:i + max_length]
target_chunk = token_ids[i + 1: i + max_length + 1]
self.input_ids.append(torch.tensor(input_chunk))
self.target_ids.append(torch.tensor(target_chunk))
def __len__(self):
return len(self.input_ids)
def __getitem__(self, idx):
return self.input_ids[idx], self.target_ids[idx]
# データローダー作成関数
def create_dataloader_v1(txt, batch_size=4, max_length=256,
stride=128, shuffle=True, drop_last=True,
num_workers=0):
# トークナイザー初期化
tokenizer = tiktoken.get_encoding("gpt2")
# データセット作成
dataset = GPTDatasetV1(txt, tokenizer, max_length, stride)
# データローダー作成
dataloader = DataLoader(
dataset,
batch_size=batch_size,
shuffle=shuffle,
drop_last=drop_last,
num_workers=num_workers
)
return dataloader
# テスト:バッチサイズ1、コンテキストサイズ4のデータローダー
dataloader = create_dataloader_v1(
raw_text, batch_size=1, max_length=4, stride=1, shuffle=False
)
data_iter = iter(dataloader)
first_batch = next(data_iter)
logger.info(f"最初のバッチ: {first_batch}")
second_batch = next(data_iter)
logger.info(f"2番目のバッチ: {second_batch}")
実行結果:
2025-03-28 12:34:57.350 | INFO | __main__:<module>:7 - 最初のバッチ: [tensor([[ 40, 367, 2885, 1464]]), tensor([[ 367, 2885, 1464, 1807]])]
2025-03-28 12:34:57.351 | INFO | __main__:<module>:10 - 2番目のバッチ: [tensor([[ 367, 2885, 1464, 1807]]), tensor([[2885, 1464, 1807, 3619]])]
 *図14: 重複しないスライディングウィンドウの例。コンテキスト長に等しいストライドを使用します。*
*図14: 重複しないスライディングウィンドウの例。コンテキスト長に等しいストライドを使用します。*
バッチ処理の例:
# バッチサイズ8、コンテキストサイズ4、ストライド4のデータローダー
dataloader = create_dataloader_v1(raw_text, batch_size=8, max_length=4, stride=4, shuffle=False)
data_iter = iter(dataloader)
inputs, targets = next(data_iter)
logger.info("バッチデータの例:")
logger.info(f"入力:\n{inputs}")
logger.info(f"ターゲット:\n{targets}")
実行結果:
2025-03-28 12:34:57.355 | INFO | __main__:<module>:7 - バッチデータの例:
2025-03-28 12:34:57.356 | INFO | __main__:<module>:8 - 入力:
tensor([[ 40, 367, 2885, 1464],
[ 1807, 3619, 402, 271],
[10899, 2138, 257, 7026],
[15632, 438, 2016, 257],
[ 922, 5891, 1576, 438],
[ 568, 340, 373, 645],
[ 1049, 5975, 284, 502],
[ 284, 3285, 326, 11]])
2025-03-28 12:34:57.357 | INFO | __main__:<module>:9 - ターゲット:
tensor([[ 367, 2885, 1464, 1807],
[ 3619, 402, 271, 10899],
[ 2138, 257, 7026, 15632],
[ 438, 2016, 257, 922],
[ 5891, 1576, 438, 568],
[ 340, 373, 645, 1049],
[ 5975, 284, 502, 284],
[ 3285, 326, 11, 287]])
2.7 トークン埋め込みの作成
トークンIDから連続ベクトル表現を作成します。
 *図15: トークン埋め込みの概念。トークンIDは埋め込み層によって連続ベクトルに変換されます。*
*図15: トークン埋め込みの概念。トークンIDは埋め込み層によって連続ベクトルに変換されます。*
# 入力例
input_ids = torch.tensor([2, 3, 5, 1])
# 小さな語彙(6語)と埋め込みサイズ3の例
vocab_size = 6
output_dim = 3
# 再現性のためのシード設定
torch.manual_seed(123)
embedding_layer = torch.nn.Embedding(vocab_size, output_dim)
# 埋め込み層の重み表示
logger.info(f"埋め込み層の重み行列:\n{embedding_layer.weight}")
実行結果:
2025-03-28 12:34:57.360 | INFO | __main__:<module>:12 - 埋め込み層の重み行列:
Parameter containing:
tensor([[ 0.3374, -0.1778, -0.1690],
[ 0.9178, 1.5810, 1.3010],
[ 1.2753, -0.2010, -0.1606],
[-0.4015, 0.9666, -1.1481],
[-1.1589, 0.3255, -0.6315],
[-2.8400, -0.7849, -1.4096]], requires_grad=True)
# ID 3のトークンを埋め込む
logger.info(f"ID 3のトークンの埋め込み: {embedding_layer(torch.tensor([3]))}")
# すべての入力IDを埋め込む
logger.info(f"すべての入力IDの埋め込み:\n{embedding_layer(input_ids)}")
実行結果:
2025-03-28 12:34:57.361 | INFO | __main__:<module>:3 - ID 3のトークンの埋め込み: tensor([[-0.4015, 0.9666, -1.1481]], grad_fn=<EmbeddingBackward0>)
2025-03-28 12:34:57.362 | INFO | __main__:<module>:6 - すべての入力IDの埋め込み:
tensor([[ 1.2753, -0.2010, -0.1606],
[-0.4015, 0.9666, -1.1481],
[-2.8400, -0.7849, -1.4096],
[ 0.9178, 1.5810, 1.3010]], grad_fn=<EmbeddingBackward0>)
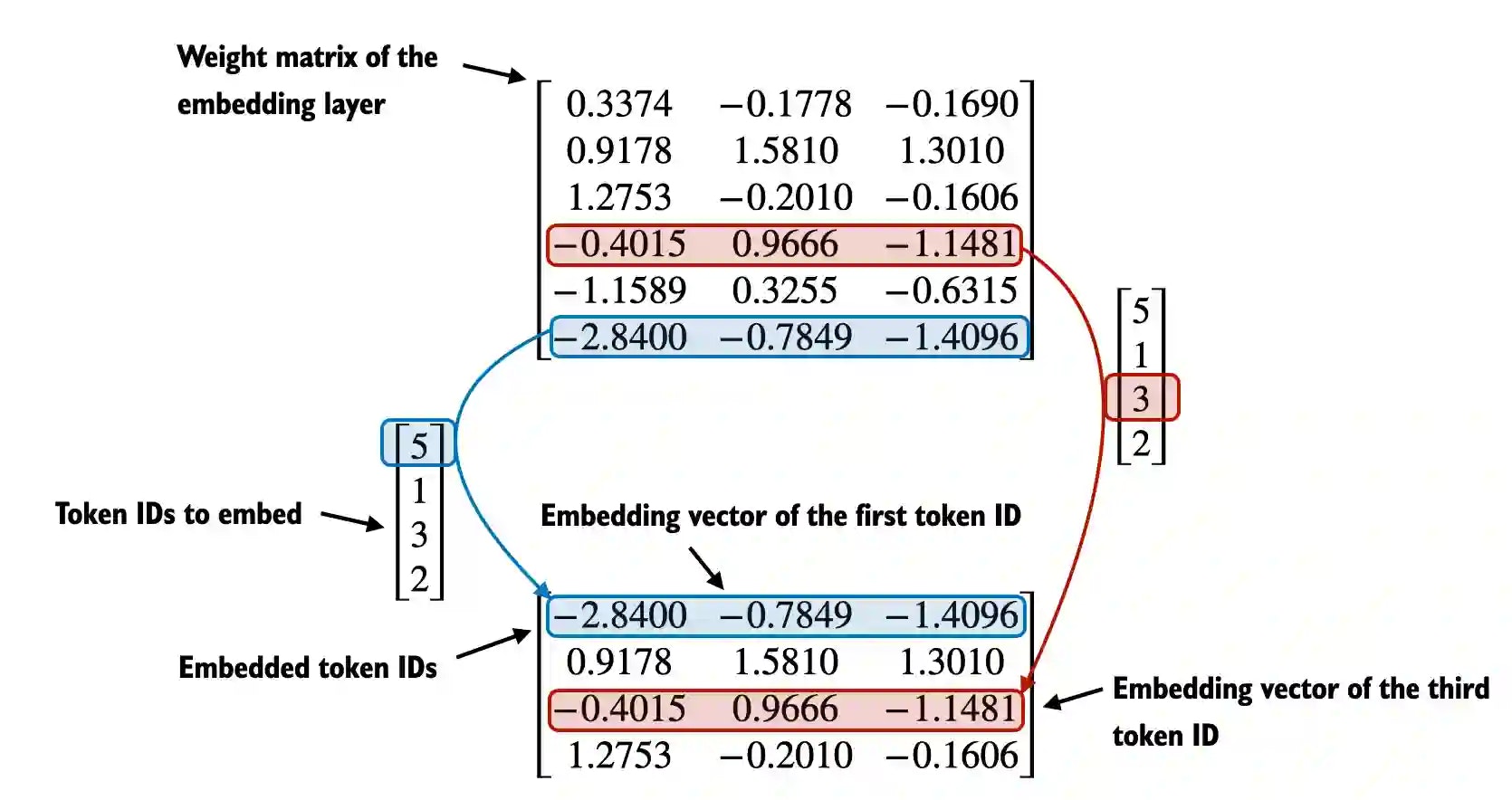 *図16: 埋め込み層の実装。埋め込み層は本質的に検索操作として機能し、IDを対応するベクトルに変換します。*
*図16: 埋め込み層の実装。埋め込み層は本質的に検索操作として機能し、IDを対応するベクトルに変換します。*
2.8 単語位置のエンコード
埋め込み層はトークンIDを同一のベクトル表現に変換しますが、トークンの位置情報も重要です。
 *図17: 位置情報なしの埋め込み。同じ単語は入力シーケンス内の位置に関係なく同じ埋め込みを持ちます。*
*図17: 位置情報なしの埋め込み。同じ単語は入力シーケンス内の位置に関係なく同じ埋め込みを持ちます。*
 *図18: 位置埋め込みの追加。トークン埋め込みと位置埋め込みを組み合わせて、位置情報を持つ入力を作成します。*
*図18: 位置埋め込みの追加。トークン埋め込みと位置埋め込みを組み合わせて、位置情報を持つ入力を作成します。*
# バイトペアエンコーダーの語彙サイズとGPT-2の埋め込みサイズ
vocab_size = 50257
output_dim = 256
# トークン埋め込み層の作成
token_embedding_layer = torch.nn.Embedding(vocab_size, output_dim)
# データサンプリング
max_length = 4
dataloader = create_dataloader_v1(
raw_text, batch_size=8, max_length=max_length,
stride=max_length, shuffle=False
)
data_iter = iter(dataloader)
inputs, targets = next(data_iter)
logger.info(f"トークンID:\n{inputs}")
logger.info(f"入力の形状:\n{inputs.shape}")
実行結果:
2025-03-28 12:34:57.370 | INFO | __main__:<module>:16 - トークンID:
tensor([[ 40, 367, 2885, 1464],
[ 1807, 3619, 402, 271],
[10899, 2138, 257, 7026],
[15632, 438, 2016, 257],
[ 922, 5891, 1576, 438],
[ 568, 340, 373, 645],
[ 1049, 5975, 284, 502],
[ 284, 3285, 326, 11]])
2025-03-28 12:34:57.371 | INFO | __main__:<module>:17 - 入力の形状:
torch.Size([8, 4])
# トークン埋め込みの計算
token_embeddings = token_embedding_layer(inputs)
logger.info(f"トークン埋め込みの形状: {token_embeddings.shape}")
実行結果:
2025-03-28 12:34:57.380 | INFO | __main__:<module>:4 - トークン埋め込みの形状: torch.Size([8, 4, 256])
# 位置埋め込み層の作成
context_length = max_length
pos_embedding_layer = torch.nn.Embedding(context_length, output_dim)
# 位置埋め込みの計算
pos_embeddings = pos_embedding_layer(torch.arange(max_length))
logger.info(f"位置埋め込みの形状: {pos_embeddings.shape}")
実行結果:
2025-03-28 12:34:57.385 | INFO | __main__:<module>:8 - 位置埋め込みの形状: torch.Size([4, 256])
# 入力埋め込みの作成(トークン埋め込み + 位置埋め込み)
input_embeddings = token_embeddings + pos_embeddings
logger.info(f"入力埋め込みの形状: {input_embeddings.shape}")
実行結果:
2025-03-28 12:34:57.386 | INFO | __main__:<module>:4 - 入力埋め込みの形状: torch.Size([8, 4, 256])
 *図19: 入力処理の全体像。テキストはトークン化され、IDに変換され、埋め込まれて、最終的にLLMへの入力として使用されます。*
*図19: 入力処理の全体像。テキストはトークン化され、IDに変換され、埋め込まれて、最終的にLLMへの入力として使用されます。*
まとめと要点
この章では、LLMの入力データを準備するための基本的なステップを学びました:
- テキストのトークン化 - テキストを小さな単位(トークン)に分割
- トークンIDへの変換 - トークンを整数IDに変換
- 特殊トークンの追加 - 未知の単語や文脈情報を表す特殊トークンの導入
- BPEトークナイザー - 未知語を部分語に分解する高度なトークン化手法
- データサンプリング - 次の単語予測のためのデータ準備
- トークン埋め込み - トークンIDを連続ベクトル表現に変換
- 位置埋め込み - トークンの位置情報の追加
これらのステップは、後続の章でLLMを構築する際の基礎となります。
📒ノートブック
リポジトリ