はじめに
最近,Dota2を始めましたが全く勝てません
ハードボットにボコボコにされます.
色々と調べても「死ぬな」くらいのことしか分らず苦戦しています.
データサイエンスでDota2強くなるかも説
そこで,データサイエンスの力を借りて,どのような状況なら勝っているか?や前回に比べてどのように振舞ったから勝てたのか?ということを数値化して分析していけば強くなるのでは!と考えました.本企画はその仮説を検証していく企画です.

前回までのあらすじ
環境構築編
Dota2の情報をPythonで取得できるような環境を作成し*1,データを取得+定期的に保存する機構を作りました*2.
データ解析編
実際にBotとの対戦をプロットしてみて客観的に解析してみたところ*3,ミディアムボットとの対戦をしてもハードボットとの対戦ではそこまで効果がない可能性が発見されました*4.
今回の概要
ハード試合データを解析してみたいと思います.
必要なもの
Dota2

Dota2解析環境
Dota2 解析プログラム
使用データセット
- bot戦(ハード):Jakiro【勝利】
- bot戦(ハード):Jakiro【勝利】
- bot戦(ハード):Jakiro【敗北】
- bot戦(ハード):Jakiro【勝利】
- bot戦(ハード):Jakiro【勝利】
- bot戦(ハード):Jakiro【勝利】
- bot戦(ハード):Jakiro【敗北】
- bot戦(ハード):Jakiro【敗北】
8試合のデータセットを使います.いずれもjakiroを使用しました.
ハードボットとの対戦について,僕的にはこいつが使いやすいかなと初心者ながら感じでいます.

Import package
import dota2gsi
import glob
import pandas as pd
import seaborn as sns
from matplotlib import pyplot as plt
import matplotlib as mpl
figure style
#sns.palplot(sns.color_palette("RdBu_r", 24))
#sns.set_palette("RdBu_r")
#sns.set(style='darkgrid')
#sns.set_style('whitegrid')
mpl.style.use('fivethirtyeight')
Read csv file
ログのフォルダを指定します.
target_dir = "logs"
ログのフォルダ内のcsvファイルを検索します.
#target_log_file_list = ["log_20220901-160140_BM_W.csv", "log_20220901-204148_BM_W.csv", "log_20220902-010822_BH_L.csv", "log_20220904-035245_BH_L.csv"]
target_log_file_list = glob.glob(target_dir + "/*.csv")
ファイルの一覧はこちらになります.
target_log_file_list
['logs\\log_20220904-161354_npc_dota_hero_jakiro_W.csv',
'logs\\log_20220905-092008_npc_dota_hero_jakiro_W.csv',
'logs\\log_20220905-131433_npc_dota_hero_jakiro_L.csv',
'logs\\log_20220905-141336_npc_dota_hero_jakiro_W.csv',
'logs\\log_20220905-151758_npc_dota_hero_jakiro_W.csv',
'logs\\log_20220905-171404_npc_dota_hero_jakiro_W.csv',
'logs\\log_20220906-093622_npc_dota_hero_jakiro_L.csv',
'logs\\log_20220906-102435_npc_dota_hero_jakiro_L.csv']
ファイルを順に読みだしてDataFrame型をlistに追加していきます.
df_list = []
for file_path in target_log_file_list:
df_list.append(pd.read_csv(file_path))
中身のDataFrameはこんな感じになります.
df_list[0].head(5)
| Unnamed: 0 | draft_activeteam | draft_activeteam_time_remaining | draft_dire_bonus_time | draft_pick | draft_radiant_bonus_time | draft_team#:home_team | hero_alive | hero_break | hero_buyback_cost | ... | provider_appid | provider_version | provider_timestamp | hero_level_try0 | hero_health_try0 | player_gold_try0 | player_camps_stacked_try0 | hero_level_try0_W | hero_level_W | player_gold_try | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | NaN | NaN | NaN | NaN | NaN | NaN | True | False | 253 | ... | 570 | 47 | 1662275633 | 1 | 740 | 5.0 | NaN | 1 | 1 | 5.0 |
| 1 | 0 | NaN | NaN | NaN | NaN | NaN | NaN | True | False | 253 | ... | 570 | 47 | 1662275635 | 1 | 740 | 5.0 | NaN | 1 | 1 | 5.0 |
| 2 | 0 | NaN | NaN | NaN | NaN | NaN | NaN | True | False | 253 | ... | 570 | 47 | 1662275635 | 1 | 740 | 5.0 | NaN | 1 | 1 | 5.0 |
| 3 | 0 | NaN | NaN | NaN | NaN | NaN | NaN | True | False | 253 | ... | 570 | 47 | 1662275635 | 1 | 740 | 5.0 | NaN | 1 | 1 | 5.0 |
| 4 | 0 | NaN | NaN | NaN | NaN | NaN | NaN | True | False | 253 | ... | 570 | 47 | 1662275635 | 1 | 740 | 5.0 | NaN | 1 | 1 | 5.0 |
5 rows × 84 columns
DataFrameの列名の一覧はこちら
df_list[0].columns
Index(['Unnamed: 0', 'draft_activeteam', 'draft_activeteam_time_remaining',
'draft_dire_bonus_time', 'draft_pick', 'draft_radiant_bonus_time',
'draft_team#:home_team', 'hero_alive', 'hero_break',
'hero_buyback_cost', 'hero_buyback_cooldown', 'hero_disarmed',
'hero_has_debuff', 'hero_health', 'hero_health_percent', 'hero_hexed',
'hero_id', 'hero_level', 'hero_magicimmune', 'hero_mana',
'hero_mana_percent', 'hero_max_health', 'hero_max_mana', 'hero_muted',
'hero_name', 'hero_respawn_seconds', 'hero_selected_unit',
'hero_silenced', 'hero_stunned', 'hero_talent_1', 'hero_talent_2',
'hero_talent_3', 'hero_talent_4', 'hero_talent_5', 'hero_talent_6',
'hero_talent_7', 'hero_talent_8', 'hero_xpos', 'hero_ypos',
'map_clock_time', 'map_daytime', 'map_dire_ward_purchase_cooldown',
'map_game_state', 'map_game_time', 'map_name', 'map_matchid',
'map_radiant_ward_purchase_cooldown', 'map_nightstalker_night',
'map_roshan_state', 'map_roshan_state_end_seconds', 'map_win_team',
'map_customgamename', 'player_assists', 'player_camps_stacked',
'player_deaths', 'player_denies', 'player_gold', 'player_gold_reliable',
'player_gold_unreliable', 'player_gpm', 'player_hero_damage',
'player_kill_list:victimid_#', 'player_kill_streak', 'player_kills',
'player_last_hits', 'player_net_worth', 'player_pro_name',
'player_runes_activated', 'player_support_gold_spent',
'player_wards_destroyed', 'player_wards_placed',
'player_wards_purchased', 'player_xpm', 'provider_name',
'provider_appid', 'provider_version', 'provider_timestamp'],
dtype='object')
Plot level section
Extract level data
ここから対象の列だけ抽出してDataFrameに新たにぶち込んでいきます.
df_ex_data_list = []
for i, df in enumerate(df_list):
target_name = 'hero_level'
result_flag = target_log_file_list[i].split(".csv")[0].split("_")[-1]
plot_name = '{}_try{}_{}'.format(target_name, i, result_flag)
#plot_name = '{}_{}'.format(target_name, result_flag)
df[plot_name] = df[target_name]
df_ex_data_list.append(df[plot_name])
df_ex_merge = pd.concat(df_ex_data_list, axis=1)
レベルの列だけを抽出したDataFrameがこちらになります.
df_ex_merge
| hero_level_try0_W | hero_level_try1_W | hero_level_try2_L | hero_level_try3_W | hero_level_try4_W | hero_level_try5_W | hero_level_try6_L | hero_level_try7_L | |
|---|---|---|---|---|---|---|---|---|
| 0 | 1.0 | NaN | NaN | NaN | NaN | NaN | NaN | 1.0 |
| 1 | 1.0 | NaN | NaN | NaN | NaN | NaN | NaN | 1.0 |
| 2 | 1.0 | NaN | NaN | NaN | NaN | NaN | NaN | 1.0 |
| 3 | 1.0 | NaN | NaN | NaN | NaN | NaN | NaN | 1.0 |
| 4 | 1.0 | NaN | NaN | NaN | NaN | NaN | NaN | 1.0 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 33798 | NaN | NaN | NaN | NaN | 23.0 | NaN | NaN | NaN |
| 33799 | NaN | NaN | NaN | NaN | 23.0 | NaN | NaN | NaN |
| 33800 | NaN | NaN | NaN | NaN | 23.0 | NaN | NaN | NaN |
| 33801 | NaN | NaN | NaN | NaN | 23.0 | NaN | NaN | NaN |
| 33802 | NaN | NaN | NaN | NaN | 23.0 | NaN | NaN | NaN |
33803 rows × 8 columns
Plot level data
レベルの遷移をプロットしたグラフがこちらです.
plt.figure(figsize=(20,8))
sns.lineplot(data=df_ex_merge, lw=2)
#sns.lineplot(data=df_data, x='clock_time', y='level', lw=2)
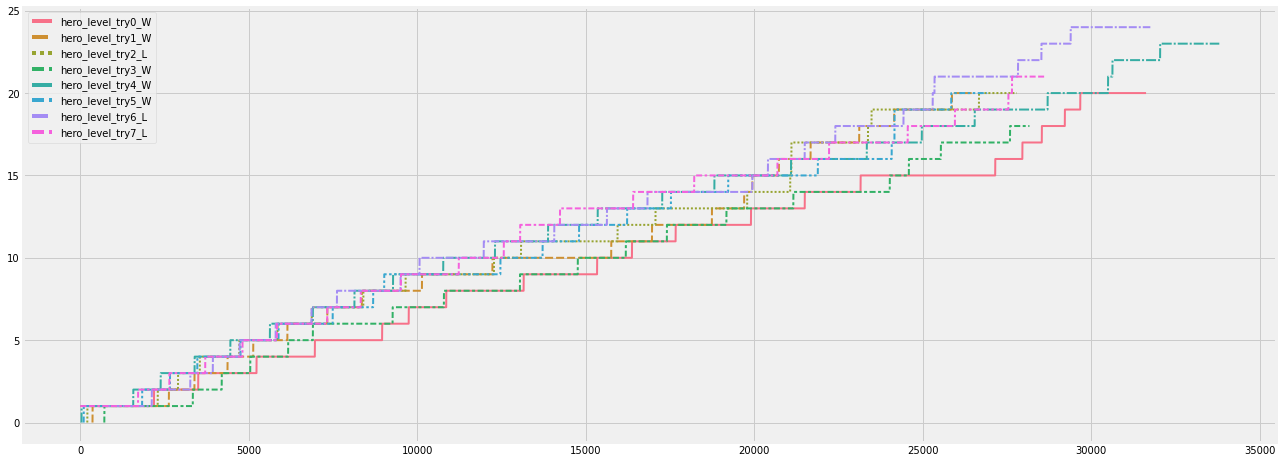
Mean data
make mean data
「勝ち」,「負け」のグループに分けて平均を算出していきます.
def extract_columns_data(df_ex_merge, target_name):
columns_list = [i for i in df_ex_merge.columns if(target_name in i)]
df_ex_merge[target_name] = df_ex_merge[columns_list].mean(axis=1, skipna=True)
#df_ex_merge[target_name] = df_ex_merge.mean(axis=1)
return df_ex_merge
df_mean_merge = extract_columns_data(df_ex_merge, "_W")
df_mean_merge = extract_columns_data(df_mean_merge, "_L")
df_mean_merge
| player_gold_try0 | player_gold_try1 | player_gold_try2 | player_gold_try3 | player_gold_try4 | player_gold_try5 | player_gold_try6 | player_gold_try7 | _W | _L | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 5.0 | 600.0 | NaN | NaN | 5.0 | NaN | NaN | 5.0 | NaN | NaN |
| 1 | 5.0 | 600.0 | 600.0 | 600.0 | 5.0 | NaN | 600.0 | 5.0 | NaN | NaN |
| 2 | 5.0 | 600.0 | 600.0 | 600.0 | 5.0 | 600.0 | 600.0 | 5.0 | NaN | NaN |
| 3 | 5.0 | 600.0 | 600.0 | 600.0 | 5.0 | 600.0 | 600.0 | 5.0 | NaN | NaN |
| 4 | 5.0 | 600.0 | 600.0 | 600.0 | 5.0 | 600.0 | 600.0 | 5.0 | NaN | NaN |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 33798 | NaN | NaN | NaN | NaN | 4652.0 | NaN | NaN | NaN | NaN | NaN |
| 33799 | NaN | NaN | NaN | NaN | 4652.0 | NaN | NaN | NaN | NaN | NaN |
| 33800 | NaN | NaN | NaN | NaN | 4652.0 | NaN | NaN | NaN | NaN | NaN |
| 33801 | NaN | NaN | NaN | NaN | 4652.0 | NaN | NaN | NaN | NaN | NaN |
| 33802 | NaN | NaN | NaN | NaN | 4685.0 | NaN | NaN | NaN | NaN | NaN |
33803 rows × 10 columns
「勝ち」,「負け」を抽出して平均を算出したDataFrameがこちらです.
df_mean_merge2 = df_mean_merge[["_W", "_L"]]
df_mean_merge2
| _W | _L | |
|---|---|---|
| 0 | 1.0 | 1.0 |
| 1 | 1.0 | 1.0 |
| 2 | 1.0 | 1.0 |
| 3 | 1.0 | 1.0 |
| 4 | 1.0 | 1.0 |
| ... | ... | ... |
| 33798 | 23.0 | NaN |
| 33799 | 23.0 | NaN |
| 33800 | 23.0 | NaN |
| 33801 | 23.0 | NaN |
| 33802 | 23.0 | NaN |
33803 rows × 2 columns
各試合のレベル遷移と勝ったときの平均,負けたときの平均をプロットしたデータがこちらです.
plt.figure(figsize=(20,12))
ax = sns.lineplot(data=df_mean_merge2, lw=4)
ax = sns.lineplot(data=df_ex_merge, lw=2, ax=ax)
plt.legend(labels=["Win","Lose"])
#sns.lineplot(data=df_data, x='clock_time', y='level', lw=2)

Plot health section
Extract health data
ここから体力の列だけ抽出してDataFrameに新たにぶち込んでいきます.
df_ex_data_list = []
for i, df in enumerate(df_list):
target_name = 'hero_health'
plot_name = '{}_try{}'.format(target_name, i)
df[plot_name] = df[target_name]
df_ex_data_list.append(df[plot_name])
df_ex_merge = pd.concat(df_ex_data_list, axis=1)
Plot health data
plt.figure(figsize=(20,5))
sns.lineplot(data=df_ex_merge, lw=2)

Plot gold data
Extract gold data
ここからゴールドの列だけ抽出してDataFrameに新たにぶち込んでいきます.
df_ex_data_list = []
for i, df in enumerate(df_list):
target_name = 'player_gold'
result_flag = target_log_file_list[i].split(".csv")[0].split("_")[-1]
plot_name = '{}_try{}_r_{}'.format(target_name, i, result_flag)
#plot_name = '{}_try'.format(target_name, i)
df[plot_name] = df[target_name]
df_ex_data_list.append(df[plot_name])
df_ex_merge = pd.concat(df_ex_data_list, axis=1)
ゴールドの遷移から,稼いだ金額の積算を算出します.
df_ex_merge2 = df_ex_merge.diff().fillna(0)
df_ex_merge2[df_ex_merge2<0] = 0
df_ex_merge2 = df_ex_merge2.cumsum()
df_ex_merge2
積算の結果がこちら
| player_gold_try0_r_W | player_gold_try1_r_W | player_gold_try2_r_L | player_gold_try3_r_W | player_gold_try4_r_W | player_gold_try5_r_W | player_gold_try6_r_L | player_gold_try7_r_L | |
|---|---|---|---|---|---|---|---|---|
| 0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 1 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 2 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 3 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 4 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 33798 | 17763.0 | 14212.0 | 14526.0 | 14759.0 | 18162.0 | 14715.0 | 21314.0 | 19372.0 |
| 33799 | 17763.0 | 14212.0 | 14526.0 | 14759.0 | 18162.0 | 14715.0 | 21314.0 | 19372.0 |
| 33800 | 17763.0 | 14212.0 | 14526.0 | 14759.0 | 18162.0 | 14715.0 | 21314.0 | 19372.0 |
| 33801 | 17763.0 | 14212.0 | 14526.0 | 14759.0 | 18162.0 | 14715.0 | 21314.0 | 19372.0 |
| 33802 | 17763.0 | 14212.0 | 14526.0 | 14759.0 | 18195.0 | 14715.0 | 21314.0 | 19372.0 |
33803 rows × 8 columns
勝,負の列をそれぞれ平均します.
df_mean_merge = extract_columns_data(df_ex_merge2, "r_W")
df_mean_merge = extract_columns_data(df_mean_merge, "r_L")
df_mean_merge
| player_gold_try0_r_W | player_gold_try1_r_W | player_gold_try2_r_L | player_gold_try3_r_W | player_gold_try4_r_W | player_gold_try5_r_W | player_gold_try6_r_L | player_gold_try7_r_L | r_W | r_L | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 1 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 2 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 3 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 4 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 33798 | 17763.0 | 14212.0 | 14526.0 | 14759.0 | 18162.0 | 14715.0 | 21314.0 | 19372.0 | 15922.2 | 18404.0 |
| 33799 | 17763.0 | 14212.0 | 14526.0 | 14759.0 | 18162.0 | 14715.0 | 21314.0 | 19372.0 | 15922.2 | 18404.0 |
| 33800 | 17763.0 | 14212.0 | 14526.0 | 14759.0 | 18162.0 | 14715.0 | 21314.0 | 19372.0 | 15922.2 | 18404.0 |
| 33801 | 17763.0 | 14212.0 | 14526.0 | 14759.0 | 18162.0 | 14715.0 | 21314.0 | 19372.0 | 15922.2 | 18404.0 |
| 33802 | 17763.0 | 14212.0 | 14526.0 | 14759.0 | 18195.0 | 14715.0 | 21314.0 | 19372.0 | 15928.8 | 18404.0 |
33803 rows × 10 columns
勝,負の列だけを抽出します.
df_mean_merge2 = df_mean_merge[["r_W", "r_L"]]
df_mean_merge2
| r_W | r_L | |
|---|---|---|
| 0 | 0.0 | 0.0 |
| 1 | 0.0 | 0.0 |
| 2 | 0.0 | 0.0 |
| 3 | 0.0 | 0.0 |
| 4 | 0.0 | 0.0 |
| ... | ... | ... |
| 33798 | 15922.2 | 18404.0 |
| 33799 | 15922.2 | 18404.0 |
| 33800 | 15922.2 | 18404.0 |
| 33801 | 15922.2 | 18404.0 |
| 33802 | 15928.8 | 18404.0 |
33803 rows × 2 columns
x軸にとるindexを作成します.
df_mean_merge3 = df_mean_merge2.reset_index()
df_mean_merge2
| r_W | r_L | |
|---|---|---|
| 0 | 0.0 | 0.0 |
| 1 | 0.0 | 0.0 |
| 2 | 0.0 | 0.0 |
| 3 | 0.0 | 0.0 |
| 4 | 0.0 | 0.0 |
| ... | ... | ... |
| 33798 | 15922.2 | 18404.0 |
| 33799 | 15922.2 | 18404.0 |
| 33800 | 15922.2 | 18404.0 |
| 33801 | 15922.2 | 18404.0 |
| 33802 | 15928.8 | 18404.0 |
33803 rows × 2 columns
df_mean_merge2.columns
Index(['r_W', 'r_L'], dtype='object')
Plot gold data
ゴールドの積算をプロットしたものです.
plt.figure(figsize=(20,10))
sns.lineplot(data=df_ex_merge2, lw=2)

平均もプロットしたものがこちらです.
plt.figure(figsize=(20,20))
#sns.lineplot(data=df_mean_merge2, x="index", y="player_gold_try")
ax = sns.lineplot(data=df_mean_merge2, lw=4)
sns.lineplot(data=df_ex_merge2, lw=2, ax=ax)
#plt.legend(labels=["Win","Lose"])

考察
8試合のデータを勝,負に分類して考察していこうと思います.
レベルとゴールドの遷移をプロットしたところ,いずれも勝利したときの平均のグラフの方が敗北したときの平均のグラフより下回っていました.これより,レベルやゴールドを順調に稼いだからといって勝てる訳ではないと考えられます.
これは,味方の振る舞いの影響が想定よりも大きく,自分のレベルやゴールドの稼ぎがそこまで影響していないということになります.
(とても悲しい....)
プログラム
コードはこちらです.
おわりに
今回はハードボットとの対戦ログを解析してみた結果.
勝利している方が敗北している試合よりもレベル,ゴールドを多く稼いでいると思っていたのですが,その仮説とは相反した結果が得られました.敗北した方が勝利している方より稼いでいる結果になってました.
これは,味方の振る舞いの影響が想定よりも大きく,自分のレベルやゴールドの稼ぎがそこまで影響していないということになりました.
とても悲しい結果ですね....
参考サイト
- *1:データサイエンスでDota2強くなるかも説(1)~環境設定~
- *2:データサイエンスでDota2強くなるかも説(2)~ビッグデータ取得&定期保存~
- *3:データサイエンスでDota2強くなるかも説(3)~試合データをプロットしてみた~
- *4:データサイエンスでDota2強くなるかも説(4)~ミディアムとハード試合データをプロットしてみたら驚愕の事実が~
最新情報
速報はTwitterやブログにて