ROOKは、Kubernetes用のストレージ・オーケストレーターである。この役割は分散ストレージのシステム管理、自己スケーリング、自己修復を担当する。詳しくはオペレーターを利用することで、ストレージ管理者のタスク、デプロイ、ブートストラップ、構成、プロビジョニング、スケーリング、アップグレード、移行、災害復旧、監視、およびリソース管理を自動化する。
ROOKは、複数のストレージを提供するストレージ・オーケストレーターであり、横断的に共通のフレームワークを提供する。ワークロードに必要なストレージプロバイダーを選択して、Kubernetes上で同じように操作できる。ストレージプロバイダーには以下の種類がある。
- Ceph
- EdgeFS
- CockroachDB
- Cassandra
- NFS
- Yugabyte DB
このROOKが、最も効果的に利用できると考えられるのは、オンプレミス環境でのKubernetesクラスタである。つまり、クラウドのKubernetesサービスでは、Kubernetes上のPersistent Volume Claim(PVC)のAPIから、クラウドのストレージサービスと連携して、永続ボリュームがポッドに対して提供される。そのため、クラウドの環境では ROOK の利便性を感じることは無い。しかし、オンプレミス環境では、Kubernetesクラスタ環境にストレージサービスを構築できるため、低コスト、短期間で、クラウド環境と同様なストレージサービス利用できる。
この記事は、ROOK Cephのブロックストレージについて、Vagrant上のアップストリームのKubernetes 1.17.2 で検証した記録である。ROOK Cephは、Kubenretesクラスタ内部に、Kubernetesのコントローラーと連携してダイナミック・プロビジョニングできるソフトウェア定義ストレージシステム(SDS)である。これまでオンプレミスにKubernetesクラスタを配置する場合には、外部のストレージ装置に依存してきたが、ROOK Cephを使うことで、ワーカーノードの内蔵ディスクを利用して、ストレージのクラスタを作ることができる。このことによってハードウェアのインフラコストを抑えることができる。さらに、オペレーターによって、運用を自動化できるため、クラウドのストレージサービスを利用するかのように使用できると期待される。
しかし、良い話だけでは無い。引き換えとして、Kubernetesのバージョンアップなどの影響を受け易くなるなどの課題があるので、導入にあたっては慎重な姿勢が必要である。
ROOK実行環境の準備
これまで利用してきた学習用 Kubernetes に以下の改造を加えて、ROOKを実行させる。 リソースを大幅に必要とするため、一般的なパソコンのスペックで動作させるのは難しいパラメーターとなってしまった。
-
Vagrantfileの編集
- メモリとCPUの追加
- ストレージサイズの変更
- node2をコピーしてnode3を作成 マスターx1,ワーカーx3 へ
-
ansible-playbook の hostsファイルの編集
- hosts へ node3 を追加、証明書パスの変更
- nodesの変数範囲の追加
- KubernetesノードのOSをUbuntu18.04へ変更
仮想サーバーの起動
複数ノードを起動する点、そして、仮想マシンの内蔵ディスク追加するため、下記のVagrantプラグインをインストールしておく。
vagrant plugin install vagrant-cachier
vagrant plugin install vagrant-disksize
KubernetesをVagrantで起動するコードをクローンする。ブランチ 1.17-3nodeに、3ノード構成でメモリとコア数を増やしたバージョンを追加してある。
git clone -b 1.17-3node https://github.com/takara9/vagrant-kubernetes k8s
cd k8s
仮想サーバーの起動を以下のコマンドで実行する。
vagrant up
起動の確認
export KUBECONFIG=`pwd`/kubeconfig/config
kubectl get node
NAME STATUS ROLES AGE VERSION
master Ready master 2m5s v1.17.2
node1 Ready <none> 92s v1.17.2
node2 Ready <none> 93s v1.17.2
node3 Ready <none> 93s v1.17.2
外部アクセスノードの作成
ホントは正しく無いことであるが、masterノードを外部からアクセスするため NodePort 中継ノードにする。
masterノードに付与したホスト側LANのIPアドレスとNodePortのポート番号で、K8sクラスタ外部からアクセスできるようになる。
マスターノードを停止して、IPアドレスを設定して、再び起動する。
vagrant halt master
Vagrantfileを編集して、パソコンが繋がるLAN側にIPアドレス設定する。
vi Vagrantfile
154行目がコメントになっているので、#を消して有効な行にする。
153 machine.vm.network :private_network,ip: "172.16.20.11"
154 machine.vm.network :public_network, ip: "192.168.1.91", bridge: "en0: Ethernet"
再び master ノードを起動する。起動過程でインタフェースの選択を要求する場合があるので、ここでは有線LANのインタフェースを洗濯した。
vagrant up master
Bringing machine 'master' up with 'virtualbox' provider...
==> master: Checking if box 'ubuntu/xenial64' version '20200121.0.0' is up to date...
==> master: Clearing any previously set forwarded ports...
==> master: Fixed port collision for 22 => 2222. Now on port 2202.
==> master: Clearing any previously set network interfaces...
==> master: Specific bridge 'en0: Ethernet' not found. You may be asked to specify
==> master: which network to bridge to.
==> master: Available bridged network interfaces:
1) enp4s0
2) wlp3s0
3) docker0
==> master: When choosing an interface, it is usually the one that is
==> master: being used to connect to the internet.
master: Which interface should the network bridge to? 1
==> master: Preparing network interfaces based on configuration...
master: Adapter 1: nat
master: Adapter 2: hostonly
ROOK Ceph のデプロイ
ROOKとCephをインストールする。これによってブロック、ファイル、オブジェクトの3種類のストレージが利用できる。
参考URL ( https://rook.io/docs/rook/v1.2/ceph-quickstart.html )のガイドに従って、インストールを実施する。
git clone --single-branch --branch release-1.2 https://github.com/rook/rook.git
cd rook/cluster/examples/kubernetes/ceph
kubectl create -f common.yaml
kubectl create -f operator.yaml
上記で、ROOKのCephオペレーターまでが起動する。起動の確認としては、以下4つのポッドが起動すれば完了である。
kubectl get po -n rook-ceph
NAME READY STATUS RESTARTS AGE
rook-ceph-operator-6d74795f75-lhf65 1/1 Running 0 5m37s
rook-discover-949bg 1/1 Running 0 4m42s
rook-discover-m5sz7 1/1 Running 0 4m42s
rook-discover-zrdhd 1/1 Running 0 4m42s
ここで、ワーカーノードのOSストレージを利用すると、Cephに圧迫されて、コンテナ用のファイルシステムエリアが不足して、ワーカーノードの正常稼働の障害となるため、ワーカーノードに仮想ディスクを追加して、Cephから利用する。
次のファイルは、CephのCRDを使用してCephを起動するマニフェストである。この中でワーカーノードのディスクをマウントしたパス /var/lib/rook にCephのデータを dataDirHostPath: /var/lib/rook によって設定する。以下のcluster.yamlは、要点が判る様にコメント文を除いてたもので編集して作成する。
apiVersion: ceph.rook.io/v1
kind: CephCluster
metadata:
name: rook-ceph
namespace: rook-ceph
spec:
cephVersion:
image: ceph/ceph:v14.2.6
allowUnsupported: false
dataDirHostPath: /var/lib/rook # <--- データディレクトリ
skipUpgradeChecks: false
continueUpgradeAfterChecksEvenIfNotHealthy: false
mon:
count: 3
allowMultiplePerNode: false # モニターはノードに一つ
dashboard:
enabled: true
ssl: true
monitoring:
enabled: false
rulesNamespace: rook-ceph
network:
hostNetwork: false # ポッドネットワークを使用、パフォーマンスを求める時は再考
rbdMirroring:
workers: 0
crashCollector:
disable: false
annotations:
resources:
mgr:
limits:
cpu: "500m"
memory: "1024Mi"
requests:
cpu: "500m"
memory: "1024Mi"
removeOSDsIfOutAndSafeToRemove: false
storage:
useAllNodes: true
useAllDevices: true
config:
databaseSizeMB: "1024" # uncomment if the disks are smaller than 100 GB
journalSizeMB: "1024" # uncomment if the disks are 20 GB or smaller
osdsPerDevice: "1" # this value can be overridden at the node or device level
directories:
- path: /ceph_data
disruptionManagement:
managePodBudgets: false
osdMaintenanceTimeout: 30
manageMachineDisruptionBudgets: false
machineDisruptionBudgetNamespace: openshift-machine-api
ワーカーノードを構築する際に、Ansibleから追加したワーカーノード仮想ディスクをマウントしておく。次のファイル node_storage.yml がマウントするための プレイブックの一部である。
- hosts: nodes
become: yes
gather_facts: True
tasks:
- name: include k8s version
include_vars: /vagrant/ansible-playbook/versions.yml
- name: mkfs /dev/sdc
filesystem:
fstype: ext4
dev: /dev/sdc
- name: Creates directory
file:
path: /ceph_data
state: directory
owner: root
group: root
mode: 0775
- name: mount /ceph_data
mount:
path: /ceph_data
src: /dev/sdc
fstype: ext4
state: mounted
前述で編集したcluter.yamlを適用して、Cephを起動する。
kubectl create -f cluster.yaml
起動には、数分を要するので、-w をつけて様子を見ると良い。最終的には以下の状態になる。
kubectl get po -n rook-ceph
NAME READY STATUS RESTARTS AGE
csi-cephfsplugin-9vzmd 3/3 Running 0 9m3s
csi-cephfsplugin-bzjmk 3/3 Running 0 9m3s
csi-cephfsplugin-provisioner-565ffd64f5-gjbhc 4/4 Running 0 9m3s
csi-cephfsplugin-provisioner-565ffd64f5-tj7h7 4/4 Running 0 9m3s
csi-cephfsplugin-pv5s9 3/3 Running 0 9m3s
csi-rbdplugin-cws6k 3/3 Running 0 9m3s
csi-rbdplugin-jpgjb 3/3 Running 0 9m3s
csi-rbdplugin-p6zxd 3/3 Running 0 9m3s
csi-rbdplugin-provisioner-7bb78d6c66-p49kw 5/5 Running 0 9m3s
csi-rbdplugin-provisioner-7bb78d6c66-r687q 5/5 Running 0 9m3s
rook-ceph-crashcollector-node1-7bbb758b85-lxnmj 1/1 Running 0 5m46s
rook-ceph-crashcollector-node2-6c58bddcdd-hc7ck 1/1 Running 0 5m28s
rook-ceph-crashcollector-node3-7c8c9dd5bc-9c5h8 1/1 Running 0 4m44s
rook-ceph-mgr-a-98554f488-8zjft 1/1 Running 0 5m8s
rook-ceph-mon-a-59c478755b-8tk8d 1/1 Running 0 5m54s
rook-ceph-mon-b-5d9d488947-4r5xh 1/1 Running 0 5m46s
rook-ceph-mon-c-6bfd478cc5-hkhx2 1/1 Running 0 5m28s
rook-ceph-operator-6d74795f75-95nnv 1/1 Running 0 23m
rook-ceph-osd-0-644d5c77d7-mqfwd 1/1 Running 0 4m45s
rook-ceph-osd-1-54964546d4-xfwwh 1/1 Running 0 4m44s
rook-ceph-osd-2-78b5c5f8b-nss7l 1/1 Running 0 4m44s
rook-ceph-osd-prepare-node1-jtk75 0/1 Completed 0 4m49s
rook-ceph-osd-prepare-node2-c5r2n 0/1 Completed 0 4m49s
rook-ceph-osd-prepare-node3-jzl2w 0/1 Completed 0 4m49s
rook-discover-dqm9l 1/1 Running 0 23m
rook-discover-hvgcf 1/1 Running 0 23m
rook-discover-mvd7s 1/1 Running 0 23m
ツールボックスによるテスト
同じディレクトリ rook/cluster/examples/kubernetes/ceph のtoolbox.yamlを利用すると、cephコマンドを実行できる。
kubectl create -f toolbox.yaml
deployment.apps/rook-ceph-tools created
kubectl -n rook-ceph get pod -l "app=rook-ceph-tools"
NAME READY STATUS RESTARTS AGE
rook-ceph-tools-78b599b6dd-47vdt 1/1 Running 0 11s
ターミナルをポッドに繋いで、対話型でcephコマンドを実行する。
kubectl -n rook-ceph exec -it $(kubectl -n rook-ceph get pod -l "app=rook-ceph-tools" -o jsonpath='{.items[0].metadata.name}') bash
[root@rook-ceph-tools-78b599b6dd-47vdt /]# ceph status
cluster:
id: 40b602cc-b666-458f-b3a5-25287d48d6d4
health: HEALTH_OK
services:
mon: 1 daemons, quorum a (age 25m)
mgr: a(active, since 25m)
osd: 3 osds: 3 up (since 24m), 3 in (since 24m)
data:
pools: 0 pools, 0 pgs
objects: 0 objects, 0 B
usage: 17 GiB used, 129 GiB / 145 GiB avail
pgs:
[root@rook-ceph-tools-78b599b6dd-47vdt /]# ceph osd status
+----+-------+-------+-------+--------+---------+--------+---------+-----------+
| id | host | used | avail | wr ops | wr data | rd ops | rd data | state |
+----+-------+-------+-------+--------+---------+--------+---------+-----------+
| 0 | node2 | 5718M | 42.8G | 0 | 0 | 0 | 0 | exists,up |
| 1 | node1 | 5684M | 42.8G | 0 | 0 | 0 | 0 | exists,up |
| 2 | node3 | 5684M | 42.8G | 0 | 0 | 0 | 0 | exists,up |
+----+-------+-------+-------+--------+---------+--------+---------+-----------+
[root@rook-ceph-tools-78b599b6dd-47vdt /]# ceph df
RAW STORAGE:
CLASS SIZE AVAIL USED RAW USED %RAW USED
hdd 145 GiB 129 GiB 17 GiB 17 GiB 11.49
TOTAL 145 GiB 129 GiB 17 GiB 17 GiB 11.49
POOLS:
POOL ID STORED OBJECTS USED %USED MAX AVAIL
[root@rook-ceph-tools-78b599b6dd-47vdt /]# rados df
POOL_NAME USED OBJECTS CLONES COPIES MISSING_ON_PRIMARY UNFOUND DEGRADED RD_OPS RD WR_OPS WR USED COMPR UNDER COMPR
total_objects 0
total_used 17 GiB
total_avail 129 GiB
total_space 145 GiB
Cephの調整
仮想マシンのOSが Ubuntu 16.04 の場合は、カーネルの問題によりペンディングを回避する目的で、パラメータを変更する。一方、Ubuntu 18.04 を利用している場合は不要である。本記事で利用するブランチ 1.17-3node の場合は、Ubuntu 18.04 を使用しているので、以下の調整は不要である。
デフォルトのtunablesパラメータを確認する。以下の様にjewelでは、ブロックストレージが獲得されない課題があるので、変更する。
[root@rook-ceph-tools-78b599b6dd-8srn5 /]# ceph osd crush show-tunables
{
"choose_local_tries": 0,
"choose_local_fallback_tries": 0,
"choose_total_tries": 50,
"chooseleaf_descend_once": 1,
"chooseleaf_vary_r": 1,
"chooseleaf_stable": 1,
"straw_calc_version": 1,
"allowed_bucket_algs": 54,
"profile": "jewel", <<--- 設定のプロファイルが jewel になっている
"optimal_tunables": 1,
"legacy_tunables": 0,
"minimum_required_version": "jewel",
"require_feature_tunables": 1,
"require_feature_tunables2": 1,
"has_v2_rules": 0,
"require_feature_tunables3": 1,
"has_v3_rules": 0,
"has_v4_buckets": 1,
"require_feature_tunables5": 1,
"has_v5_rules": 0
}
hammerに設定を変更しておく。
[root@rook-ceph-tools-78b599b6dd-8srn5 /]# ceph osd crush tunables hammer
adjusted tunables profile to hammer
変更を確認する。
[root@rook-ceph-tools-78b599b6dd-8srn5 /]# ceph osd crush show-tunables
<中略>
"profile": "hammer",
<以下省略>
これで、Cephクラスタ側の設定は完了したので、クライアント側に入っていく。
ストレージクラスの設定
ダイナミック・プロビジョニングを実行するために、ストレージクラスを設定する。
cd csi/rbd
kubectl apply -f storageclass.yaml
cephblockpool.ceph.rook.io/replicapool created
storageclass.storage.k8s.io/rook-ceph-block created
設定されたことを確認する。
kubectl get sc
NAME PROVISIONER RECLAIMPOLICY VOLUMEBINDINGMODE ALLOWVOLUMEEXPANSION AGE
rook-ceph-block rook-ceph.rbd.csi.ceph.com Delete Immediate false 35s
これで、ブロックストレージを動的にプロビジョニングできるようになった。
動作検証 WordPressの起動
次に、ダイナミックプロビジョニングの機能を確かめるテストを実施する。テストには Wordpress を起動して、コンテンツとデータベースの二つの永続データの領域が ROOK Ceph から確保されるようにする。
サンプルのマニフェストが存在するディレクトリへ移動する。
$ cd ../../..
データベースをデプロイする。
kubectl apply -f mysql.yaml
アプリケーションサーバーをデプロイする。
kubectl apply -f wordpress.yaml
これにより、PVCが二つ作成される。
kubectl get pvc
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
mysql-pv-claim Bound pvc-4af72998-cfcf-46a7-9fe4-624e34db85cd 20Gi RWO rook-ceph-block 11s
wp-pv-claim Bound pvc-2c7a1991-00dd-4309-9883-c9c69eb0e7db 20Gi RWO rook-ceph-block 5s
Persistent Volume Claim
ここで、マニフェストを確認しておく。PVCのマニフェストでは、ブロックストレージなので、accessModesは共有を許さない ReadWriteOnceとなっている。
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: wp-pv-claim
labels:
app: wordpress
spec:
storageClassName: rook-ceph-block
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 2Gi
ブロックストレージをファイルシステムにマウントできる。つまり、おそらくプロビジョナーが動的にファイルシステムを作成してくれている。
volumeMounts:
- name: wordpress-persistent-storage
mountPath: /var/www/html
volumes:
- name: wordpress-persistent-storage
persistentVolumeClaim:
claimName: wp-pv-claim
トラブルシューティング
前述のceph osd crush tunables hammerを実行しなかった場合の問題について、説明する。
次のように、ポッドがポッドが'ContainerCreating'の状態のまま、次の段階に進まない場合、Cephに原因があるケースがある。
kubectl get po
NAME READY STATUS RESTARTS AGE
wordpress-5b886cf59b-6mdnv 0/1 ContainerCreating 0 2m44s
wordpress-mysql-b9ddd6d4c-s7dfc 0/1 ContainerCreating 0 2m50s
このようなケースの場合、ポッドの詳細を表示して Eventsを確認することで、停滞の原因が判る。ボリュームがマウントできない、タイムアウトのエラーが発生してることが判る。つまり、CephやROOKに問題があることが推定される。
kubectl describe po wordpress-mysql-b9ddd6d4c-s7dfc
<中略>
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Warning FailedScheduling 3m9s (x2 over 3m9s) default-scheduler error while running "VolumeBinding" filter plugin for pod "wordpress-mysql-b9ddd6d4c-s7dfc": pod has unbound immediate PersistentVolumeClaims
Normal Scheduled 3m8s default-scheduler Successfully assigned default/wordpress-mysql-b9ddd6d4c-s7dfc to node1
Normal SuccessfulAttachVolume 3m8s attachdetach-controller AttachVolume.Attach succeeded for volume "pvc-4af72998-cfcf-46a7-9fe4-624e34db85cd"
Warning FailedMount 65s kubelet, node1 Unable to attach or mount volumes: unmounted volumes=[mysql-persistent-storage], unattached volumes=[mysql-persistent-storage default-token-8qr52]: timed out waiting for the condition
Warning FailedMount 58s (x2 over 119s) kubelet, node1 MountVolume.MountDevice failed for volume "pvc-4af72998-cfcf-46a7-9fe4-624e34db85cd" : rpc error: code = Internal desc = rbd: map failed exit status 110, rbd output: rbd: sysfs write failed
In some cases useful info is found in syslog - try "dmesg | tail".
rbd: map failed: (110) Connection timed out
このケースは、https://github.com/ceph/ceph-helm/issues/60 によると、以下の原因にあたる。
Important Kubernetes uses the RBD kernel module to map RBDs to hosts. Luminous requires CRUSH_TUNABLES 5 (Jewel). The minimal kernel version for these tunables is 4.5. If your kernel does not support these tunables, run ceph osd crush tunables hammer
Ubuntu 16.04 を使用したワーカノードのカーネルのバージョンを調べると、4.4である。つまり、上記に該当するため、変更が必要となる。
vagrant@node1:~$ uname -a
Linux node1 4.4.0-171-generic #200-Ubuntu SMP Tue Dec 3 11:04:55 UTC 2019 x86_64 x86_64 x86_64 GNU/Linux
Ubuntu 18.04 を使用したカーネルは以下の通りであるので、対応は不要となる。
vagrant ssh node3
Welcome to Ubuntu 18.04.4 LTS (GNU/Linux 4.15.0-76-generic x86_64)
ROOK Ceph ダッシュボード
ブラウザからCephのダッシュボードを参照できるように設定を変更する。
初期設定では、サービスタイプが、ClusterIPになっている。これではクラスタ外部からアクセスすることができない。
kubectl -n rook-ceph get service rook-ceph-mgr-dashboard
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
rook-ceph-mgr-dashboard ClusterIP 10.32.0.200 <none> 8443:31930/TCP 5h49m
サブコマンド edit を使って、実行中のマニフェストを変更して、K8sクラスタ外部からアクセスできるように変更する。
kubectl -n rook-ceph edit service rook-ceph-mgr-dashboard
次は、上記のコマンドの実行結果である。35行目の type: ClusterIP を type: NodePort を変更する。
23 spec:
24 clusterIP: 10.32.0.252
25 ports:
26 - name: https-dashboard
27 port: 8443
28 protocol: TCP
29 targetPort: 8443
30 nodePort: 30443
31 selector:
32 app: rook-ceph-mgr
33 rook_cluster: rook-ceph
34 sessionAffinity: None
35 type: ClusterIP
上記の変更によって、以下のように、ノードのポートが開かれ、Cephのダッシュボードへアクセスが可能となる。マニフェストのports: に nodePort: 30443 を加えて設定することで、ポートが空いていれば、ダッシュボードのアドレスを一定に維持できる。
kubectl get svc -n rook-ceph rook-ceph-mgr-dashboard
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
rook-ceph-mgr-dashboard NodePort 10.32.0.252 <none> 8443:30443/TCP 17h
Cephダッシュボードにアクセスするには、パスワードが必要となる。このパスワードの取得は次のコマンドを実行することで得られる。
kubectl -n rook-ceph get secret rook-ceph-dashboard-password -o jsonpath="{['data']['password']}" | base64 --decode && echo
xZVbe1aVOL
マスターノードの仮想マシンホストに追加したIPアドレスに、このポート番号を追加して、https://192.168.1.91:30443 として ユーザーID admin でアクセスできる。
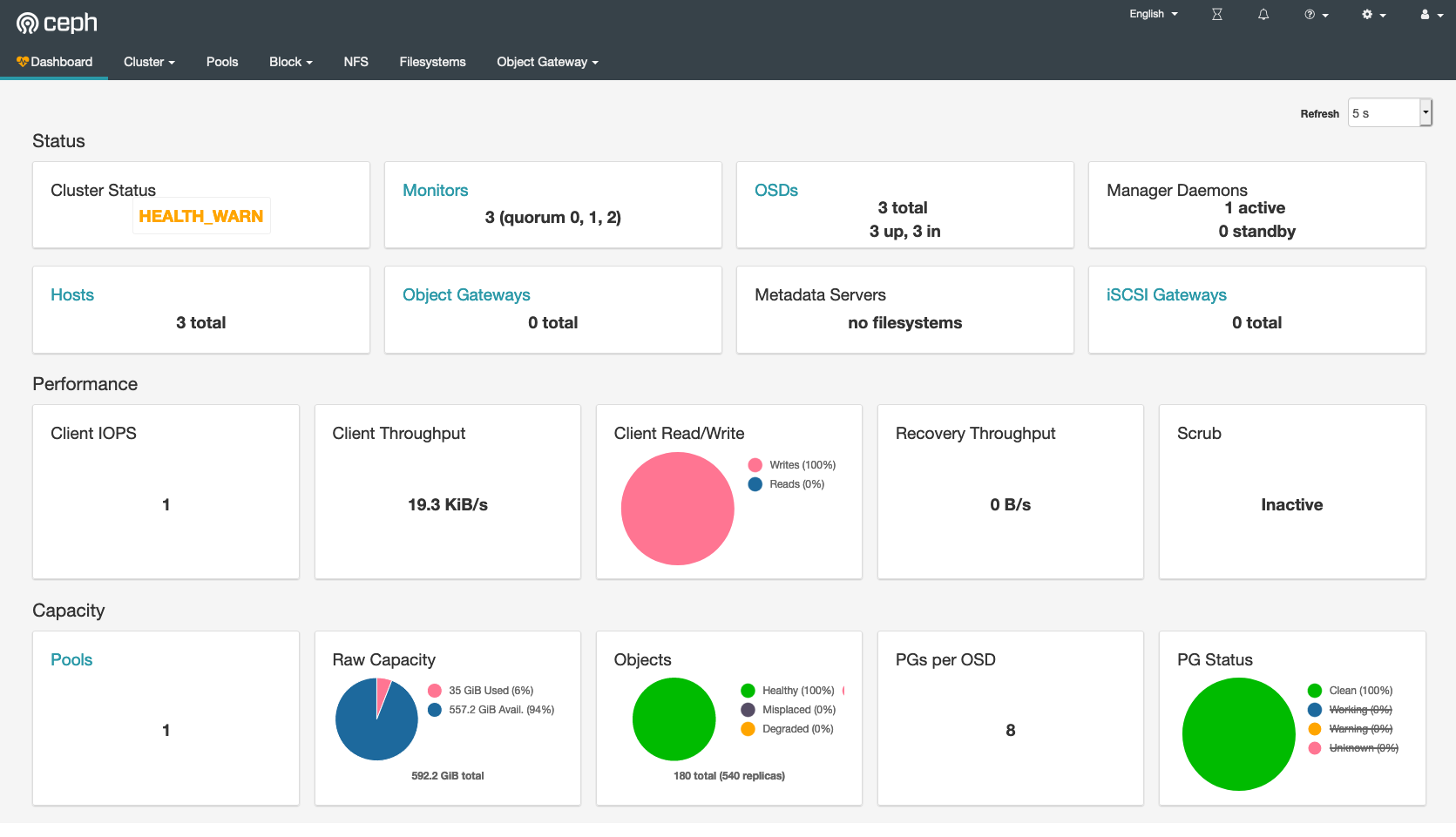
まとめ
ROOKでは、Cephを同じKubernetesクラスタ内のワーカーノードの内蔵ディスクを使用してSDSを構築することができる。ワーカーノードに永続データを保存することに、クラスタリングによって分散と冗長性が確保され、データの保全性が高いと言っても、やはり、抵抗感がある。単純なものほど壊れない、その事から、大切なデータを保存する装置は、必要な用件を満たした単純な装置である方が良い。こうすることで、ソフトウェアの複雑な連携、脆弱性、バージョンアップなど、ソフトウェアの不安定さから来る課題から、大切なデータを保護しておける。
しかし、Kubernetesクラスタに加えて、SDSクラスタを構築するとなると、相応のコストが必要となる。しかし、ROOKで同一Kubernetesクラスタに永続データを保持することができれば、手間もコストも少なくて済む。そして、スナップショットを取得してリモートのオブジェクトストレージに保存なども検証してみたい。
今回は、ROOK Cephのセットアップは、非常に簡単で早く実施できることが解った。しかし、Cephについての知識が不要なわけでは無い。ROOKの前にCephを知っているべきとも言える。そして、最新バージョンのCephを利用するには、ワーカーノードのLinuxカーネルのバージョンは4.5以上である必要がある。それが出来ない場合は、プロファイルのレベルを落とす必要がある。
ROOKは、OpenShiftでは OpenShift Container Storage として、OpenShift 4.3から利用できるようになっている。 オンプレミスでOpenShiftを使用する場合には、必要不可欠なコンポーネントになると考えられる。