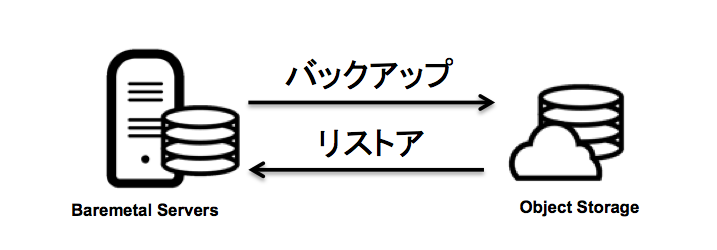
Bleumix インフラストラクチャー Baremetal Server の CentOS を Linuxのコマンドによるバックアップ、および、ディスク障害からのバックアップ時点までに復旧するリストア方法の備忘録です。対象のCentOSは、CentOS6.x x86-64, CentOS7.x x86-64で、バックアップの取得先は、Bluemix インフラストラクチャー の オブジェクト・ストレージです。
Bluemix インフラストラクチャー の Flex Image は CentOS7.x がサポート対象となっていません。このため、CentOS7.x の OSイメージのバックアップが、手軽に出来ないという課題がありました。
特記事項
- 本方法では、オブジェクト・ストレージの1オブジェクトの最大制限 5GB の制約を受けません。 したがって、OS起動ストレージが、5GB を超えるデータが保存されていても、すべてバックアップする事が出来ます。
- RedHat Enterprise Linux 6 / 7 の検証は実施していません。
- 本方法を仮想サーバーのバックアップに適用して、ベアメタルサーバーへリストアすることは検証していません。 また、その逆も検証していません。
- 本方法を4コアのベアメタルのバックアップに適用して、10コア等の大きなサイズのベアメタルへリストアする事は検証していません。すなわち、異なるベアメタルサーバーへリストアも検証していません。
- 本方法を他社の仮装サーバーや物理サーバーのバックアップに適用して、Bluemix インフラストラクチャー のベアメタルサーバーへリストアする事は検証していません。
- (注意)本方法は技術ノウハウを提供することが目的であり、利用者へのOSバックアップ・リストアを保証するものではありません。自己責任において利用をお願いします。
準備作業
このバックアップとリストアの方法では、Bluemix インフラストラクチャーのオブジェクト・ストレージに、アカウントを持っている必要があります。 アカウントの取得方法は、https://control.softlayer.com/ のメニューから Storage -> Object Storage -> Order Object Storage でアカウントを取得しておきます。
定期的なOSバックアップ取得として活用するのであれば、本記事で紹介するツール群をインストールしておく事をお勧めします。
基本的な作業の概要
基本的な流れは次の様になります。
バックアップの準備作業概要
- バックアップ・ツールのダウンロード (GitHub からのクローン)
- オブジェクト・ストレージの認証情報をツールの設定ファイルにセット
バックアップ実行概要
- バックアップ用のシェルスクリプトの実行
リストア実行手順概要
- ディスク交換後、OSのリロードを実行
- レスキュー・カーネルで起動
- リストア・ツールのダウンロード (GitHub からのクローン)
- オブジェクト・ストレージの認証情報のセット
- リストア用のシェルの実行
- 再起動
それでは、ここから詳細な内容に入っていきます。CentOS6.x と CentOS7.x ではコマンドやファイルなどが異なっていますが、シェルの中で切り替えて実行しています。
CentOS のバックアップ準備
ここから、すべて root での作業で、rootのホームディレクトリ /root で実行することを想定しています。 まず、git コマンドをインストールします。
# yum install git -y
次に、オブジェクト・ストレージにバックアップするためのツールを導入します。このツールのシェルは、rootのホームディレクトリ /root/os_tools で実行することを想定して書いていますので、それ以外の場所で実行する場合は、シェルを編集する必要があります。
バックアップ・ツールのダウンロード
# git clone https://github.com/takara9/os_tools
オブジェクト・ストレージの認証情報をツールの設定ファイルにセット
オブジェクト・ストレージの認証情報をツールの設定ファイルにセットします。 サンプルのファイル名は、credentials.json.sample でクローンしたファイルの中に含まれています。 このファイルの内容を本当の認証情報に置き換えます。
# mv credentials.json.sample credentials.json
このファイルの内容は、以下の様になっていますから、ポータル画面のオブジェクト・ストレージの認証情報 (Credentials) の内容に編集します。
{
"username": "IBMOS000001-1:IBM000001",
"password": "63411c19faee094567cab66d5127e40f5b8f13192cbcc16d21b751f330e13df",
"data_center": "tok02"
}
CentOS バックアップの実行
CentOS の OSバックアップは、以下のシェル・スクリプトを実行するだけです。
# ./backup_os
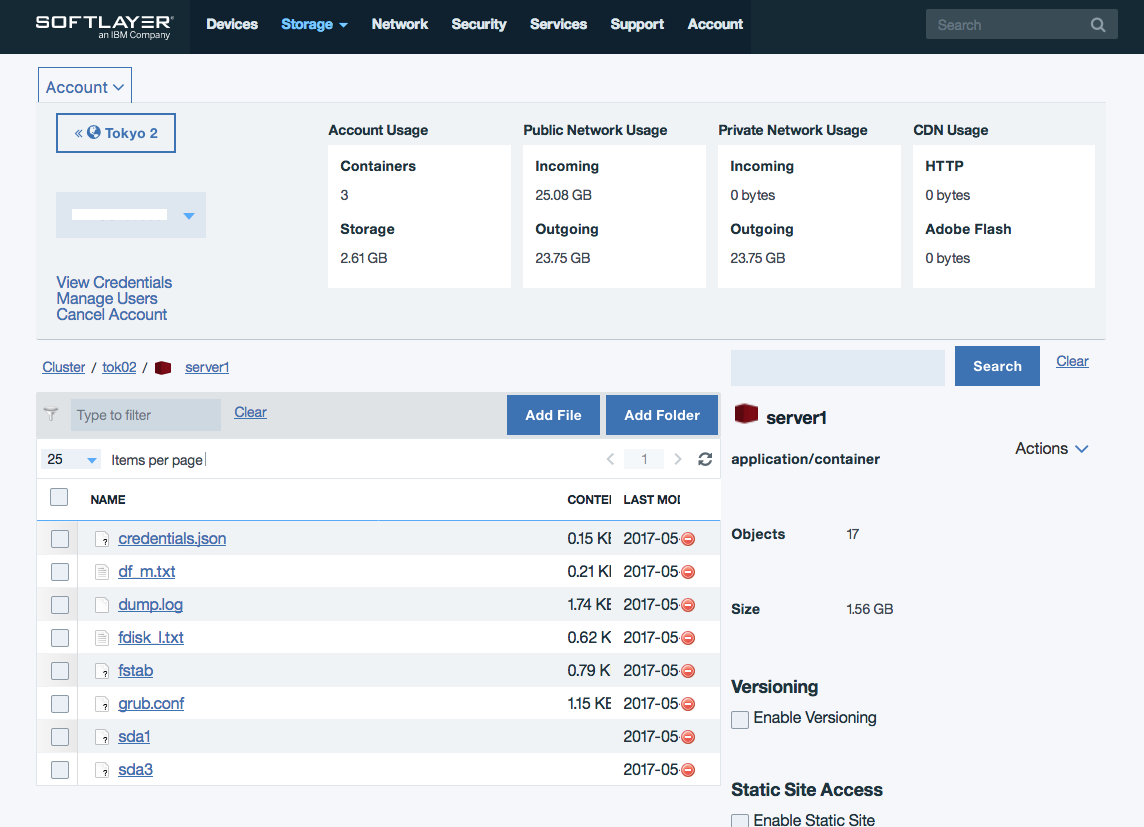
バックアップ先のオブジェクト・ストレージには、次の様にデータが保管されます。 sda1 と sda3 はメタファイルになっており、このメタファイルをダウンロードする事で、5GBを超えるファイルも一括で取得できます。
このシェル・スクリプトは、次の特徴を持っています。
- リストアに必要なファイル群が、オブジェクト・ストレージにアップロードされます。
- CentOS のバージョンに合わせて、実行するコマンドを変更するようになっています。
- バックアップの所用時間は、ベアメタル導入直後の状態(1.6GB使用) で30秒前後です。
- バックアップデータの一貫性を確保するための再起動やシングルユーザーモードへの移行を実施しません。
- sda1 をブート・ディスク、sda3 を ルート・ディスクとして固定設定しています。
- 一つのオブジェクトが5GBを超えるサイズに対応しています。
- オブジェクト・ストレージのコンテナを参照することで、バックアップの内容を確認できます。
CentOS リストアの実行
ベアメタルのディスクが壊れた場合、データセンターの技術員が壊れたディスクを交換して、もとのOSをリロード(再インストール)する処まで実施してくれます。そこで、この記事は、OSリロード完了した状態から、バックアップ取得時点まで復元する事を主に記載します。 OSのパーティションを設定、ファイルシステム作成等の作業は考慮していません。
ディスク交換後、OSのリロードを実行
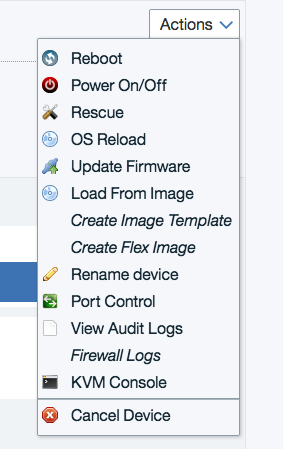
ポータルから実行するには、サーバーの詳細画面のアクションのメニューを展開して、OSリロードを選択することで、OSの再インストールをスタートできます。 下記のスクリーン・ショットでは、上から4番目の項目です。
レスキュー・カーネルで起動
ベアメタルの内臓ディスクに、バックアップしたOSイメージをコピーするために、ベアメタルサーバーをレスキューモードで起動します。 前述のアクション・メニューの上から3番目 Rescue をクリックします。 レスキュー・モードで起動が完了すると、パブリックIP または プライベートIP に対して、rootユーザーでログインできます。この時の認証は、ポータルから参照できる root のパスワードを用います。
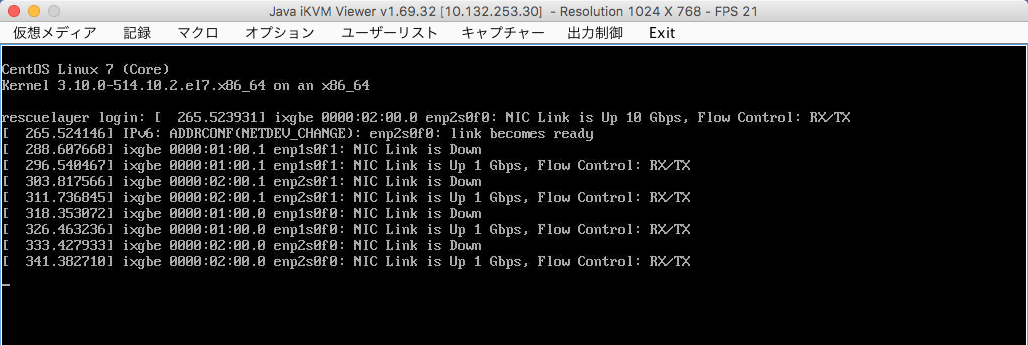
レスキュー・カーネルを起動する際に、KVM Console を起動しておくと、重大なOSエラー等がコンソールへ出力されるので、問題を早く発見する事ができます。 KVMコンソールを利用するには、SSL VPN 接続している必要があります。 次のスクリーン・ショットは、レスキュー・カーネルを起動した時のもので、起動直後はNICが初期化されていないため、IPアドレスにsshでアクセスして、ログインする事ができません。 起動後しばらくすると、NIC のポートがリンクアップしていきますので、これが完了すると、ssh を使って、プライベート側のIPアドレスへ接続する事ができる様になります。
リストア・ツールのダウンロード
これは前述のバックアップ・ツールのダウンロードと同じです。
# git clone https://github.com/takara9/os_tools
オブジェクト・ストレージの認証情報のセット
前述のオブジェクト・ストレージの認証情報のセットと同じです。 もし判らなければ、オブジェクト・ストレージにアップロードされていますから、ポータルからオブジェクト・ストレージにアクセスして、credentials.json をダウンロードする事で、参照できます。
リストア用のシェル・スクリプトの実行
レスキュー・カーネルからリストアを実行するには、次のコマンドを実行します。
# /root/os_tools/restore_os
このシェルを実行すると、レスキュー・カーネルのルートファイルシステムの下に、/sysimage/boot と /sysimage としてマウントされ、リストアされた状態になります。この後 /sysimage に展開された内容に対して、grub.conf、fstab を自動修正します。
[root@rescuelayer os_tools]# df
Filesystem 1K-blocks Used Available Use% Mounted on
/dev/loop5 3997376 1820116 2118944 47% /
devtmpfs 32657848 0 32657848 0% /dev
tmpfs 32930796 4 32930792 1% /dev/shm
tmpfs 32930796 2062488 30868308 7% /run
tmpfs 32930796 0 32930796 0% /sys/fs/cgroup
/dev/loop0 522810 522810 0 100% /run/initramfs/live
tmpfs 32930796 8 32930788 1% /tmp
varcacheyum 32930796 76752 32854044 1% /var/cache/yum
vartmp 32930796 0 32930796 0% /var/tmp
tmpfs 6586160 0 6586160 0% /run/user/0
/dev/sda1 253871 2051 238713 1% /sysimage/boot
/dev/sda3 960011672 73380 911149404 1% /sysimage
注意事項
レスキュー・カーネルは、CentOS7.xベースのため、レスキュー・カーネルの mkfs系コマンドで、ファイルシステムを作成した場合、CentOS6.x系では未サポートの内容を含むため、ファイルシステムをマウントできなくなる事があります。 CentOS6.x を復旧させる場合には、ポータル操作で OS reload によって作成されたファイルシステムへリストアする事がお勧めです。
再起動
再起動して、CentOSが起動して、login プロンプトが表示されると成功です。
# reboot
トラブルシューティング
- リストア後の起動時に、カーネルパニックが発生して起動不能となる
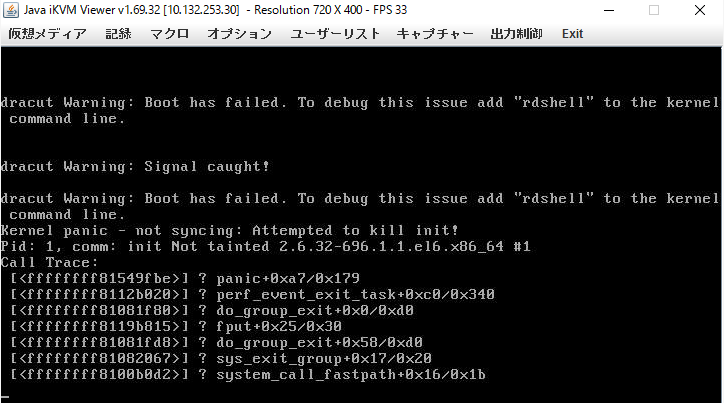
原因は、CentOS6.x のgrub.conf の / のディスク(sda3) の UUID を指定が間違っている場合、本問題が発生する。 grub.conf の UUID を再確認する。
参考資料
- RHEL6 第36章 基本的なシステムの復元 https://access.redhat.com/documentation/ja-JP/Red_Hat_Enterprise_Linux/6/html/Installation_Guide/ap-rescuemode.html
- RHEL7 8.7. XFS ファイルシステムのバックアップと復元 https://access.redhat.com/documentation/ja-JP/Red_Hat_Enterprise_Linux/6/html/Storage_Administration_Guide/xfsbackuprestore.html
- Red Hat Enterprise Linux 6 インストールガイド https://access.redhat.com/documentation/ja-JP/Red_Hat_Enterprise_Linux/6/html-single/Installation_Guide/index.html
- RHEL7 インストールガイド https://access.redhat.com/documentation/ja-JP/Red_Hat_Enterprise_Linux/7/html/Installation_Guide/index.html
- RHEL7 24.7. GRUB 2 の再インストール https://access.redhat.com/documentation/ja-JP/Red_Hat_Enterprise_Linux/7/html/System_Administrators_Guide/sec-Reinstalling_GRUB_2.html
- How to re-install bootstrap code (GRUB) https://wiki.centos.org/TipsAndTricks/ReinstallGRUB
- Bluemix IaaS Object Storage のupload / download ツール https://github.com/takara9/os_tools