Redis Cluster をマルチゾーンリージョン(MZR)上のKubernetesクラスタで構築した場合の考慮点のメモです。
Redisは、memcachedに代わってオンメモリのキャッシュとして利用されるだけでなく、永続ボリュームにデータを保存することもできる。
Kubernetesを応用したアプリケーションのマイクロサービス化やウェブアプリケーションのモダナイズにおいて、軽量で高速な Redis は重要な構成パーツの一つと考えられる。さらに、以下に引用する「The Twelve-Factor Apps」の VI.プロセスでは、セッション状態のデータはRedisのようなデータストアに保存するべきとされている。このことからも、Kubernetesクラスタで、Redisを高い可用性、且つ、性能面で有利に利用するノウハウが必要である。
The Twelve-Factor Apps https://12factor.net/ja/processes
VI. プロセス
アプリケーションを1つもしくは複数のステートレスなプロセスとして実行する
抜粋
Webシステムの中には、“スティッキーセッション”に頼るものがある – これはユーザーのセッションデータを
アプリケーションプロセスのメモリにキャッシュし、同じ訪問者からの将来のリクエストが同じプロセスに送ら
れることを期待するものである。スティッキーセッションはTwelve-Factorに違反しており、決して使ったり
頼ったりしてはならない。セッション状態のデータは、有効期限を持つデータストア(例:Memcached や
Redis)に格納すべきである。
信頼性と性能では「Redisクラスタ」または「Redisとセンチネル」を利用することが一般的である。そして、クラウドでは一つの地域(リージョン)の中に、複数データセンターを配置することでゾーンを形成して、高可用性を確保することが一般的である。この方式は、ゾーンを完全に独立したデータセンター内に配置することで、データセンターレベルの障害に対応できるだけでなく、広域災害においても一定の効果が期待される。一つのデータセンターが重大障害などで長期に渡り利用できなくなったとしても、残ったデータセンターで業務の継続が期待できる。
本メモでは、Redisクラスタについて、マルチゾーン(複数データセンター)に配置した場合の課題と実装方法について検証する。
ゾーンと Redis Cluster の配置の考え方
Redisはキー・バリュー・ストアのデータストアーで、キーを指定してデータの登録と取得ができる。そして、Redisクラスタでは、複数のハッシュ・スロットを有して、キーのハッシュによって分散してデータを格納する。例えば、最小構成では3つのRedisマスターを使用する。そして、データの保全性を確保するために Redisマスターのデータのレプリカの保管を、Redisスレーブが受け持つ。
もしも、3つのRedisマスターのうちの一つが、なんらかの障害によって失われた場合は、この構造により、スレーブがマスターに昇格して、Redisクラスタの機能を継続する。一方、Redisのマスターが同時に2つ以上停止した場合は、クラスタの機能を停止して、読出しと書込みの動作を停止する。
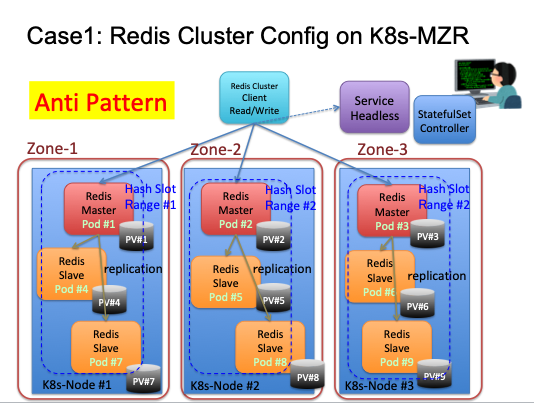
構成ケース1 ゾーンにマスター分散して配置、同一ゾーンにスレーブも配置する
Redisマスターをゾーンに分散して配置して、スレーブを各ゾーン内に配置する構成例である。このような構成では、どれか1つのゾーンが停止した場合、あるデータ範囲、すなわち、スロットの一つのデータが失われることになる。結果として、Redisクラスタは停止状態におち、データの書込みと読出しは不能な状態となる。そのため、構成1はRedisクラスタを構築する場合、避けるべき構成であり、アンチパターンと言える。
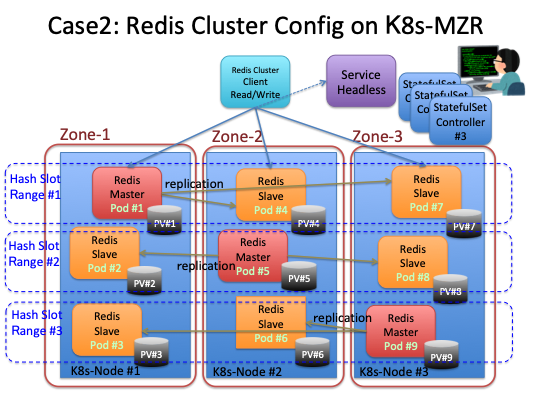
構成ケース2 ゾーンにマスター分散して配置、他のゾーンにスレーブを配置する
この構成ケースは、大切なデータを失うことを防止できる。Redisクラスタはデータを複数のハッシュスロットに分散して格納する。それぞれのスロット単位にマスターを立てることが必要であり、このケースでは、Zone-1〜3にマスターを分散配置している。そして各スロット範囲のスレーブは、Redisマスターのデータのレプリカを、他のゾーン上に保持する。この構成では、どれかゾーンの一つが停止しても、サービスを継続できる。そして、3つのゾーンのうち、2つまでが壊滅状態になっても、データは読み書き可能な状態に復旧可能である。
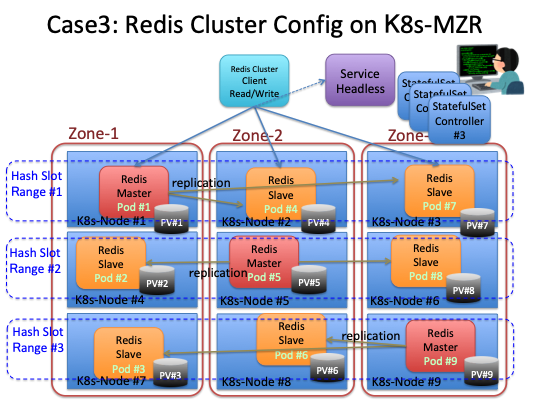
構成ケース3 ゾーンにマスター分散して配置、RedisノードごとにK8sノードを割り当てる。
前述の構成では、一つのK8sノード上に複数のRedisノードを稼働させる構成であった。これに対して、構成ケース3では、RedisノードとK8sノードを1対1で稼働させる。 レプリケーションの方向は構成ケース2と同じクロスゾーンで実施する。 このケースでは、構成ケース2の特徴に加えて、K8sノード障害の影響を軽減することができる。ただし、K8sノードを増やすことは、クラウドの利用料金が上がるため必要性とコストのバランスの考慮が必要となる。
ここまでに挙げた構成ケースの中で、コストとデータ保全性のバランスが良いのは構成ケース2なので、これについて、実際に検証しながら確認する。
マルチゾーンでのステートフルセットの書き方
Redisクラスタは、K8sのステートフルセット・コントローラーを用いて構築すると、都合が良い。それは、ポッドを連番で管理して、順序性を維持した起動と停止、そして、ポッド数の増加と縮小を実施してくれ、永続ボリュームをセットでデプロイしてくれるためだ。
しかし、ステートフルセット・コントローラーでマルチゾーン環境で利用する場合、IKSでは厄介な問題に遭遇する。これは、ステートフルセットが起動ポッドと、永続ボリュームのゾーンが、必ずしも一致しない。例えば、ポッドは、指定通りゾーン1に起動するが、永続ボリュームはゾーン2でプロビジョニングされるといった問題である。
この問題に対して、ステートフルセットのマニフェストに、次のラベルと追加することで、問題を回避できる。なぜ「region」と「zone」のラベルを追加することで、永続ボリュームのプロビジョニング先を制御できるのかは不明だ。おそらく、ストレージクラスに定義されているプロビジョナーが、ラベルを参照していると思われる。 このマニフェストのコードの全体は、GitHub https://github.com/takara9/redis-cluster/tree/master/iks-mzr-tok-multi-pod にある。
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: redis-cluster-1
labels:
app: redis-cluster
spec:
serviceName: redis-cluster
replicas: 3
selector:
matchLabels:
app: redis-cluster
region: jp-tok ## これら二つのラベルを追加する
zone: tok05 ## zone値は以下のnodeSelectorの値と一致しなくてはならない。
template:
metadata:
labels:
app: redis-cluster
antiaffinity: redis-node
region: jp-tok ## こちらにも、同じキーと値のセットのラベルを書いておく。
zone: tok05 ##
spec:
# ノードセレクターで、ポッドがデプロイされるゾーンを指定する。
# しかし、これだけでは永続ボリュームの配置先は同一リージョン内で不定となる。
nodeSelector:
failure-domain.beta.kubernetes.io/zone: tok05
<以下省略>
マルチゾーン + マルチノード 構成の作り方
マルチゾーンで、Redisクラスタを起動するためのマニフェストは、GitHubの次のURLへ置いてあるので、マニフェストを確認して欲しい。
https://github.com/takara9/redis-cluster/tree/master/iks-mzr-tok-multi-pod
コンフィグマップとサービスから適用する。
$ kubectl apply -f redis-configmap.yml
configmap/redis-cluster created
$ kubectl apply -f redis-service.yml
service/redis-cluster created
最初に2つのゾーンにステートフルセットを作成する。
$ kubectl apply -f redis-cluster-mzr-1m.yml
statefulset.apps/redis-cluster-1 created
$ kubectl apply -f redis-cluster-mzr-2m.yml
statefulset.apps/redis-cluster-2 created
imac:iks-mzr-tok maho$ kubectl get po
NAME READY STATUS RESTARTS AGE
redis-cluster-1-0 1/1 Running 0 28m
redis-cluster-1-1 1/1 Running 0 26m
redis-cluster-1-2 1/1 Running 0 24m
redis-cluster-2-0 1/1 Running 0 28m
redis-cluster-2-1 1/1 Running 0 26m
redis-cluster-2-2 1/1 Running 0 24m
Redisクラスタのマスターとスレーブの作成
redis-cluster-1-0 で Redisの管理コマンド redis-cli を実行して、最小セットのクラスタを作成する。
Redisマスターとスレーブは、Redisが自動的に決定する。この際に自動的に一つのゾーンにマスターを集約してくれる。
もし、正しくゾーンをアサインできなければ、クラスタを起動したあと、手動でフェイルオーバーして、一つのゾーンに集約する。
$ kubectl exec -it redis-cluster-1-0 -- redis-cli --cluster create --cluster-replicas 1 $(kubectl get pods -l 'app=redis-cluster' -o jsonpath='{range.items[*]}{.status.podIP}:6379 ')
>>> Performing hash slots allocation on 6 nodes...
Master[0] -> Slots 0 - 5460
Master[1] -> Slots 5461 - 10922
Master[2] -> Slots 10923 - 16383
Adding replica 172.30.155.83:6379 to 172.30.46.203:6379
Adding replica 172.30.155.84:6379 to 172.30.46.204:6379
Adding replica 172.30.155.82:6379 to 172.30.46.205:6379
< 中略 >
..
>>> Performing Cluster Check (using node 172.30.46.203:6379)
M: 7e9ab7262b2c48211afdce8e95c511a0296d0a1b 172.30.46.203:6379
slots:[0-5460] (5461 slots) master
1 additional replica(s)
M: 47bb522b281cc046346fda7d29727d0f54f9e766 172.30.46.204:6379
slots:[5461-10922] (5462 slots) master
1 additional replica(s)
S: cf7ef722d2b5248eb22f8058f3cba9c06582c3fc 172.30.155.82:6379
slots: (0 slots) slave
replicates 1f27ff665a44590151ea356a7879cf391ab54636
M: 1f27ff665a44590151ea356a7879cf391ab54636 172.30.46.205:6379
slots:[10923-16383] (5461 slots) master
1 additional replica(s)
S: 430c82e5ba4173661c3776da7cda2443c5e4de81 172.30.155.84:6379
slots: (0 slots) slave
replicates 47bb522b281cc046346fda7d29727d0f54f9e766
S: 9265e13e2d2218f1649a4f10ef4de04dd6ca2147 172.30.155.83:6379
slots: (0 slots) slave
replicates 7e9ab7262b2c48211afdce8e95c511a0296d0a1b
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
Redisクラスタの最小セットができたら、ステートフルセットの3番目のゾーンを追加する。
$ kubectl apply -f redis-cluster-mzr-3a.yml
statefulset.apps/redis-cluster-3 configured
imac:iks-mzr-tok maho$ kubectl get po
NAME READY STATUS RESTARTS AGE
redis-cluster-1-0 1/1 Running 0 32m
redis-cluster-1-1 1/1 Running 0 30m
redis-cluster-1-2 1/1 Running 0 28m
redis-cluster-2-0 1/1 Running 0 32m
redis-cluster-2-1 1/1 Running 0 30m
redis-cluster-2-2 1/1 Running 0 28m
redis-cluster-3-0 1/1 Running 0 3m52s
redis-cluster-3-1 1/1 Running 0 3m30s
redis-cluster-3-2 1/1 Running 0 3m12s
3番目のゾーンのポッドに、各スロットのRedisマスターのIDを指定して、Redisスレーブを設定する。
redis-cluster-3-0 を redis-cluster-1-0 のスレーブにつける
$ kubectl exec redis-cluster-1-0 -- redis-cli --cluster add-node --cluster-slave --cluster-master-id 7e9ab7262b2c48211afdce8e95c511a0296d0a1b $(kubectl get pod redis-cluster-3-0 -o jsonpath='{.status.podIP}'):6379 $(kubectl get pod redis-cluster-1-0 -o jsonpath='{.status.podIP}'):6379
redis-cluster-3-1 を redis-cluster-1-1 のスレーブにつける
$ kubectl exec redis-cluster-1-0 -- redis-cli --cluster add-node --cluster-slave --cluster-master-id 47bb522b281cc046346fda7d29727d0f54f9e766 $(kubectl get pod redis-cluster-3-1 -o jsonpath='{.status.podIP}'):6379 $(kubectl get pod redis-cluster-1-0 -o jsonpath='{.status.podIP}'):6379
redis-cluster-3-2 を redis-cluster-1-2 のスレーブにつける
$ kubectl exec redis-cluster-1-0 -- redis-cli --cluster add-node --cluster-slave --cluster-master-id 1f27ff665a44590151ea356a7879cf391ab54636 $(kubectl get pod redis-cluster-3-2 -o jsonpath='{.status.podIP}'):6379 $(kubectl get pod redis-cluster-1-0 -o jsonpath='{.status.podIP}'):6379
Redisクラスター 3ゾーン構成
以上の操作で、Redisマスター x3(スロット)、スレーブ(レプリカ)x3(スロット) x2(ゾーン)のセットアップが完了しました。
$ kubectl exec redis-cluster-1-0 -- redis-cli -c cluster nodes (実際は順不同、見やすさのため並べかえ済み)
7e9ab7262b2c48211afdce8e95c511a0296d0a1b 172.30.46.203:6379@16379 myself,master - 0 1564886560000 1 connected 0-5460
47bb522b281cc046346fda7d29727d0f54f9e766 172.30.46.204:6379@16379 master - 0 1564886563000 2 connected 5461-10922
1f27ff665a44590151ea356a7879cf391ab54636 172.30.46.205:6379@16379 master - 0 1564886565207 3 connected 10923-16383
cf7ef722d2b5248eb22f8058f3cba9c06582c3fc 172.30.155.82:6379@16379 slave 1f27ff665a44590151ea356a7879cf391ab54636 0 1564886566212 4 connected
9265e13e2d2218f1649a4f10ef4de04dd6ca2147 172.30.155.83:6379@16379 slave 7e9ab7262b2c48211afdce8e95c511a0296d0a1b 0 1564886564206 5 connected
430c82e5ba4173661c3776da7cda2443c5e4de81 172.30.155.84:6379@16379 slave 47bb522b281cc046346fda7d29727d0f54f9e766 0 1564886563000 6 connected
8185dfc3e13fffe360235e04c32b822fccdafffa 172.30.190.208:6379@16379 slave 7e9ab7262b2c48211afdce8e95c511a0296d0a1b 0 1564886562000 1 connected
abc6d8ca61162829429bac9fcc8f4d6d9ef79438 172.30.190.209:6379@16379 slave 47bb522b281cc046346fda7d29727d0f54f9e766 0 1564886563217 2 connected
eccce1ad7408e85a8f941d0e1875750503844b58 172.30.190.210:6379@16379 slave 1f27ff665a44590151ea356a7879cf391ab54636 0 1564886564000 3 connected
この状態では、ゾーン1のノードに、Redisマスターノードが集まっている状態である。 このママの状態で利用した場合のケースを知るために、このままの状態で、模擬障害テストまでを実施することにする。
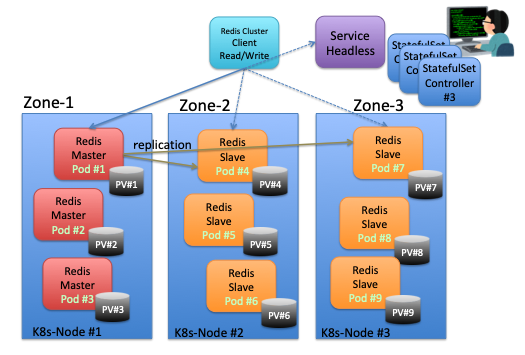
Redisクライアントからのアクセス
redis-clusterのステートフルセットは、各ゾーンごとにデプロイして、3個のステートフルセットを作成した。
一方、redis-clusterのサービスは、3つのゾーンの9つのポッドのIPアドレスを返すように、ラベルとセレクターを設定してある。
詳しくは、GitHubのマニフェストを参照のこと。
$ kubectl get po -l redis-cluster
No resources found.
imac:iks-mzr-tok-multi-pod maho$ kubectl get po -o wide -l app=redis-cluster
NAME READY STATUS RESTARTS AGE IP NODE
redis-cluster-1-0 1/1 Running 0 3h57m 172.30.46.203 10.193.10.58
redis-cluster-1-1 1/1 Running 0 3h57m 172.30.46.204 10.193.10.58
redis-cluster-1-2 1/1 Running 0 3h56m 172.30.46.205 10.193.10.58
redis-cluster-2-0 1/1 Running 0 3h52m 172.30.155.82 10.192.57.161
redis-cluster-2-1 1/1 Running 0 3h51m 172.30.155.83 10.192.57.161
redis-cluster-2-2 1/1 Running 0 3h51m 172.30.155.84 10.192.57.161
redis-cluster-3-0 1/1 Running 0 4h23m 172.30.190.208 10.212.5.223
redis-cluster-3-1 1/1 Running 0 4h20m 172.30.190.209 10.212.5.223
redis-cluster-3-2 1/1 Running 0 4h18m 172.30.190.210 10.212.5.223
$ kubectl get svc redis-cluster
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
redis-cluster ClusterIP None <none> 6379/TCP,16379/TCP 22h
$ kubectl get ep redis-cluster
NAME ENDPOINTS AGE
redis-cluster 172.30.155.82:6379,172.30.155.33:6379,172.30.155.84:6379 + 15 more... 22h
$ kubectl describe ep redis-cluster
Name: redis-cluster
Namespace: default
Labels: app=redis-cluster
Annotations: <none>
Subsets:
Addresses: 172.30.155.82,172.30.155.83,172.30.155.84,172.30.190.208,172.30.190.209,172.30.190.210,172.30.46.203,172.30.46.204,172.30.46.205
NotReadyAddresses: <none>
Ports:
Name Port Protocol
---- ---- --------
client 6379 TCP
gossip 16379 TCP
Events: <none>
コンテナイメージのredisには、redis-cli が入っているので、対話型で起動して、Redisクラスタのサービスへ接続する。
書き込みと読み出しをテストしてみる。 サービス名でアクセスして、返されたポッドのIPアドレスに問いかけて、別のハッシュスロットであれば、リダイレクトのメッセージが帰る。リダイレクト先でデータの書込み、または、読出しが実施される。
$ kubectl run redis-cli --image redis --restart=Never
$ kubectl exec -it redis-cli -- bash
root@redis-cluster-1-0:/data# redis-cli -c -h redis-cluster -p 6379
redis-cluster:6379> set key-a 1001
-> Redirected to slot [6672] located at 172.30.46.204:6379
OK
172.30.46.204:6379> set key-b 2042
OK
172.30.46.204:6379> set key-c 3408
-> Redirected to slot [14930] located at 172.30.46.205:6379
OK
172.30.46.205:6379> get key-a
-> Redirected to slot [6672] located at 172.30.46.204:6379
"1001"
172.30.46.204:6379> get key-b
"2042"
172.30.46.204:6379> get key-c
-> Redirected to slot [14930] located at 172.30.46.205:6379
"3408"
実際のアプリケーションでは、プログラム言語のライブラリで上記の動作を実施する。
模擬ゾーン障害からの復旧 (マスターが特定のゾーンに集中したケース)
Redisクラスタを再作成しているので、ポッドのIPアドレスが異っているので、注意ください。 ゾーンすなわち、データセンターの一つで、障害が発生して、コミュニケーションが不能になった場合の振る舞いについて確認する。開始時点でRedisマスターが存在するゾーンのポッドを、すべて削除するという模擬ゾーン障害を発生させる。つまり、以下の例では、redis-cluster-2-* のポッドがすべて消えたという状態になる。
初期状態、redis-cluster-2-* にマスターが存在する状態
$ kubectl get po -o wide
NAME READY STATUS RESTARTS AGE IP NODE
redis-cluster-1-0 1/1 Running 0 112s 172.30.46.227 10.193.10.58
redis-cluster-1-1 1/1 Running 0 92s 172.30.46.228 10.193.10.58
redis-cluster-1-2 1/1 Running 0 74s 172.30.46.229 10.193.10.58
redis-cluster-2-0 1/1 Running 0 44m 172.30.155.89 10.192.57.161
redis-cluster-2-1 1/1 Running 0 42m 172.30.155.90 10.192.57.161
redis-cluster-2-2 1/1 Running 0 40m 172.30.155.91 10.192.57.161
redis-cluster-3-0 1/1 Running 0 27m 172.30.190.215 10.212.5.223
redis-cluster-3-1 1/1 Running 0 25m 172.30.190.216 10.212.5.223
redis-cluster-3-2 1/1 Running 0 23m 172.30.190.217 10.212.5.223
$ kubectl exec -it redis-cluster-2-0 -- redis-cli -c cluster nodes (見やすくするために、IPアドレスでソートしています。)
a42b74b5a3f8002aac192c9e936c28382ab4fca9 172.30.155.89:6379@16379 myself,master - 0 1564909420000 7 connected 10923-16383
a1bc886c988fb43538c96cf64261470d2b0a3070 172.30.155.90:6379@16379 master - 0 1564909420000 8 connected 0-5460
07fbf589aff23033581264a9734d8bd7d6a0c570 172.30.155.91:6379@16379 master - 0 1564909420000 9 connected 5461-10922
ff0d4b630bfbc015a192db93911d4c27d9ccc0fa 172.30.46.227:6379@16379 slave a1bc886c988fb43538c96cf64261470d2b0a3070 0 1564909422477 8 connected
4aab750764825dadf4fddb67eaf7c2df6101195d 172.30.46.228:6379@16379 slave 07fbf589aff23033581264a9734d8bd7d6a0c570 0 1564909421000 9 connected
643ac620d961badfef08c39e815724503dbd53de 172.30.46.229:6379@16379 slave a42b74b5a3f8002aac192c9e936c28382ab4fca9 0 1564909420000 7 connected
31c819ff92f73294c47480e7107d2cbaf2df1c42 172.30.190.215:6379@16379 slave a1bc886c988fb43538c96cf64261470d2b0a3070 0 1564909421470 8 connected
a93fbcda1dd4ff810aa39717195ddbfb1cc7292a 172.30.190.216:6379@16379 slave 07fbf589aff23033581264a9734d8bd7d6a0c570 0 1564909422000 9 connected
19dcb21943fcbdb6244052f2f76ba2dc652900bd 172.30.190.217:6379@16379 slave a42b74b5a3f8002aac192c9e936c28382ab4fca9 0 1564909423482 7 connected
模擬障害発生
redis-cluster-2-* シリーズのポッドをまとめて削除した。
$ kubectl delete -f redis-cluster-mzr-2m.yml
statefulset.apps "redis-cluster-2" deleted
$ kubectl get po -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
redis-cluster-1-0 1/1 Running 0 2m55s 172.30.46.227 10.193.10.58 <none> <none>
redis-cluster-1-1 1/1 Running 0 2m35s 172.30.46.228 10.193.10.58 <none> <none>
redis-cluster-1-2 1/1 Running 0 2m17s 172.30.46.229 10.193.10.58 <none> <none>
redis-cluster-3-0 1/1 Running 0 28m 172.30.190.215 10.212.5.223 <none> <none>
redis-cluster-3-1 1/1 Running 0 26m 172.30.190.216 10.212.5.223 <none> <none>
redis-cluster-3-2 1/1 Running 0 24m 172.30.190.217 10.212.5.223 <none> <none>
Redisマスターが、すべてフェール(fail)している状態になった。
$ kubectl exec -it redis-cluster-1-0 -- redis-cli -c cluster nodes
a42b74b5a3f8002aac192c9e936c28382ab4fca9 172.30.155.89:6379@16379 master,fail? - 1564909448754 1564909446000 7 connected 10923-16383
a1bc886c988fb43538c96cf64261470d2b0a3070 172.30.155.90:6379@16379 master,fail? - 1564909448855 1564909445000 8 connected 0-5460
07fbf589aff23033581264a9734d8bd7d6a0c570 172.30.155.91:6379@16379 master,fail? - 1564909448754 1564909446950 9 connected 5461-10922
ff0d4b630bfbc015a192db93911d4c27d9ccc0fa 172.30.46.227:6379@16379 myself,slave a1bc886c988fb43538c96cf64261470d2b0a3070 0 1564909465000 1 connected
4aab750764825dadf4fddb67eaf7c2df6101195d 172.30.46.228:6379@16379 slave 07fbf589aff23033581264a9734d8bd7d6a0c570 0 1564909464019 9 connected
643ac620d961badfef08c39e815724503dbd53de 172.30.46.229:6379@16379 slave a42b74b5a3f8002aac192c9e936c28382ab4fca9 0 1564909465022 7 connected
31c819ff92f73294c47480e7107d2cbaf2df1c42 172.30.190.215:6379@16379 slave a1bc886c988fb43538c96cf64261470d2b0a3070 0 1564909467035 8 connected
a93fbcda1dd4ff810aa39717195ddbfb1cc7292a 172.30.190.216:6379@16379 slave 07fbf589aff23033581264a9734d8bd7d6a0c570 0 1564909464000 9 connected
19dcb21943fcbdb6244052f2f76ba2dc652900bd 172.30.190.217:6379@16379 slave a42b74b5a3f8002aac192c9e936c28382ab4fca9 0 1564909466032 7 connected
3つのRedisマスターが停止したので、クラスタは停止状態 cluster_state:fail となる。 Redisクラスタでは、同時に2つ以上が停止した場合はクラスタを停止させる仕様であるためだ。
一方、スロットのステータスはOKとなっており、データが失われていないことが解る。
この状態では、Redisクラスタは停止しているので、クライアントからの読出し、書込みは、出来ない。
$ kubectl exec -it redis-cluster-1-0 -- redis-cli -c cluster info
cluster_state:fail
cluster_slots_assigned:16384
cluster_slots_ok:0
cluster_slots_pfail:16384
cluster_slots_fail:0
cluster_known_nodes:9
cluster_size:3
cluster_current_epoch:9
<以下省略>
クラスタの回復操作
Redisクラスタが、ゾーン障害によって停止した状態から、Redisのサービスを復旧させるために必要な作業を確認する。
Redisクラスタが停止しているので、Redisスレーブがマスターへ昇格しない。そのため、マニュアル操作で、スレーブをマスターへフェイルオーバーさせる。
下記の例では、2つのRedisノードをフェイルオーバーさせた処で、Redisクラスタが復活して、
三番目のスレーブはマスターに昇格していたので、エラーとなった。これは問題なしと見なせる。
「cluster failover takeover」コマンドは、Redisスレーブで実行しなければならない。
そして、このコマンドによって、Redisスレーブが、マスターの権限を奪い、自身がRedisマスターに昇格する。
1ゾーンに3つのスロットのマスターを作っているため、以下のように、3回の動作が必要となる。
imac:iks-mzr-tok-multi-pod maho$ kubectl exec -it redis-cluster-1-0 -- redis-cli -c cluster failover takeover
OK
imac:iks-mzr-tok-multi-pod maho$ kubectl exec -it redis-cluster-1-1 -- redis-cli -c cluster failover takeover
OK
imac:iks-mzr-tok-multi-pod maho$ kubectl exec -it redis-cluster-1-2 -- redis-cli -c cluster failover takeover
(error) ERR You should send CLUSTER FAILOVER to a replica
クラスタの回復後の確認
フェイルしたマスターは、そのまま停止した状態で、手操作でフェイルオーバーしたマスターが動作中になっている。
もちろん、Redisクラスタ状態を表示すると、cluster_state:ok となっている。
$ kubectl exec -it redis-cluster-1-0 -- redis-cli -c cluster nodes (見易さのため IPアドレスでソートしました)
a42b74b5a3f8002aac192c9e936c28382ab4fca9 172.30.155.89:6379@16379 master,fail - 1564909448754 1564909446000 7 connected
a1bc886c988fb43538c96cf64261470d2b0a3070 172.30.155.90:6379@16379 master,fail - 1564909448855 1564909445000 8 connected
07fbf589aff23033581264a9734d8bd7d6a0c570 172.30.155.91:6379@16379 master,fail - 1564909448754 1564909446950 9 connected
ff0d4b630bfbc015a192db93911d4c27d9ccc0fa 172.30.46.227:6379@16379 myself,master - 0 1564909596000 10 connected 0-5460
4aab750764825dadf4fddb67eaf7c2df6101195d 172.30.46.228:6379@16379 master - 0 1564909597569 11 connected 5461-10922
643ac620d961badfef08c39e815724503dbd53de 172.30.46.229:6379@16379 master - 0 1564909596563 12 connected 10923-16383
31c819ff92f73294c47480e7107d2cbaf2df1c42 172.30.190.215:6379@16379 slave ff0d4b630bfbc015a192db93911d4c27d9ccc0fa 0 1564909595562 10 connected
a93fbcda1dd4ff810aa39717195ddbfb1cc7292a 172.30.190.216:6379@16379 slave 4aab750764825dadf4fddb67eaf7c2df6101195d 0 1564909597000 11 connected
19dcb21943fcbdb6244052f2f76ba2dc652900bd 172.30.190.217:6379@16379 slave 643ac620d961badfef08c39e815724503dbd53de 0 1564909598575 12 connected
$ kubectl exec -it redis-cluster-1-0 -- redis-cli -c cluster info
cluster_state:ok
cluster_slots_assigned:16384
cluster_slots_ok:16384
cluster_slots_pfail:0
cluster_slots_fail:0
cluster_known_nodes:9
cluster_size:3
cluster_current_epoch:12
障害ノードの処理
落ちたゾーンが復活すれば、自動的にスレーブとして再編入される。
$ kubectl apply -f redis-cluster-mzr-2m.yml
statefulset.apps/redis-cluster-2 created
$ kubectl exec -it redis-cluster-1-0 -- redis-cli -c cluster nodes
a42b74b5a3f8002aac192c9e936c28382ab4fca9 172.30.155.92:6379@16379 slave 643ac620d961badfef08c39e815724503dbd53de 0 1564910872000 12 connected
a1bc886c988fb43538c96cf64261470d2b0a3070 172.30.155.93:6379@16379 slave ff0d4b630bfbc015a192db93911d4c27d9ccc0fa 0 1564910871000 10 connected
07fbf589aff23033581264a9734d8bd7d6a0c570 172.30.155.94:6379@16379 slave 4aab750764825dadf4fddb67eaf7c2df6101195d 0 1564910874024 11 connected
ff0d4b630bfbc015a192db93911d4c27d9ccc0fa 172.30.46.227:6379@16379 myself,master - 0 1564910873000 10 connected 0-5460
4aab750764825dadf4fddb67eaf7c2df6101195d 172.30.46.228:6379@16379 master - 0 1564910872014 11 connected 5461-10922
643ac620d961badfef08c39e815724503dbd53de 172.30.46.229:6379@16379 master - 0 1564910870005 12 connected 10923-16383
31c819ff92f73294c47480e7107d2cbaf2df1c42 172.30.190.215:6379@16379 slave ff0d4b630bfbc015a192db93911d4c27d9ccc0fa 0 1564910873020 10 connected
a93fbcda1dd4ff810aa39717195ddbfb1cc7292a 172.30.190.216:6379@16379 slave 4aab750764825dadf4fddb67eaf7c2df6101195d 0 1564910875028 11 connected
19dcb21943fcbdb6244052f2f76ba2dc652900bd 172.30.190.217:6379@16379 slave 643ac620d961badfef08c39e815724503dbd53de 0 1564910870000 12 connected
模擬ゾーン障害からの復旧 (Redisマスターが各ゾーンに分散配置されたケース)
初期状態は、redis-cluster-1-* に、Redisマスターが集中している。つまり、Zone-1に集中した状態である。
$ kubectl exec -it redis-cluster-1-0 -- redis-cli -c cluster nodes
ff0d4b630bfbc015a192db93911d4c27d9ccc0fa 172.30.46.227:6379@16379 myself,master - 0 1564968490000 10 connected 0-5460
4aab750764825dadf4fddb67eaf7c2df6101195d 172.30.46.228:6379@16379 master - 0 1564968490405 11 connected 5461-10922
643ac620d961badfef08c39e815724503dbd53de 172.30.46.229:6379@16379 master - 0 1564968489000 12 connected 10923-16383
31c819ff92f73294c47480e7107d2cbaf2df1c42 172.30.190.215:6379@16379 slave ff0d4b630bfbc015a192db93911d4c27d9ccc0fa 0 1564968491414 10 connected
a93fbcda1dd4ff810aa39717195ddbfb1cc7292a 172.30.190.216:6379@16379 slave 4aab750764825dadf4fddb67eaf7c2df6101195d 0 1564968493419 11 connected
19dcb21943fcbdb6244052f2f76ba2dc652900bd 172.30.190.217:6379@16379 slave 643ac620d961badfef08c39e815724503dbd53de 0 1564968492417 12 connected
a42b74b5a3f8002aac192c9e936c28382ab4fca9 172.30.155.92:6379@16379 slave 643ac620d961badfef08c39e815724503dbd53de 0 1564968491000 12 connected
a1bc886c988fb43538c96cf64261470d2b0a3070 172.30.155.93:6379@16379 slave ff0d4b630bfbc015a192db93911d4c27d9ccc0fa 0 1564968491000 10 connected
07fbf589aff23033581264a9734d8bd7d6a0c570 172.30.155.94:6379@16379 slave 4aab750764825dadf4fddb67eaf7c2df6101195d 0 1564968487000 11 connected
$ kubectl get po -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
redis-cluster-1-0 1/1 Running 0 16h 172.30.46.227 10.193.10.58 <none> <none>
redis-cluster-1-1 1/1 Running 0 16h 172.30.46.228 10.193.10.58 <none> <none>
redis-cluster-1-2 1/1 Running 0 16h 172.30.46.229 10.193.10.58 <none> <none>
redis-cluster-2-0 1/1 Running 0 16h 172.30.155.92 10.192.57.161 <none> <none>
redis-cluster-2-1 1/1 Running 0 16h 172.30.155.93 10.192.57.161 <none> <none>
redis-cluster-2-2 1/1 Running 0 16h 172.30.155.94 10.192.57.161 <none> <none>
redis-cluster-3-0 1/1 Running 0 16h 172.30.190.215 10.212.5.223 <none> <none>
redis-cluster-3-1 1/1 Running 0 16h 172.30.190.216 10.212.5.223 <none> <none>
redis-cluster-3-2 1/1 Running 0 16h 172.30.190.217 10.212.5.223 <none> <none>
次のターミナルの操作記録は、172.30.46.228:6379 5461-10922 を redis-cluster-2-1 172.30.155.93 へ、そして、172.30.46.229:6379 10923-16383 を redis-cluster-3-2 172.30.190.217 へ移動するために、次のコマンドを実行して、結果を確認したものである。Redisマスターが移動しているのが解る。
$ kubectl exec -it redis-cluster-2-1 -- redis-cli -c cluster failover
OK
$ kubectl exec -it redis-cluster-3-2 -- redis-cli -c cluster failover
OK
$ kubectl exec -it redis-cluster-1-0 -- redis-cli -c cluster nodes
31c819ff92f73294c47480e7107d2cbaf2df1c42 172.30.190.215:6379@16379 slave a1bc886c988fb43538c96cf64261470d2b0a3070 0 1564968794000 13 connected
a93fbcda1dd4ff810aa39717195ddbfb1cc7292a 172.30.190.216:6379@16379 slave 4aab750764825dadf4fddb67eaf7c2df6101195d 0 1564968791638 11 connected
19dcb21943fcbdb6244052f2f76ba2dc652900bd 172.30.190.217:6379@16379 master - 0 1564968792641 14 connected 10923-16383
ff0d4b630bfbc015a192db93911d4c27d9ccc0fa 172.30.46.227:6379@16379 myself,slave a1bc886c988fb43538c96cf64261470d2b0a3070 0 1564968793000 10 connected
4aab750764825dadf4fddb67eaf7c2df6101195d 172.30.46.228:6379@16379 master - 0 1564968792000 11 connected 5461-10922
643ac620d961badfef08c39e815724503dbd53de 172.30.46.229:6379@16379 slave 19dcb21943fcbdb6244052f2f76ba2dc652900bd 0 1564968794648 14 connected
a42b74b5a3f8002aac192c9e936c28382ab4fca9 172.30.155.92:6379@16379 slave 19dcb21943fcbdb6244052f2f76ba2dc652900bd 0 1564968792000 14 connected
a1bc886c988fb43538c96cf64261470d2b0a3070 172.30.155.93:6379@16379 master - 0 1564968791000 13 connected 0-5460
07fbf589aff23033581264a9734d8bd7d6a0c570 172.30.155.94:6379@16379 slave 4aab750764825dadf4fddb67eaf7c2df6101195d 0 1564968795653 11 connected
模擬障害テストを実施
ここから、模擬障害テストを実施する前に、初期状態の確認である。「cluster_state:ok」と正常に機能していることが解る。そして、redis-cluster-1-* 系統のポッドを削除する。
$ kubectl exec -it redis-cluster-1-0 -- redis-cli -c cluster info
cluster_state:ok
cluster_slots_assigned:16384
cluster_slots_ok:16384
<以下省略>
$ kubectl delete -f redis-cluster-mzr-1m.yml
statefulset.apps "redis-cluster-1" deleted
状態の確認
ゾーン1のポッドが、無くなっても正常にサービスが継続していることが、「cluster_state:ok」から確認できる。
$ kubectl get po -o wide
NAME READY STATUS RESTARTS AGE IP NODE
redis-cluster-2-0 1/1 Running 0 16h 172.30.155.92 10.192.57.161
redis-cluster-2-1 1/1 Running 0 16h 172.30.155.93 10.192.57.161
redis-cluster-2-2 1/1 Running 0 16h 172.30.155.94 10.192.57.161
redis-cluster-3-0 1/1 Running 0 16h 172.30.190.215 10.212.5.223
redis-cluster-3-1 1/1 Running 0 16h 172.30.190.216 10.212.5.223
redis-cluster-3-2 1/1 Running 0 16h 172.30.190.217 10.212.5.223
$ kubectl exec -it redis-cluster-2-0 -- redis-cli -c cluster info
cluster_state:ok
cluster_slots_assigned:16384
cluster_slots_ok:16384
<以下省略>
Redisノードをリストした表示である。もし、ここで2重障害が発生して、redis-cluster-2系列が止まると、流石に、Redisクラスタは停止することが読み取れる。
$ kubectl exec -it redis-cluster-2-0 -- redis-cli -c cluster nodes
ff0d4b630bfbc015a192db93911d4c27d9ccc0fa 172.30.46.227:6379@16379 slave,fail a1bc886c988fb43538c96cf64261470d2b0a3070 1564968882898 1564968880493 13 connected
4aab750764825dadf4fddb67eaf7c2df6101195d 172.30.46.228:6379@16379 master,fail - 1564968882899 1564968882499 11 connected
643ac620d961badfef08c39e815724503dbd53de 172.30.46.229:6379@16379 slave,fail 19dcb21943fcbdb6244052f2f76ba2dc652900bd 1564968882898 1564968881000 14 connected
a42b74b5a3f8002aac192c9e936c28382ab4fca9 172.30.155.92:6379@16379 myself,slave 19dcb21943fcbdb6244052f2f76ba2dc652900bd 0 1564968978000 7 connected
a1bc886c988fb43538c96cf64261470d2b0a3070 172.30.155.93:6379@16379 master - 0 1564968979845 13 connected 0-5460
07fbf589aff23033581264a9734d8bd7d6a0c570 172.30.155.94:6379@16379 master - 0 1564968977838 15 connected 5461-10922
31c819ff92f73294c47480e7107d2cbaf2df1c42 172.30.190.215:6379@16379 slave a1bc886c988fb43538c96cf64261470d2b0a3070 0 1564968979000 13 connected
a93fbcda1dd4ff810aa39717195ddbfb1cc7292a 172.30.190.216:6379@16379 slave 07fbf589aff23033581264a9734d8bd7d6a0c570 0 1564968980849 15 connected
19dcb21943fcbdb6244052f2f76ba2dc652900bd 172.30.190.217:6379@16379 master - 0 1564968981851 14 connected 10923-16383
まとめ
マイクロサービス化ではIstioばかりに目が向きがちであるが、クラウドネイティブなアプリとして、ステートレス化を進めるに当たって、重要なサービスである。
そのRedisは、クラウドのマルチゾーン、すなわち、複数データセンターに分散配置すれば、それで可用性やデータの保全性が向上するというものではない。
マルチゾーンに配置するコンテナのソフトウェアの仕様を良く鑑みた上で、K8sオブジェクトの構成を決定する必要があることが解った。
そして、Redisのようなアプリケーションのレイヤーでクラスタリングを構成するソフトウェアは、K8s上であっても、十分な配慮が必要だ。
このような、システム管理の負荷を軽減するのが、Red Hat が提案してきた Operator である。早急に時間を確保して確認したい。
参考資料
- 動的プロビジョニング: ステートフル・セット作成時の PVC の作成, https://cloud.ibm.com/docs/containers?topic=containers-file_storage#file_dynamic_statefulset
- Redisクラスタのチュートリアル,https://redis.io/topics/cluster-tutorial
- Redisのコマンドライン・クライアント,https://redis.io/topics/rediscli
- Redisコマンド,https://redis.io/commands