第3回目は、Watson NLC (Natural Language Classifier; 自然言語分類) を利用して、チャットボットに意味の判別をさせます。 例えば、「おはよう」は、朝の挨拶であり、相手の存在を認識している事を表明して、相手からも同様に挨拶言葉が返ってくることを期待します。また「自己紹介してください」で自分の名前、職業、趣味などを話して欲しいという要求を表す意味になりますね。 この様な相手の気持ちや意思を受け止めて、反応を返す第一歩となる能力が、自然言語分類(以下 NLC とする)という機能になります
これまでの記事
- Watson チャットボットの作り方 第1回目 オウム返しボット
- Watson チャットボットの作り方 第2回目 セッション管理の実装
今回目指すレベル
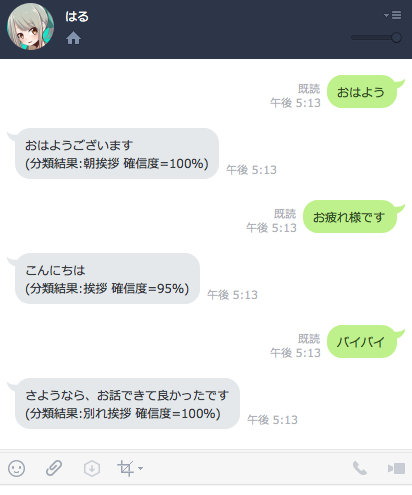
挨拶言葉を判別すること、受け取った挨拶に相応しい返事ができる様にします。そして、NLCのトレーニングを追加すれば、言葉の判別能力が向上して、返事のためのコーパスを追加すれば、応対ができる様にします。つまり、自分の好みに合わせて、チャットボットを育てる事ができる基礎になる実装レベルを目指します。次のLINEの画面は、第三回目で達成する実装レベルのイメージです。
Watson Natural Language Classifier (自然言語分類)とは
この Watson NLCは、Bluemix のサービスの一つで、Bluemix のカタログにある説明文を参考資料(1)では、以下になります。
Natural Language Classifier サービスは、コンピューター認識技法を使って、文または句に最も一致したクラスを戻します。例えば、質問を送信すると、このサービスは最も適した回答かまたは質問者のアプリケーションが次に取るべき操作を示すキーを戻します。 管理者は学習させるための典型的なストリングのセットとそれぞれのセットに対する 1 つ以上の正しいクラスのセットを供給して、分類サービスのインスタンスを作成します。学習を終えると、その新しい分類サービスが、新しい質問または句を受け取り、それに最も一致するものを確度を示す値と共に戻すことができるようになります。
参考資料(2)は、NLCのプロモーションのページで、NLCのデモや解説記事へのリンクがあり、素早く把握ができると思います。
チャットボットのアーキテクチャ
アーキテクチャと呼ばれるプログラムの基本構造の図のeventHandlerのボックスの下に、WatsonAPIs という箱を追加します。これは Watson API に関するコードをこのモジュールに集め、LINE版とFacebook版のコードで共通に利用できる様にすること、そして、重複が無い簡潔なコードとするためです。
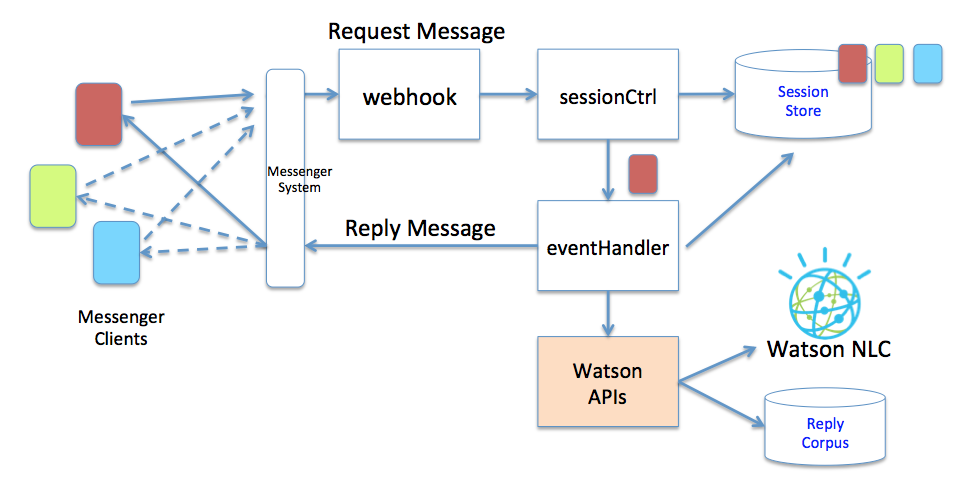
具体的に、eventHandlerに記述するコードは、次の様になっています。 watsonAPI.js のモジュールを読み込んで wn としてアクセスします。wn.messageReply をコールすることで、NLCにアクセスしていきます。 それから、このモジュールの内部のコードは、また後ほど紹介したいと思います。 wn.messageReplyのコールバック関数の中で、SNSクライアントへリプライを返します。
<中略>
var wn = require("./watsonAPI.js"); // Watson API
<中略>
// LINE イベント処理
function _eventHandlerLine( message, session, callback) {
if (message.events[0].message.type == 'text') {
session.inputMsg = message.events[0].message.text;
// Watson API をコールして応答を返す
wn.messageReply(session, function (err,session) {
bot.replyMessage(message.events[0].replyToken, session.outputMsg);
callback(err, session);
});
<中略>
コールバック関数の動きについて、解らないという方は、参考資料(3)に検証結果をまとめましたので、合わせて参照いただけると理解が深まると思います。
今回のリポジトリ
それぞれ、第三回目のコード用にブランチを切ってありますので下記の方法で、ローカルへクローンする事ができます。
git clone -b nlc https://github.com/takara9/chatbot-echo-facebook
git clone -b nlc https://github.com/takara9/chatbot-echo-line
それぞれのブランチへのリンク
- Facebook版 https://github.com/takara9/chatbot-echo-facebook/tree/nlc
- LINE版 https://github.com/takara9/chatbot-echo-line/tree/nlc
Watson NLC 利用開始
Watson NLC は、Bluemix の クラウドサービスの一つとして提供されています。Bluemixにログインして、画面右上のカタログをクリックすると。選択可能なサービスの一覧画面に進みますから、以下の Watson NLC アイコンを探してクリックします。
画面の表示内容に従って、Watson NLCをオーダーすると、サービス資格情報が提供され、このJSON形式のデータを利用してNLCにアクセスできます。
ランタイムとサービスを繋ぐサービス資格情報
前回と同様に、Bluemix のランタイムでは、VCAP環境変数を利用してNLCのサービスをアクセスし、ローカル開発環境では、vcap-local.jsonを編集して利用します。
ローカル開発環境の場合
また、ローカル開発環境では、vcap-local.json のファイルを編集します。今回は下記のファイルの中で、"natural_language_classifier" から始まる項目を追加します。credentials から始まる情報の参照先は、NLCのサービス資格情報です。
{
"services": {
"cloudantNoSQLDB": [
{
"credentials": {
"username": "*****",
"password": "*****",
"host": "*****",
"port": 443,
"url": "*****"
},
"label": "cloudantNoSQLDB"
}
],
"natural_language_classifier": [
{
"credentials": {
"url": "*****",
"username": "*****",
"password": "*****"
},
"label": "natural_language_classifier"
}
]
}
}
Bluemix の ランタイムの場合
ランタイムを実行した場合、サービスに接続できなくて、問題は判別に手間取ることがあります。次に紹介するコマンドで、アプリのランタイムへ提供されている環境変数をコマンドラインに表示するものです。
bx cf env line-chatbot
アプリ名を指定する必要がありますから、アプリ名を調べるには、次のコマンドが便利です。
bx cf apps
マニフェスト
Bluemix の CloudFoundry のランタイム環境へ、ファイル群をプッシュする際に、必ず manifest.yaml が必要です。 このファイルは、実行環境のスペック、および、結びつけるサービスのインスタンス名を記述します。 今回は、一番最後の行のNLCのインスタンス名を追加します。最後の2文字がユーザーのインスタンスによって変化しますから、最後まで正確に記述します。 マニフェストの記述について詳しく知りたい場合は、参考資料(4)が良いと思います。
applications:
- path: .
memory: 128M
instances: 1
domain: mybluemix.net
name: line-chatbot
host: line-chatbot
disk_quota: 1024M
services:
- Cloudant NoSQL DB-f1
- Natural Language Classifier-mr
この段階でpushしても、NLCのインスタンスが作られていないので動作しませんので、次から、NLCを作成してトレーニングを実施していきます。
NLC 分類器の作成とトレーニング
ここまで、NLCをオーダーして、インスタンス名を取得してmanifest.yamlに追加、サービス資格情報を参照してvcap-local.jsonを編集しておきます。そして、これから、NLCの分類器の作成とトレーニングを実施します。 NLC分類器のトレーニングのツールとデータは、https://github.com/takara9/chatbot-corpus/tree/master/nlc_training に置いてありますので、下記のコマンドで、takara9/chatbot-corpus をクローンして、ディレクトリを移動してご利用ください。
git clone https://github.com/takara9/chatbot-corpus
下記のツールを使って、分類器のトレーニングからテスト〜削除までのプロセスを見ていきます。これらのツールは、すべてコマンドライン用に作っていますから、ローカルの開発環境でNLCの分類器を作成して、テストしていきます。 それぞれのコマンドの使い方は、https://github.com/takara9/chatbot-echo-line/tree/nlc/nlc にありますので、参考にしてください。
| ファイル名 | 役割説明 |
|---|---|
| nlc_create.js | 分類器を作成してトレーニング |
| nlc_delete.js | 分類器を削除 |
| nlc_list.js | 作成済みの分類器をリスト |
| nlc_set_classifier_id.js | 分類器のIDをDBへセット |
| nlc_status.js | 分類器の状態をリスト |
| nlc_test.js | 分類器を対話でテスト |
分類器の作成からトレーニング完了まで
分類器の作成とトレーニング
GitHubのリポジトリに、サンプルのトレーニングデータ https://raw.githubusercontent.com/takara9/chatbot-echo-line/nlc/nlc/greetings.csv があります。これを利用して分類器をトレーニングします。
./nlc_create.js ja greetings2 greetings.csv
NLC 登録完了 {
"classifier_id": "67a480x203-nlc-31343",
"name": "greetings2",
"language": "ja",
"created": "2017-06-15T13:33:01.109Z",
"url": "https://gateway.watsonplatform.net/natural-language-classifier/api/v1/classifiers/67a480x203-nlc-31343",
"status": "Training",
"status_description": "The classifier instance is in its training phase, not yet ready to accept classify requests"
}
nlc_status.js を実行すると状態が、status に表示されます。 この値が Training から Availableになれば 完成です。
./nlc_status.js
{
"classifier_id": "67a480x203-nlc-31343",
"name": "greetings2",
"language": "ja",
"created": "2017-06-15T13:33:01.109Z",
"url": "https://gateway.watsonplatform.net/natural-language-classifier/api/v1/classifiers/67a480x203-nlc-31343",
"status": "Training",
"status_description": "The classifier instance is in its training phase, not yet ready to accept classify requests"
}
トレーニングの成果確認
nlc_test.js を実行して、プロンプトにメッセージを入れて、分類器のテストを実施します。 これで意図した様に分類されれば、チャットボットへ適用します。
./nlc_test.js 67a480x203-nlc-31343
NLC> お世話になります。
{
"classifier_id": "67a480x203-nlc-31343",
"url": "https://gateway.watsonplatform.net/natural-language-classifier/api/v1/classifiers/67a480x203-nlc-31343",
"text": "お世話になります。",
"top_class": "挨拶",
"classes": [
{
"class_name": "挨拶",
"confidence": 0.9798353344217938
},
{
"class_name": "別れ挨拶",
"confidence": 0.003859900890585107
},
<中略>
利用するべき分類器の指定
次のコマンドで、分類器のID (classifier_id) をチャットボットに登録します。 これでチャットボットのプログラムが、この分類器が利用される様になります。
./nlc_set_classifier_id.js set 67a480x203-nlc-31343
更新完了
このコマンド実行によって、Cloudant の データベース nlcid に キー(_id)として current_classifier_id で登録します。 チャットボットアプリは、下記の関数をコールして、現在使うべき分類器のIDを取得します。
// 受信した意味に対応する応答文検索
function getClassifierId(callback) {
var cdb = cloudant.db.use("nlcid");
var key = 'current_classifier_id';
cdb.get(key, function(err,data) {
callback(err, data.classifier_id);
});
}
分類器の運用
分類器をテストすると、意図した様に分類できない事や、本番適用すると、想定外のメッセージを受け処理できないなど、様々な問題が生じます。 このため継続的な改善のサイクルを回して、育てていく必要があります。 次の図は、参考資料(5)からの引用です。
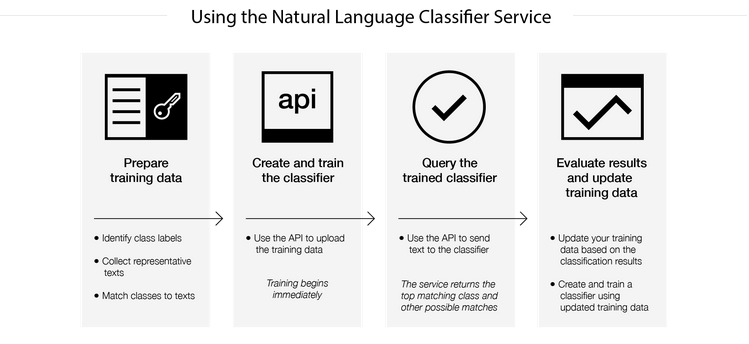
図の運用サイクルを訳すると、次の様になり、特に最後の評価と改善が重要になってきます。
- Prepare training data (トレーニングデータの準備)
- Create and train the classifier (分類器の作成とトレーニング)
- Query the trained classifier (訓練済みの分類器への問い合わせ)
- Evaluate results and update training data (結果の評価とトレーニングデータの更新)
NLCのAPIには、分類器の再訓練という機能は無いので、チャットボットを停止しないで能力を改善するには、並行して新しい分類器をトレーニングが完了したら、新しい分類器に切り替え、古い分類器を削除するといった運用が必要になります。 このため、
ローカル開発環境での実行
前述の様に、Cloudant と Wantson NLC のサービス資格情報を vcap-local.json にセットして、credentials.json にLINEやfacebookの認証情報、SSL接続に必要な証明書とキーをセットして、下記のコマンドで実行します。FacebookもLINEでも、どちらも同じです。
tkr@tkr02:~/chatbot-echo-line$ npm install
<中略>
tkr@tkr02:~/chatbot-echo-line$ npm start
tkr@tkr02:~/chatbot-echo-facebook$ npm install
<中略>
tkr@tkr02:~/chatbot-echo-facebook$ npm start
ローカル環境のセットアップは、Watson チャットボットの作り方 第1回目の「BMX-VSIで Node.js を実行する時の考慮点」や takara9/chatbot-echo-line 「Bluemix Infrastructure の仮想サーバーにデプロイする場合」が参考になると思います。
Bluemix へのデプロイ
LINEとfacebookのどちらも、bx cf push するだけです。
tkr@tkr02:~/chatbot-echo-line$ bx cf push
'cf push' を起動しています...
マニフェスト・ファイル /home/tkr/chatbot-echo-line/manifest.yml を使用しています
<中略>
要求された状態: started
インスタンス: 1/1
使用法: 128M x 1 インスタンス
URL: line-chatbot.mybluemix.net
最後アップロード日時: Thu Jun 15 13:46:46 UTC 2017
スタック: unknown
ビルドパック: SDK for Node.js(TM) (ibm-node.js-6.10.2, buildpack-v3.12-20170505-0656)
状態 次の日時から CPU メモリー ディスク 詳細
# 0 実行 2017-06-15 10:48:09 PM 0.0% 128M の中の 64.4M 1G の中の 101.4M
tkr@tkr02:~/chatbot-echo-facebook$ bx cf push
'cf push' を起動しています...
マニフェスト・ファイル /home/tkr/chatbot-echo-facebook/manifest.yml を使用しています
<中略>
要求された状態: started
インスタンス: 1/1
使用法: 128M x 1 インスタンス
URL: facebook-chatbot-tkr.mybluemix.net
最後アップロード日時: Thu Jun 15 13:51:34 UTC 2017
スタック: unknown
ビルドパック: SDK for Node.js(TM) (ibm-node.js-6.10.2, buildpack-v3.12-20170505-0656)
状態 次の日時から CPU メモリー ディスク 詳細
# 0 実行 2017-06-15 10:52:29 PM 0.2% 128M の中の 52.4M 1G の中の 97.5M
コーパスの作成
前述のアーキテクチャ図の中で、Reply Corpus の部分を作成していきます。トレーニング用のデータ greetings.csv では、挨拶言葉に関連する文が入っており、18 のクラスに分類する様に作っています。この 18 のクラスに対応する応答文を作成して、Cloudant のデータベース reply に登録します。 登録は、csv形式のデータを次のコマンド実行します。
./load_reply.py reply.csv
環境のセットアップは、takara9/chatbot-corpus/reply_sentences/README.mdの事前準備を参考にしてください。
応答文の内容は、クラス名、応答文 のCSV形式です。チャットボットがメッセージを受けて、分類器が分類したクラスに対応する応答文を返えすためのものです。
良評価,ありがとう
挨拶,こんにちは
質問名前,名前の質問に答える機能はありません、どうか私を育ててください
質問状態,状態の質問に答える機能はありません、どうか私を育ててください
自己依頼,自己紹介の機能はありません、 どうか私を育ててください
感謝,どういたしまして
朝挨拶,おはようございます
今日天気,天気の状態に答える機能はありません
風速質問,風速の状態に答える機能はありません
天気予報,天気予報にお伝えする機能はありません
温度質問,温度を認識する機能はありません
帰着挨拶,おかえりなさい
共感,これは共感ですね
気温質問,気温を認識する機能はありません
別れ挨拶,さようなら、お話できて良かったです
明日天気,天気予報にお伝えする機能はありません
悪評価,褒めて育ててくださいね
夜挨拶,こんばんは
以上で、「今回目指すレベル」まで達成した事になります。 様々な挨拶文に対して、適切な反応を返せる事ができると思います。
プログラムの実装 の解説
Watson API
今回、追加した Watson API のコードについて見ていきます。 前述の _eventHandlerLine() からコールされた関数の中身です。
// メッセージの意味判別と応答
exports.messageReply = function(session, callback) {
getClassifierId( function(err,cid) {
// 分類器へ渡すパラメータは、受信メッセージ、分類器のID
params = {
text: session.inputMsg,
classifier_id: cid
}
nlc.classify( params, function(err, resp) { <--- 訓練済みの分類器のコール
if (err) {
console.log(err);
session.outputMsg = "内部エラー発生";
callback(err,session);
} else {
//応答メッセージの組み立て
session.outputMsg = "(分類結果:" + resp.classes[0].class_name;
session.confidence = parseInt(resp.classes[0].confidence * 100);
session.outputMsg = session.outputMsg + " 確信度=" + session.confidence + "%)"
// 確信度が低い場合は、「わかりません」と答える
if (session.confidence < 60) {
session.outputMsg = "わかりません" + "\n" + session.outputMsg;
callback(null,session);
} else {
// 応答文の入った reply を 分類クラスでサーチして、対応する言葉を返信する
getReplyMsg(resp.classes[0].class_name, function(err,rsp) {
session.outputMsg = rsp + "\n" + session.outputMsg;
callback(null,session); <-- 応答文を返し、呼び出し元のコールバック関数を実行する
});
}
}
});
});
}
まとめ
3回目で、Watson NLC とチャットボットのプログラムを連結して、挨拶言葉に対して、応答を返せる様になりました。 今回の仕組みに、トレーニングデータと、対応するクラスの応答文を増やしていく事で、簡単な質問応答のシステムを作る事ができます。
チャットボットを運用していく上で、必要な要素として、ログを取得しておき、ログを分析して分類器を改善していく作業が必要ですが、今回の実装では、ログを取得して分析するといった機能がありません。 また、相手のユーザーを認識したり、識別する機能も無いですね。 次回は、ログ取得機能、および、会話ログから、トレーニングデータを改善する機能の実装を進めていきたいと思います。
参考資料
(1) Bluemix カタログ NKCとは https://console.ng.bluemix.net/catalog/services/natural-language-classifier?env_id=ibm:yp:us-south&taxonomyNavigation=apps
(2) 自然言語分類 https://www.ibm.com/watson/jp-ja/developercloud/nl-classifier.html
(3) Node コールバック関数とノンブロッキングI/O の動作 http://qiita.com/MahoTakara/items/4298440e1227c64aaec1
(4) CloudFoundry Deploying with Application Manifests https://docs.cloudfoundry.org/devguide/deploy-apps/manifest.html
(5) Natural Language Classifier How you use the service https://console.bluemix.net/docs/services/natural-language-classifier/natural-language-classifier-overview.html#about
(6) IBM Cloudant API Reference Databases CREATE https://docs.cloudant.com/database.html#create
(7) IBM Bluemix Docs Natural Language Classifier
https://console.bluemix.net/docs/services/natural-language-classifier/getting-started.html
(8) Natural Language Classifier Using your own data https://console.bluemix.net/docs/services/natural-language-classifier/using-your-data.html#using-your-own-data