Watson の NLC や R&R は、自然言語処理の難しい部分を隠蔽して、簡単にビジネスに応用できる機能を提供してくれている。しかし、応用を考える時、いろいろな疑問が湧き上がってくる。 雨の休日に自己研鑽のために、学んだことを忘備録としてQiitaに投稿します。
自然言語とは
人間がお互いにコミュニケーションを行うための自然発生的な言語である。「自然言語」という語は特に数式やプログラミング言語、人工的に定義された形式言語・人工言語に対比させる必要がある場合にこう呼ばれる
文化や曖昧さを含んだ自然発生的にかたち作られた言語をどの様に機械で処理できるのか、とても興味深いので、探求を進める。
自然言語処理とは
自然言語処理(しぜんげんごしょり、英語: natural language processing、略称:NLP)は、人間が日常的に使っている自然言語をコンピュータに処理させる一連の技術であり、人工知能と言語学の一分野である。
この自然言語処理を理解するために、この基礎技術から応用技術を順番に、調べを進めていく事にする。
自然言語処理に関わる技術を鳥瞰するには、この図が解りやすいので引用する。
大規模データ時代に求められる自然言語処理 SlidShare

次の表は、自然言語処理の階層的な表現が、解りやすかったので、もう一つ挙げておく事にする。
C2Cube株式会社 新機能素解析アルゴリズム からの引用
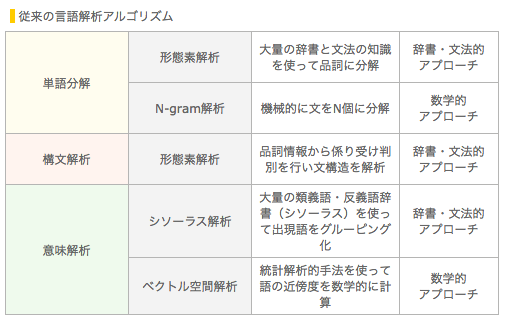
単語分割
形態素解析
形態素解析(けいたいそかいせき、Morphological Analysis)とは、文法的な情報の注記の無い自然言語のテキストデータ(文)から、対象言語の文法や、辞書と呼ばれる単語の品詞等の情報にもとづき、形態素(Morpheme, おおまかにいえば、言語で意味を持つ最小単位)の列に分割し、それぞれの形態素の品詞等を判別する作業である。
フリーで利用できる日本語の形態素解析ソフトウェアの中で、何を利用して良いか迷う時は、MeCab のウェブページが参考になる。
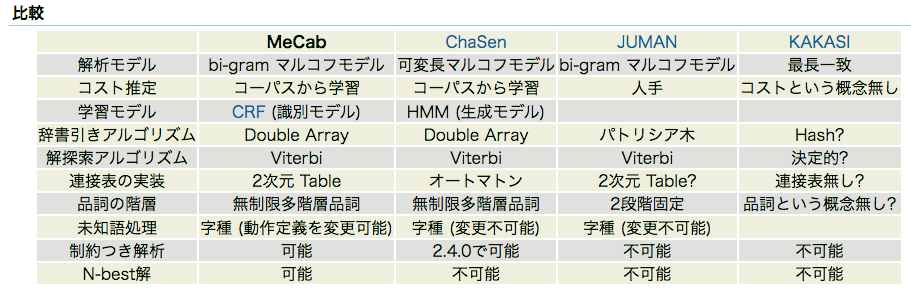
ChaSenからの改良点は、MeCabの開発経緯に説明されている。一番進化した形態素解析エンジンとしては、MeCabを選択するのが良さそうですね。
Watson R&R で利用されている Apache Solr は日本語の文章から単語を抽出する方法に、N-gramと形態素解析が使えます。(*1) 形態素解析は Kuromoji が採用されています。(*2)
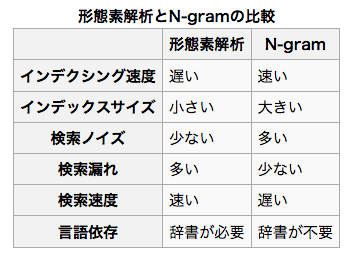
N-gram解析
[全文検索 Wikipedia からの引用] (https://ja.wikipedia.org/wiki/%E5%85%A8%E6%96%87%E6%A4%9C%E7%B4%A2)
「N文字インデックス法」「Nグラム法」などともいう。検索対象を単語単位ではなく文字単位で分解し、後続の N-1 文字を含めた状態で出現頻度を求める方法。Nの値が1なら「ユニグラム(uni-gram)」、2なら「バイグラム(bi-gram)」、3なら「トライグラム(tri-gram)」と呼ばれる。たとえば「全文検索技術」という文字列の場合、「全文」「文検」「検索」「索技」「技術」「術(終端)」と2文字ずつ分割して索引化を行ってやれば、検索漏れが生じず、辞書の必要も無い。形態素解析によるわかち書きに比べると、2つの欠点がある。意図したものとは異なる検索結果(いわゆる検索ノイズ)の発生と、インデックスサイズの肥大化である。検索ノイズの一例として、「京都」で検索すると「東京都庁」という適合しない検索結果が返ってくる場合、タレント名を検索するとネットショッピングサイトからの「お探しの商品は見つかりませんでした」というリプライやアフィリエイトブログばかりが結果として返って来る場合が挙げられる。
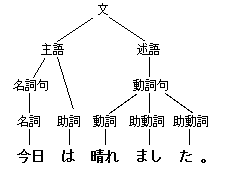
構文解析
自然言語であれば形態素に切分け、さらにその間の関連(修飾-被修飾など)といったような、統語論的(構文論的)な関係を図式化するなどして明かにする(解析する)手続きである。自然言語については自然言語処理における要点のひとつであり、
構文解析ソフトウェアとして、フリーで使えるものとして、2つが見つかりました。
CaboCha/南瓜とは
CaboCha は, Support Vector Machines に基づく日本語係り受け解析器です. 2001年6月現在, 統計的な日本語係り受け解析器として最も精度が高い(89.29%)システムとなっています. また, バックトラックを行なわない決定的な解析アルゴリズム (Cascaded Chunking Model) を採用しており, 比較的効率の良い解析が行なえます.
KNP (日本語構文・格・照応解析システム) とは
KNPは日本語文の構文・格・照応解析を行うシステムです.形態素解析システムJUMANの解析結果(形態素列)を入力とし, 文節および基本句間の係り受け関係,格関係,照応関係を出力します. 係り受け関係,格関係および照応関係は,Webから自動構築した大規模格フレームに基づく確率的モデルにより決定します.
意味解析・意味理解
形態素解析と構文解析までは、インターネットに色々な情報があるが、意味解析や意味理解という高次の分野は、長年研究されてきた分野の様であるが、非常に難しい問題を含み、難しい研究テーマの様だ。
文中の単語は何らかの意味をもち、また文中で依存関係にある2語の間には何らかの意味関係がある。しかし、それらの意味はその単語だけ、あるいは依存関係を示す表現だけを見ていたのでは必ずしも一意に決まらない。これは、単語には複数の意味をもつものがあり、依存関係を示す表現、例えば名詞をつなぐ「AのB」という表現が示す意味関係にも複数ありえるからである。 このような曖昧性の中には、文脈情報がなければ解釈できないもの、あるいは文脈によってもわからないものがある。
語義曖昧性解消 WSD (Word Sense Disambiguation) Wikipediaからの引用
語義の曖昧性解消とは自然言語処理において、文中のある単語に出会ったとき、その単語がどの語義をあらわしているのかを判断する過程のこと。 語義識別、語義判別、語義確定などともいう。 自然言語の単語には複数の語義が存在する場合がある。
述語項構造解析
述語項構造解析とは,文中の各述語について述語が表す意味を補う働きをする項を同定するタスクです.この項とは、動詞や形容詞などの「述語」は文の中心的な要素であり,動きや状態などの事態を表現します。
テキスト含意認識
テキスト含意認識とは、ある文書が特定の意味を含むかどうかを、表現の違いに左右されずに判定する技術
格文法
格文法(かくぶんぽう case grammar)とは、1968年に言語学者チャールズ・フィルモアによって提唱された文法理論である。 格文法は、動詞(さらには形容詞・名詞)とその深層格(動作主・場所・道具のような意味役割)との組み合わせから成るものとして文を分析しようとする理論である。フィルモアによれば、動詞はそれぞれいくつかの深層格を選択し、それらは格フレームを成す。格フレームはその動詞の意味的結合価の重要な側面を記述するものである。格フレームには、例えば一つの深層格は一文に一つしか現れないなどの制約がある。格には義務的なものと随意的なものがあり、義務的格を削除すると非文法的になる。
この格文法を用いることの目的は、複数の意味のある単語の意味を、文中のほかの単語との意味的整合性から決定することが意味解析の一つの目的である。また、依存関係を示す種々の表層表現からその深層の意味関係を決定するということがもう一つの目的となる。
言葉の意味を人工知能が理解して対応するために、難しい問題として、一般常識を全て学ばなければいけないという問題がある。このフレーム意味論から、理解することができる。
フレーム意味論の基本的な考え方は、ある語の理解にはその語と関連する世界知識にへのアクセスが不可欠であるということだ。例えば「買う」という語を理解するには、商取引についての背景知識が必要で、その知識には売り手・買い手・商品・金銭や、それらのあいだの関係を含む。
述語項構造解析ツール
文章中に出現する述語とその格要素を同定するツール
文書中の各述語に対して,「項」となる名詞句等を当てること。 すなわち、「語間の意味的な関係」を捉える
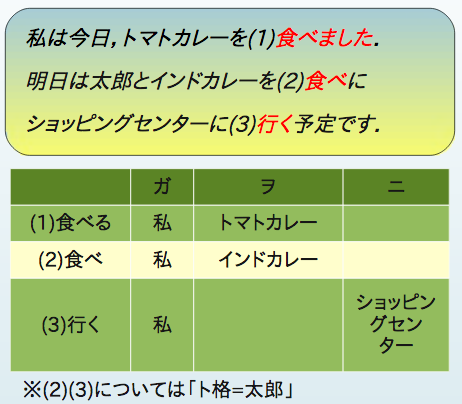
語義曖昧性解消の論文
語義の曖昧性解消に関するコード探して見たが、見つからなかった。 論文をいくつか発見したので、列挙しておく。
テキスト含意認識
NECのテキスト含意認識システム
テキストデータでは、同じ意味の内容が異なる表現で書かれている場合がたくさんあります。異なる表現が同じ意味であることを認識する技術は、テキスト含意認識技術と呼ばれます。
意味解析ツール
シソーラスを用いて、文章中に出現する述語とその格要素を分類するツールの様です。フレーム意味論といった高次までは難しい様です。
意味解析システムSAGE
日本語文の語の意味と、語と語の間の深層関係を、正確に計算する意味解析システム。 これは、語の意味的類似性から文の意味的類似性を計算するもので、文の分類や問い合わせ文による検索、さらには文をベースにした推論も可能。
日本語 意味解析ツール AYA
文章を入力すると、形態素解析(JUMAN)、係り受け解析(KNP)、意味解析を高速かつ高精度に行います。意味解析では、文章を形態素・文節に区切り、文節を頂点、係り受けを辺とした意味グラフ構造にまとめ上げた後、 形態素の意味をEDR辞書約40万語意の中から、また、文節間の係り受けの役割的関係である深層格をEDRおよび独自定義の30種の中から決定します。 時制、アスペクト、モダリティも解析できるので、「食べる」、「食べた」、「食べたい」の語意以外の意味もきちんと区別し、 文を書いた人の態度やニュアンスなど、より細かい情報も得られる。
ベクトル空間解析による意味解析
潜在意味解析(英: Latent Semantic Analysis, LSA)は、ベクトル空間モデルを利用した自然言語処理の技法の1つで、文書群とそこに含まれる用語群について、それらに関連した概念の集合を生成することで、その関係を分析する技術である。
ベクトル空間モデルとは情報検索を行うためのアルゴリズムの一つ。ベクトル空間モデルによる検索は高次元のベクトル空間上に配置した検索対象のベクトル表現と検索語のベクトル表現の相関量をコサイン、内積、距離等によって計算して関連度を求める。
tf-idfは、文書中の単語に関する重みの一種であり、主に情報検索や文章要約などの分野で利用される。
scikit-learn (正式には scikits.learn) はPythonのオープンソース機械学習ライブラリ[2]である。サポートベクターマシン、ランダムフォレスト、Gradient Boosting、k近傍法、DBSCANなどを含む様々な分類、回帰、クラスタリングアルゴリズムを備えており、Pythonの数値計算ライブラリのNumPyとSciPyとやり取りするよう設計されている。 Scikit-learnプロジェクトはDavid CournapeauによるGoogle Summer of Codeプロジェクト、scikits.learnとして始まった。 http://scikit-learn.org/stable/index.html
Word2vecは、テキスト処理を行い、2層から成るニューラルネットワークです。 テキストコーパスを入力すると、出力結果には、ベクトルのセット、つまりコーパスにある単語の特徴量ベクトル(feature vector)が出されます。Word2vecは、ディープ・ニューラル・ネットワークではありませんが、テキストをdeepネットワークが解釈できる数値形式に変えます。 Word2Vecとは?
word2vecのソースコード https://github.com/svn2github/word2vec
シソーラス、コーパス等のデータ
シソーラス (Thesaurus) は単語の上位 / 下位関係、部分 / 全体関係、同義関係、類義関係などによって単語を分類し、体系づけた類語辞典・辞書。
コーパス(英: corpus)とは、言語学において、自然言語処理の研究に用いるため、自然言語の文章を構造化し大規模に集積したもの。構造化では言語的な情報(品詞、統語構造など)が付与される。コンピュータ利用が進み、電子化データとなった。
OpenCycは、世界で最も大きく完全な汎用知識ベースと常識推論エンジンであるCyc技術のオープンソースバージョンです。OpenCycはインテリジェントアプリケーションのさまざまな基礎として使用することができます。https://ja.osdn.net/projects/freshmeat_opencyc/
日本の言語資源・ツールのカタログ http://www.jaist.ac.jp/project/NLP_Portal/doc/LR/lr-cat-j.html#jp:tsutsuji
DBpediaは、Wikipediaから構造化された情報を抽出し、この情報をWeb上で利用できるようにするために、クローリングにもとづくコミュニティの取り組みです。 DBpediaを使用すると、Wikipediaに対する洗練された質問をしたり、Web上のさまざまなデータセットをWikipediaデータにリンクさせることができます。 この作業によって、Wikipediaの膨大な量の情報を新しい興味深い方法で簡単に使用できるようになることを願っています。 さらに、百科事典そのものをナビゲート、リンク、改良するための新しい仕組みを鼓舞しているかもしれません。
自然言語処理のライブラリ
- Python による日本語自然言語処理
- Stanford CoreNLP – a suite of core NLP tools
- NLTK 3.0 documentation
- IBM developerWorks Python、機械学習、そして NLTK ライブラリーについて探る
言語処理学会
言語処理学会(The Association for Natural Language Processing)は,わが国の言語処理の研究成果発表の場として,また国際的な研究交流の場として,1994年4月1日に設立されました.原則年4回の会誌「自然言語処理」の発行,年1回の言語処理学会年次大会の開催を通じて,この分野の学問の発展,応用技術の発展と普及,国際的なレベルでの研究者・技術者・ユーザ相互間のコミュニケーションと人材の育成をはかる機関とすべく活動しています.
http://www.anlp.jp/index.html
参照資料
(1)Understanding Analyzers, Tokenizers, and Filters
(2)Language-Specific Factories Japanese
(3)自然言語処理 岩波書店