現在職場でGoogle Colabを使って分析環境を整え、誰もが高度な分析ができることを目指しています。具体的には作ったコードをボタン1つで実行するだけで、コードに慣れていない人でもデータからインサイトを得られる。そんな環境作りを目指しています。
とはいえ、
「コードが不慣れな人に、どうやって安全かつ直感的に使ってもらえるか?」
分析条件を少し変えたい時、コードのどこを書き換えればいいのかを伝えるのは大変ですし、間違った場所を編集してしまうリスクもあります。
もし、コードを一切触ることなく、まるでWebサイトのようにボタンやスライダーを操作するだけで、分析条件を変えられるとしたらどうでしょうか?
その方法の1つとして最近Google Colabのウィジェット機能について調べたので、備忘録として纏めました。
手軽なフォーム機能の活用
Google Colabのウィジェットを使うと、スライダーやテキストボックスなどをノートブック上に表示し、マウス操作でコード中の変数の値をインタラクティブに変更できます。これにより、コードを都度書き換えることなく、パラメータ調整や結果のシミュレーションが簡単に行えるようになります。
数値を直感的に変える「スライダー」
グラフの表示件数や分析機関といったパラメーターを動かして試すことができるようになります。
#@title 整数スライダーの例 { run: "auto" }
integer_slider = 1 #@param {type:"slider", min:0, max:100, step:1}
print(f"選択された整数値: {integer_slider}")

テキスト入力
任意の文字列を入力させたい場合に使用します。
#@title テキスト入力の例 { run: "auto" }
text_input = "xxxxx" #@param {type:"string"}
print(f"入力されたテキスト: {text_input}")

日付ピッカーの例
カレンダーから特定の日付を選択させたい場合に使用します。
#@title 日付ピッカーの例 { run: "auto" }
selected_date = "2025-08-01" #@param {type:"date"}
print(f"選択された日付: {selected_date}")

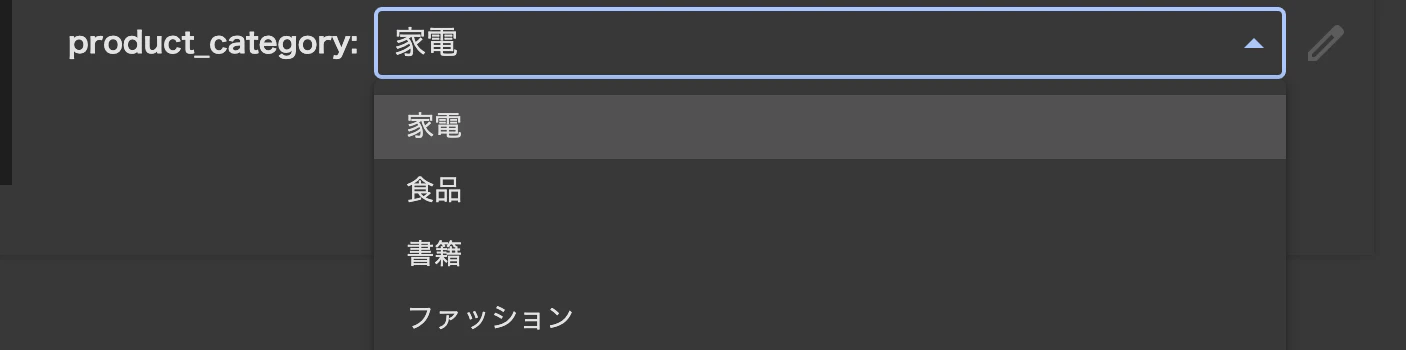
選択肢から安全に選ばせる「ドロップダウン」
分析対象の製品カテゴリや地域などをリスト化すれば、手入力によるミスを防ぎ、定義された選択肢の中から安全に選んでもらえます。
#@title 分析したい製品を選んでください { run: "auto" }
product_category = "家電" #@param ["家電", "食品", "書籍", "ファッション"]
print(f"「{product_category}」カテゴリのデータを分析します。")
ON/OFFを切り替える「チェックボックス」
「グラフに移動平均線を追加する」「前年同月比も計算する」といった分析のオプションを、ON/OFFできるようになります。
#@title チェックボックスの例 { run: "auto" }
use_feature = True #@param {type:"boolean"}
if use_feature:
print("機能が有効です。")
else:
print("機能が無効です。")

上記の方法だけでもある程度は、「コードの塊」から「少し対話的なツール」へと変わり映えするかと思いますが、「誰でも使える高度な分析環境を作る」には、もう一歩踏み込む必要があります。
ipywidgetsを使用したウィジェットの構築
「フォーム」機能は手軽ですが、「各担当者に自分のCSVファイルをアップロードして分析してほしい」「より複雑な条件設定ができるUIを作りたい」といった、プロジェクトの本格的な要求に応えるにはipywidgetsライブラリが不可欠です。
ライブラリの読み込み
import ipywidgets as widgets
from IPython.display import display
手元のデータを読み込ませる方法(FileUpload)
自分の手元にあるデータ(CSVやExcelなど)を直接ツールにアップロードして、標準化された分析を実行できるようになります。
import io
import pandas as pd
# ファイルアップロードウィジェットの作成
uploader = widgets.FileUpload(
accept='.csv', # .csvファイルのみを許可
multiple=False # 複数ファイルのアップロードを許可しない
)
print("CSVファイルをアップロードしてください:")
display(uploader)
def on_upload_change(change):
# アップロードされたファイル名を取得
filename = next(iter(uploader.value))
# ファイルの中身を読み込む
content = uploader.value[filename]['content']
# pandas DataFrameとして読み込む
df = pd.read_csv(io.BytesIO(content))
print("--- アップロードされたデータ (先頭5行) ---")
display(df.head())
# ファイルがアップロードされたら on_upload_change 関数を実行
uploader.observe(on_upload_change, names='value')

Uploadボタンが出てくるので、こちらをクリックすると任意のcsvファイルをアップロードすることができます。
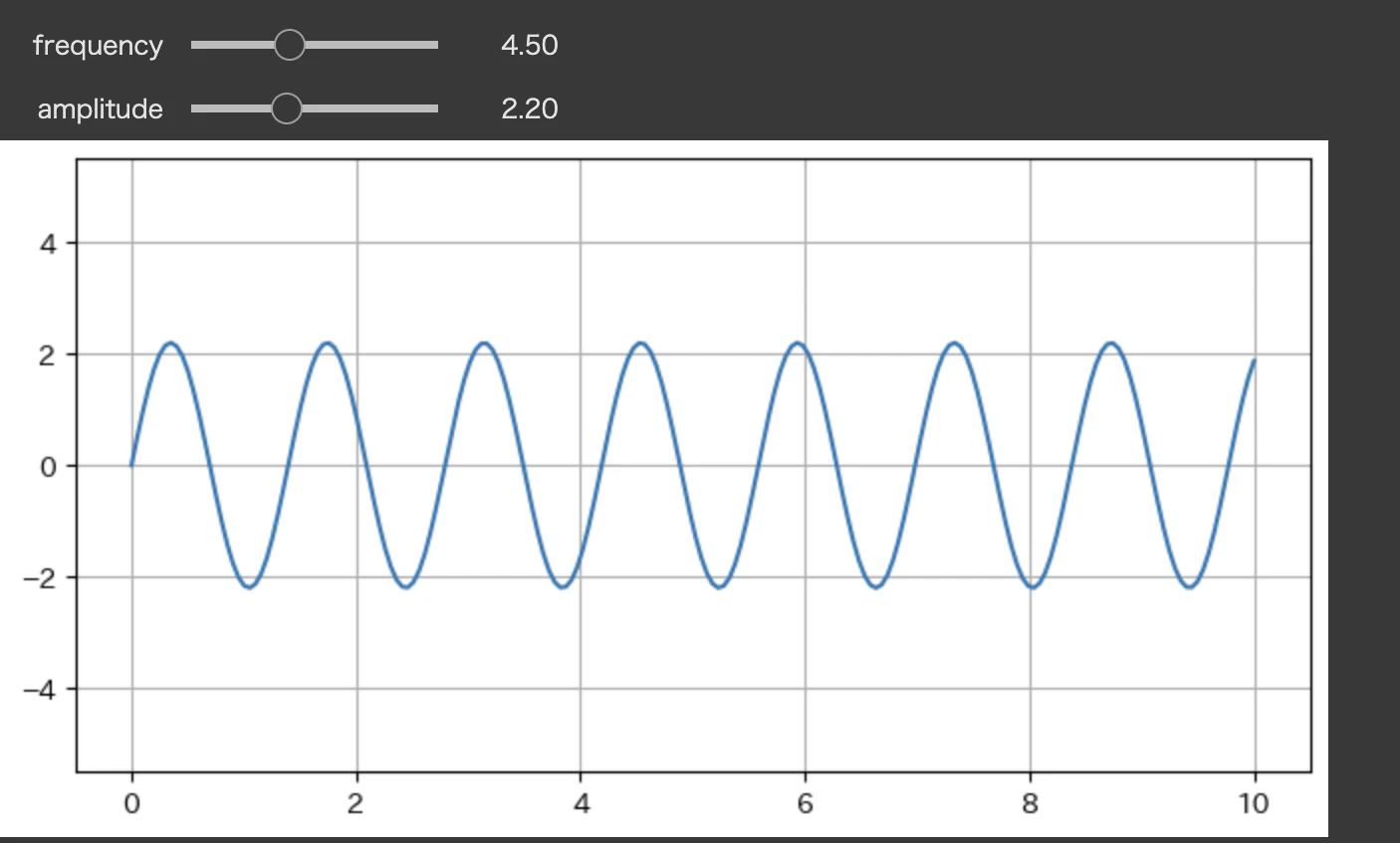
インタラクティブなグラフ操作(interact)
ipywidgets.interact を使うと、関数の引数を自動的にウィジェットに変換し、グラフなどを動的に変更できるようになります。パラメータを変更しながら結果を視覚的に確認したいデータ分析業務で効果を発揮します。
import numpy as np
import matplotlib.pyplot as plt
def plot_sine_wave(frequency, amplitude):
x = np.linspace(0, 10, 200)
y = amplitude * np.sin(frequency * x)
plt.figure(figsize=(8, 4))
plt.plot(x, y)
plt.ylim(-5.5, 5.5)
plt.grid(True)
plt.show()
# interactに関数を渡すと、引数がスライダーになる
widgets.interact(plot_sine_wave,
frequency=widgets.FloatSlider(min=1, max=10, step=0.5, value=2),
amplitude=widgets.FloatSlider(min=0.5, max=5, step=0.1, value=1));
機械学習モデルのハイパーパラメータを変更しながら、精度曲線をリアルタイムで確認したり、統計モデルのパラメータ(平均、分散など)を動かして、確率分布の形状がどう変わるか視覚的に理解する際に活用できると思います。
処理の進捗バー (IntProgress)
時間のかかる処理(例: 大規模なデータの前処理、モデルの学習など)を実行する際に、現在の進捗状況を知らせることができます。処理が止まっているわけではないと分かり、安心して待つことができます。
import time
# 進捗バーの作成 (0%から100%まで)
progress_bar = widgets.IntProgress(
value=0,
min=0,
max=100,
description='処理中:',
style={'bar_color': 'lightgreen'} # バーの色を指定
)
display(progress_bar)
# 時間のかかる処理をシミュレート
for i in range(101):
progress_bar.value = i
time.sleep(0.05) # 0.05秒待つ
progress_bar.description = '完了!'


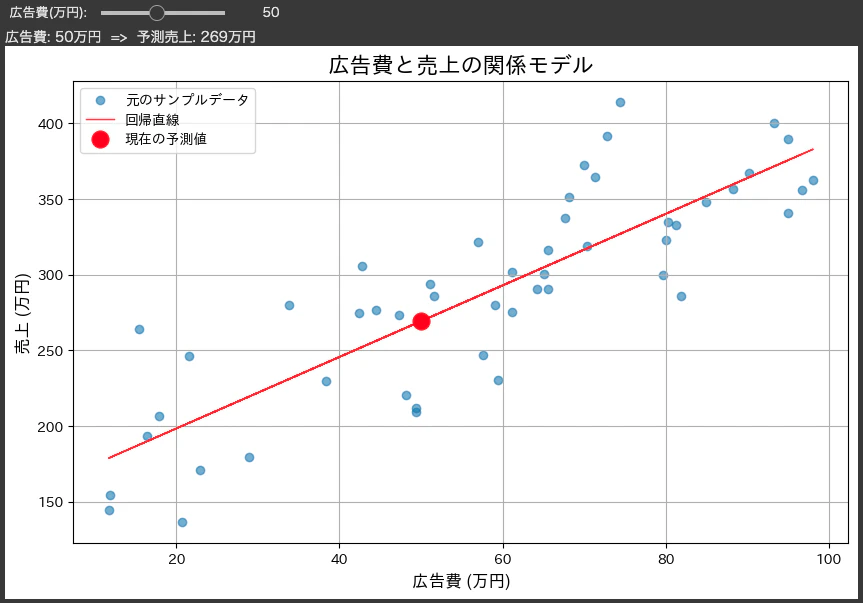
"what-if"分析の実装(interact)
「広告費をこれくらい増やしたら、売上予測はどう変わる?」
「このパラメータを調整したら、顧客の反応はどう変化する?」
interactを使えば、そんなwhat-if分析ができるようになります。関数の引数が自動でスライダーに変わり、まるでシミュレーターのように結果を試せます。
今回は広告費と売上関係スライダーで可変することで、瞬時に求めることができるコードを作成してみました。
pip install japanize_matplotlib
import numpy as np
import matplotlib.pyplot as plt
import japanize_matplotlib
import ipywidgets as widgets
from ipywidgets import interact
from sklearn.linear_model import LinearRegression
# --- 1. サンプルデータの作成 ---
# 乱数を固定して、いつでも同じデータが作られるようにする
np.random.seed(0)
# 広告費 (10〜100万円の範囲で50個のデータをランダムに生成)
X = 10 + 90 * np.random.rand(50, 1)
# 売上 (広告費に比例する関係に、ノイズ(ばらつき)を加える)
y = 150 + 2.5 * X.flatten() + np.random.randn(50) * 40
# --- 2. 予測モデルの作成と学習 ---
# 単回帰モデルのインスタンスを作成
model = LinearRegression()
# 作成したサンプルデータでモデルを学習させる
model.fit(X, y)
# --- 3. interactと連携するシミュレーション関数の定義 ---
def sales_simulator_with_model(ad_spend):
# スライダーから受け取った広告費を使って売上を予測
# model.predict()には2次元配列を渡す必要があるため、[[ad_spend]]とする
predicted_sales = model.predict([[ad_spend]])[0]
print(f"広告費: {ad_spend:,.0f}万円 => 予測売上: {predicted_sales:,.0f}万円")
# --- ▼▼ グラフの可視化 ▼▼ ---
plt.figure(figsize=(10, 6))
# 1. 元のサンプルデータを散布図としてプロット(青い点)
plt.scatter(X, y, alpha=0.6, label='元のサンプルデータ')
# 2. 学習したモデルの回帰直線をプロット(赤の線)
plt.plot(X, model.predict(X), color='red', linewidth=1, label='回帰直線')
# 3. スライダーで選択された現在の予測値をプロット(赤い大きな点)
plt.plot(ad_spend, predicted_sales, 'ro', markersize=12, label='現在の予測値')
# グラフのタイトルやラベルを設定
plt.title('広告費と売上の関係モデル', fontsize=16)
plt.xlabel('広告費 (万円)', fontsize=12)
plt.ylabel('売上 (万円)', fontsize=12)
plt.grid(True)
plt.legend()
plt.show()
# --- 4. ウィジェット(スライダー)とシミュレーション関数を連携 ---
interact(sales_simulator_with_model,
ad_spend=widgets.IntSlider(min=10, max=100, step=5, value=50, description='広告費(万円):'));
まとめ
今回What-if分析の方では、サンプルデータを作成して実装をしました。
サンプルデータ作成の部分をFileUploadに変更するだけで、任意のcsvファイルから回帰直線を求めることができるコードへ早変わりすると思うので、ぜひこちらのコードを参考に誰もが活用できるようなコートに整えてみてはいかがでしょうか?