Argo workflow の言葉のイメージから、人と人が連携して仕事を熟すためのツールと間違えそうだが、そうではなく、コンテナ化されたバッチアプリケーションのジョブコントロールシステムと言っても良いと思う。このOSSの実態を掴むために、軽く動かして見ただけだけど、これは良いツールという印象だった。
Argo workflow のインストール
K8sクラスタのセットアップ
Argo workflowは、コンテナ化されたバッチジョブのステップを実行するので、コンテナのエクゼキューターを指定できるようになっている。
デフォルトの設定では、dockerになっており、ソケットのパスが決まっている。 これらをdocker以外に変更しても動くが、成果物データをストレージに保存出来ないIssueがOpenとなっている。しかし、dockerと言っても、containerdをアクセスするだけのようなので、ソケットのパスが解れば解決するかもしれない。
# Specifies the container runtime interface to use (default: docker)
# must be one of: docker, kubelet, k8sapi, pns
containerRuntimeExecutor: docker
# Specifies the location of docker.sock on the host for docker executor (default: /var/run/docker.sock)
# (available since Argo v2.4)
dockerSockPath: /var/someplace/else/docker.sock
クラウドの環境で動かすのは、いったん保留として、パソコン環境下で Kubernetes を動かして、Argo workflow を動かすことにした。普段は触りたくないが、こういう時は、自由自在に変更できる アップストリームの Kubernetes環境は重宝する。
GitHubからクローンするが、バージョン 1.16 のブランチを使用する。いったん、Vagrantfile を編集して、ワーカーノードのコア数を 4コア、メモリを 8GB する。それから、コンテナのランタイムエンジンを docker に変更する。 リソースの増強は、パソコンにリソースがあればの話であるが....
$ git clone -b 1.16 https://github.com/takara9/vagrant-kubernetes k8s-1.16
$ cd k8s-1.16
$ vi Vagrantfile
以下の node1 と node2 となる行の cpu: 4, memory: 8192 が変更箇所
vm_spec = [
{ name: "master", cpu: 2, memory: 2048,
box: linux_os,
private_ip: "172.16.20.11",
public_ip: "192.168.1.91",
storage: [], playbook: "install_master.yml",
comment: "Master node" },
{ name: "node1", cpu: 4, memory: 8192,
box: linux_os,
private_ip: "172.16.20.12",
public_ip: "192.168.1.92",
storage: [], playbook: "install_node.yml",
comment: "Worker node #1" },
{ name: "node2", cpu: 4, memory: 8192,
box: linux_os,
private_ip: "172.16.20.13",
public_ip: "192.168.1.93",
storage: [], playbook: "install_node.yml",
comment: "Worker node #2" },
]
それから、Ansible playbook の以下の部分で、コンテナエンジンを docker-ce にする。
# どちらか一方を選んで、有効化してください。
# Chose either one and enable it. docker-ce or containerd
container_engine: docker-ce
# container_engine: containerd
vagrant up してから、起動後に、マスターノードにログインして、以下の結果を得られたら K8sクラスタの起動は成功である。
maho:k8s-1.16 maho$ vagrant ssh master
<中略>
vagrant@master:~$ kubectl get node
NAME STATUS ROLES AGE VERSION
master Ready master 18m v1.16.8
node1 Ready <none> 15m v1.16.8
node2 Ready <none> 12m v1.16.8
Argo workflow のインストール
マスターノードで引き続き、Argo workflow のインストールを実施する。 名前空間 argo を作成して、その名前空間にインストールする。
$ kubectl create ns argo
$ kubectl apply -n argo -f https://raw.githubusercontent.com/argoproj/argo/stable/manifests/quick-start-postgres.yaml
これは Argo workflow のクイックインストール用の構成ファイルで、UIを提供する argo-server と バッチジョブのコントロールを担う workflow-controller を起動するだけでなく、データベース postgress と 実効結果の成果物データを保存するオブジェクトストレージ minio を起動してくれる。 クラウドで動かしていれば、クラウドのデータベースサービスとオブジェクトストレージに繋ぐのだが、今回は、オブジェクトストレージだけ AWS S3 を利用ことにする。次は、起動直後のポッドの起動状況である。
$ kubectl get pod -n argo
NAME READY STATUS RESTARTS AGE
argo-server-787995cbf5-f7v2c 1/1 Running 3 2m8s
minio 1/1 Running 0 2m8s
postgres-69559bd989-9krjj 1/1 Running 0 2m8s
workflow-controller-f5958489f-gfk9x 1/1 Running 3 2m8s
ArgoのCLIコマンドのインストール
本格的に活用する時には、CLIで操作できるのが便利だと思うので、インストールしておく。
$ curl -sLO https://github.com/argoproj/argo/releases/download/v2.9.2/argo-linux-amd64
$ chmod +x argo-linux-amd64
$ sudo mv ./argo-linux-amd64 /usr/local/bin/argo
$ argo version
argo: v2.9.2
BuildDate: 2020-07-08T23:54:33Z
GitCommit: 65c2bd44e45c11e0a0b03adeef8d6800b72cd551
GitTreeState: clean
GitTag: v2.9.2
GoVersion: go1.13.4
Compiler: gc
Platform: linux/amd64
CLIコマンドからのジョブのサブミット
Argo workflow の構成ファイルを指定して、サブミットすれば、バッチ処理を実行して、結果をオブジェクトストレージに保存してくれる。
Kubernetes Job を本格的に利用する場合には、いろいろなツールを手作りする必要があったが、Argo workflow は便利である。
ジョブ(ワークフロー)のサブミット
$ argo submit -n argo --watch https://raw.githubusercontent.com/argoproj/argo/master/examples/hello-world.yaml
結果表示
$ argo list -n argo
NAME STATUS AGE DURATION PRIORITY
hello-world-qbsfr Succeeded 1m 42s 0
$ argo get -n argo @latest
Name: hello-world-qbsfr
Namespace: argo
ServiceAccount: default
Status: Succeeded
Conditions:
Completed True
Created: Sun Jul 12 13:54:39 +0000 (1 minute ago)
Started: Sun Jul 12 13:54:39 +0000 (1 minute ago)
Finished: Sun Jul 12 13:55:21 +0000 (58 seconds ago)
Duration: 42 seconds
ResourcesDuration: 22s*(1 cpu),22s*(100Mi memory)
STEP TEMPLATE PODNAME DURATION MESSAGE
✔ hello-world-qbsfr whalesay hello-world-qbsfr 40s
次はログ表示で、これは、オブジェクトストレージにも保存される。
$ argo logs -n argo @latest
hello-world-qbsfr: 2020-07-12T13:55:19.44861898Z _____________
hello-world-qbsfr: 2020-07-12T13:55:19.448653193Z < hello world >
hello-world-qbsfr: 2020-07-12T13:55:19.4486569Z -------------
hello-world-qbsfr: 2020-07-12T13:55:19.448659054Z \
hello-world-qbsfr: 2020-07-12T13:55:19.448661275Z \
hello-world-qbsfr: 2020-07-12T13:55:19.448663282Z \
hello-world-qbsfr: 2020-07-12T13:55:19.448665338Z ## .
hello-world-qbsfr: 2020-07-12T13:55:19.448667331Z ## ## ## ==
hello-world-qbsfr: 2020-07-12T13:55:19.448669252Z ## ## ## ## ===
hello-world-qbsfr: 2020-07-12T13:55:19.448671178Z /""""""""""""""""___/ ===
hello-world-qbsfr: 2020-07-12T13:55:19.448673284Z ~~~ {~~ ~~~~ ~~~ ~~~~ ~~ ~ / ===- ~~~
hello-world-qbsfr: 2020-07-12T13:55:19.448675217Z \______ o __/
hello-world-qbsfr: 2020-07-12T13:55:19.448677205Z \ \ __/
hello-world-qbsfr: 2020-07-12T13:55:19.448679348Z \____\______/
書き込み先を minio から AWS S3 へ変更
AWS S3 にバケットを作成して、アクセス権を付与して、結果の書き込みができるようにする。
$ export mybucket=argo-tkr-bucket249
$ cat > policy.json <<EOF
> {
> "Version":"2012-10-17",
> "Statement":[
> {
> "Effect":"Allow",
> "Action":[
> "s3:PutObject",
> "s3:GetObject"
> ],
> "Resource":"arn:aws:s3:::$mybucket/*"
> }
> ]
> }
> EOF
バケットの作成
$ aws s3 mb s3://$mybucket
make_bucket: argo-tkr-bucket249
権限の付与
$ aws iam create-user --user-name $mybucket-user
$ aws iam put-user-policy --user-name $mybucket-user --policy-name $mybucket-policy --policy-document file://policy.json
$ aws iam create-access-key --user-name $mybucket-user > access-key.json
アクセスキーとシークレットキーの表示
$ cat access-key.json
{
"AccessKey": {
<以下省略>
これらは、以下の設定ファイルには、オブジェクトストレージをアクセスするためのシークレット my-minio-cred が設定されているので、my-s3-cred を作って参照先を変更する。
$ kubectl get configmap -n argo
NAME DATA AGE
artifact-repositories 1 9h
workflow-controller-configmap 4 9h
それから、エンドポイント、バケット名、リージョンもセットする。minioではTLSが使わないが、S3は暗号化されるので、それに合わせて変更もしておく。
artifactRepository:
archiveLogs: true
s3:
endpoint: s3.amazonaws.com
bucket: bucket-tkr-9949
region: us-west-2
insecure: false
<中略>
accessKeySecret:
name: my-s3-cred
key: accesskey
secretKeySecret:
name: my-s3-cred
key: secretkey
それぞれのコンフィグマップは適用するだけで、それぞれのポッドは、新しい設定で動作するので、特にポッドの再起動は必要ない。
それから、参照先のシークレットも作成する。
apiVersion: v1
kind: Secret
metadata:
labels:
app: s3
name: my-s3-cred
stringData:
accesskey: access-key.jsonから該当の値をコピペ
secretkey: 同上
type: Opaque
これで、オブジェクトストレージ minio から S3 への切り替えが完了した。
Argo UI のアクセス
本格的に動かすならば、SSOや認証環境の考慮も必要であるが、パソコンの中で完結して動かすので、認証なしで簡単にアクセスできるようにする。
次のコマンドで、実行中のオブジェクトを直接編集して、nodeport としてアクセスできるようにする。
$ kubectl edit svc argo-server -n argo
編集箇所は、2つで、nodePort の行を追加、typeの値を NodePort へ変更する。
spec:
clusterIP: 10.32.0.124
externalTrafficPolicy: Cluster
ports:
- name: web
nodePort: 30007
port: 2746
protocol: TCP
targetPort: 2746
selector:
app: argo-server
sessionAffinity: None
type: NodePort
これで、Argo workflow のブラウザ画面を表示できるようになった。
ブラウザ画面のアクセス
サービスをNodePortで公開したので、マスターノードやワーカーノードのIPアドレス:30007 でブラウザ画面を開ける。
http://172.16.20.12:30007 にアクセスすれば、以下のワークフローの結果リストにアクセスできる。
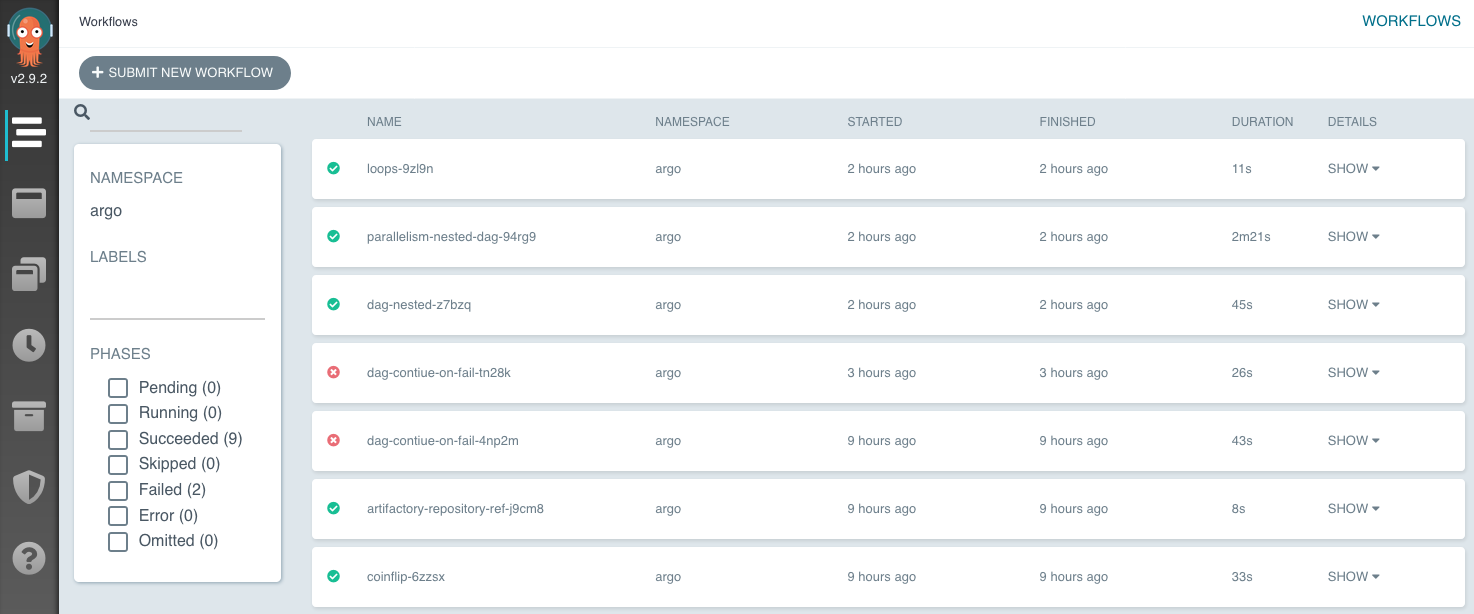
この画面の左上、「+SUBMIT NEW WORKFLOW」からサンプルのワークフロー構成ファイルを指定してジョブを実行できる。サンプルは、
https://github.com/argoproj/argo/tree/master/examples に沢山あるので、試してみると良い。
ワークフローの実行結果
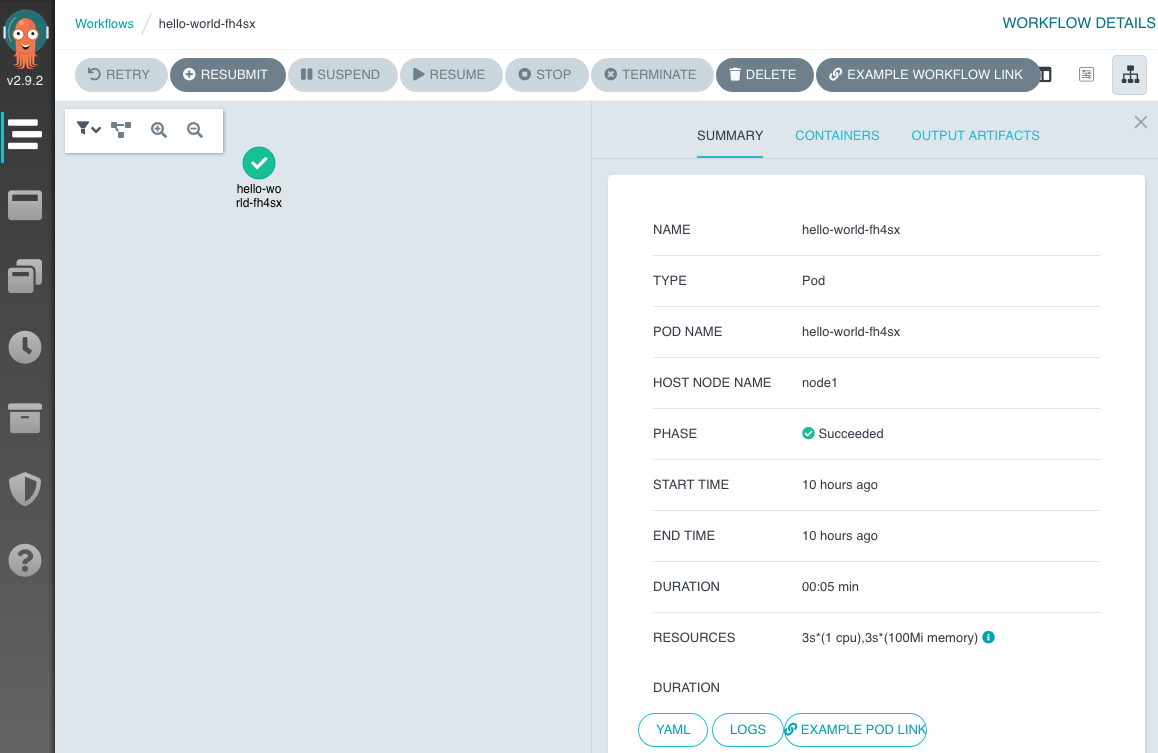
ワークフローを確認してみる。最初に実行した Hello-world は、タスクが一つしか無いので、一個だけが表示されている。このミドリのアイコンをクリックすると、右側に概要、コンテナ、出力成果物を選択して参照することができる。
次のステップが沢山あり並列処理があるサンプルも見ておく。
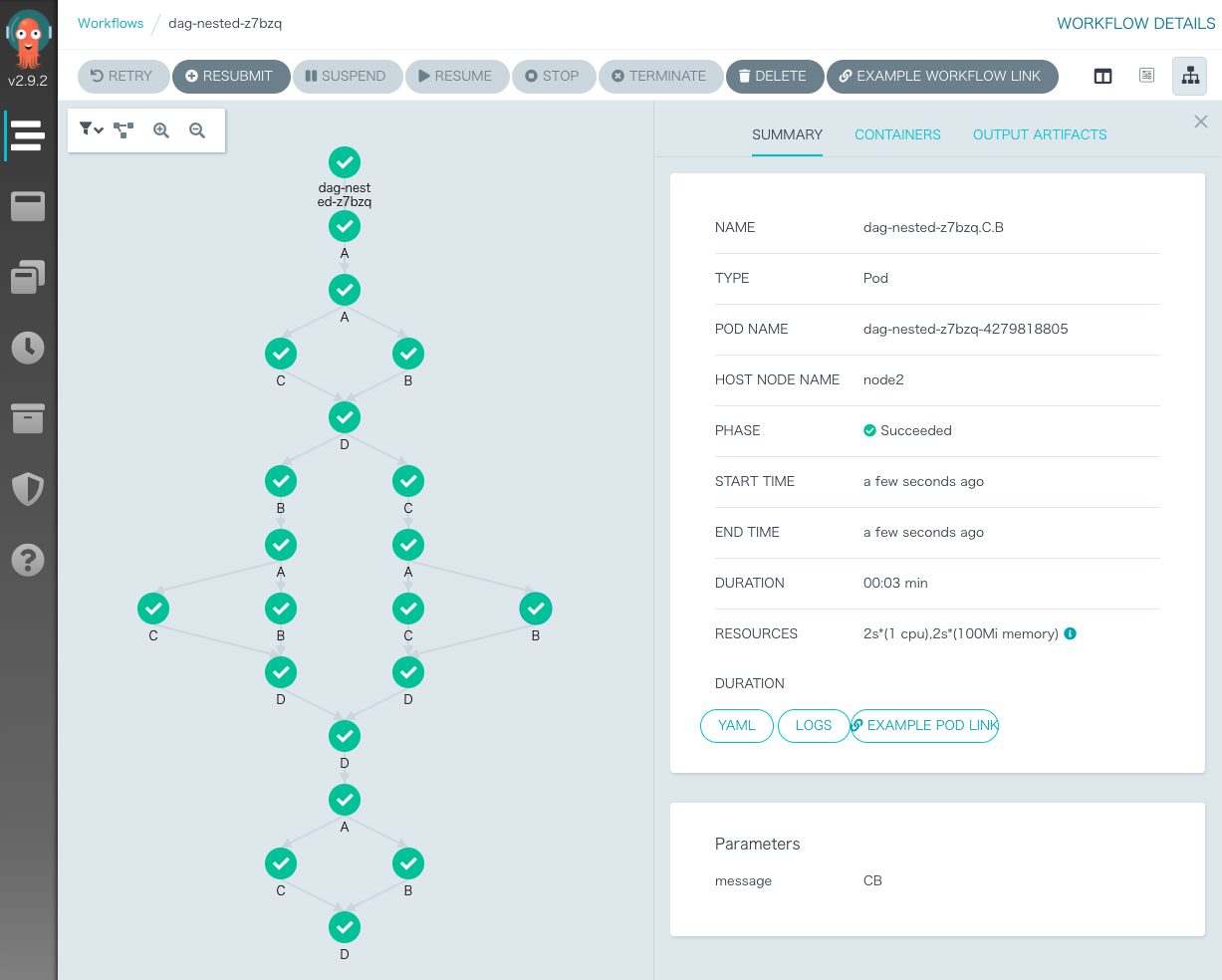
このジョブの構成ファイルが次である。ここでは、A,B,C,D のタスクがネストされて実行されている。
テンプレート、依存関係、受け渡す値などが表現されている。
apiVersion: argoproj.io/v1alpha1
kind: Workflow
metadata:
generateName: dag-nested-
spec:
entrypoint: diamond
templates:
- name: echo
inputs:
parameters:
- name: message
container:
image: alpine:3.7
command: [echo, "{{inputs.parameters.message}}"]
- name: diamond
dag:
tasks:
- name: A
template: nested-diamond
arguments:
parameters: [{name: message, value: A}]
- name: B
dependencies: [A]
template: nested-diamond
arguments:
parameters: [{name: message, value: B}]
- name: C
dependencies: [A]
template: nested-diamond
arguments:
parameters: [{name: message, value: C}]
- name: D
dependencies: [B, C]
template: nested-diamond
arguments:
parameters: [{name: message, value: D}]
- name: nested-diamond
inputs:
parameters:
- name: message
dag:
tasks:
- name: A
template: echo
arguments:
parameters: [{name: message, value: "{{inputs.parameters.message}}A"}]
- name: B
dependencies: [A]
template: echo
arguments:
parameters: [{name: message, value: "{{inputs.parameters.message}}B"}]
- name: C
dependencies: [A]
template: echo
arguments:
parameters: [{name: message, value: "{{inputs.parameters.message}}C"}]
- name: D
dependencies: [B, C]
template: echo
arguments:
parameters: [{name: message, value: "{{inputs.parameters.message}}D"}]
まとめ
Argo workflow の言葉のイメージから、人と人が連携して仕事を熟すためのツールと間違えそうだが、ジョブコントロールシステムと言っても良いと思う。いろいろ課題もあるが、深層学習などのデータ前処理、学習処理などにも便利なツールであるが、バッチ中心の業務システムなどでも使えそうに思う。
参考資料
- チュートリアル https://github.com/argoproj/argo/blob/master/docs/quick-start.md
- ワークフローのサンプル, https://argoproj.github.io/argo/examples/
- インストール, https://argoproj.github.io/argo/installation/
- https://github.com/argoproj/argo
- https://blog.argoproj.io/artifacts-management-in-container-native-workflows-part-1-f6efa838666b